一、安装插件
1.1搜索的方式安装:
setting中找到plugins插件,然后搜索big Data,如下图:

如果找不到可以修改几个配置试一下:


如果还是不行,你可以在cmd里面 ping plugins.jetbrains.com 一下
https://my.oschina.net/u/4359728/blog/3305115
1.2 第二种本地插件的安装(成功)
我的是2018版的IDE,还是搜不到,搜到了如下办法:
https://blog.csdn.net/weixin_43311978/article/details/105558773?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-5.control&spm=1001.2101.3001.4242
下载HadoopIntellijPlugin
github链接:
https://github.com/fangyuzhong2016/HadoopIntellijPlugin
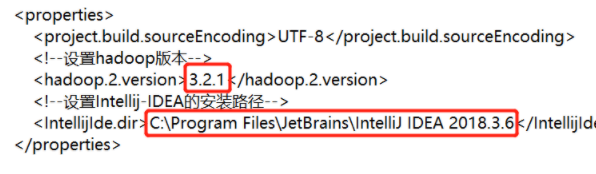
修改pom.xml文件
用记事本打开 pom.xml,将版本号改成你自己的 hadoop 版本号,路径改成你 idea 的安装路径
编译打包生成插件
打开 cmd,进入到解压的这个目录(可以直接在某文件夹上方地址栏输入cmd+回车,就会直接进入该目录)
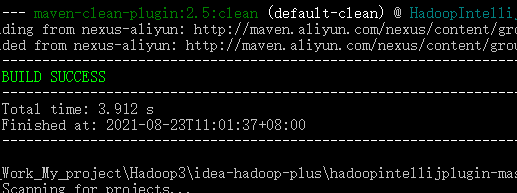
执行命令:mvn clean
可以看到 BUILD SUCCESS
接着执行:mvn assembly:assembly

在刚刚解压的目录可以看到多了一个 target 文件夹

idea 配置插件
打开 idea,Configure --> Settings

选择刚刚生成的 HadoopIntellijPlugin-1.0.zip (再次提醒是 zip 不是 jar)

然后重启 idea,可以看到hadoop项;
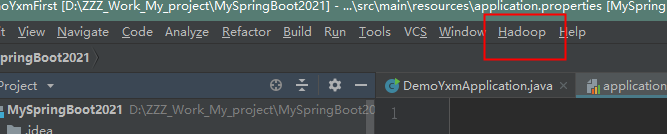
连接HDFS文件系统:


我填写了自己的IP,是连接失败;我本地电脑装了hadoop,所以我连接了本地地址127.0.0.1

好像连接成功:

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)