〇、Python 是什么
P(胖)y(丫)t(头)h(狠)o(殴)n(你)是一种高级编程语言。
一、推荐的教程
随便找了个看上去挺完整的教程
这里不再做任何推荐。
二、这篇学习笔记适合什么人
适合我。
不适合什么都不会的人。适合很会 C++ (C++ 11 及以上版本)的,熟悉基础算法的,了解部分高级数据结构的,有一定 C++ 开发经验的,熟悉计算机基本知识的,不会 Python 的人。
三、环境
1. 操作系统
对于 Windows
至少 Windows 10 1903
推荐 Windows 10 1903(OS 内部版本 18362.145)
如果版本低于最低要求版本,请升级操作系统(你要是不升级我也拿你没法)。
特别地,如果你的操作系统版本为 Windows XP 或更低,请点击右上角。
推荐使用 64 位操作系统。
对于 Ubuntu
至少 Ubuntu 18.04
如果版本低于最低要求版本,请升级操作系统(你要是不升级我也拿你没法)。
只提供 64 位操作系统。
对于其他操作系统
随便你。
2. Python
众所周知,Python 2 和 Python 3 并不兼容,这里我们学的是 Python 3。
对于 Windows
Python 3.7.0(64 位)
目前最新版本为 Python 3.7.3,请前往官网下载。
安装步骤
1. 下载
你可以点击上面的链接,也可以到 Python 官网上去下载。
2. 安装
注意要勾选高亮的那个东西。
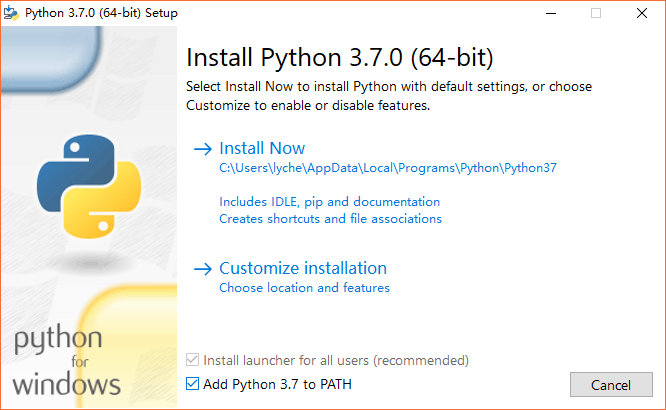
什么你看不到?就是那个“Add Python 3.7 to PATH”。
然后点击“立即安装”。然后按 Close,就安好啦!
测试是否成功安装
在命令提示符中输入:
python
将会出现
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
即说明安装成功。称这个界面为“Python 交互界面”。
退出 Python
输入:
exit()
或
quit()
即可退出刚刚测试时进入的 Python。注意,Python 是区分大小写的。
对于 Windows 应用商店用户
在 Windows 应用商店中找到 Python 3.7,安装即可。不过,它真的需要 Windows 10 17763.0 或更高版本。
对于 Ubuntu
在新安装的 Ubuntu 18.04 中,输入:
python
提示:
Command 'python' not found, but can be installed with:
sudo apt install python3
sudo apt install python
sudo apt install python-minimal
You also have python3 installed, you can run 'python3' instead.
所以输入:
python3
即可启动 Python:
Python 3.6.5 (default, Apr 1 2018, 05:46:30)
[GCC 7.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
四、第一个 Python 程序
在 Python 交互界面中,键入:
print('hello world')
运行效果:
Python 3.7.0 (v3.7.0:1bf9cc5093, Jun 27 2018, 04:59:51) [MSC v.1914 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> print('hello world')
hello world
>>>
Q & A
1. 为何 Python 拥有交互界面
不同于 C++ 是编译型语言,Python 是解释型语言,所以速度相比 C++ 要慢许多,也不如 C++ 底层。但正因为如此,Python 交互界面的存在就有理由了。
2. 为何字符串用 ’ ’ 表示
事实上,也可以用 " " 表示。将会在后面解释。
3. print 是什么
显然 print 是用来输出的函数。具体如何使用将在后面解释。
保存你的源代码
1. 使用 IDE
这里不作任何推荐,我用的是 Visual Studio 2019。接下来的教程都基于 Visual Studio 2019。
至于 IDE 的使用方法和设置选项,请自行摸索。
2. 通过你的源代码运行程序
输入代码:
按下运行键,即可得到运行结果:
hello world
请按任意键继续. . .
浏览一下项目的文件结构,发现只有一个有用的文件:
3. 在命令提示符中运行这个程序
在命令提示符中,首先将当前目录更改为源代码所在的目录,然后键入:
python FirstPythonApplication.py
即可得到运行结果。
4. 在 Ubuntu 中运行这个程序
Ubuntu 中可以直接运行以 .py 结尾的文件,但是需要在代码最前面加上一句注释:
print('hello world')
**Python 中用 # 表示注释。**注意这里的第一句注释是不能改的。
五、变量与基础数据类型
1. 变量
① 动态类型
不同于 C++ 是静态类型语言,Python 是动态类型语言。静态类型语言需要先声明变量,在编译的时候就确定了这个变量所占的空间以及如何操作这个变量。而动态类型语言的变量的类型在运行时确定,并且不用提前声明。
② 声明变量
在 Python 中交换两个变量的程序可以这样写:
程序:交换两个“变量”
a = 1
b = 2
t = b
b = a
a = t
print(a)
print(b)
运行结果:
2
1
在这里,变量 a,b,t 均未提前声明。Python 声明变量的方式就是在第一次使用某个变量时为其赋值,而且 Python 的变量没有默认值。
另外,这个程序也说明了 Python 没有像 C++ 那样用 ; 作为一句代码的结尾。
③ 动态类型语言的实例
程序:测试动态类型
a = 1
b = 2
print(a + b)
a = "1"
b = "2"
print(a + b)
b = 3
print(a + b)
运行结果:
3
12
Traceback (most recent call last):
File "demo.py", line 10, in <module>
print(a + b)
TypeError: can only concatenate str (not "int") to str
这份代码可以帮助你理解动态类型语言。
2. 常量
Python 没有常量。
程序:一个 C++ 程序
const int a = 10;
a = 100; // WRONG!
C++ 路过……
3. 数据类型
① 整数 int
除了十进制表示法,也可以像 C++ 那样,以 0x 开头表示十六进制的数。
程序:十六进制表示法
print(0xff - 255)
print(255 - 0XfF)
与 C++ 完全不同的是,Python 中的整数不分 32 位和 64 位,在 Python 中整数就是整数。
程序:整数
print(0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff + 233)
前者是一个 256 位的整数。
运行结果:
115792089237316195423570985008687907853269984665640564039457584007913129640168
还可以表示八进制数,甚至还能表示二进制数。
程序:八进制和二进制
print(0o11)
print(0O11)
print(0b1001)
print(0B1001)
运行结果:
9
9
9
9
② 浮点数 float
Python 的浮点数和 C++ 的 double 一样(或类似),有大小和精度限制。
用 / 运算符进行除法运算,结果始终是浮点数。若要进行整除,请使用 // 运算符。// 运算符的结果是否是整数,取决于它的操作数的类型。
程序:浮点数的除法
print(666 / 233)
print(666 // 233)
print(666.0 // 233)
print(666 // 233.0)
print(666.0 // 233.0)
print(666 / 0)
运行结果:
2.8583690987124464
2
2.0
2.0
2.0
Traceback (most recent call last):
File "demo.py", line 6, in <module>
print(666 / 0)
ZeroDivisionError: division by zero
在除法的基础上,我们有可亲的求余运算符 %。一般情况下,它与 C++ 的类似,甚至还要更厉害些。
程序:求余 1
print(365 % 7)
print(30 % 60)
print(2.33 % 0.3)
运行结果:
1
30
0.23000000000000015
浮点误差令人感到亲切。
但是如果有负数,事情就不是这么好理解了:
程序:求余 2
print(-1 % 7)
print(-2 % 7)
print(1 % -7)
print(2 % -7)
print(-1 % -7)
print(-2 % -7)
print(5 % 7)
print(5 % -7)
print(-5 % 7)
print(-5 % -7)
运行结果:
6
5
-6
-5
-1
-2
5
-2
2
-5
一言以蔽之,Python 取余运算结果的正负与除数的正负相一致,这与 C++ 中与被除数的正负相一致是不同的。实际上,这个结果的出现赖于 Python 处理带负数整除的机制。Python 始终向下取整,而 C++ 始终向 0 取整,因此会有如此不同的结果。
程序:求余 3
print(8 / 5)
print(8 // 5)
print(8 % 5)
print()
print(-8 / 5)
print(-8 // 5)
print(-8 % 5)
print()
print(8 / -5)
print(8 // -5)
print(8 % -5)
print()
print(-8 / -5)
print(-8 // -5)
print(-8 % -5)
运行结果:
1.6
1
3
-1.6
-2
2
-1.6
-2
-2
1.6
1
-3
乘方运算
Python 还有乘方运算符 **。需要特别注意的是它比某些单目运算符(如负号 -)还要高。
程序:乘方
print(2 ** 4)
print(-2 ** 4)
print((-2) ** 4)
运行结果:
16
-16
16
③ 布尔值 bool
程序:布尔值
print(True)
print(False)
print(1 < 2)
print(1 > 2)
print(int(True))
print(bool(1))
print(bool(0))
print(True == 1)
print(True == 2)
print(true)
运行结果:
True
False
True
False
1
True
False
True
False
Traceback (most recent call last):
File "demo.py", line 10, in <module>
print(true)
NameError: name 'true' is not defined
也就是说,布尔值是一种单独的类型(bool),值为 True 或 False(区分大小写)。当 True 被强制转化成整数时, 它将会被转化为 1;当整数倍转化成 bool 时,情况与 C++ 相同。至于其他类型转化成 bool 的情况,我们以后再说。
④ 字符串 str(入门)
在 Python 中,可以像在 C++ 中一样用 " " 表示字符串:
print("this is a string")
也可以使用 C++ 中的转义符:
print("this is a string\nFirst\t\"Python\'\' Application")
运行结果:
this is a string
First "Python'' Application
(中间是个制表符)
除此之外,还可以用 ' ' 表示字符串。在使用 ' ' 表示字符串时,字符串中的 " 不用加转义符:
print('"python"');
运行结果:
"python"
同理,在使用 " " 表示字符串时,字符串中的 ' 不用加转义符。除此之外,' 和 " 没有任何区别。
长字符串
使用 ''' 表示长字符串:
print(
'''释义
“你好”是对别人的一种尊敬,遇到认识的人或陌生的人都可以说的。
“你好”主要用于打招呼请教别人问题前的时候,或者单纯表示礼貌的时候等。
“你好”的表达情感比较中性,与熟人说有点过于拘束,多和非熟人群体应用,表达一种礼貌。''')
运行结果:
释义
“你好”是对别人的一种尊敬,遇到认识的人或陌生的人都可以说的。
“你好”主要用于打招呼请教别人问题前的时候,或者单纯表示礼貌的时候等。
“你好”的表达情感比较中性,与熟人说有点过于拘束,多和非熟人群体应用,表达一种礼貌。
原始字符串
在 "、' 或者 ''' 前面加上 r,将不会翻译字符串中的转义字符,称这种字符串为原始(raw)字符串。特别地,原始字符串不能以奇数个 \ 结尾,因为这样 \' 将会被当作转义字符,从而出现错误;如果再补上一个 ',\' 又会被当作原始字符串。一个有效的解决方法是:用两个字符串来表示。这一点与 C++ 是相同的。
程序:原始字符串技巧
print('''C:\Windows\System32''''\\')
print('''C:\Windows\System32''' '\\')
print('''C:\Windows\System32\\\
Windows.System.Profile.HardwareId.dll''')
print('''C:\Windows\System32\\ \
Windows.System.Profile.HardwareId.dll''')
运行结果:
C:\Windows\System32\
C:\Windows\System32\
C:\Windows\System32\Windows.System.Profile.HardwareId.dll
C:\Windows\System32\ Windows.System.Profile.HardwareId.dll
上面还用到了一个 \ 作为强制换行的标志,这一点也与 C++ 是相同的。
程序:一个 C++ 程序
#include <cstdio>
int main()
{
wprintf(L"go"
"od\n");
wprintf(L"go\
od\n");
return 0;
}
C++ 路过……运行结果:
good
go od
中间岔开的制表符是强制换行后本用来代码对齐的制表符被算进了字符串中的结果!类比到 Python,可以肯定地说,\ 用在行末就是一个强制换行的作用,相当于它本身与接下来的回车构成一个什么都不表示的转义字符。需要注意,这个符号之后不应再加任何内容,包括空格。
Python 的又一个好处是,(Python 3 的)字符串都是 Unicode 的,不用像 C++ 中在字符串前面加一个 L 表示宽字符字符串。
六、序列:列表和元组
1. 数组与列表
程序:熟悉的数组
sequence = [1, 2, 3]
print(sequence[0])
print(sequence[1])
print(sequence[2])
print(sequence)
print(sequence[-1])
print(sequence[-3])
print(sequence[-4])
运行结果:
1
2
3
[1, 2, 3]
3
1
Traceback (most recent call last):
File "demo.py", line 8, in <module>
print(sequence[-4])
IndexError: list index out of range
在 Python 中,最基本的数据结构为序列(sequence)。列表(list)是序列的典型代表,它其实就是 C++ 中的动态数组(std::vector)。Python 和 C++ 一样,数组的下标(更专业地说,应该叫“序列的索引(indexing)”)从 0 开始编号,但有两个很重要的不同点:
- Python 可以有负下标,表示倒数第 n 个元素(这时 n 从 1 开始计数),这一点可以从上述示例代码中看得很清楚;
- 在下标超出范围时,Python 会明确发生运行时错误,而不像 C++ 那样进行简单的指针操作不加检查。这一点与 Python 解释型语言的身份相符。
列表是一个名为 list 的类。是数组就应该有数组的特性,是类就应该由相应的方法,下面对其进行介绍。
① 列表的加法和乘法
可使用 + 来拼接列表;可使用 * 来得到使原序列重复 n 次的新列表。
程序:列表的加法和乘法
print([1, 2, 3] + [4, 5, 6])
print([1, 2, 3] * 3 + [4, 5, 6])
运行结果:
[1, 2, 3, 4, 5, 6]
[1, 2, 3, 1, 2, 3, 1, 2, 3, 4, 5, 6]
② 列表的的初始化
Python 与 C++ 不同的是,它不能直接声明一个变量而不初始化。
程序:那我声明一个大数组咋办捏
int sequence[int(1e6)];
C++ 路过……
程序:Python 解决方案
sequence = [0] * int(1e6)
emptySequence = [None] * int(1e6)
这里有一个新东西:None。在 Python 中,None 表示什么都没有,而不是 0!
程序:None 的真假
print(bool(None))
print(bool(0))
运行结果:肯定都是 False 啊!
③ 动态类型的列表
列表本来都是动态类型的哟。
程序:动态类型在列表中
sequence = [None, bool(1), 2, "san", [4, 5], [6, [7, [8]]]]
print(sequence)
运行结果:
[None, True, 2, 'san', [4, 5], [6, [7, [8]]]]
当然,一般我们不会用这种神奇的动态类型。看上去动态类型十分复杂,好消息是,网上说时间复杂度是有保证的,下面我们来看看。
④ 索引
刚刚已经讲过了。这里明确提出:使用索引的时间复杂度为:
O
(
1
)
\LARGE{O(1)}
O(1)
什么我为什么不打小一点?我的意思是,如果你不知道时间复杂度是什么东西的话,赶紧去学!
程序:试验 1
sequence = [None] * int(1e7)
sequence[-1] = int(input())
sequence[-2] = int(input())
print(sequence[-1] * sequence[-2])
程序:试验 2
sequence = [None] * int(1e7)
print(int(input()) * int(input()))
程序:试验 3
print(int(input()) * int(input()))
试验 2 比试验 1 的时间消耗和内存消耗少一点点。试验 3 比试验 2 的时间消耗和内存消耗少许多,说明 Python 所进行的操作与代码本身基本相符。另外,可以发现, Python 的大整数乘法虽然在时间复杂度上有了保证,但是常数巨大,无法与用 C++ 写的 FFT 相媲美。事实上,这就是解释型语言的缺点:运行效率低。
⑤ 其他方法
in 运算符
程序:in 与列表相会,字符串前来凑合
sequence = [r'raw', 1, 2, [1, 2, 3]]
print('raw' in sequence)
print('r' in sequence[0])
print('aw' in sequence[0])
print(1 in sequence)
print([1, 2] in sequence)
print([1, 2, 3] in sequence)
运行结果:
True
True
True
True
False
True
也就是说,in 运算符与
∈
\in
∈ 同义,但特别地,对字符串,in 表示“是否是子串”。
对于表示
∈
\in
∈ 的 in,时间复杂度显然是
O
(
n
)
O(n)
O(n)。对于用于检查是否是子串的 in,时间复杂度我也不知道!正所谓怀最坏的打算迎最好的结果,姑且认为它使用的是时间复杂度为
O
(
n
m
)
O(nm)
O(nm) 的算法吧!
del 运算符
程序:del 与 in
sequence = [r'raw', 1, 2, [1, 2, 3]]
del sequence[0]
print('raw' in sequence)
print('r' in sequence[0])
运行结果:
False
Traceback (most recent call last):
File "demo.py", line 4, in <module>
print('r' in sequence[0])
TypeError: argument of type 'int' is not iterable
由于不知道 Python 内部的实现,我们无法肯定 del 作用在列表上时的时间复杂度(或许有懒惰删除)。不过显然,这个时间复杂度不会超过
O
(
n
)
O(n)
O(n)。网上有人指出,
O
(
n
)
O(n)
O(n) 妥妥的。
len、min、max 函数
函数 len 返回序列包含的元素个数,而 min 和 max 函数分别返回序列中最小和最大的元素。另外,min 和 max 函数支持直接将任意多个数作为参数。
程序:len、min、max
sequence = [0] * int(1e8)
sequence[int(1e8) >> 1] = 1
print(sequence[int(1e8) >> 1])
print(len(sequence))
print(max(sequence))
print(min(2, 3, -1, 10, -10.0, -15))
运行结果:
1
100000000
1
-15
该程序的运行时间证明,对于列表而言,len 的时间复杂度为
O
(
1
)
O(1)
O(1),min、max 的时间复杂度为
O
(
n
)
O(n)
O(n)。
append 方法
void push_back(const T& val);
C++ 路过……
程序:append 示例
sequence = [r'raw', 1, 2, [1, 2, 3]]
print(sequence)
print(sequence.append("いち, に, さん"))
print(sequence)
运行结果:
['raw', 1, 2, [1, 2, 3]]
None
['raw', 1, 2, [1, 2, 3], 'いち, に, さん']
注意,append 始终返回 None,类似于 C++ 中的 void 型函数。
append 的时间复杂度为
O
(
1
)
O(1)
O(1)。
clear 方法
程序:clear 示例
sequence = [r'raw', 1, 2, [1, 2, 3]]
print(sequence.clear())
print(sequence)
运行结果:
None
[]
瘦死的骆驼比马大,clear 了的 list 还是 list。时间复杂度显然为
O
(
n
)
O(n)
O(n)。
copy 方法
程序:C++ 被叫来巡山
std::vector<int> a({1, 2, 3});
auto& b = a;
b.push_back(4);
std::cout << '[' << a[0];
for(int i = 1; i < a.size(); i++)
std::cout << ", " << a[i];
std::cout << ']';
程序:真假新列表
a = [1, 2, 3]
b = a
b.append(4)
print(a)
运行结果如出一辙:
[1, 2, 3, 4]
程序:copy 来也
a = [1, 2, 3]
b = a.copy()
b.append(4)
print(a)
print(b)
运行结果分道扬镳(反正不考成语了哈哈哈哈嗝):
[1, 2, 3]
[1, 2, 3, 4]
无需过多解释,时间复杂度为
O
(
n
)
O(n)
O(n)。
程序:三打构造函数,打成 250
a = [1, 2, 3]
b = list(a)
b[1] = 250
print(a)
运行结果。孬,孬,这打了不起效:
[1, 2, 3]
count 方法
程序:找 1
sequence = ['いちにさん', 1, 2, 3, 1, 2, 3, [1, 2, 3]]
print(sequence.count(1))
print(sequence.count('いち'))
运行结果:
2
0
C++ 的 vector 没有 count 方法。显然,count 方法的时间复杂度为
O
(
n
)
O(n)
O(n)。
extend 方法
程序:机不容十
sequence = [1, 2, 3]
print(sequence.extend([4, 5, 6]))
print(sequence)
sequence += [7, 8, 9]
print(sequence)
print(sequence + [10])
运行结果:
None
[1, 2, 3, 4, 5, 6]
[1, 2, 3, 4, 5, 6, 7, 8, 9]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
显然,extend 方法的时间复杂度为
O
(
n
)
O(n)
O(n)。在 C++ 中,有一种说法,认为 a += b 比 a = a + b 更快,后来被 O2 证伪了,不过,在 Python 中,sequence.extend(['fake']) 确实比 sequence = sequence + 'fake' 更快,因为后者会多创建一个列表的拷贝。
index 方法
index(val, [start], [stop]) 返回在列表的
[
s
t
a
r
t
,
s
t
o
p
)
[\mathrm{start}, \mathrm{stop})
[start,stop) 中第一个 val 的下标,若 val 不存在,将抛出异常。为了防止抛出异常,可以使用 in 运算符或者使用 count 方法进行检查。显然,时间复杂度为
O
(
n
)
O(n)
O(n)。注意,这里并不能用负数来表示下标,用负数表示下标的方式只能在列表的 [] 运算符中使用。
程序:爸爸去哪儿
Earth = ['你', '爸爸', '爷爷']
print(Earth.index("你", 0, 3))
del Earth[1]
print(Earth.index("爸爸", 1))
运行结果:
0
Traceback (most recent call last):
File "demo.py", line 4, in <module>
print(Earth.index("爸爸", 1))
ValueError: '爸爸' is not in list
insert 方法
insert(index, val) 方法在下标为 index 的元素前插入一个 val。
程序:插队青年
Queue = ['甲', '乙', '丙']
Queue.insert(2, '青年')
print(Queue)
运行结果:
['甲', '乙', '青年', '丙']
显然时间复杂度为
O
(
n
)
O(n)
O(n)。
pop 方法
程序:一个 C++ 程序员说自己只能写一行代码
std::cout << Vector.back() << std::endl; Vector.pop_back();
程序:Python 得换行,一行抵两行
print(Vector.pop())
时间复杂度显然为
O
(
1
)
O(1)
O(1)。
什么你问我 pop 是什么?你猜。
什么你问我怎么 push?当然只能创建一个大小比原来的大 1 的新的列表咯[~](#append 方法)隔。
remove 方法
remove 用于删除第一个为指定值的元素,返回 None。
程序:真假 123
sequence = [1, 2, 3, 'いち', 'に', 'さん', 1, 2, 3]
print(sequence)
sequence.remove(2)
print(sequence)
sequence.remove(2)
print(sequence)
sequence.remove(2)
运行结果:
[1, 2, 3, 'いち', 'に', 'さん', 1, 2, 3]
[1, 3, 'いち', 'に', 'さん', 1, 2, 3]
[1, 3, 'いち', 'に', 'さん', 1, 3]
Traceback (most recent call last):
File "demo.py", line 7, in <module>
sequence.remove(2)
ValueError: list.remove(x): x not in list
时间复杂度显然为
O
(
n
)
O(n)
O(n)。另外,remove 不能指定搜索范围。
reverse 方法
是个时间复杂度显然为
O
(
n
)
O(n)
O(n) 的好东西。
程序:三、二、一!
sequence = ['いち', 'に', 'さん']
sequence.reverse()
print(sequence[0] + '、' + sequence[1] + '、' + sequence[2] + '!')
运行结果:
さん、に、いち!
重头戏:sort 方法与 sorted 函数
程序:排序
sequence = [3, 1, 4, 1, 5, 9, 2, 6]
print(sorted(sequence))
print(sequence)
print(sequence.sort())
print(sequence)
运行结果:
[1, 1, 2, 3, 4, 5, 6, 9]
[3, 1, 4, 1, 5, 9, 2, 6]
None
[1, 1, 2, 3, 4, 5, 6, 9]
显然时间复杂度为
O
(
n
log
n
)
O(n \log n)
O(nlogn),并且还是稳定排序。对 sorted 函数而言,其返回的内容一定是个列表,但它的参数不一定是列表,这一点我们以后再说。
虽然看上去 sort 和 sorted 没有其他参数了,但事实上还能继续指定。
程序:度长絜大
sequence = ['1', '2', '3', 'one', 'two', 'three', 'いち', 'に', 'さん']
print(sorted(sequence))
print(sorted(sequence, reverse = True))
print(sorted(sequence, key = len, reverse = True))
print(sorted(sequence, reverse = False, key = len))
运行结果:
['1', '2', '3', 'one', 'three', 'two', 'いち', 'さん', 'に']
['に', 'さん', 'いち', 'two', 'three', 'one', '3', '2', '1']
['three', 'one', 'two', 'いち', 'さん', '1', '2', '3', 'に']
['1', '2', '3', 'に', 'いち', 'さん', 'one', 'two', 'three']
稳定排序的效果可见一斑。有关 key 的使用,将在后面讨论。
2. 元组
元组(tuple)与列表的一个重要区别是,元组是不能修改的。
元组的表示方法
程序:“这括号君便就是元组了”
sequence = 1, 2, 3
print(sequence)
sequence = (1, 2, 3)
print(sequence)
print((1, 2, 3))
print(1, 2, 3)
print()
print(())
print((1))
print((1, ))
print(1, )
运行结果:
(1, 2, 3)
(1, 2, 3)
(1, 2, 3)
1 2 3
()
1
(1,)
1
- 用
(x, y, ...) 的形式表示元组; - 若元组是空的,那么用
() 表示; - 若元组中只有一个元素,那么用
(x, ) 的形式表示; - 如果
x, y, ... 这种写法没有其他意图,那么 x, y, ... 等价于 (x, y, ...)。
元组的使用
① 索引
程序:三太爷爷抗日战争时期投奔资本主义,曾孙被广大网友拒之门外
figure = ('Peter', '特别皮')
print(figure[0])
figure[1] = '顾念祖'
运行结果:
Peter
Traceback (most recent call last):
File "demo.py", line 3, in <module>
figure[1] = '顾念祖'
TypeError: 'tuple' object does not support item assignment
② 其他方法
相比 list,tuple 只有 index 和 count 方法可用。这不难理解,因为所有的修改序列的方法对元组而言都是禁忌,而 copy 方法在元组面前显得没有意义。
③ 为什么要有元组
大家都知道加了 const 更安全些,不是吗?
不完全是。其实使用元组最主要的原因是,有时某些量需要以一个不能被修改的量的形式存在。比如,当你把一个元素放入集合中后,你就不能修改它了;作为替代方案,你只能插入一个新元素,再把要修改的元素删除,以达到修改的目的。否则平衡树就会被颠覆,数据结构将会陷入错误。
3. 切片
切片是什么
程序:切了皮特
figure = '顾念祖'
print(figure[1:3])
print(figure[-2:-1])
print(figure[-2:0])
print(figure[-2:])
运行结果:
念祖
念
念祖
切片(slicing)用来访问特定范围内的元素,用两个索引加冒号分隔。简而言之,切片遵循左闭右开的原则。当使用负数时,仍然是第一个索引代表第一个元素的编号,第二个索引代表最后一个元素后面的那个元素的编号。
- 若第二个索引与第一个索引相同或着在第一个索引的前面,那么结果是一个空的列表;
- 若省略第一个索引,代表从头开始;若省略第二个索引,代表包含最后一个元素结束。
若序列是一个列表,那么切片的结果也是一个列表;若序列是一个元组,那么切片的结果也是元组。
步长
程序:步长
sequence = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(sequence[::2])
print(sequence[::3])
print(sequence[::-1])
print(sequence[::-4])
print(sequence[::])
print(sequence[0:10:-1])
print(sequence[10:0:-1])
print(sequence[9:0:-1])
print(sequence[9::-1])
print(sequence[::0])
运行结果:
[1, 3, 5, 7, 9]
[1, 4, 7, 10]
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
[10, 6, 2]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
[]
[10, 9, 8, 7, 6, 5, 4, 3, 2]
[10, 9, 8, 7, 6, 5, 4, 3, 2]
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
Traceback (most recent call last):
File "demo.py", line 11, in <module>
print(sequence[::0])
ValueError: slice step cannot be zero
当步长为负数时,第一个索引必须比第二个索引大,但仍然是第一个索引包含在切片内,而第二个索引不被包含。此时,第一个元素一定是第一个索引对应的元素。
大切片能屈能伸
程序:切片删除与赋值
sequence = [1, 2, 3]
sequence[3:] = ['いち', 'に', 'さん']
print(sequence)
del sequence[::-3]
print(sequence)
sequence[0:2] = [0]
print(sequence)
sequence[0:0] = ['-2', '-1']
print(sequence)
sequence[::4] = [None, None]
print(sequence)
sequence[-2:0:-1] = [-1, 0, 1]
print(sequence)
sequence[::2] = [None, None]
运行结果:
[1, 2, 3, 'いち', 'に', 'さん']
[1, 2, 'いち', 'に']
[0, 'いち', 'に']
['-2', '-1', 0, 'いち', 'に']
[None, '-1', 0, 'いち', None]
[None, 1, 0, -1, None]
Traceback (most recent call last):
File "demo.py", line 14, in <module>
sequence[::2] = [None, None]
ValueError: attempt to assign sequence of size 2 to extended slice of size 3
del 运算符作用在切片上很好理解。对切片赋值,分成两种情况:
- 步长为 1 时,将赋予的序列硬生生地对原切片对应序列进行替换;
- 当步长不为 1 时(-1 也属于这种情况),将每个元素根据用于赋值的序列中的元素进行一一替换,这要求用于赋值的序列的长度与切片长度相等。
细细研究以上运行结果,你会明白的。
七、字符串
1. 字符串不可修改
这的确很令人沮丧,C++ 中的 std::string 可不像这样傲娇。但在 Python 中,字符串确实与元组类似,不可修改。
程序:百度确实已死
String = '百度已死'
String[2] = '未'
运行结果:
Traceback (most recent call last):
File "demo.py", line 2, in <module>
String[2] = '未'
TypeError: 'str' object does not support item assignment
2. 字符串方法
center 方法
程序:强调百度已死
String = '百度已死'
print(String.center(19))
print(String.center(19, ' '))
print(String.center(19, '*'))
print(String)
print('BaiduHasDied'.center(19, '*'))
print(String.center(19, '**'))
运行结果:
百度已死
百度已死
********百度已死*******
百度已死
****BaiduHasDied***
Traceback (most recent call last):
File "demo.py", line 7, in <module>
print(String.center(19, '**'))
TypeError: The fill character must be exactly one character long
在 Python 中,没有单独的字符类型,直接使用只含一个字符的字符串表示字符即可。另外还有一些方法与这种格式有关:ljust、rjust、zfill,可以参考 Python 帮助。
程序:查看帮助
help(str.zfill)
运行结果:
Help on method_descriptor:
zfill(self, width, /)
Pad a numeric string with zeros on the left, to fill a field of the given width.
The string is never truncated.
find 方法
find 方法与 in 运算符类似,在字符串中查找子串。不同的是,in 运算符返回一个布尔值,而 find 方法返回一个字串的第一个字符的索引。如果没有找到,返回 -1。
还可以指定搜索的起点和终点。需要注意的是,依然满足左闭右开区间。
程序:KMP 算法显神威
String = "KMP 算法显 KMP 神威"
print(String.find('KMP'))
print(String.find('KMP', 1))
print(String.find('KMP', 8, 11))
print(String.find('KMP', 8, -1))
print('length = ' + str(len(String)))
print(String.find('KMP', 0, 16000000000))
运行结果:
0
8
8
8
length = 14
0
可见 find 函数对参数有一定的容错机制。
还记得列表有一个 index 方法吗?功能与 find 方法相同,但是找不到不会返回 -1,而是会发生错误。字符串也有一个叫做 index 的方法,与列表的相同。但不幸的是,列表没有 find 方法。
另外,还有一些类似的方法:rfind、rindex、count、startswith,endswith。
程序:KMP 数 KMP
String = 'KMP 算法显 KMP 神威'
print(String.startswith('KMP'))
print(String.count('KMP'))
运行结果:
True
2
lower、upper、islower、isupper
方法 lower 将字符串中所有的大写字母转换成小写字母,而方法 upper 将字符串中所有的小写字母转换成大写字母。
以 is 开头的函数用于进行检验。islower 检验所给字符串是否均为小写字母,相应地,isupper 用于检验所给字符串是否均为大写字母。
程序:大小写
UpperOne = 'PETER'
LowerOne = 'peter'
NormalOne = 'Peter'
print(UpperOne.isupper())
print(LowerOne.islower())
print(NormalOne.isupper())
print(NormalOne.islower())
print(NormalOne.upper())
print(NormalOne)
运行结果:
True
True
False
False
PETER
Peter
replace 方法
方法 replace 将所有指定子串都替换为另一字符串,并返回替换后的结果。
程序:啊啊怪
Origin = 'aaaaa'
print(Origin.replace('aa', 'あ'))
运行结果:
ああa
strip 方法
strip 方法用于删除字符串开头和结尾的空白,返回删除后的结果。还可以通过字符串的形式指定要删除的其他字符。
程序:What does Peter say?
String = ' Peter! '
print(String.strip(' !'), String.strip())
运行结果:
Peter Peter!
与之类似的方法还有:lstrip、rstrip。
3. 字符串格式设置
C++ 路线 - % 运算符
程序:C++ 坐船头
#include <cstdio>
#include <cmath>
int main()
{
const char str[] = "PI";
const double pi = std::acos((double)-1);
printf("%s is approximately %.7lf", str, pi);
return 0;
}
程序:Python 岸上走
String = 'PI'
from math import pi
print("%s is approximately %.7f" % (String, pi))
运行结果如出一辙:
PI is approximately 3.1415927
使用 str % tuple 的形式得到格式化后的字符串。注意元组的元素个数必须与字符串的所需个数一致,否则将会报错。
Python 路线 - format 方法
使用字符串的 format 方法实现其格式化,format 返回格式化后的字符串。
程序:够你用的 format
String = 'PI'
from math import pi
print("{String} is approximately {PI:.7f}".format(String = String, PI = pi))
print("{} is approximately {:.7f}".format(String, 3))
print("{}{:f}".format(3))
运行结果:
PI is approximately 3.1415927
PI is approximately 3.0000000
Traceback (most recent call last):
File "demo.py", line 5, in <module>
print("{}{:f}".format(3))
IndexError: tuple index out of range
程序:format 的参数是元组吗?
print("{0} {0:f}".format(3))
运行结果:
3 3.000000
没错,可以把 format 的参数看成一个 tuple,然后手动提供编号。需要注意的是,如果不提供编号,将会被依次自动编号,这意味着给定的参数可以多(这与 C++ 路线不同),但不能少。但是不能自动编号和手动编号混用,否则会报错。
程序:再探 format 编号规则
>>> print("{pi} {1} {0:f}".format(3, 3.14, pi = 3.1415))
3.1415 3.14 3.000000
>>> print("{pi} {1} {0:f}".format(3, pi = 3.1415, 3.14))
SyntaxError: positional argument follows keyword argument
>>> print("{pi} {1} {0:f} {2}".format(3, 3.14, pi = 3.1415))
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
print("{pi} {1} {0:f} {2}".format(3, 3.14, pi = 3.1415))
IndexError: tuple index out of range
该程序表明:必须把没有命名的放在前面,没有命名的形成一个元组,命了名的不在元组内。
格式说明
有关其他类型说明符,与 C++ 是类似的,但又有少许区别(如可以用 b 表示二进制数;不存在 lf 这样的类型说明符),这里不再赘述。并且在前面的例程中,已经给出了几个最重要的用法,可以仔细研究前面三个例程中的格式说明方式。
程序:探寻几个重要的格式说明
print("No. %05d" % 1)
print("No. {:05d}".format(1))
print()
print("Level: %010.5f" % (12.34, ))
print("Level: {:10.5f}".format(12.34))
print()
print("Binary Code: {code:b}".format(code = 127))
print("Binary Code: {code:#b}".format(code = 127))
print("{{{}}}".format('End'))
输出结果:
No. 00001
No. 00001
Level: 0012.34000
Level: 12.34000
Binary Code: 1111111
Binary Code: 0b1111111
{End}
还有很多其它的格式说明,这里不再赘述,可以上网查阅。
input 函数与 split 方法
input 函数将返回用户输入的一行字符串,可以提供一个参数作为对用户的提示信息。
split 方法将默认在单个或多个连续的空白字符(空格、制表符、换行符等)处进行拆分,返回一个列表。
第一个有用的程序:我小学时写的图形帮手
String = input("Input the width and the height of the rectangle"\
"(Use space as an interval): ")
List = String.split()
if len(List) != 2 :
print("You may have made it wrong!")
exit()
print("{:g}".format(float(List[0]) * float(List[1])))
运行结果:
Input the width and the height of the rectangle(Use space as an interval): 5 6.5
32.5
还能指定分隔符:
程序:拆分路径
print(r"C:\Windows\ System32".split('\\ '))
print(r"C:\Windows\System32".split('\\'))
运行结果:
['C:\\Windows', 'System32']
['C:', 'Windows', 'System32']
可以看出,这里指定参数的方法与 strip 的不同,split 是将它的参数看作一个完整的字符串的。
print 函数
print 函数可以自定义分隔符和结束字符串:
程序:我们中出了一个叛徒
print('a', 'A', '啊', '嘎', sep = "|あ|", end = '')
print('嘎')
print("我们中出了一个叛徒↑")
运行结果:
a|あ|A|あ|啊|あ|嘎嘎
我们中出了一个叛徒↑
还记得 format 方法吗?
SyntaxError: positional argument follows keyword argument
\large{\text{SyntaxError: positional argument follows keyword argument}}
SyntaxError: positional argument follows keyword argument
看来,这是 Python 中的一个语法规则。
八、条件结构、循环结构
1. 代码块
Python 的一大特点是,通过缩进来表示代码块,这与 C++ 中使用大括号表示代码块截然不同。这造成了一个问题:我们不能随意缩进了。缩进的结束意味着代码块的结束,而缩进的贸然开始将会导致运行错误。
2. 条件结构
在“第一个有用的程序:我小学时写的图形帮手”中,我们已经使用了一次 if,这里我们再多用几次,顺便把他的兄弟也用了。
程序:愚蠢的单词翻译
word = input("请输入英文:")
if word == 'night': print('よる')
elif word == 'read': print('よむ')
elif word == 'alcohol': print('おさけ')
elif word == 'drink': print('のむ')
elif word == 'you':
pass
else:
print('还没学,你就说!')
用 : 开始一个代码块,但首先要写一个 if 语句(或其它可以接代码块的语句,如 elif)。如果代码块有且仅有一句代码,可以将这句代码写在 : 后面。如果代码块真的一句代码都写不出来,那怎么办?像以上代码那样,用 pass 占位即可。
需要注意的是,如果你不用 elif,非要用 else if,那就只能这样写了:
程序:愚蠢是没有下限的
word = input("请输入英文:")
if word == 'night': print('よる')
elif word == 'read': print('よむ')
elif word == 'alcohol': print('おさけ')
else:
if word == 'drink': print('のむ')
elif word == 'you':
pass
else:
print('还没学,你就说!')
因为这些语句后面都要接上一个代码块,而代码块必须以 : 开头,还得把缩进弄清楚,所以 elif 的存在就有理由了。
True or False
Python 中的所有内置类型都能自动转换成 bool 类型的值。一言以蔽之,空即是 False,不空即是 True。那表达式呢?
链式赋值
Python 支持链式赋值,但它不借助于 Python 的某个语法特性,而是 Python 一个单独的功能。
程序:Python 链式赋值
x = y = 'こんにちは!'
print(x, y)
运行结果:
こんにちは! こんにちは!
该程序与以下程序等价:
程序:Python 链式的好兄弟
x = 'こんにちは!'
y = x
print(x, y)
然而,该程序却与以下程序不同:
程序:Python 链式复制的死对头
#include <iostream>
#include <string>
int main()
{
using std::string;
string a, b;
a = b = "こんにちは!";
std::cout << a << ' ' << b;
return 0;
}
难道只是语言不一样吗?不是的,我们可以看一下 string 的 operator= 函数。
basic_string& operator=(_In_z_ const _Elem* const _Ptr);
别的都不用管,关键是,C++ 的赋值运算符实际上会“返回”一个引用,该引用指向链式复制最左边的那个元素。通过这个返回引用的机制,C++ 才实现了所谓的链式赋值。
程序:死对头有话说,“你会 C++ 吗?不会请看 一、”
#include <iostream>
#include <string>
int main()
{
using std::string;
string a, b;
(b = a = "こんにちは!") = "さようなら!";
std::cout << a << ' ' << b;
return 0;
}
运行结果:
こんにちは! さようなら!
程序:Python 捉襟见肘
>>> (b = a = 'こんにちは!') = 'さようなら!'
SyntaxError: invalid syntax
>>> if a = 'こんにちは!': print('はい')
SyntaxError: invalid syntax
增强赋值
就是 += 那一套啦!同链式赋值,Python 不会返回引用。
程序:Python 表示不服气,撞南墙,乃回
>>> y = 'こんにちは!'
>>> print(y *= 2)
SyntaxError: invalid syntax
要特别注意的是,Python 不支持自增自减运算符。
链式比较
Python 支持链式比较,对于 a < b == c <= d,其等价于 a < b and b == c and c <= d。
程序:链式比较真奇妙
a = 1
b = 2
c = 2
d = 1
e = 3
print(a < b == c)
print(a < b == c > d < e)
运行结果:
True
True
逻辑运算符
一元逻辑运算符
Python 中,逻辑非运算符用 not 表示,不能用 ! 表示。
in、not in、is、is not
前面我们已经介绍过 in 运算符,这里介绍一下它的否定形式 not in。它们之间的关系与 == 和 != 之间的关系相同。
is 运算符用于检验两个变量是否指向同一个对象,而 is not 运算符用于检验两个变量是否指向不同对象。
程序:月地检验
Moon = Apple = [1, 2, 3]
Newton = [1, 2, 3]
print(Moon is Apple, Moon == Apple)
print(Moon is not Newton, Moon != Newton)
运行结果:
True True
True False
过多的有关 is 运算符的内容,这里不再阐释。
二元逻辑运算符
与 not 的情况一样,Python 中不存在 && 和 ||,相应地,用 and 和 or 代替。计算时,满足短路逻辑。
位运算符
Python 中存在与 C++ 一样的位运算符:~、&、|、^、<<、>>,而且它们与 Python 的大整数特性并行不悖!
当整数的二进制位数不再有限制时,我们如何理解 ~ 运算符?难道要使无穷多的存在于高位的 0 变为 1 吗?考虑负数在计算机中的储存方式:在其相反数的二进制码的基础上取补码(各位取反后加一)。我们可以大胆猜测 ~ 运算符针对 Python 的整数在逻辑上有无穷多二进制位的实现:将给定数取相反数后,再减去 1。
程序:~-检验
num = int(input('输入一个整数,输出的是 True\n'))
print((~num) == (-num - 1))
对于移位运算符,完全可以将它们视为 * 2、// 2,无论正负。但是与 C++ 一样,应避免对负数进行移位操作。
三元运算符:条件表达式
程序:连中三元
scores = input('input scores:')
print('You are right.' if scores == '750' else 'You make it wrong.')
没错,A if B else C 与 C++ 中的 B ? A : C 等价。
断言
程序:虽然没什么用,但是大家应该都会吧
assert 1 == 1
assert 2 == 2, '您家处理器坏了'
需要注意的是,assert 是一个语句,而不是一个函数,因此不要加括号,否则会被翻译成元组,而此时的元组一定是非空的,Python 会友好地提示你,帮你报个警告:
demo.py:2: SyntaxWarning: assertion is always true, perhaps remove parentheses?
assert (2 == 2, '您家处理器坏了')
3. 循环结构
while 循环
while 循环是最简单的循环,简直可以叫做顾名思义。
程序:while 当 for
seq = [1, 1]
while len(seq) < 10000:
seq.append(seq[-1] + seq[-2])
i = len(seq) - 100
while i < len(seq):
print(seq[i], end = ' ')
i += 1
这个程序计算斐波那契数列的前 10000 项并打印这 10000 项中的最后 100 项。在学习了 while 后,你终于可编写计算量非常大的程序了,比如上面这个:请注意,Python 中的整数是大整数,所以我们只能算到 10000 项,否则计算机的内存甚至存不下计算出的结果!
for 循环
range 对象
range (目前)是个很奇怪的对象,我们先了解它的形式。
程序:range 遇 list
print(list(range(10)))
print(list(range(2, 10)))
print(list(range(1, 10, 3)))
print(list(range(10, 1, -3)))
运行结果:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[2, 3, 4, 5, 6, 7, 8, 9]
[1, 4, 7]
[10, 7, 4]
也就是说,range 有三种形式,并且与之前所学的一样,同样满足左闭右开原则,对负数有同样的处理方法。
程序:range 单枪匹马
print(range(10))
运行结果:
range(0, 10)
这样我们大概就能理解 range 的内涵了:range 本身不能生成一个数的序列,要通过别的途径(如把 range 作为 list 构造的参数)才能使 range 发挥作用,生成数的实体。换句话说,range 只负责生成,不消耗运算资源,那就可以放心地用在循环中了。
程序:range 遇 for
for i in range(1, 10 + 1):
print(i, end = ' ')
运行结果:
1 2 3 4 5 6 7 8 9 10
这个程序在不用列表的情况下输出了 1 到 10 的整数。
迭代列表
程序:C++ 时间到
#include <iostream>
#include <vector>
int main()
{
std::vector<int> seq = { 1, 2, 3, 4 };
for (const auto& t : seq)
std::cout << t << std::endl;
return 0;
}
程序:Python 显神威
seq = [1, 2, 3, 4]
for t in seq:
print(t)
运行结果差个回车,我就不写了。没错就是这么简单。
解包
程序:梦回最初交换变量
a = 1
b = 2
print(a, b)
a, b = b, a
print(a, b)
运行结果:
1 2
2 1
程序:浪潮起伏变量无数
seq = list(range(10))
a, b, *rest = seq
print(a, b)
print(rest)
运行结果:
0 1
[2, 3, 4, 5, 6, 7, 8, 9]
带 * 的变量将收集多余的变量,最后以列表的形式存在(哪怕只收集到 1 个元素,它还是列表)。显然,这时需要满足两个条件:
- 带
* 的变量至多只有一个,否则结果是不确定的; - 赋值号右侧的可迭代对象至少有左侧不带星号的变量那么多个。
什么是可迭代对象?list 是可迭代对象,其实 range 也是一个可迭代对象,因为 range 实际上是一个迭代器,迭代器的事,我们以后再说。
程序:range 描摹变量的黄土
a, b, *rest = range(10)
print(a, b)
print(rest)
不用解释,这个程序的结果与上面的程序是一样的,但是资源占用要少一个 list。
程序:解包踏上 for 的归途
seq = [('Alice', 10), ('Bob', 9), ('C++', 100), ('David', 8)]
for name, score in seq:
print('{} got {:d}'.format(name, score))
运行结果略。没错,就是这么简单。
zip 对象与并行迭代
程序:zip
name = ['Alice', 'Bob', 'C++', 'David', 'E Language', 'Frank']
score = (10, 9, 100, 8, 0)
print(zip(name, score))
print(tuple(zip(name, score)))
运行结果:
<zip object at 0x000001D55571A4C8>
(('Alice', 10), ('Bob', 9), ('C++', 100), ('David', 8), ('E Language', 0))
也就是说,zip 对象可以将多个序列的元素依次缝合成元组,结合解包,我们可以在不适用索引的情况下进行迭代。
程序:并行迭代
name = ['Alice', 'Bob', 'C++', 'David', 'E Language', 'Frank']
score = (10, 9, 100, 8, 0)
for n, s in zip(name, score):
print("{} got {:d}".format(n, s))
enumerate 对象
程序:enumerate 1
seq = [1, 2, 3]
for index, num in enumerate(seq):
print("seq[{}] = {}".format(index, num))
程序:enumerate 2
seq = [1, 2, 3]
seq2 = [2, 3, 4]
for index, tup in enumerate(zip(seq, seq2)):
print("seq[{0}] = {1} seq2[{0}] = {2}".format(index, tup[0], tup[1]))
enumerate 对象可以帮助你在进行迭代时使用索引,你将得到一个大小为 2 的元组。在结合 zip 对象使用时,zip 对象提供的元组不能直接解包(因为它是元组中的元组),你只能直接得到一个元组。
程序:enumerate 3
seq = [1, 2, 3]
seq2 = [2, 3, 4]
for raw in enumerate(zip(seq, seq2)):
print(raw)
运行结果:
(0, (1, 2))
(1, (2, 3))
(2, (3, 4))
reversed 迭代器
要反向迭代一个序列,使用 reversed 迭代器。
程序:reversed
seq = [1, 2, 3, 4, 5]
for t in reversed(seq):
print(t, end = ' ')
运行结果略。
循环结构语句
break 和 continue
break 和 continue 是个好东西,他们的使用方法没什么好说的。
循环结构中的 else
在循环中,可以随时通过 break 跳出循环。如果你想知道你是否是通过 break 跳出循环的,Python 可以帮你。在 Python 中,你可以在循环结构中使用 else,当循环退出不是通过调用 break 时,else 对应的代码块将会被执行,这会使问题简单许多。
程序:愚蠢的单词翻译 2
en = ('alcohol', 'read', 'vegetables', 'night', 'wear')
jp = ('おさけ', 'よむ', 'やさい', 'よる', 'きる')
dic = tuple(zip(en, jp))
word = input("type English word:")
for e, j in dic:
if e == word:
print(j)
break
else:
print("not found!")
这样可以避免额外增加一个记录是否找到的变量。
另外的语句
pass 语句
啊想必这个东西大家都会了。
程序:pass or string
a = 1
if a == 2:
print("您家处理器坏了")
elif a == 1:
'验证成功之后干什么还没有想好'
else:
pass
既可以使用 pass 代表空代码块,也可以使用一个字符串占位。
del 语句
前面我们已经使用 del 语句删除列表中的元素,这里我们学习用 del 删除名称。
程序:del
x = y = [1, 2, 3]
print(x is y)
del x
print(y)
print(x)
运行结果:
True
[1, 2, 3]
Traceback (most recent call last):
File "demo.py", line 5, in <module>
print(x)
NameError: name 'x' is not defined
可见,Python 使用了引用计数。del 语句只是删除了名称,无法删除名称指向的列表。当没有名称指向列表时,列表将被自动删除,表面上 del 语句便删除了名称和列表。
九、函数(一)
1. 内置函数 callable
要判断某个对象是否可调用,可使用内置函数 callable。
程序:callable
print(callable(callable))
print(callable(list))
print(callable('function'))
运行结果:
True
True
False
也就是说,能调用的对象不一定是函数,也可以是类。
2. 定义函数 def
用 def 语句定义函数。
程序:def
def swap(a, b):
return (b, a)
a = 1
b = 2
a, b = swap(a, b)
print(a, b)
运行结果略。
文档字符串
放在函数开头的字符串将作为函数的一部分储存起来,称之为文档字符串。文档字符串相当于函数的注释信息,但是它与 Python 紧密联系,甚至可以用 help 函数获取其它函数的文档字符串。
文档字符串其实是函数的一个属性,名为 __doc__,因此,可以用 func.__doc__ 的形式访问函数的文档字符串。
程序:文档字符串
def swap(a, b):
'What will be returned is a tuple.'
return (b, a)
help(swap)
print(swap.__doc__)
运行结果:
Help on function swap in module __main__:
swap(a, b)
What will be returned is a tuple.
What will be returned is a tuple.
void 与 None
C++ 中的 void 型函数(或 VB 中的过程),在 Python 中如何表示呢?由于 Python 是动态类型语言,函数不会显示指定返回值类型,因此直接模仿 C++ 是行不通的,但是我们可以从 return 语句下手。
程序:return
def voidFunc():
return
voidFunc()
这就制造了一个 “void” 型的函数。实际上,Python 的所有函数都有返回值,对于直接写 return 的函数,实际上返回了一个 None。
程序:voidFunc
def voidFunc(): return
print(voidFunc() == None)
输出 True。
3. 参数
Python 的参数也不指定类型。
是否是引用?
程序:swap 于 C++
template<typename T>
void swap(T& a, T& b)
{
T t = a;
a = b;
b = t;
}
Python 中?没办法,你不能指定引用,传进来的参数都是值。
但目前来讲,list 除外,因为 list 的赋值本身就不是拷贝,而是引用。
程序:swap 于 Python
def wrongSwap(a, b):
t = a
a = b
b = t
def swap(lst):
t = lst[0]
lst[0] = lst[1]
lst[1] = t
lst = [1, 2]
swap(lst)
print(lst)
程序:放开函数
lst = [1, 2]
param = lst
t = param[0]
param[0] = param[1]
param[1] = t
del param
print(lst)
位置参数、关键字参数与默认参数
程序:5 个 W
def novel(what, where, when, why, who = 5):
pass
novel(1, 2, 3, 4, 5)
你知道上面的 (1, 2, 3, 4, 5) 是什么意思吗?像这样,依次写下来的参数,叫做位置参数。位置参数的缺点很明显:你可能不知道各个参数是什么意思。
要解决这个问题,方法是使用关键字参数。
程序:还是 5 个 W
def novel(what, where, when, why, who = 5):
pass
novel(what = 1, where = 2, why = 4, when = 3, who = 5)
使用关键字参数时,位置无关紧要。
当结合使用位置参数和关键字参数时,位置参数必须位于关键字参数的前面,无论是定义时还是调用时。
程序:5 个 W,5 个 novel
>>> def novel(what, where, when, why, who = 5):
pass
>>> novel(1, 2, 3, why = 4)
>>> novel(1, 2, 3, 4, 5)
>>> novel(1, 2, 3, who = 4, why = 5)
>>> novel(1, 2, 3, when = 4, who = 5)
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
novel(1, 2, 3, when = 4, who = 5)
TypeError: novel() got multiple values for argument 'when'
>>> novel(1, 2, why = 3, 4, who = 5)
SyntaxError: positional argument follows keyword argument
可以指定默认参数,默认参数必须位于参数列表的末端。将默认参数与关键字参数结合,可以使函数的参数满足个性化需求。
收集参数
定义函数时,在其中一个非默认参数前面加上一个 *,则称这个参数为收集参数。
程序:收集参数
>>> def PrintParams(title, *params):
print(title)
print(params)
>>> PrintParams("params:")
params:
()
>>> PrintParams("params:", "没有参数")
params:
('没有参数',)
收集参数将以元组的形式存在。
在定义函数时,收集参数的后面还能够有其他参数,但这些参数都必须是关键字参数,称这些参数为强制关键字参数。收集参数不会收集关键字参数。
程序:强制关键字参数
>>> def func1(*params, key1, key2):
pass
>>> func1(1, 2)
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
func1(1, 2)
TypeError: func1() missing 2 required keyword-only arguments: 'key1' and 'key2'
>>> func1(1, key2 = 2)
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
func1(1, key2 = 2)
TypeError: func1() missing 1 required keyword-only argument: 'key1'
收集参数本身不能指定任何默认值,它的默认值始终是空元组,但是收集参数的前面可以有默认参数。由于收集参数的后面是强制关键字参数,因此在其前面有默认参数的情况下其后面的参数可以随意决定是否指定默认值,无论后面参数的顺序。
因为收集参数不能是关键字参数,所有收集参数的前面实际上必须是位置参数。
可以不指定收集参数的形参名,在这种情况下,其后面必须有至少一个强制关键字参数。
十、字典
字典是 Python 的一个内置的 unordered_map,因此访问它的时间复杂度为
O
(
1
)
O(1)
O(1)。
1. 字典的表示
字典的键(key)与值(value)
显然,字典的值可以是任意类型。而字典的键可以是任何不可变的类型,如整数(int)、浮点数(float)、字符串(str)、元组(tuple)。并且由于字典的本质是一个哈希表,因此字典的键必须是可哈希的,这里我们只需知道上面提到的四种类型都可以作为字典的键即可。
内置表示方式
程序:我的第一本字典
MyFirstDict = {'house': 'いえ',
'room': 'へや',
'cloudy': 'くもり',
'dog': 'いぬ',
'cat': 'ねこ',
'bird': 'とり',
'outside': 'そと'}
print(MyFirstDict)
运行结果:
{'house': 'いえ', 'room': 'へや', 'cloudy': 'くもり', 'dog': 'いぬ', 'cat': 'ねこ', 'bird': 'とり', 'outside': 'そと'}
正如以上代码,Python 中的字典用大括号 {} 表示。其中的元素用 key: value 的格式表示。对于空字典,用一个空的大括号表示({})。
通过构造函数创建字典
程序:字典不够,列表来凑
FakeDict = [('sunny', 'はれ'),
('summer', 'なつ'),
('winter', 'ふゆ')]
MySecondDict = dict(FakeDict)
print(MySecondDict)
print(dict([('back', 'せなか'), ('eye', 'め')]))
print(dict([(1, 2, 3)]))
运行结果:
{'sunny': 'はれ', 'summer': 'なつ', 'winter': 'ふゆ'}
{'back': 'せなか', 'eye': 'め'}
Traceback (most recent call last):
File "demo.py", line 8, in <module>
print(dict([(1, 2, 3)]))
ValueError: dictionary update sequence element #0 has length 3; 2 is required
如以上程序,可以通过列表来构建字典,要求列表的所有元素都是二元的元组,元组的第一个元素作为键,元组的第二个元素作为值。
程序:列表不够,关键字参数来凑
>>> MyThirdDict = dict(ear = 'みみ')
>>> print(MyThirdDict)
{'ear': 'みみ'}
>>> dict(2 = 'に')
SyntaxError: keyword can't be an expression
>>> dict('6' = 'ろく')
SyntaxError: keyword can't be an expression
如以上程序,可以使用关键字参数来构建字典,但是这样的话键必须是符合变量命名要求的字符串。这里实际上用到了前面《函数(一)》中没有讲解的收集关键字参数。前面讲了位置参数的收集,并且知道了位置参数是用元组的形式保存的。事实上,关键字参数也可以收集,并且是以字典的形式保存的。
2. 字典的相关操作
① 函数 len
通过调用 len(d) 获取字典 d 包含的“键-值对”数。
② d[k]
用 d[k] 的形式可以获取与键 k 相关联的值;用 d[k] = v 的形式将值 v 关联到键 k。
程序:谁解其中味
dict1 = {}
dict1['author'] = '老曹'
print('The author is', dict1['author'])
print('He noted that', dict1['note'])
运行结果:
The author is 老曹
Traceback (most recent call last):
File "demo.py", line 4, in <module>
print('He noted that', dict1['note'])
KeyError: 'note'
相信大家也明白了,Python 没有什么返回一个引用之说的,唯一的引用就是赋值时默认使用引用的形式,其他地方都是有特定的语法的。如此处,d[k] 和 d[k] = v 应该是两个截然不同的语法,而不像 C++ 那样一个引用就了结。有关 Python 的具体语法规则,我们以后再深究。
由以上程序可知,使用 d[k] 的形式访问字典时,必须保证给定的键存在;使用 d[k] = v 修改字典时,若给定的键不存在,将会自动添加。
③ del d[k]
del d[k] 可以将 k 这个键及其对应的值从字典 d 中移除。
④ k in d
可以用 k in d 的形式判断键 k 是否存在于字典中。
⑤ 其他方法
clear
clear 方法删除字典中所有的元素。
copy 方法与 deepcopy 函数
copy 方法是浅复制,复制时对其中的值复制引用。deepcopy 方法是深复制,复制时对其中的值执行深复制。使用 deepcopy 函数时,需要将其从 copy 模块导入。
程序:copy
from copy import deepcopy
origin = {"dict1": {"dict2" : {"dict3": 0}}}
copy1 = origin.copy()
copy1["append"] = 1
copy1["dict1"]["dict2"]["dict3"] = 1
print(origin, copy1)
copy2 = deepcopy(copy1)
copy2["dict1"]["dict2"]["dict3"] = 2
print(origin, copy1, copy2)
运行结果:
{'dict1': {'dict2': {'dict3': 1}}} {'dict1': {'dict2': {'dict3': 1}}, 'append': 1}
{'dict1': {'dict2': {'dict3': 1}}} {'dict1': {'dict2': {'dict3': 1}}, 'append': 1} {'dict1': {'dict2': {'dict3': 2}}, 'append': 1}
fromkeys 方法
可以直接对 dict 类调用方法 fromkeys,效果是创建键于字典中,值默认为 None。也可以通过第二个参数指定默认值。
程序:未完成的字典
dict1 = dict.fromkeys(['one', 'five', 'eight', 'nine', 'ten'])
print(dict1)
print(dict1.fromkeys(('eleven', 'twelve')))
运行结果:
{'one': None, 'five': None, 'eight': None, 'nine': None, 'ten': None}
{'eleven': None, 'twelve': None}
get 方法
用于访问键值。不同于 [],在键不存在时 get 方法不会报错。
程序:get
dict1 = {0: 0}
print(dict1.get(0))
print(dict1.get(1))
print(dict1.get(2, 'not found!'))
运行结果:
0
None
not found!
items 方法
items 方法返回一个字典视图。字典视图是一种特殊的数据类型,可以把它看作字典的常量引用。items 方法返回的字典试图包含以 (key, value) 形式组织的所有项。
keys 方法
keys 方法返回一个字典视图,其中包含所有的 key。
values 方法
values 方法返回一个字典视图,其中包含所有的 value。
pop 方法
pop 方法可以获取某个键的值,并将这个键对应的项从字典中删除。
popitem 方法
popitem 方法随机获得一个键值对并将其从字典中删除。这在需要处理并删除字典中所有的项时尤其有用。
setdefault 方法
setdefault 方法获取与指定键相关联的值,并且在字典中不包含指定的键时,在字典中添加指定的键值对。如果不指定默认值,默认为 None。
update 方法
update 方法的参数提供一个字典,然后用该字典中的值替换原字典中的值。如果原字典中不存在对应的键,就创建它。
3. 作用域
vars 函数
vars 函数返回一个字典,这个字典称为命名空间或作用域。
程序:vars
def ViewVars():
print(vars())
print(vars())
ViewVars()
运行结果:
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'demo.py', 'ViewVars': <function ViewVars at 0x000002E98C1DC1E0>}
{}
除全局作用域外,每个函数调用都将创建一个作用域。
globals 和 locals 函数
这两个函数分别返回包含全局变量和局部变量的字典。
程序:global 1
def incx():
globals()['x'] += 1
x = 1
incx()
print(x)
运行结果:
2
还可以通过 global 关键字告诉 Python 我们在使用全局变量。
程序:global 2
def incx():
global x
x += 1
x = 1
incx()
print(x)
运行结果:
2
如果要使用 global x,那么在这个函数中就无法将局部变量命名为 x,否则会报错。
十一、类
类在 Python 中使用 class 表示。
1. 类的实质于 Python
程序:第一个类
class FirstClass:
content = "I am first!"
def Announce(self):
print(FirstClass.content)
obj1 = FirstClass()
obj1.Announce()
你肯定会想以下问题:
- 那个
content 难道不是属于 obj1 的?为什么要写 FirstClass? - 那个
self 是不是可以省略?
事实上,定义类的过程实际就是执行类里面的代码的过程,这些代码是在一个特殊的命名空间内执行的,这个命名空间叫做类的命名空间。
程序:一个特殊的类
class SpecialClass:
n = int(input())
strs = []
for i in range(n):
strs.append(input())
print(strs)
def printSpecialClass(self):
print(SpecialClass.n, SpecialClass.strs)
obj = SpecialClass()
obj.printSpecialClass()
至此,你也大概猜出来了,第一个类中的 content 确实不属于一个对象,它属于一整个类。要访问这样的变量,分为两种情况:如果当前命名空间就是类的命名空间,直接输入它的名字就能访问它了;否则,用 类名.变量名 访问它。
2. self 与没有 self
Python 类中的函数没有默认是什么函数之说,不管你写不写 self,毕竟 self 也并不是 Python 的一个关键字,你取名为 this 也是可以的。
程序:self 与 this
class MyClass:
def func1(self):
print(self)
def func2(this):
print(this)
def func3(a, b):
print(a + b)
a = MyClass()
a.func1()
a.func2()
MyClass.func3(1, 2)
a.func3(1, 2)
运行结果:
<__main__.MyClass object at 0x0000021B7A204320>
<__main__.MyClass object at 0x0000021B7A204320>
3
Traceback (most recent call last):
File "demo.py", line 15, in <module>
a.func3(1, 2)
TypeError: func3() takes 2 positional arguments but 3 were given
也就是说,对于对象调用类里面的函数,Python 会自动传入把对象作为第一个参数传入;如果是类调用类里面的函数,Python 就不会额外自动传入参数。
那么在类里面的函数它们本身该怎么处理呢?
程序:会无限递归吗?
class MyClass:
def func1(self):
print(self)
def func2(this):
print(this)
def func3(a, b):
print(a + b)
func3(a, b)
MyClass.func3(1, 2)
运行结果:
3
Traceback (most recent call last):
File "demo.py", line 12, in <module>
MyClass.func3(1, 2)
File "demo.py", line 10, in func3
func3(a, b)
NameError: name 'func3' is not defined
好吧,发生错误了……在类里的函数中,调用类里的函数必须指定类名,或者指定对象(一般就是第一个参数)。
那如果我要指定一个函数是静态函数,该怎么办捏?
程序:静态方法
class MyClass:
@staticmethod
def func1():
print("はい")
a = MyClass()
MyClass.func1()
a.func1()
运行结果:
はい
はい
那如果我要指定一个函数是成员函数,该怎么办捏?
应该没有这个必要吧……
3. 类的成员变量与静态变量
静态变量很简单,之前我们已经见过了。
成员变量呢?很遗憾,我们不能提前定义它们,它们和一般的变量一样,会在第一次赋值时保存于对象内。
而且,外部可以随意访问对象对应的那个“魔法字典”。
程序:Magic
class Magic:
pass
a = Magic()
a.first = 1
a.second = 2
print(a.first, a.second)
运行结果:
1 2
4. 类的构造函数、析构函数
类的构造函数形如:def __init__(self, ...)。析构函数形如:def __del__(self, ...)。
程序:自动构造与析构
class CreatureObject:
nBorn = 0
nDead = 0
def __init__(self, name = ''):
self.name = name
self.age = 0
CreatureObject.nBorn += 1
print("%s is born" % self.name)
def __del__(self):
CreatureObject.nDead += 1
print("%s is dead at the age of %d" % (self.name, self.age))
def incAge(self):
self.age += 1
a = CreatureObject("a")
a.incAge()
a.incAge()
a.incAge()
def Createb():
b = CreatureObject("b")
b.incAge()
Createb()
运行结果:
a is born
b is born
b is dead at the age of 1
a is dead at the age of 3
注意,最后一行输出后程序会立即结束。如果程序没有结束,你是看不到最后一行输出的。
由于 Python 的每个对象有个引用计数,如果其他人让引用计数增加,你就不能准确知道一个对象会在什么时候被销毁,因此尽可能不要使用 __del__。如果要用,其实是与 C++ 类似的。有一个区别是,Python 在退出代码块时不一定会销毁对象,只有在退出当前函数时才会。
至此,你已经可以用 Python 写基本的程序了,接下来,有请《Python 学习笔记——进阶》登台表演。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)