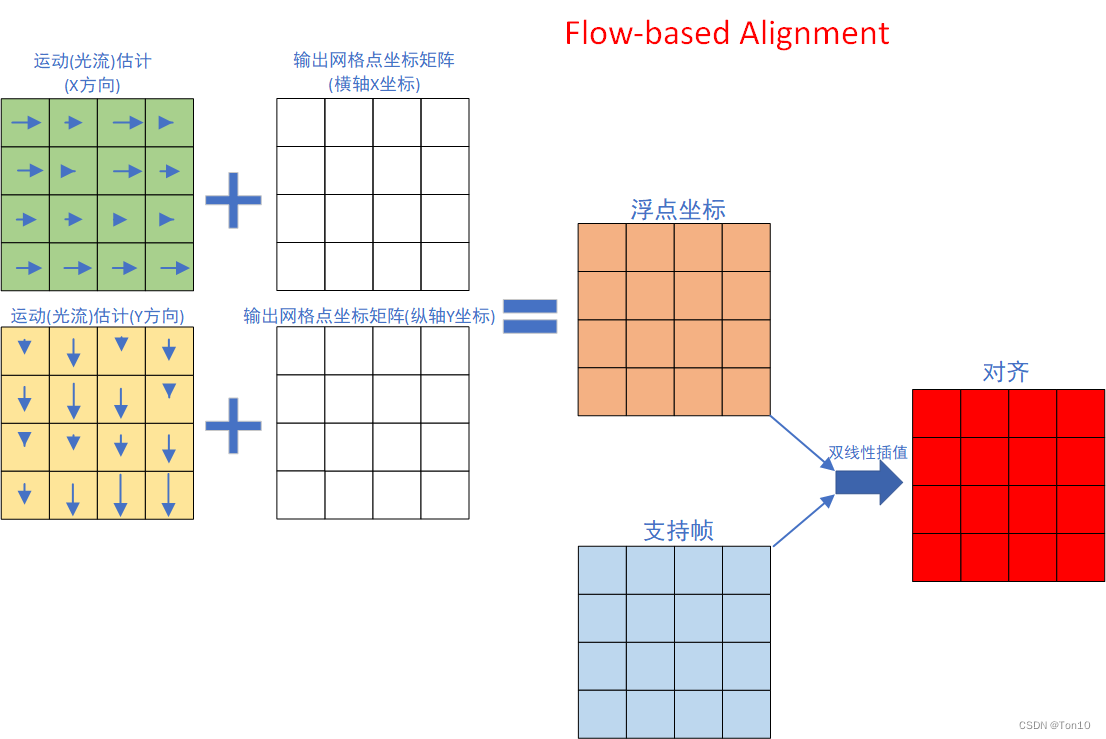
这篇文章着重研究了flow-free类对齐和flow-based类对齐之间的关系:①首先当DCN只学习1个offset的时候,它和flow-based对齐是高度相似的;②其次作者将DCN分解成一个spatial warping和1个3D卷积(或2D卷积),从而将DCN和flow-based对齐归纳成1个表达式,关键的区别只是在offset的个数上,flow-based相当于只有1个offset。这种新型的表达式既可以表示flow-based对齐,也可以表示DCN的对齐,此外,它的offset不像DCN那样限制死了——卷积核大小的平方,而是可以为任意数值
N
N
N,如当
N
=
1
N=1
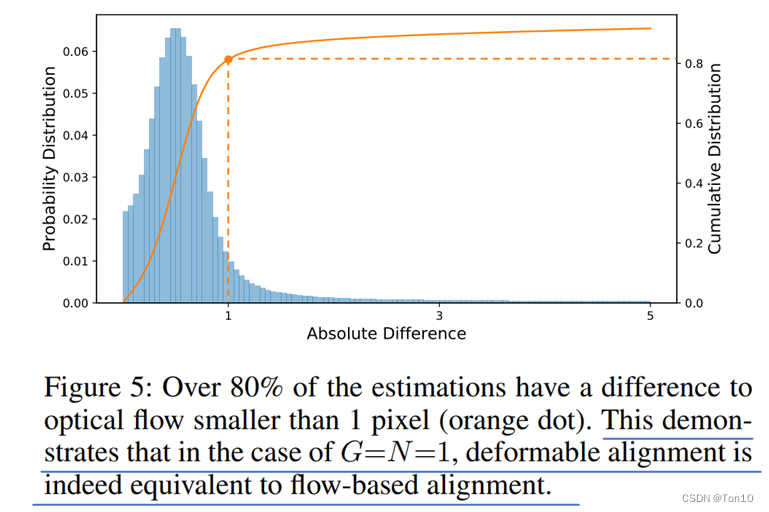
N=1表示flow-based对齐。
5帧视频可以看成是物体不动,摄像机沿着右下方移动;图1是在flow-based对齐方法中学习到的光流,比如VESPCN这种;图2和图4是DCN中同一个offset窗口内(大小为卷积核大小的平方)不同的offset;图3是纯flow-based,通过这篇文章PWC-Net: CNNs for Optical Flow Using Pyramid, Warping, and Cost Volume提出的PWCNet来计算光流;图5和图6分别是flow-based和flow-free最终的对齐feature map。 从实验中我们可以得出结论:
Flow-free vs Flow-based
\colorbox{hotpink}{Flow-free vs Flow-based}
Flow-freevsFlow-based ①基于DCN的对齐方式以强探索能力著称,可以有效应对遮挡、大运动问题(注意是缓解,而不是解决,想通过DCN解决大运动问题需要级联多个DCN且基于不同的分辨率做可变形卷积,即EDVR的做法)。 ②先不讨论特征校正的问题,Flow-based对齐每个位置的warp只取决于1个运动矢量,因此其高度依赖于运动估计的准确性,容错率较低,比flow-free更容易出现artifacts,虽然flow-free也会出现artifacts,但是其基于其较丰富的offset信息使得artifacts很少出现。 ③此外flow-based一般都是two-stage,速度相对较慢。
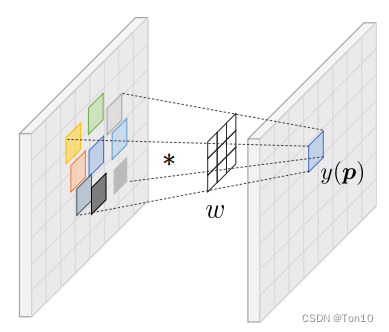
首先简要介绍下DCN,假设可变形卷积核为
3
×
3
3\times 3
3×3,
p
,
p
k
,
Δ
p
k
,
Δ
m
k
p,p_k,\Delta p_k,\Delta m_k
p,pk,Δpk,Δmk分别为输出点坐标;卷积核内第
k
k
k个位置,
p
k
∈
{
(
−
1
,
−
1
)
,
(
−
1
,
0
)
,
⋯
,
(
1
,
1
)
}
p_k\in \{(-1,-1),(-1,0),\cdots,(1,1)\}
pk∈{(−1,−1),(−1,0),⋯,(1,1)};offset;modulation mask。此外
n
n
n表示卷积核的大小,此处
n
=
3
n=3
n=3。 令
x
,
y
x,y
x,y表示输入和输出,则DCN-v2的表达式为:
y
(
p
)
=
∑
k
=
1
n
2
w
(
p
k
)
⋅
x
(
p
+
p
k
+
Δ
p
k
)
⋅
Δ
m
k
.
(1)
y(p) = \sum^{n^2}_{k=1} w(p_k) \cdot x(p+p_k+\Delta p_k) \cdot \Delta m_k.\tag{1}
y(p)=k=1∑n2w(pk)⋅x(p+pk+Δpk)⋅Δmk.(1)Note:
DCN-v2是DCN的进阶版,增加了modulation mask来控制offset的幅度且
Δ
m
k
∈
[
0
,
1
]
\Delta m_k\in [0,1]
Δmk∈[0,1],其相当于一种注意力机制,给予给DCN表现力增加最多的offset设置更多的权重。
实际操作中,我们会将输入的
C
C
C个通道进行分组卷积,假设为
G
G
G组,每组的通道数为
C
/
G
C/G
C/G,每组只学习1份深度为
n
2
n^2
n2的offset参数矩阵,因此一共学习
n
2
⋅
G
n^2\cdot G
n2⋅G张offset特征图。
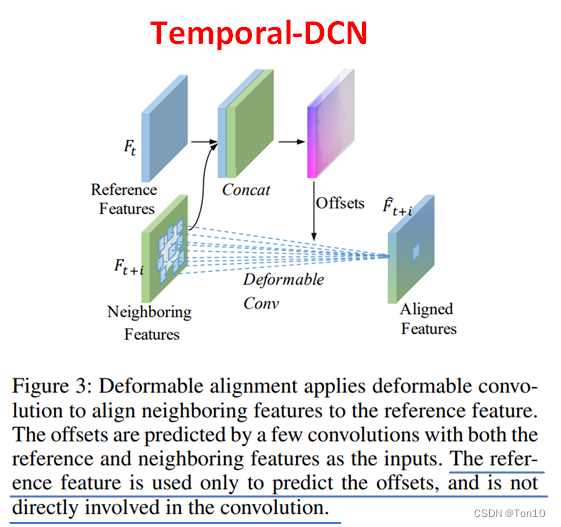
3.2 Deformable Alignment
根据TDAN、EDVR可知,DCN中offset的学习都是基于参考帧特征和支持帧特征的concat(或者说是Early fusion,时间融合的一种方式,利用了视频之间的时间相关性,而图像上的卷积由于是局部的,所以利用了图像的局部空间相关性。 VSR中的DCN属于一种变体,因为它的输入是时间相关的相邻帧,所以我称之为Temporal-DCN(TDCN),其示意图如下: 设
F
t
,
F
t
+
i
F_t,F_{t+i}
Ft,Ft+i分别为参考帧和支持帧,对齐的目的就是获取和参考帧对齐的对齐版本的支持帧
F
^
t
+
i
\hat{F}_{t+i}
F^t+i,所以是要在支持帧上进行空间变换,而offset是由参考帧和支持帧共同学习得到的,数学表达式如下:
F
^
t
+
i
(
p
)
=
∑
k
=
1
n
2
w
(
p
k
)
⋅
F
t
+
i
(
p
+
p
k
+
Δ
p
k
)
⋅
Δ
m
k
.
(2)
\hat{F}_{t+i}(p) = \sum^{n^2}_{k=1} w(p_k)\cdot F_{t+i}(p+p_k+\Delta p_k)\cdot \Delta m_k.\tag{2}
F^t+i(p)=k=1∑n2w(pk)⋅Ft+i(p+pk+Δpk)⋅Δmk.(2)Note:
参考帧只是作为一个标签,其只用于求取offset,并不在DCN学习的计算图中。
可以看出DCN的学习中,offset diversity是固定的,即卷积核大小的平方
n
2
n^2
n2。
3.3 Relation between Deformable Alignment and Flow-Based Alignment
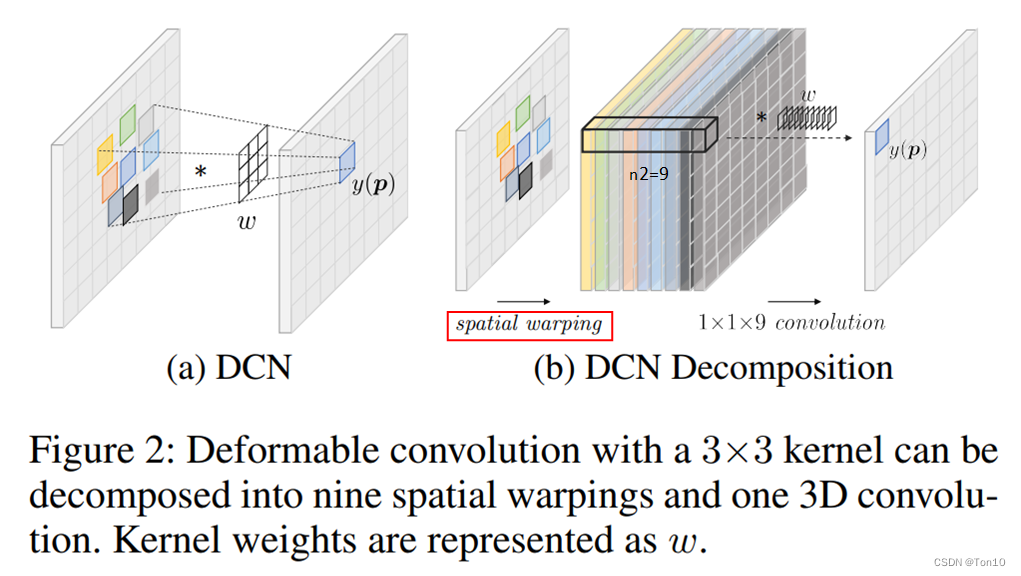
这一节开始介绍DCN类对齐方法和flow-based对齐的联系,作者将两种对齐方法用统一的表达式进行描述。具体而言,两种对齐的联系可通过将DCN的过程分解成1个spatial warping和1个3D卷积的过程来刻画。 令
x
k
(
p
)
=
x
(
p
+
p
k
+
Δ
p
k
)
x_k(p) = x(p+p_k+\Delta p_k)
xk(p)=x(p+pk+Δpk),则式(1)可变为:
y
(
p
)
=
∑
k
=
1
n
2
w
(
p
k
)
⋅
x
k
(
p
)
.
(3)
y(p) = \sum^{n^2}_{k=1} w(p_k)\cdot x_k(p).\tag{3}
y(p)=k=1∑n2w(pk)⋅xk(p).(3)因此我们可以将式子(3)总体看成1个先将图片
x
k
(
⋅
)
x_k(\cdot)
xk(⋅)变形然后进行卷积核为
1
×
1
×
n
2
1\times 1 \times n^2
1×1×n2的3D卷积,具体如下所示: Note:
这个spatial warping有点类似于PixelShuffle的逆过程。
通过将
n
2
n^2
n2改变为任意正整数
N
∈
N
N\in \mathbb{N}
N∈N,可以将DCN扩展成一个新的对齐表达式,它比DCN更加灵活,因为DCN中的
N
N
N必须是1个卷积核大小的平方。接下去为了统一叙述,offset的个数都用
N
N
N表示。
因为上述3D卷积中,输入图像格式为
(
N
,
C
,
T
,
H
,
W
)
(N,C,T,H,W)
(N,C,T,H,W),卷积核为
(
C
,
o
u
t
_
c
h
a
n
n
e
l
s
,
T
,
F
H
,
F
W
)
(C, out\_channels, T,FH,FW)
(C,out_channels,T,FH,FW),所以其可以看成是以卷积核为
(
C
,
o
u
t
_
c
h
a
n
n
e
l
,
F
H
,
F
W
)
(C,out\_channel,FH,FW)
(C,out_channel,FH,FW)对
(
N
,
C
∗
T
,
H
,
W
)
(N,C*T,H,W)
(N,C∗T,H,W)做2D卷积。
令
n
=
1
n=1
n=1,则每次卷积只对1个位置上经过运动信号的偏移之后进行特征提取,那这就等效于flow-based中每个位置的warp只取决于1个运动矢量,然后根据这个运动信号进行一些插值去采样提取输入上的特征信息。因此我们就可以将DCN和flow-based对齐用一个表达式来统一,并且需要指出的是它两唯一的不同只是offset个数不同,即offset diversity。从这里我们也可以看出flow-based的光流可以看成是1个offset,DCN中1个
n
×
n
n\times n
n×n的offset矩阵内每一个offset都可以近似看成1个flow。
DCN虽然有较多的offset从而产生较强的探索能力,但是其有一个缺陷在于当网络复杂度增加,其训练会不稳定,offset的溢出会降低表现力。为了解决这个问题,作者提出了一种offset-fidelity损失函数去训练DCN,其表达式如下所示:
L
^
=
L
+
λ
∑
n
=
1
N
L
n
.
(4)
\hat{L} = L+\lambda \sum^N_{n=1}L_n.\tag{4}
L^=L+λn=1∑NLn.(4)其中
L
L
L是data-fitting损失,例如EDVR和BasicVSR中使用的Charbonnier损失函数:
L
=
1
N
∑
i
=
0
N
ρ
(
y
i
−
z
i
)
,
ρ
(
x
)
=
x
2
+
ϵ
2
,
ϵ
=
1
×
1
0
−
8
,
z
i
:
G
T
.
L = \frac{1}{N}\sum^N_{i=0}\rho(y_i - z_i),\\ \rho(x) = \sqrt{x^2 + \epsilon^2},\epsilon = 1\times 10^{-8},z_i:GT.
L=N1i=0∑Nρ(yi−zi),ρ(x)=x2+ϵ2,ϵ=1×10−8,zi:GT.此外
L
n
=
∑
i
∑
j
H
(
∣
x
n
,
i
,
j
−
y
i
,
j
∣
−
t
)
⋅
∣
x
n
,
i
,
j
−
y
i
,
j
∣
.
(5)
L_n = \sum_i\sum_j H(|x_{n,i,j} - y_{i,j}| - t) \cdot |x_{n,i,j} - y_{i,j}|.\tag{5}
Ln=i∑j∑H(∣xn,i,j−yi,j∣−t)⋅∣xn,i,j−yi,j∣.(5)其中
H
(
⋅
)
H(\cdot)
H(⋅)为Heaviside函数(单位阶跃函数);
y
i
,
j
,
x
n
,
i
,
j
y_{i,j},x_{n,i,j}
yi,j,xn,i,j分别表示为现成的光流计算结果和在DCN中offset特征图位置
(
i
,
j
)
(i,j)
(i,j)处的第
n
n
n个offset;
λ
,
t
\lambda,t
λ,t是超参数,用于控制DCN中offset的多样性,其
λ
=
1
,
t
=
10
\lambda=1,t=10
λ=1,t=10是个合理的值。 Note:
对于光流,每个位置
(
i
,
j
)
(i,j)
(i,j)只有1个值;对于DCN,每个位置
(
i
,
j
)
(i,j)
(i,j)有
N
N
N个。
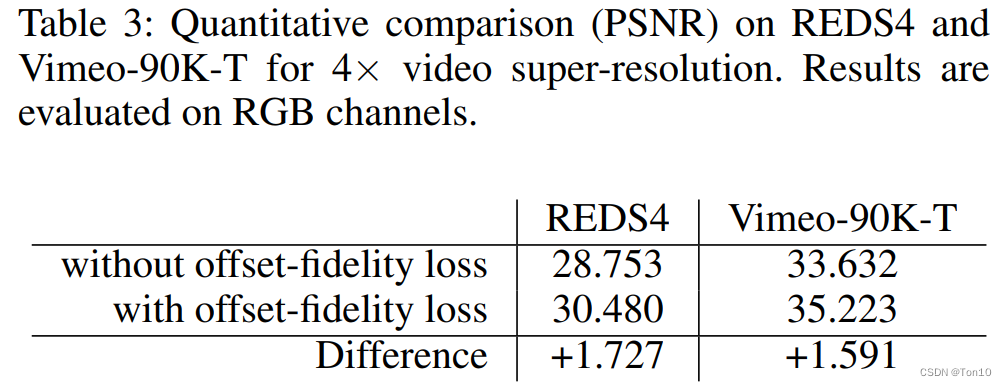
上述flow-based对齐和BasicVSR一样,是基于feature-wise。而诸如VESPCN、Robust-LTD的对齐都是image-wsie,这种对齐容易出现artifacts,是因为比如flow-based代表STN-based中会引入双线性插值来做重采样,插值就会引进一些重复的信息,而损失了很多高频信息,这样自然会出现类似重影等artifacts,虽然DCN这种feature-wise也会有插值,但是好在其具有较强的探索能力,以及特征校正模块,所以其很少出现artifacts。作者通过将flow-based对齐中的特征对齐用图像对齐来替换,发现PSNR下降了
0.84
d
B
0.84dB
0.84dB,实验数据如下: 这证明了feature-wise对齐比image-wise对齐效果更好,更有助于SR重建表现力的提升;此外作者还进行相关可视化,实验结果如下: 。
Contributions of Diversity
\colorbox{lavender}{Contributions of Diversity}
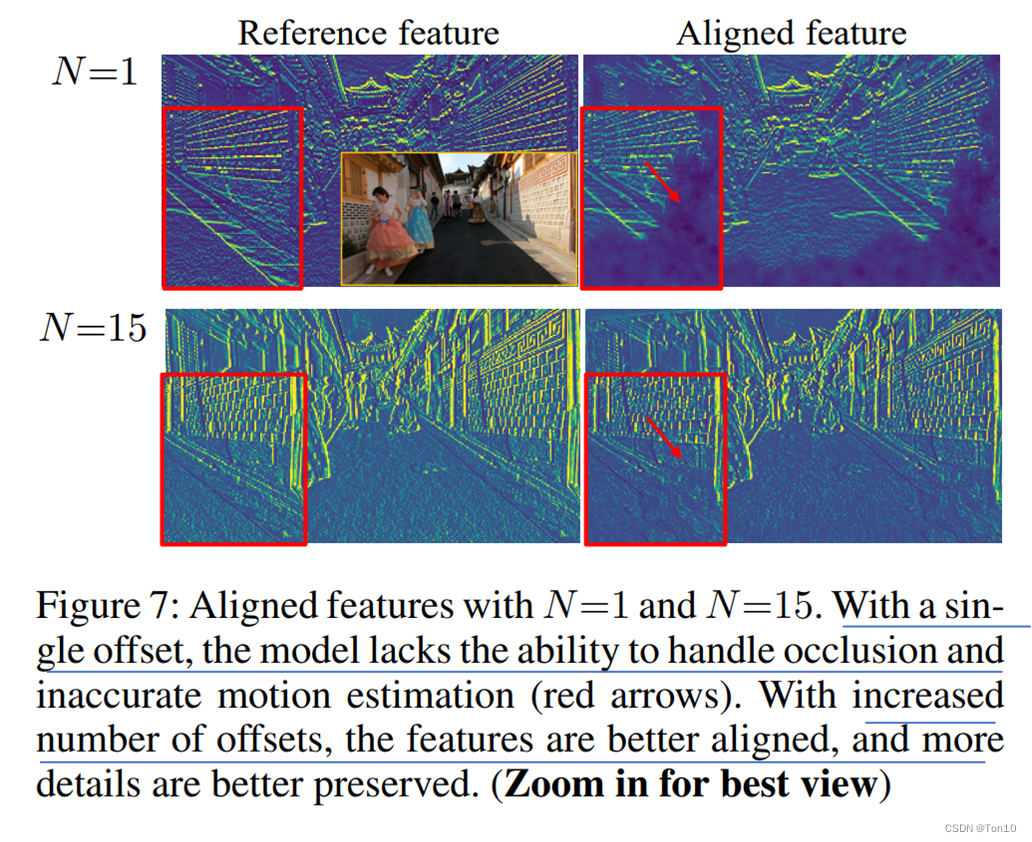
ContributionsofDiversity 上面只是光流图,为了验证多个offset在边界、遮挡这种看不见区域下对对齐性能的影响,接下来我们对比
N
=
1
N=1
N=1和
N
=
15
N=15
N=15在处理边界上的差异,实验结果如下: 可以看出来在边界这种在下一帧就不存在的情况会当
N
=
1
N=1
N=1这种少offset的DCN产生artifacts,这也和flow容易在边界差生artifacts也是相符的;而反观
N
=
15
N=15
N=15,在边界处理这些看不见区域上,DCN具有较强的探索能力,其具有多样丰富的运动信息,因此对于这种看不见区域的对齐有较鲁棒的预测。
Increasing Offset Diversity
\colorbox{violet}{Increasing Offset Diversity}
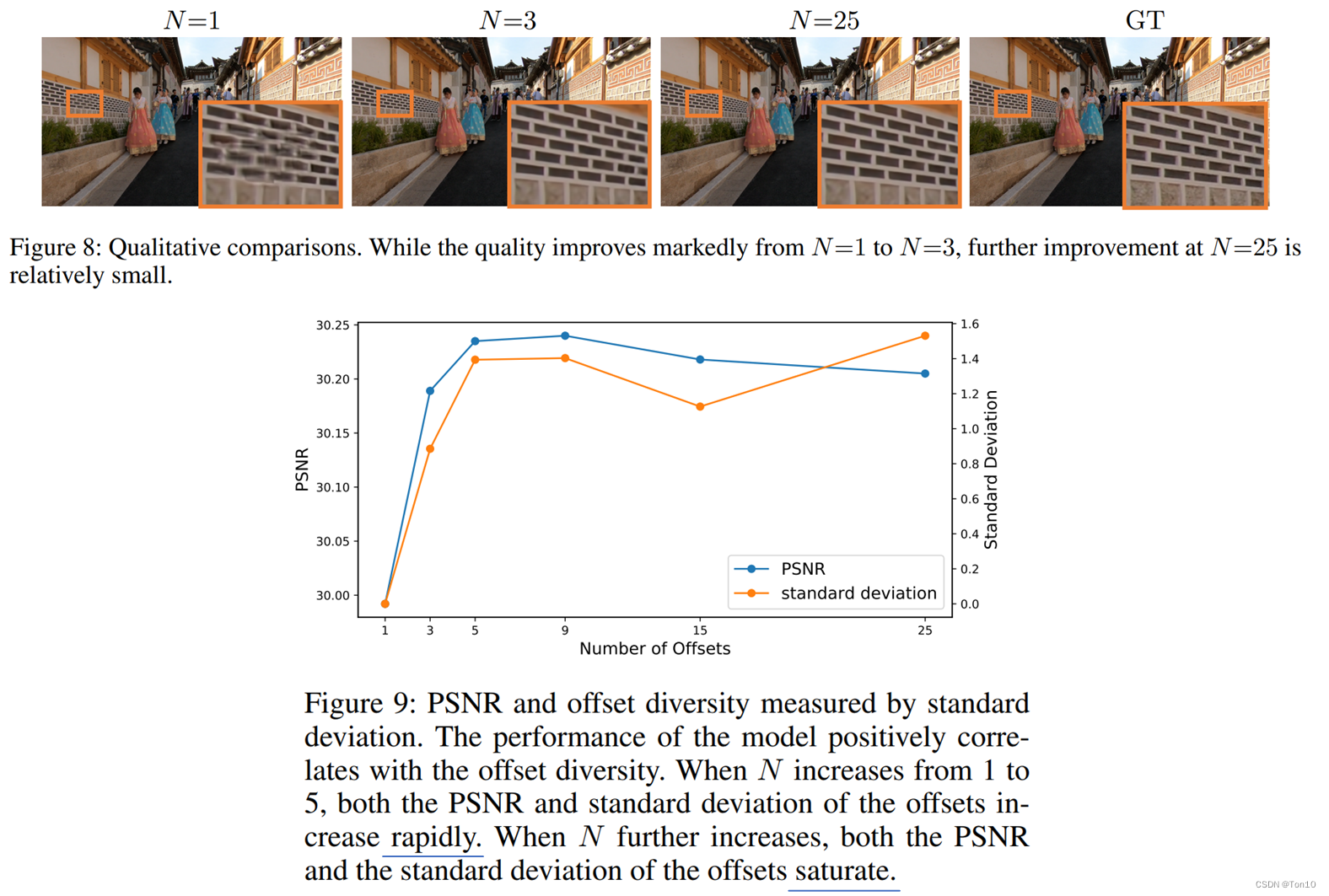
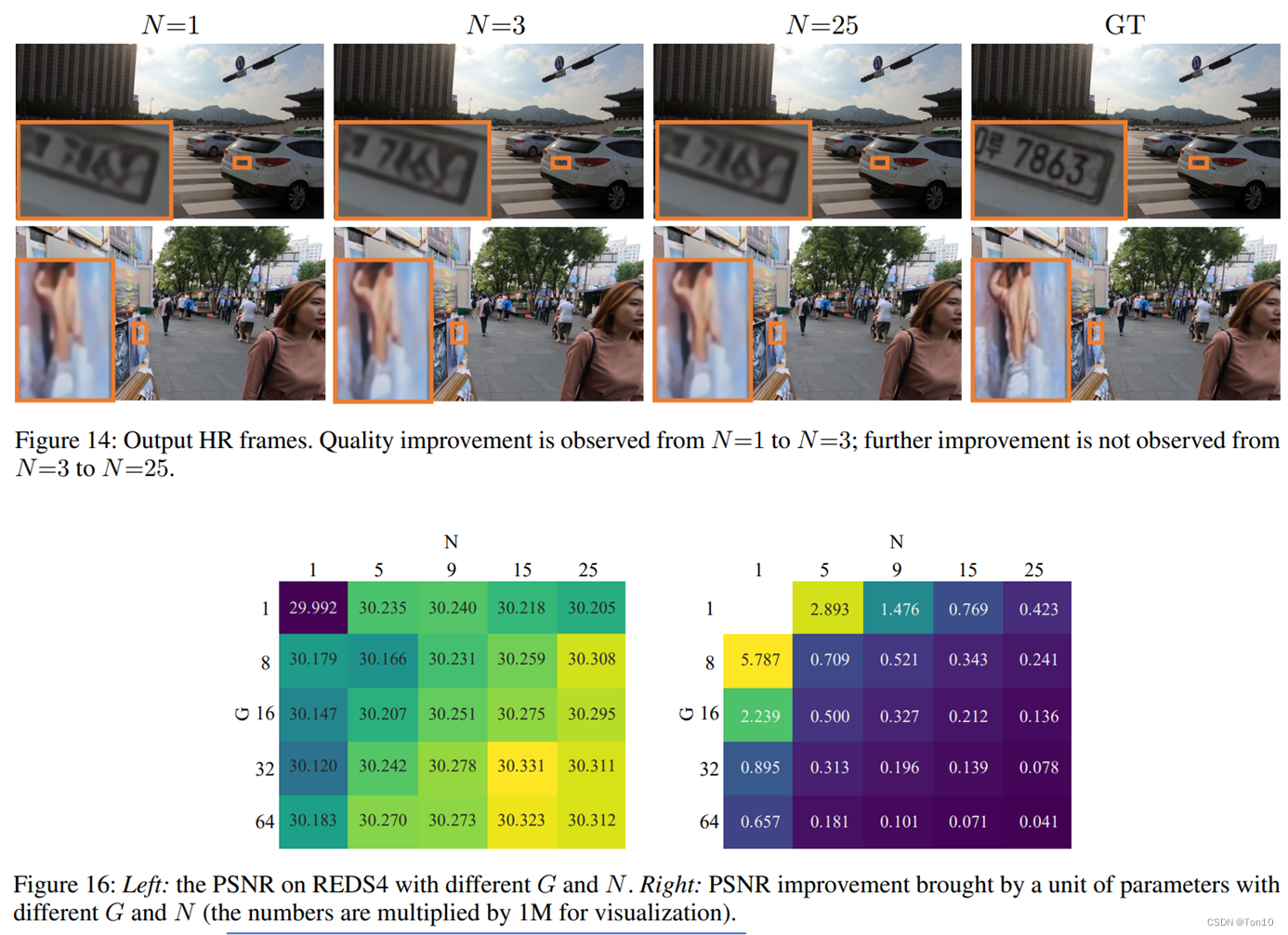
IncreasingOffsetDiversity 实验一:接下来我们探究
N
N
N的值对于对齐表现的影响,实验结果如下: 实验结论:
当
N
N
N从1升到5,对于SR重建性能的增加幅度是很大的;但是之后逐渐增加
N
N
N,虽然也有一定的提升,但似乎进入了平缓期;更重要的是,不断增加
N
N
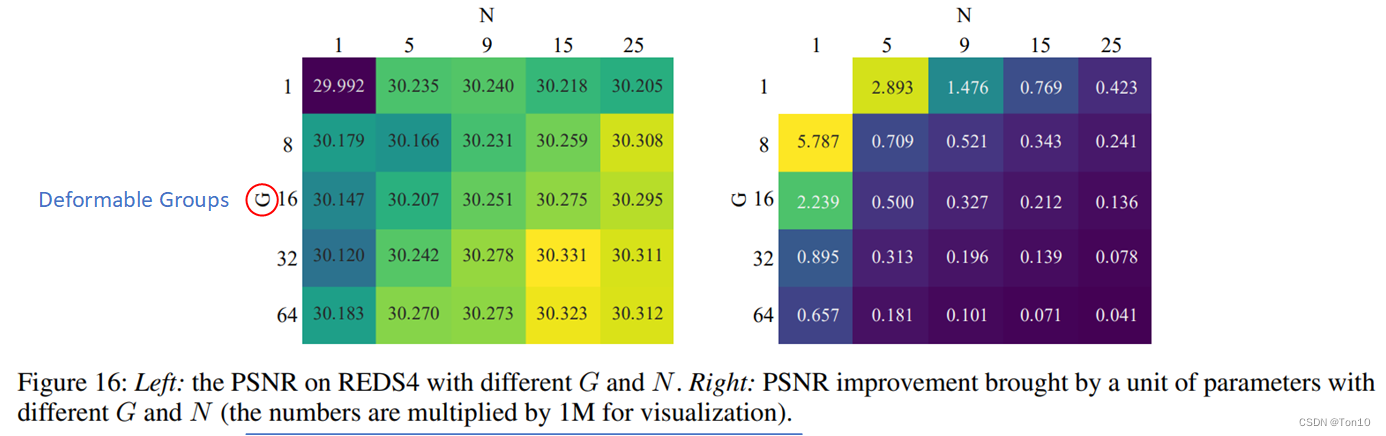
N的同时计算效率也在变低,因此如何平衡计算效率与表现力是一个关键。
作者指出,DCN很难进行平衡计算效率和重建表现力,因为其
N
N
N是个固定的值,而本文提出的ours这个具有统一性的可变形卷积可以有效调节至最佳的计算效率和表现力的trade-off,这也就体现了ours的灵活性。
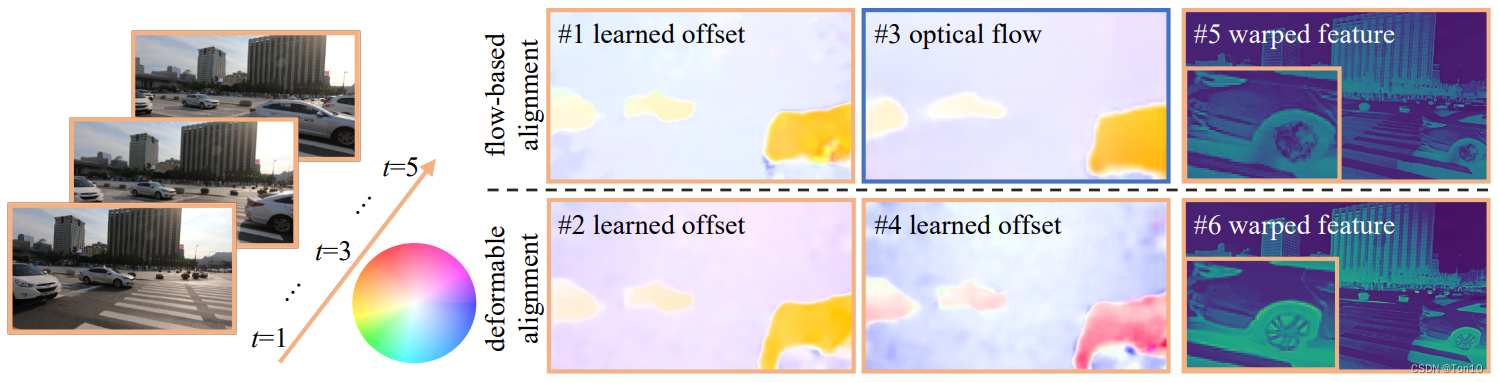
 这和我们flow-based实际在对齐过程中的学习也是一致的:左边的光流
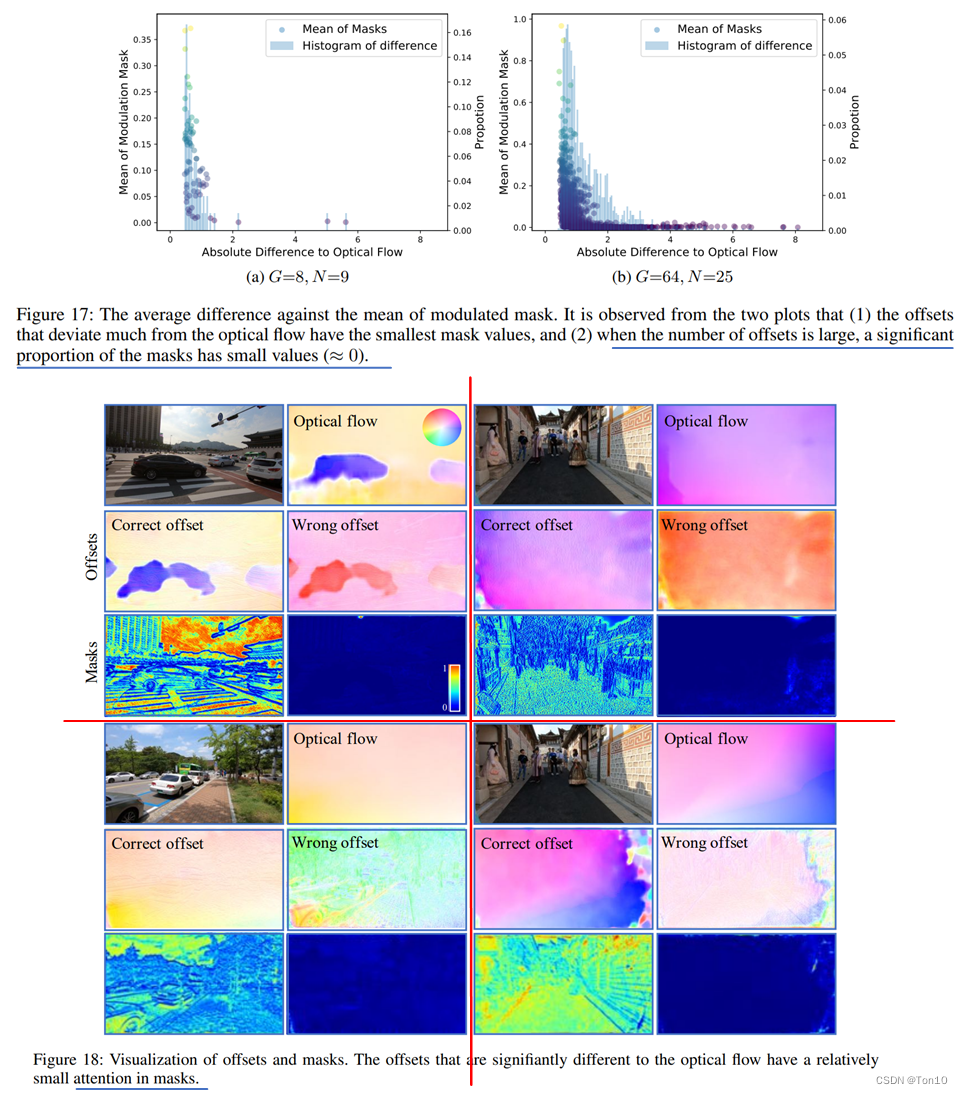
这和我们flow-based实际在对齐过程中的学习也是一致的:左边的光流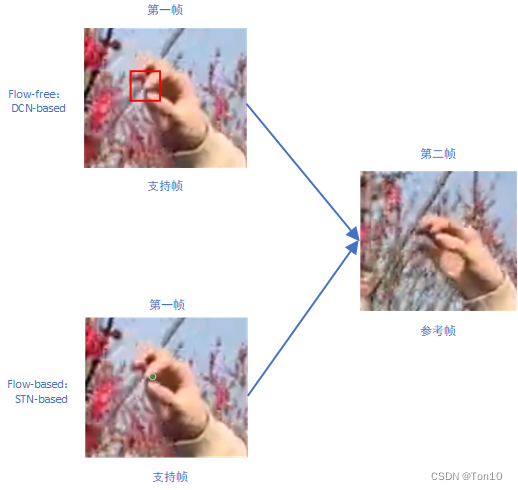 在对齐过程中,支持帧没有参考帧中关于手挡住树枝的信息,所以对齐中会出现问题,DCN的做法是在一个卷积核范围内,搜刮多方信息(多个offset)来输出最终warp的像素值;而flow-based其探索能力差,只取决于1个光流信号,所以通过光流决定的最终warp位置一般不会有被遮挡物体的特征信息,大多都是和树枝无相关的物体,比如说是手指,那么这样的warp最终会导致对齐的支持帧这一部分出现重影或其他artifacts。②对于大运动下的误差问题,个人认为这是一个方差问题(衡量稳定性的指标),DCN最终warp的输出是多个像素采样(卷积)的综合结果,而flow-based每个位置的warp只取决于1个光流,故其在大运动光流下的变化就会比较不稳定,这就有点类似于随机梯度下降(单样本)和小批量随机梯度下降一样。而这种差距在小运动或平缓运动下就体现不出来,因为光流本身就小,很难体现出来变化的不稳定性。
在对齐过程中,支持帧没有参考帧中关于手挡住树枝的信息,所以对齐中会出现问题,DCN的做法是在一个卷积核范围内,搜刮多方信息(多个offset)来输出最终warp的像素值;而flow-based其探索能力差,只取决于1个光流信号,所以通过光流决定的最终warp位置一般不会有被遮挡物体的特征信息,大多都是和树枝无相关的物体,比如说是手指,那么这样的warp最终会导致对齐的支持帧这一部分出现重影或其他artifacts。②对于大运动下的误差问题,个人认为这是一个方差问题(衡量稳定性的指标),DCN最终warp的输出是多个像素采样(卷积)的综合结果,而flow-based每个位置的warp只取决于1个光流,故其在大运动光流下的变化就会比较不稳定,这就有点类似于随机梯度下降(单样本)和小批量随机梯度下降一样。而这种差距在小运动或平缓运动下就体现不出来,因为光流本身就小,很难体现出来变化的不稳定性。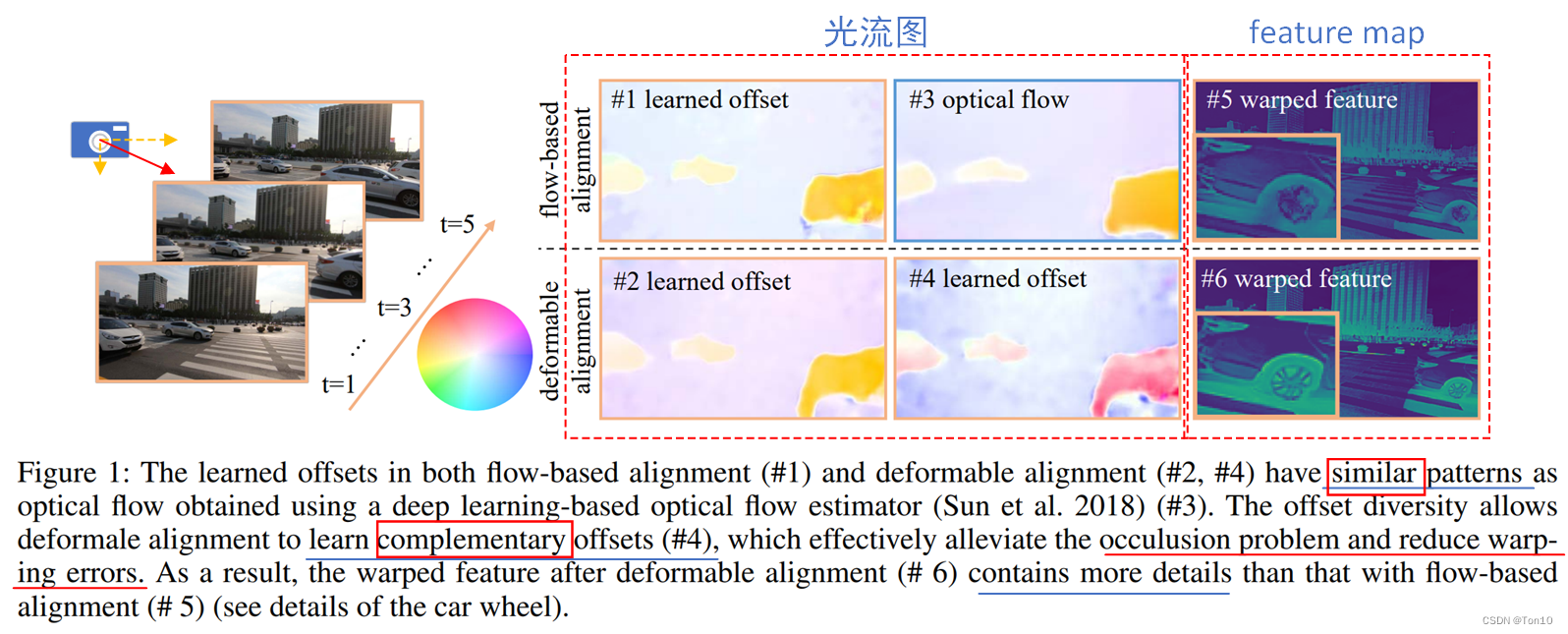




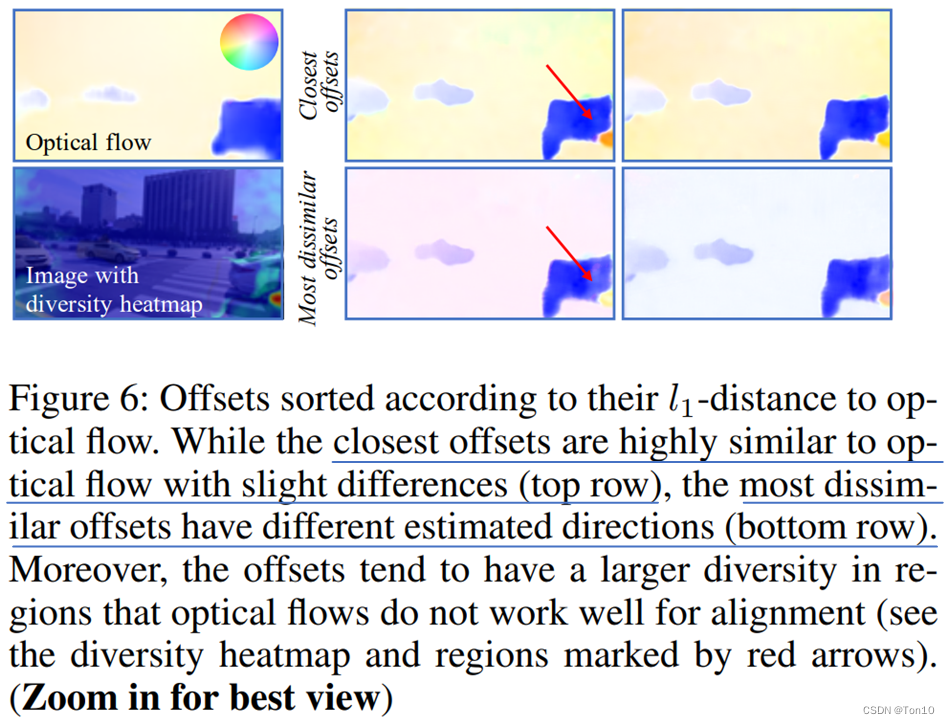
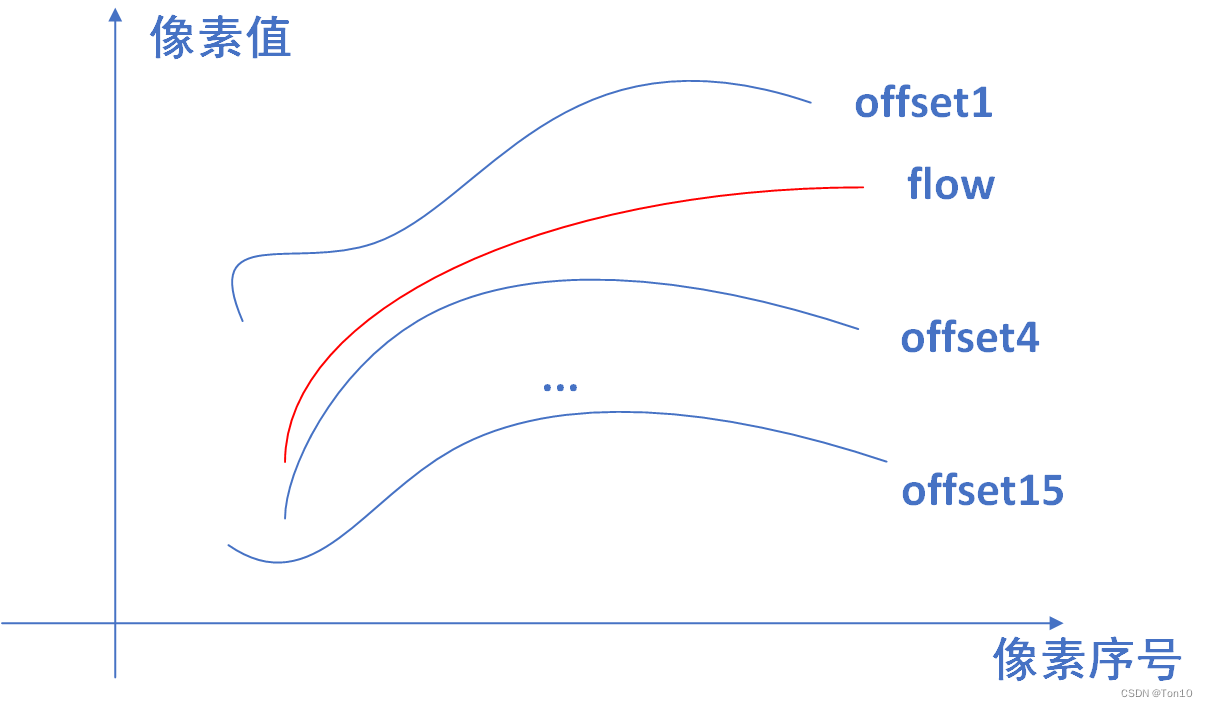 作者发现越是flow对齐不好的区域,offset在这个区域的多样性越明显,表现在标准差上就是
作者发现越是flow对齐不好的区域,offset在这个区域的多样性越明显,表现在标准差上就是