语音合成时,选取的朗读文本大多是网上收集来的TXT 文件,有些文件会因为编码原因打开不了,程序运行出错。
如同样是 “离骚.txt ”文档,用 with open('离骚.txt') as file: 则提示错误:
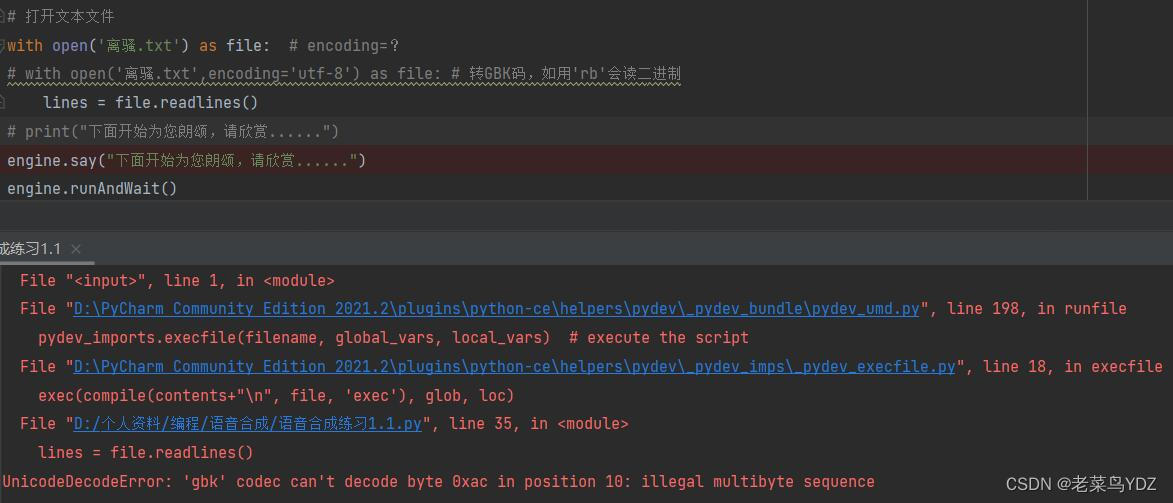
如换成 with open('离骚.txt',encoding='utf-8') as file: 则运行正常:

有些文档则相反,前一行代码可以正常运行,后一行代码则提示错误。 上图中程序正常运行时边读音边出现相应文字字幕,是我在里边加入了相关代码,这个留待以后解决。
究竟选择哪条代码,肯定是视文档编码而定。也可用代码来判断文档的编码,用if语句或try-except 来解决。
对普通人而言,判断文档编码过于复杂,可以手工对文档转码,根据我的试验,大多可行,也有少数不行的。有时一段古文,很多段文字都可以,只要加入某段文字就会出错,估计是里面有语音“不认识”的字在里面,感觉有点玄学了。
手工转码的方法,就是把TXT文档另存,在另存时选择其他编码,操作图示如下:

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)