yolov5输出检测框的中心位置,框的长宽,框的位置,以及输出对应标签格式的输出。 模型读取每个图片,并将上述的信息依此输出到同名的txt文件中保存,具体需要哪些坐标可以自己选。
更改信息在detect.py文件中,需要更改的第一个地方在如下地方,输出位置在runs/detect/exp中

location_center_dir = str(save_dir) + '/detect_location'
if not os.path.exists(location_center_dir):
os.makedirs(location_center_dir)
location_center_path = location_center_dir + '\\' + str(p.stem) + (
'' if dataset.mode == 'image' else f'_{frame}')
flocation = open(location_center_path + '.txt', 'a')
第二个需要更改的地方:
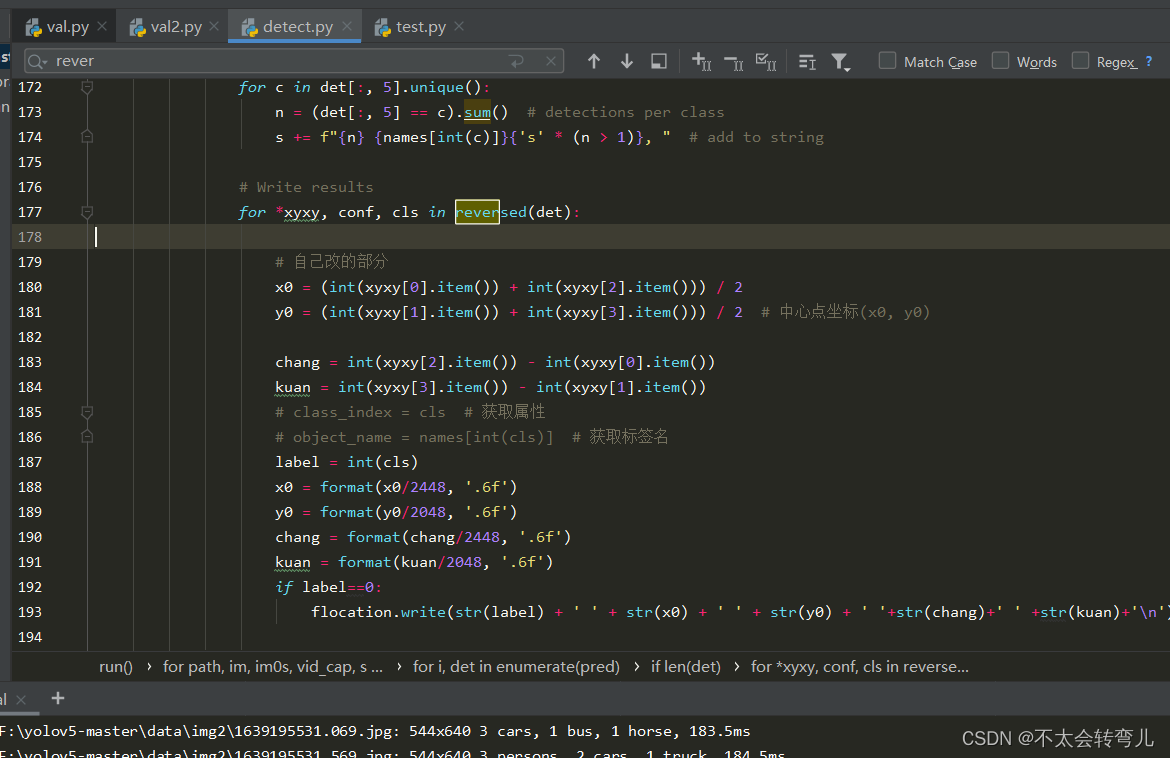
x0 = (int(xyxy[0].item()) + int(xyxy[2].item())) / 2
y0 = (int(xyxy[1].item()) + int(xyxy[3].item())) / 2
chang = int(xyxy[2].item()) - int(xyxy[0].item())
kuan = int(xyxy[3].item()) - int(xyxy[1].item())
label = int(cls)
x0 = format(x0/2448, '.6f')
y0 = format(y0/2048, '.6f')
chang = format(chang/2448, '.6f')
kuan = format(kuan/2048, '.6f')
if label==0:
flocation.write(str(label) + ' ' + str(x0) + ' ' + str(y0) + ' '+str(chang)+' ' +str(kuan)+'\n')
注释应该很清楚了,int(xyxy[0].item()) 为左边的X坐标,int(xyxy[0].item(2))为右边的x坐标,int(xyxy[1].item()) 为上面的y坐标,int(xyxy[3].item()) 为下面的y坐标。
我的坐标信息除以2048和2448,是为了获得labelimg标注工具同类型的坐标信息(用于训练或者var的label标签),即比例。需要用可通过img.shape()获得。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)