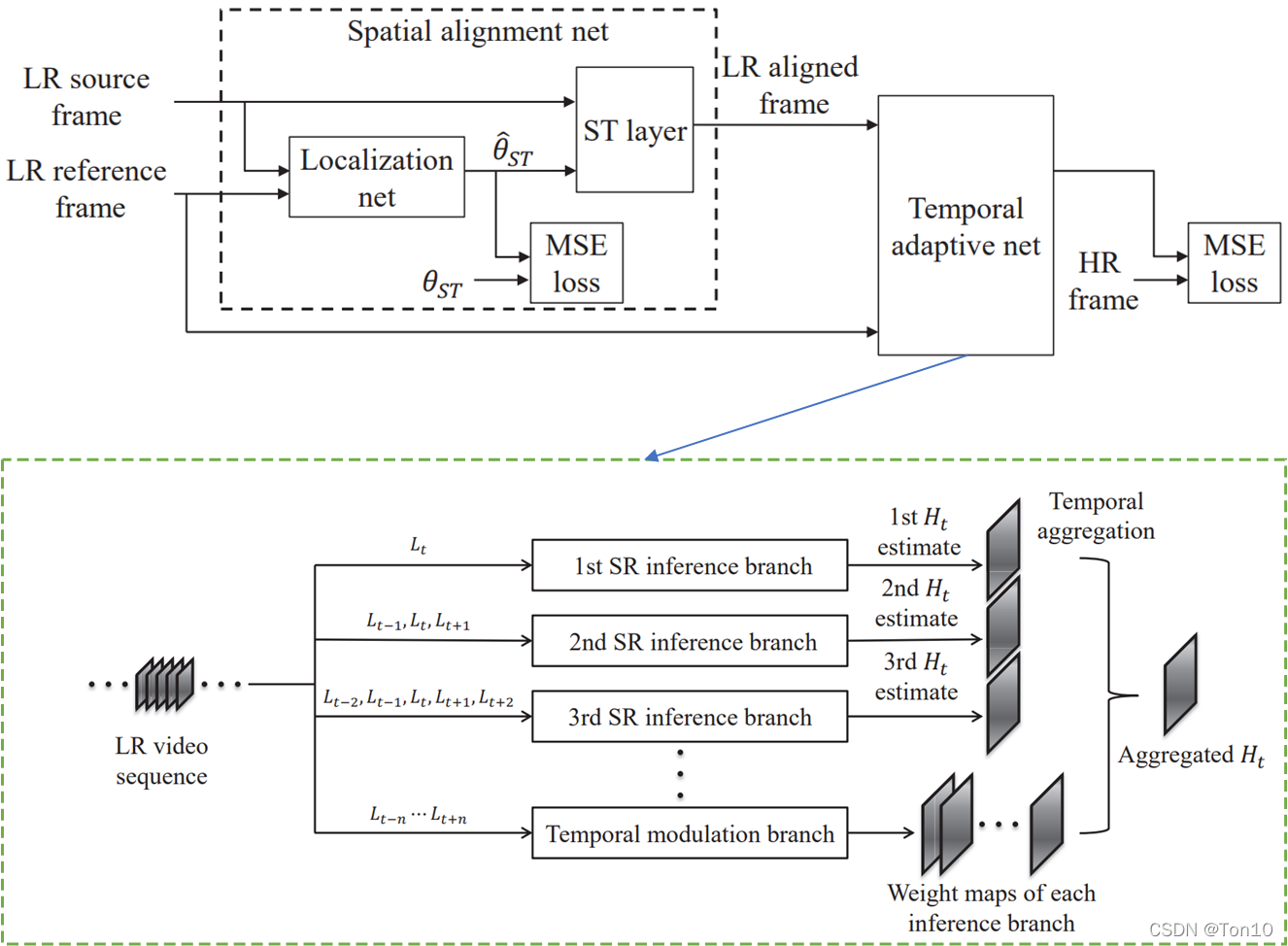
①Temporal Adaptive neural network:就是将SISR的超分网络与注意力机制结合,注意力用来自动选择合适的时间大小,即通过优化网络参数来选择最优时间冗余的范围大小。具体而言,时间自适应网络的输入为对齐网络(或者运动补偿网络,即spatial alignment network)给的
N
N
N种时间尺度,则对于每一种尺度都通过融合SR网络输出参考帧的超分重建结果,最后将
N
N
N个结果通过pixel-wise的加权和,结果就是最终我们想要的当前参考帧。其中权重图是另一个类似的SR网络训练得到的。此外,作者指出这种网络结构和Inception块结构很像,因为我们将连续的相邻帧融合之后,进行卷积的过程,除了空间卷积之外,其实也是在时间上上做卷积,而该网络是个选择时间尺度的过程,因此相当于有
N
N
N个不同大小的时间卷积滤波器,而Inception块就是在块内使用多种不同大小的空间卷积滤波器(Temporal Filters),最后进行合并的子网络。
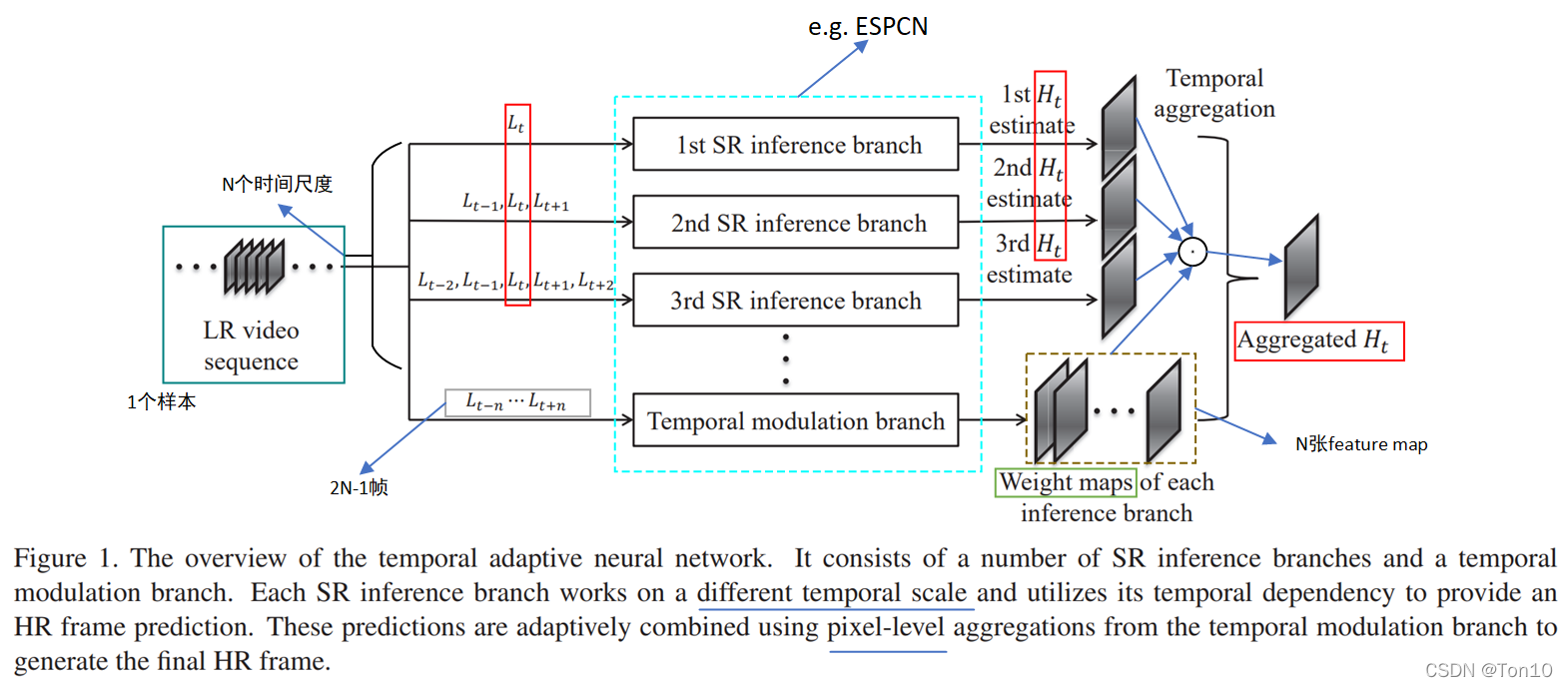
如上图所示就是时间自适应网络的结构框图。从整体看,这个网络结构就是基于SISR的超分方法(比如ESPCN、SRCNN等)以及一个自动选取最优时间尺度(时间大小、时间窗口)。其本质就是个融合SR网络。 ①假设一共有
N
N
N种时间滤波器(比如一帧、连续3帧、连续5帧,这样的话
N
=
3
N=3
N=3种),那么前者主要分为
N
N
N个SR前向分支
{
B
i
}
i
=
1
N
\{B_i\}_{i=1}^N
{Bi}i=1N,对于每一个分支
B
i
B_i
Bi,获得各自参考帧的超分结果
H
t
i
H_t^i
Hti(
i
i
i表示第
i
i
i个分支)。 ②此外还有一个分支为时间调制分支,即用来选择最优时间尺度的,该分支用来输出
N
N
N张feature map,其代表了前面
N
N
N个分支各自应得的注意力权重,其是pixel-wise,故我们将每张权重图和前面分支的输出
H
t
i
H_t^i
Hti进行元素相乘,最后相加的结果就是最后送入Loss进行优化的
H
t
H_t
Ht。 Note:
①SR前向分支 SR前向分支在本文中使用ESPCN超分结构,因为在当时相对高效且表现力较好,当然也可以是其他结构,比如SRCNN、FSRCNN等。我们对于
N
N
N种时间尺度中每一种尺度
i
∈
{
1
,
⋯
,
N
}
i\in\{1,\cdots,N\}
i∈{1,⋯,N}都使用1个SR前向分支来输出参考帧的超分结果
H
i
t
H_i^t
Hit。 作者采用Early fusion来对相邻
2
i
−
1
2i-1
2i−1帧进行融合,该融合方式下输入格式为
(
B
a
t
c
h
,
(
2
i
−
1
)
∗
c
,
H
,
W
)
(Batch, (2i-1)*c, H, W)
(Batch,(2i−1)∗c,H,W),其中
c
c
c是每一帧的通道数。然后在接下来的2层卷积层后都设置ReLU激活函数,此外不同尺度下的SR前向分支的网络参数都是不一样的,因此当可选尺度较多时,这个融合SR结构的参数量也是很大的。
②时间调整分支 时间调制分支是用来学习一个选择最优时间尺度的SR网络,它具有和SR前向分支相同的网络结构。不同于SR前向分支,该分支输入为前向分支中最长时间序列,即
2
N
−
1
2N-1
2N−1个连续帧,这样做也是为了更加全面的覆盖前向分支所有的输入情况。该分支的输出是
N
N
N张权重图
W
i
W_i
Wi,这些图通过和
N
N
N个SR前向分支的输出
H
i
t
H_i^t
Hit进行元素相乘,故其实pixel-wise的,最后将相乘的
N
N
N个结果相加,最后输出
H
t
i
H_t^i
Hti,简单表示为:
H
t
=
∑
i
W
i
⊙
H
i
t
,
i
∈
{
1
,
⋯
,
N
}
H_t = \sum_i W_i\odot H_i^t, i\in\{1,\cdots,N\}
Ht=∑iWi⊙Hit,i∈{1,⋯,N}。
3.3 Training Objective
接下来介绍下时间自适应网络的训练。 整个Temporal adaptive network网络的损失函数,作者使用L2损失:
min
Θ
∑
j
∣
∣
F
(
y
(
j
)
;
Θ
)
−
x
(
j
)
∣
∣
2
2
.
(1)
\min_{\Theta} \sum_j ||F(y^{(j)};\Theta) - x^{(j)}||_2^2.\tag{1}
Θminj∑∣∣F(y(j);Θ)−x(j)∣∣22.(1)其中
x
(
j
)
x^{(j)}
x(j)第
j
j
j个参考帧对应的
H
R
HR
HR图像,即Ground Truth;
y
j
y^{j}
yj代表以第
j
j
j帧参考帧为中心的所有对齐帧,故
F
(
y
(
j
)
;
Θ
)
F(y^{(j)};\Theta)
F(y(j);Θ)表示整个时间自适应网络的输出
H
t
H_t
Ht。
我们将式(1)更加细化表示:
min
θ
w
,
{
θ
B
i
}
i
=
1
N
∑
j
∣
∣
∑
i
=
1
N
W
i
(
y
(
j
)
;
θ
w
)
⊙
F
B
i
(
y
(
j
)
;
θ
B
i
)
−
x
(
j
)
∣
∣
2
2
.
(2)
\min_{\theta_w,\{\theta_{B_i}\}_{i=1}^N} \sum_j ||{\color{tomato}\sum^N_{i=1}W_i(y^{(j)};\theta_w)\odot F_{B_i}(y^{(j)};\theta_{B_i})} - x^{(j)}||^2_2.\tag{2}
θw,{θBi}i=1Nminj∑∣∣i=1∑NWi(y(j);θw)⊙FBi(y(j);θBi)−x(j)∣∣22.(2)其中
W
i
W_i
Wi表示时间调制网络输出的关于第
B
i
B_i
Bi个时间尺度下对应的权重图,用参数
θ
w
\theta_w
θw表示时间调制网络的参数;
F
B
i
(
y
(
j
)
;
θ
B
i
)
F_{B_i}(y^{(j)};\theta_{B_i})
FBi(y(j);θBi)表示第
B
i
B_i
Bi个SR前向分支的输出
H
t
i
H_t^i
Hti,用参数
θ
B
i
\theta_{B_i}
θBi表示该前向分支的网络参数;
⊙
\odot
⊙表示元素级相乘。
训练技巧: 实际训练中作者先独立训练
N
N
N个不同时间窗口的SR前向分支,获得了
N
N
N个类似结构的ESPCN网络;然后我们将这些训练好的参数作为时间自适应网络的初始化参数,利用式(2)去训练时间调制分支和在各个SR前向分支上微调。作者指出这种方式可以加速收敛!
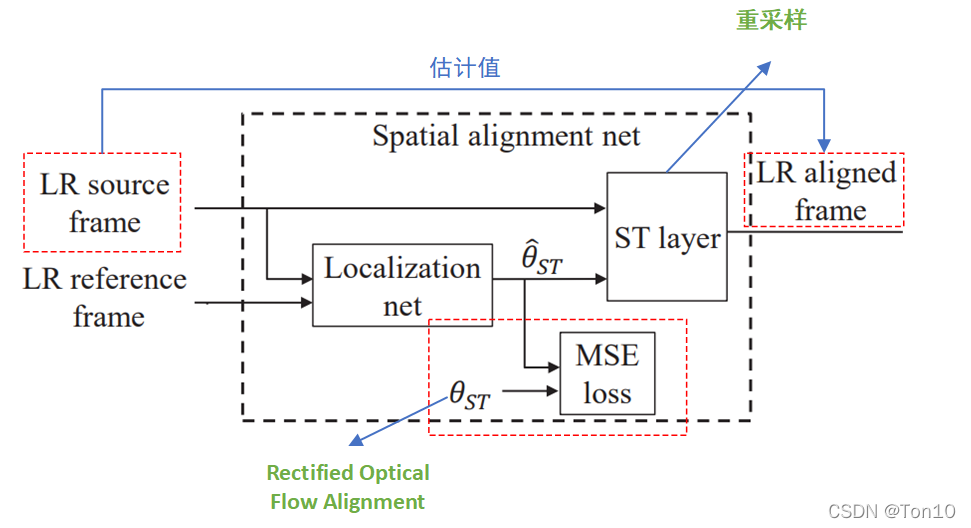
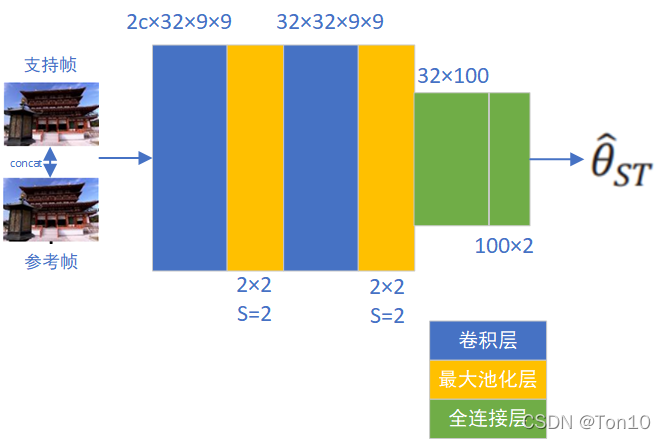
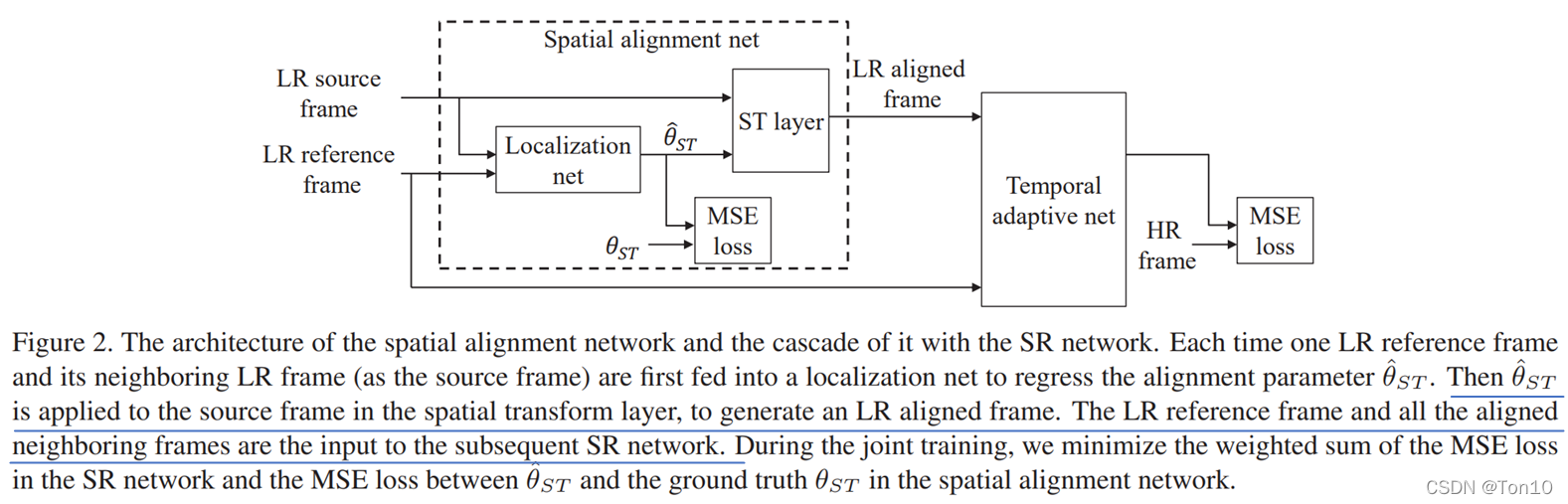
那么这个Rectified Optical Flow Alignment是怎么做的呢? Rectified Optical Flow Alignment每次操作的对象只是一个patch,我们计算这个patch内参考帧和支持帧之间的光流信息(运动矢量),然后将这个patch内沿着水平和垂直两个方向分别统计所有运动矢量的平均值,我们按四舍五入来将这个平均光流信息取整数,也就是说输入这个patch,输出这个patch对应的2个整数光流信息
θ
S
T
x
、
θ
S
T
y
\theta_{ST}^x、\theta_{ST}^y
θSTx、θSTy,分别代表水平和垂直方向。那么遍历参考帧和支持帧所有的patch就可以得到所有的整数平均光流。将这些光流作用于支持帧,就可以获得支持帧的一个估计值,从直观上来看,这个估计值应该和支持帧很相似。但我们最后需要的不是这个估计值,而是该过程中得到的2个整数光流信息
θ
S
T
x
、
θ
S
T
y
\theta_{ST}^x、\theta_{ST}^y
θSTx、θSTy。 Note:
②重采样 和STN不一样的是,TSTN将获取网格和重采样放一起来做。这里和VESPCN中的重采样一样,就是将输出(对齐版本的支持帧)的网格点
(
x
s
,
y
s
)
(x^s,y^s)
(xs,ys)通过变换得到在支持帧上相应的亚像素格点
(
x
m
,
y
m
)
(x^m,y^m)
(xm,ym),通过双线性插值获取对应的像素值作为输出网格点
(
x
s
,
y
s
)
(x^s,y^s)
(xs,ys)上的像素值。由于双线性插值可使得整个网络变得可导,因此整个时间对齐网络可以和后面的融合SR网络组成端对端的训练。
我们给出对齐网络和融合SR网络的联合训练损失:
min
{
Θ
,
θ
L
}
∑
j
∣
∣
F
(
y
(
j
)
;
Θ
)
−
x
(
j
)
∣
∣
2
2
⏟
T
e
m
p
o
r
a
l
a
d
a
p
t
i
v
e
n
e
t
w
o
r
k
+
λ
∑
j
∑
k
∈
N
j
∣
∣
θ
^
S
T
(
k
)
−
θ
S
T
(
k
)
∣
∣
2
2
⏟
S
p
a
t
i
a
l
a
l
i
g
n
m
e
n
t
n
e
t
w
o
r
k
.
(3)
\min_{\{\Theta,\theta_L\}} \underbrace{\sum_j ||F(y^{(j)};\Theta)-x^{(j)}||_2^2}_{Temporal\;adaptive\;network} + \lambda \underbrace{\sum_j\sum_{k\in \mathcal{N}_j}||\hat{\theta}_{ST}^{(k)}-\theta_{ST}^{(k)}||^2_2}_{Spatial\;alignment\;network}.\tag{3}
{Θ,θL}minTemporaladaptivenetworkj∑∣∣F(y(j);Θ)−x(j)∣∣22+λSpatialalignmentnetworkj∑k∈Nj∑∣∣θ^ST(k)−θST(k)∣∣22.(3)其中
N
j
\mathcal{N}_j
Nj表示第
j
j
j个样本中所有的
L
R
LR
LR参考帧、支持帧输入对;
λ
\lambda
λ用来平衡两个部分的Loss。 Note:
训练集:LIVE Video Quality Assessment Database、MCL-V Database、TUM 1080p Data Set。 测试集:6个经典场景:calendar、city、foliage、penguin、temple、walk;以及4k视频集:Ultra Video Group Database。 所有的
L
R
LR
LR数据都是从上面数据集中的
H
R
HR
HR图像通过Bicubic插值获得的。
本节是为了继续探究时间自适应网络的特性。 设置关于时间自适应网络的7种结构,设
B
i
B_i
Bi表示输入为
2
i
−
1
2i-1
2i−1帧,且只有1个时间尺度;
B
i
,
j
B_{i,j}
Bi,j则表示有2个时间尺度,分别由
2
i
−
1
、
2
j
−
1
2i-1、2j-1
2i−1、2j−1帧,依次类推,此外
T
T
T表示时间调制分支。这7种结构分别是: ①
B
1
B_1
B1 ②
B
2
B_2
B2 ③
B
3
B_3
B3 ④
B
1
,
2
B_{1,2}
B1,2 ⑤
B
1
,
2
+
T
B_{1,2}+T
B1,2+T ⑥
B
1
,
2
,
3
B_{1,2,3}
B1,2,3 ⑦
B
1
,
2
,
3
+
T
B_{1,2,3}+T
B1,2,3+T Note:
比如
B
1
,
2
B_{1,2}
B1,2是将两个尺度各自超分结果做平均。
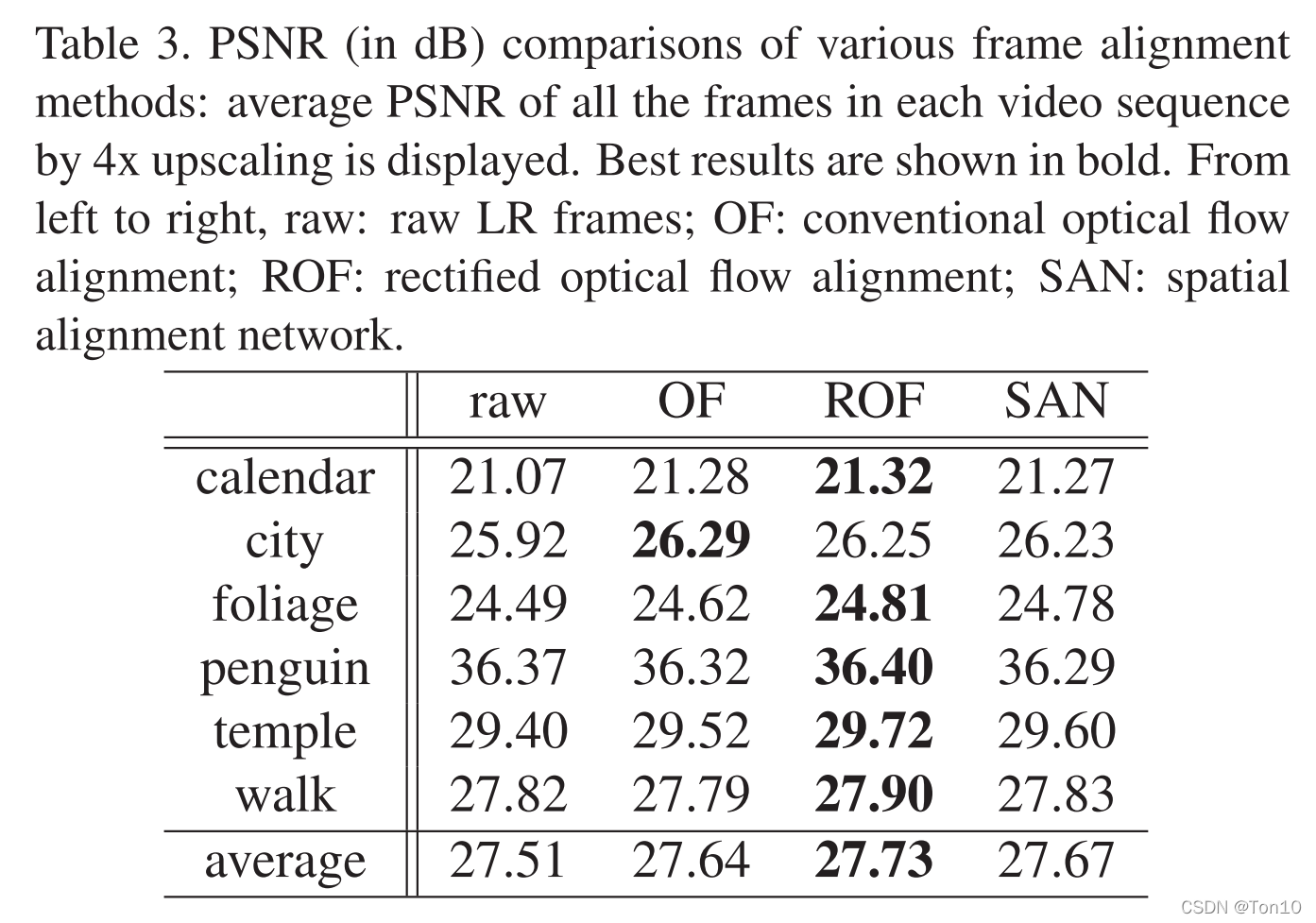
对齐网络统一采用4.1节提出的ROF做的。
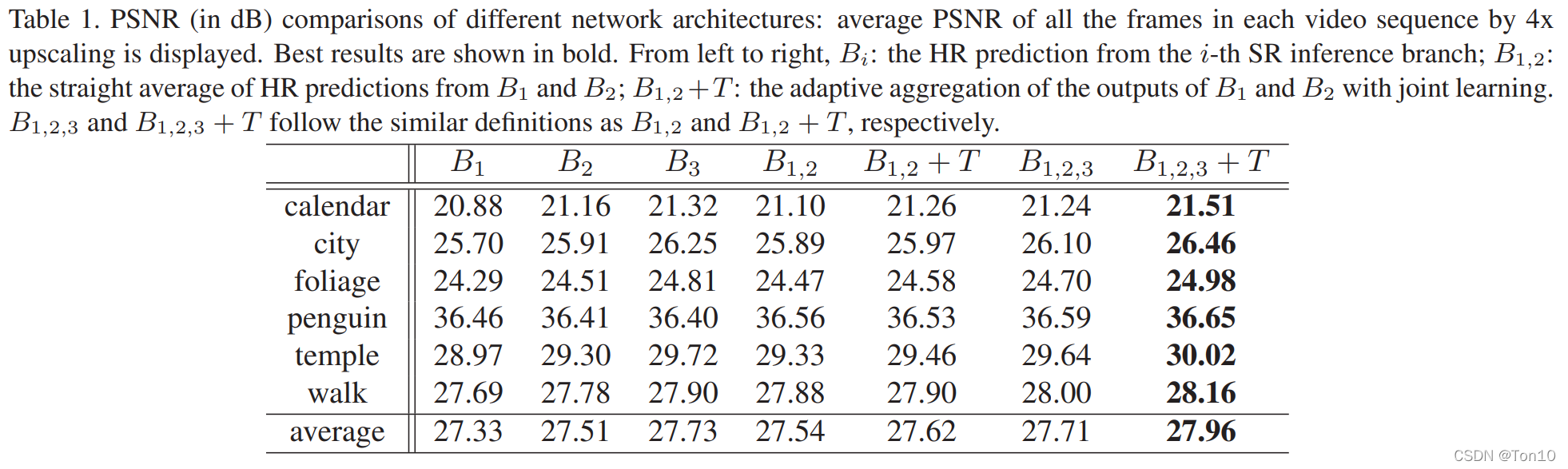
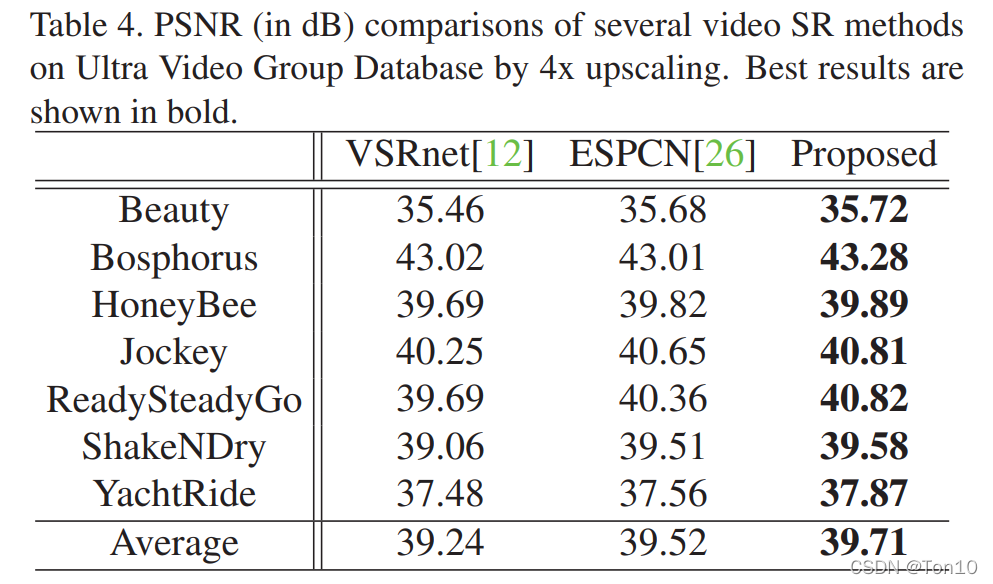
以上7种结果在6种环境下的评测结果如下(PSNR): 实验结论如下:
B
1
、
B
2
、
B
3
B_1、B_2、B_3
B1、B2、B3对比来看,一定范围内,越多的支持帧对SR重建的表现力提升越明显。
B
1
,
2
+
T
↔
B
1
,
2
B_{1,2}+T \leftrightarrow B_{1,2}
B1,2+T↔B1,2和
B
1
,
2
,
3
+
T
↔
B
1
,
2
,
3
B_{1,2,3}+T \leftrightarrow B_{1,2,3}
B1,2,3+T↔B1,2,3对比来看,注意力机制产生的权重比简单的平均分配的效果更好。
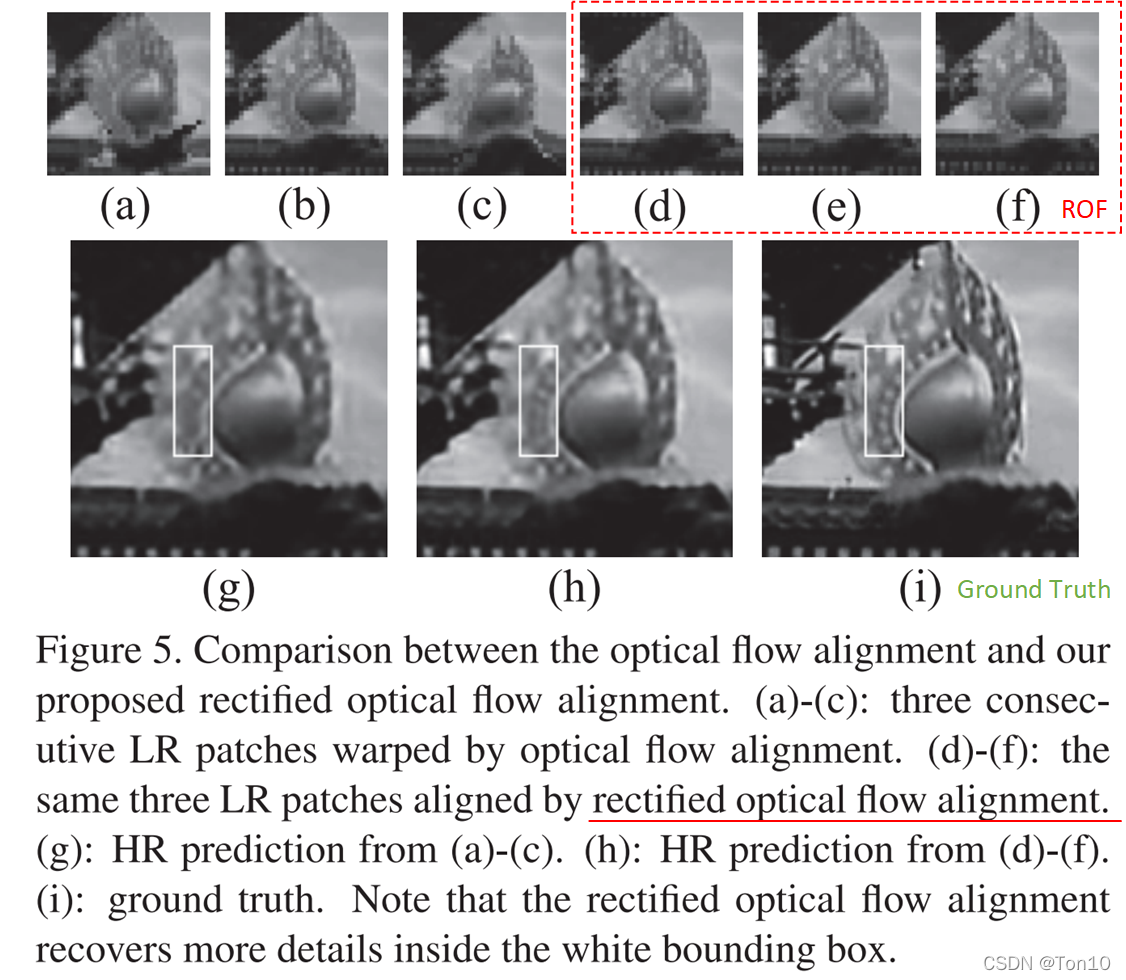
可视化结果如下: 作者针对
B
1
、
B
3
、
B
1
,
2
,
3
+
T
B_1、B_3、B_{1,2,3}+T
B1、B3、B1,2,3+T和Ground Truth三种结构进行来可视化比对。
其中针对walk这个环境中的2个区域做了重点研究,红色框是行人的耳朵,其运动相对比较缓慢;蓝色框是一只飞翔的鸽子,其运动幅度相对较大,运动估计较难准确实现:可以理解为相机的相邻帧可能很难捕捉精确的运动细节,比如一帧中鸽子是有明确位置的,下一帧鸽子就到了另一个地方,由于幅度较大,很难知道中间具体做了什么运动,因此网络在学习的时候就很可能会学错(运动估计的出错会导致后续融合SR网络也会出现问题),这样在测试的时候,对于其他运动的物体就会判定错误的运动方式,从而出现各种artifacts。比如针对蓝色框,
B
1
B_1
B1的表现会比
B
3
B_3
B3更好,有更少的artifacts,说明了多帧下运动估计出了问题,而
B
1
B_1
B1不需要对齐,自然不需要进行运动估计,所以避免了这个问题。因此,大运动下的对齐是很多VSR网络急需解决的问题(EDVR就针对这个问题提出了新的网络结构)。
对于红色框这种慢性运动,
B
3
B_3
B3倒是表现得比
B
1
B_1
B1更好,恢复了更多的细节,证明了LTD对于慢性运动的对齐做的还是可以的,它利用了视频帧时间冗余的特点,更好的提高VSR的表现力。
B
1
,
2
,
3
+
T
B_{1,2,3}+T
B1,2,3+T比2个单SR前向分支在红框和蓝框的表现都要好,说明了注意力机制的引入对VSR表现力的提升还是可观的。
为了更进一步研究时间调制分支中注意力机制的作用,作者可视化了foliage和temple两个环境下时间调制分支产生的权重图。实验对象是
B
1
,
2
,
3
+
T
B_{1,2,3}+T
B1,2,3+T中关于3个前向分支
B
1
、
B
2
、
B
3
B_1、B_2、B_3
B1、B2、B3各自对应在时间调制分支输出中的权重图。权重图也是色彩为
0
−
255
0-255
0−255的灰度图(255代表白色,0代表黑色)。此外我们将3张权重图中,每个像素位置最大的权值提取出来,形成一张Max label map,在这张图中,我们用黄色、蓝绿色、深蓝色分别表示
B
1
、
B
2
、
B
3
B_1、B_2、B_3
B1、B2、B3属于各自权重图的部分。实验结果如下: 需要注意的是:foliage中运动较大的物体为汽车,运动较慢的是背景;temple中运动较大的物体为灯笼顶部,运动较慢的是天空。 实验结论如下:
对于运动较大的物体,多帧下的融合重建往往无法展现较好的表现,这起源于运动估计的不准确。故在
B
3
B_3
B3中时间调制会给与汽车和灯笼顶部近乎0的权值;而单帧下
B
1
B_1
B1不需要运动估计,就可以展现出较好的表现效果,故给与的权值近乎255,即在Max label map中汽车和灯笼顶部都是属于
B
1
B_1
B1权值图的黄色。
LTD主要由2部分组成,那么自然时间消耗就在时间对齐网络和时间自适应网络上。 ①对于Spatial Alignment network,作者指出对于
4
k
4k
4k视频的重建,传统flow-based对齐需要15s来对齐5帧
540
×
960
540\times 960
540×960(
r
=
4
r=4
r=4),而SAN只需要0.8s! ②对于Temporal Adaptive network,
B
1
B_1
B1需要0.3s去重建一张
4
k
4k
4k的高分辨图下,而
B
1
、
B
2
、
B
3
B_1、B_2、B_3
B1、B2、B3只是输入维度不同,故时间相差不大。此外,所有的特征提取都基于
L
R
LR
LR层级且所有分支都是并行执行的,故其计算效率也是可行的。
6 Conclusions
作者主要提出了一种新的SOTA表现得VSR方法——LTD。它由Spatial Alignment network和Temporal adaptive network两部分组成。前者用于对齐,后者利用对齐的连续视频帧重建出
H
R
HR
HR图像帧。时间对齐网络基于STN,使用ROF作为target来优化变换参数;时间自适应网络基于注意力机制,通过使用
N
N
N个并行的SR前向分支和时间调制分支产生用于自动选择最佳时间尺度(窗口、大小、滤波器、冗余)的SR网络,该网络可以是之前任意的SISR网络,比如ESPCN、SRCNN等。作者通过实验证明这两个网络都具备提升超分表现力的能力!