目录
- 一、环境准备
- 1.进入ModelArts官网
- 2.使用CodeLab体验Notebook实例
- 二、向量化思维
- 三、手动向量化
- 四、自动向量化
-
AI融合计算的蓬勃发展,对框架能力提出了新的需求和挑战。问题场景和模型设计逐渐复杂化,使得业务数据的维度和计算逻辑的嵌套深度也相应增长。结合向量化优化手段可以有效优化性能瓶颈,但实现向量化优化对于普通用户并非易事。虽然用户可以很容易地实现低维数据运算逻辑,但随着数据维度的增长,业务逻辑也变得更为复杂,用户需要清晰了解各操作间的数据维度的逻辑映射关系,给用户的模型设计和编码带来了巨大挑战。自动向量化特性(Vmap)帮助用户解决了这个头疼的问题,该技术允许用户将特定的批处理逻辑从函数中剥离。用户在编写函数时,只需要先考虑低维的运算逻辑即可,通过调用vmap接口自动实现高维运算,并且支持嵌套调用,有效降低问题复杂度。
本教程介绍自动向量化vmap接口的使用方式,将模型或函数中高度重复的运算逻辑转换为并行的向量运算逻辑,从而获得更加精简的代码逻辑以及更高效的执行性能。
如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
一、环境准备
1.进入ModelArts官网
云平台帮助用户快速创建和部署模型,管理全周期AI工作流,选择下面的云平台以开始使用昇思MindSpore,获取安装命令,安装MindSpore2.0.0-alpha版本,可以在昇思教程中进入ModelArts官网
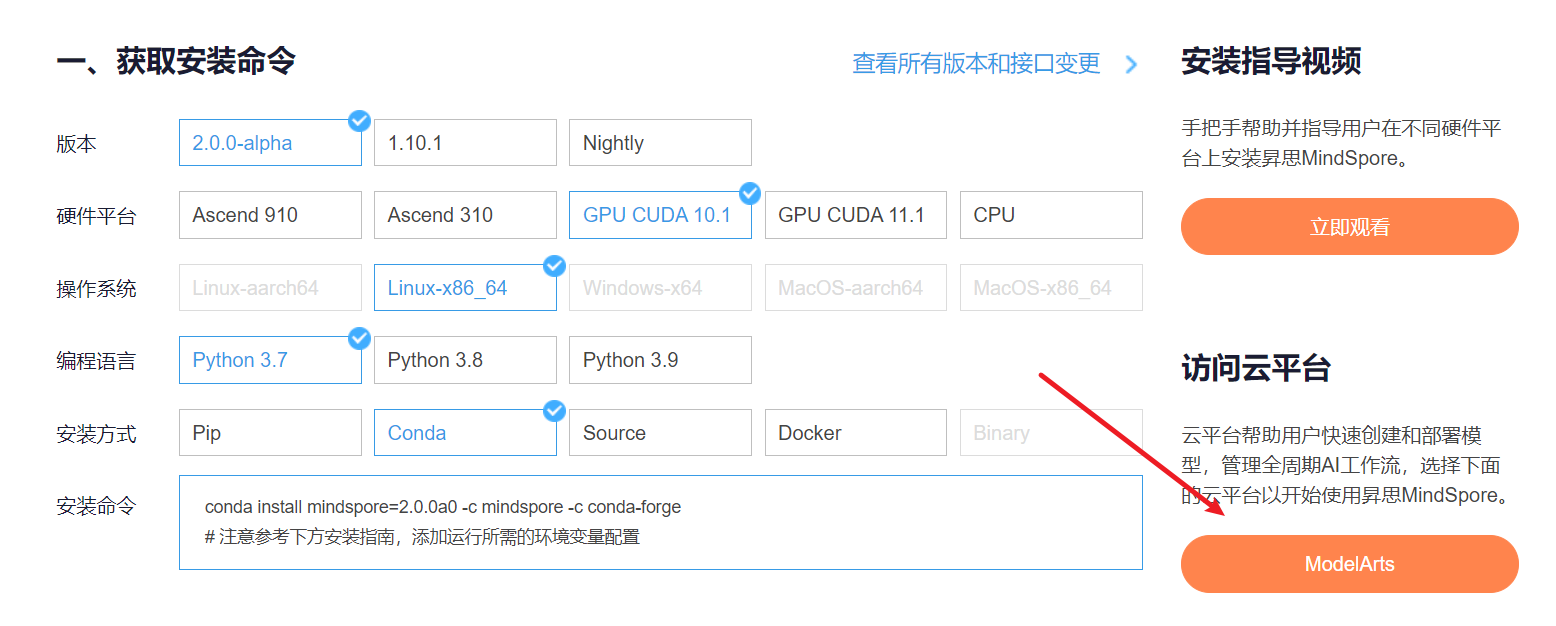
选择下方CodeLab立即体验
等待环境搭建完成
2.使用CodeLab体验Notebook实例
下载NoteBook样例代码,自动向量化Vmap ,.ipynb为样例代码

选择ModelArts Upload Files上传.ipynb文件
选择Kernel环境
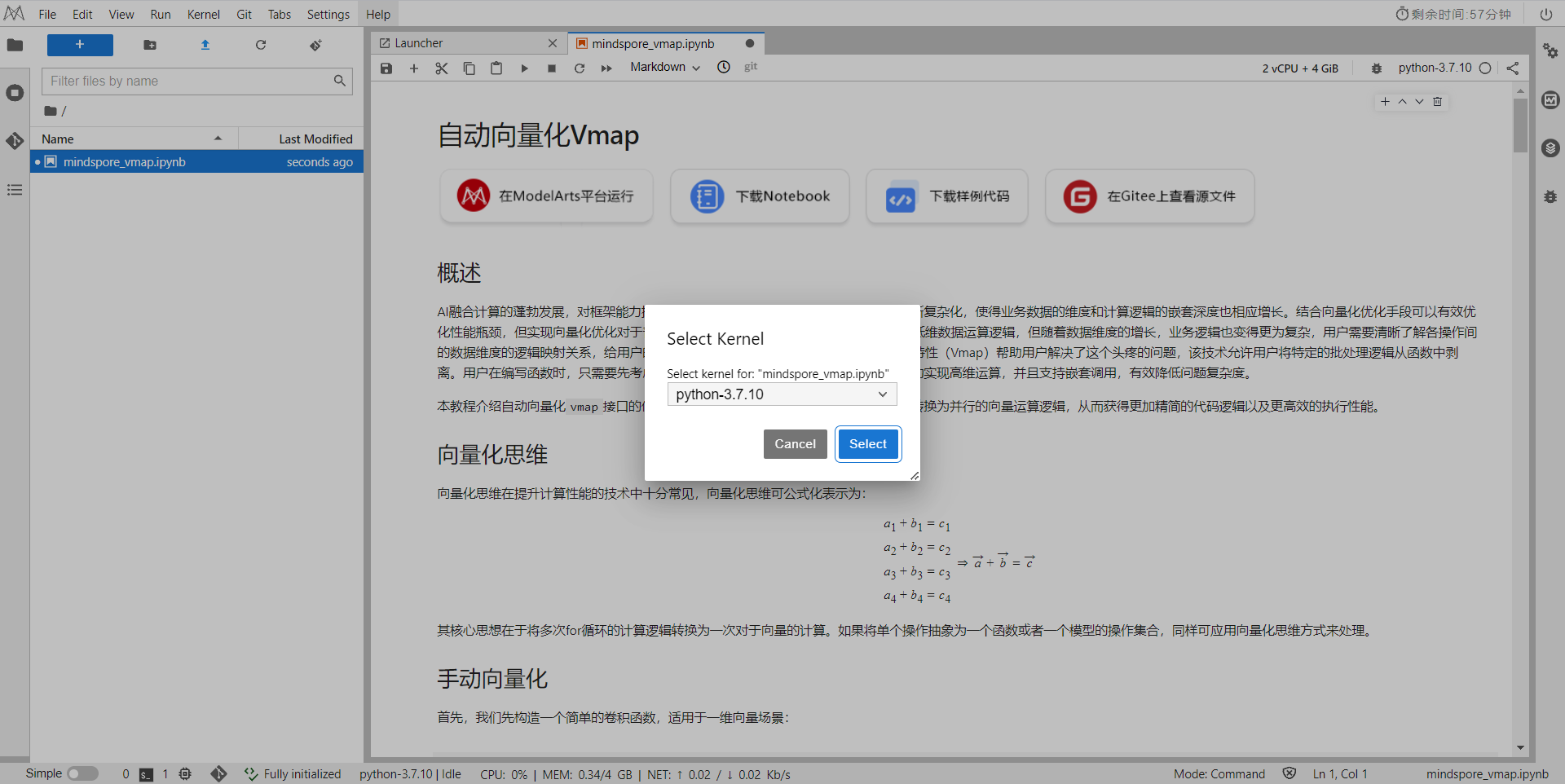
切换至GPU环境,切换成第一个限时免费
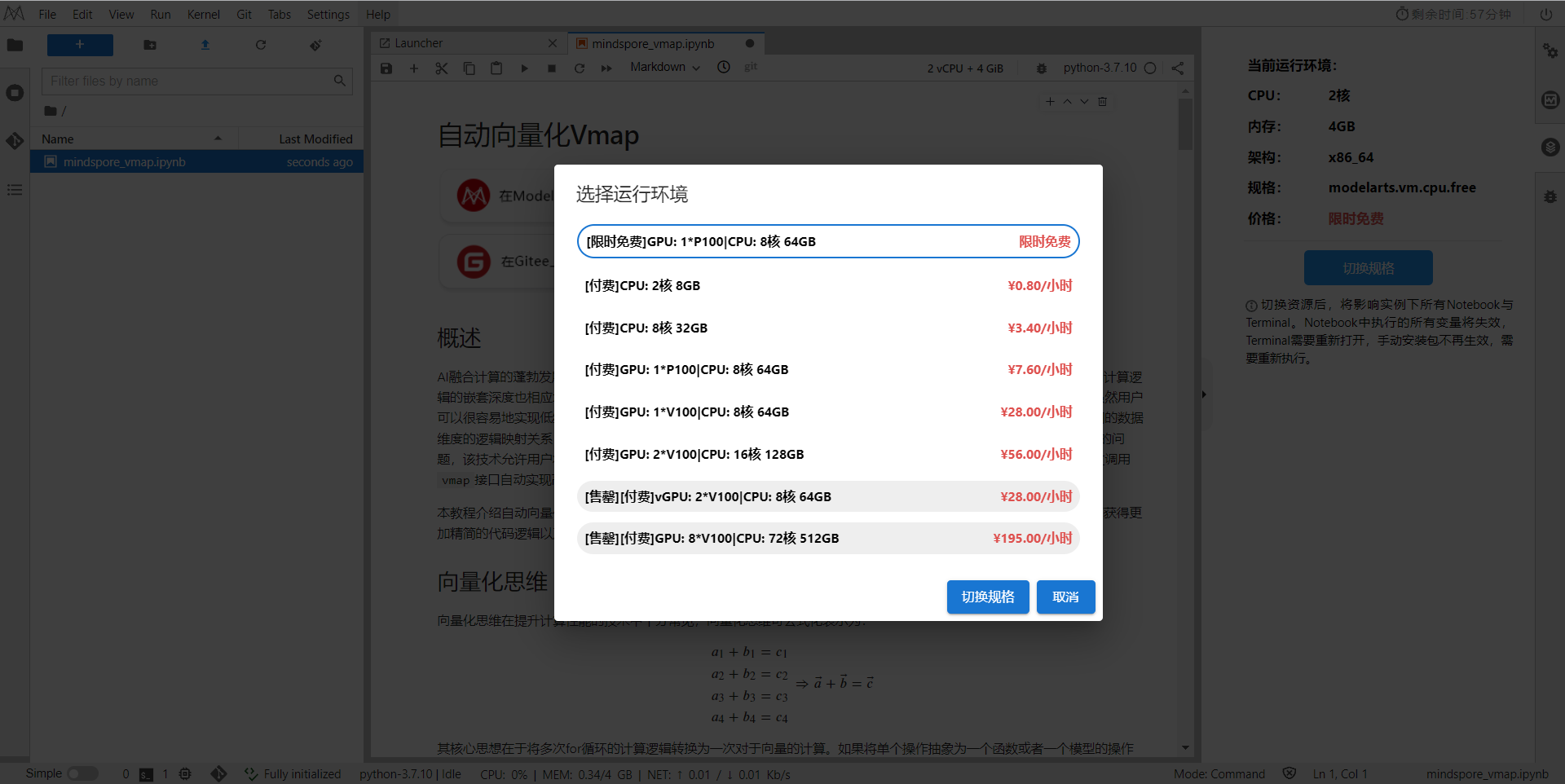
进入昇思MindSpore官网,点击上方的安装

获取安装命令

回到Notebook中,在第一块代码前加入命令
conda update -n base -c defaults conda
安装MindSpore 2.0 GPU版本
conda install mindspore=2.0.0a0 -c mindspore -c conda-forge
安装mindvision
pip install mindvision
二、向量化思维
向量化思维在提升计算性能的技术中十分常见,向量化思维可公式化表示为:
𝑎1+𝑏1=𝑐1𝑎2+𝑏2=𝑐2𝑎3+𝑏3=𝑐3𝑎4+𝑏4=𝑐4⇒𝑎⃗ +𝑏⃗ =𝑐⃗
其核心思想在于将多次for循环的计算逻辑转换为一次对于向量的计算。如果将单个操作抽象为一个函数或者一个模型的操作集合,同样可应用向量化思维方式来处理。
三、手动向量化
首先,我们先构造一个简单的卷积函数,适用于一维向量场景:
import mindspore
from mindspore import Tensor, ops
import mindspore.numpy as mnp
x = mnp.arange(5).astype('float32')
w = mnp.array([1., 2., 3.])
def convolve(x, w):
output = []
for i in range(1, len(x) - 1):
output.append(mnp.dot(x[i - 1 : i + 2], w))
return mnp.stack(output)
convolve(x, w)

Tensor(shape=[3], dtype=Float32, value= [ 8.00000000e+00, 1.40000000e+01, 2.00000000e+01])
当我们期望该函数运用于计算一批一维的卷积运算时,我们很自然地会想到调用for循环进行批处理:
x_batch = mnp.stack([x, x, x])
w_batch = mnp.stack([w, w, w])
def manually_batch_conv(x_batch, w_batch):
output = []
for i in range(x_batch.shape[0]):
output.append(convolve(x_batch[i], w_batch[i]))
return mnp.stack(output)
manually_batch_conv(x_batch, w_batch)

很显然,通过这种实现方式我们能够得到正确的计算结果,但效率并不高。
当然,您也可以通过自己手动重写函数实现更高效率的向量化计算逻辑,但这将涉及对数据的索引、轴等信息的处理。
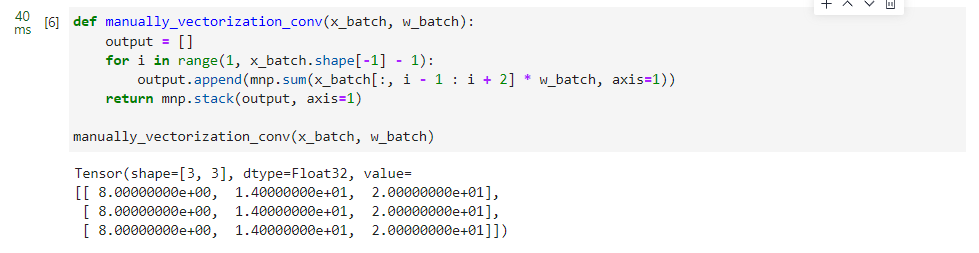
def manually_vectorization_conv(x_batch, w_batch):
output = []
for i in range(1, x_batch.shape[-1] - 1):
output.append(mnp.sum(x_batch[:, i - 1 : i + 2] * w_batch, axis=1))
return mnp.stack(output, axis=1)
manually_vectorization_conv(x_batch, w_batch)
Tensor(shape=[3, 3], dtype=Float32, value=
[[ 8.00000000e+00, 1.40000000e+01, 2.00000000e+01],
[ 8.00000000e+00, 1.40000000e+01, 2.00000000e+01],
[ 8.00000000e+00, 1.40000000e+01, 2.00000000e+01]])
在低维场景下,您可以很容易把握数据索引间的映射逻辑,但随着维度的增加,计算逻辑也变得更为复杂,您或许也会为此混乱的逻辑感到头疼。
幸运的是Vmap为我们提供了另一种实现方式。
四、自动向量化
Vmap可以帮助我们隐藏批处理维度,您只需要调用一个接口便可以将函数转换为向量化形式。
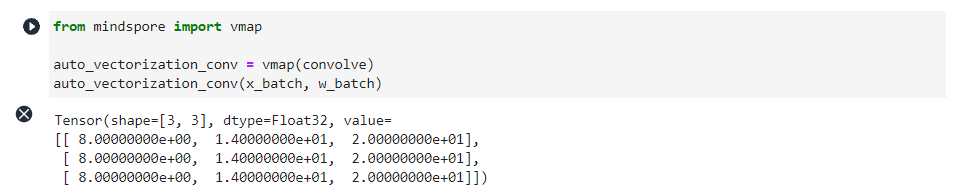
from mindspore import vmap
auto_vectorization_conv = vmap(convolve)
auto_vectorization_conv(x_batch, w_batch)
Tensor(shape=[3, 3], dtype=Float32, value=
[[ 8.00000000e+00, 1.40000000e+01, 2.00000000e+01],
[ 8.00000000e+00, 1.40000000e+01, 2.00000000e+01],
[ 8.00000000e+00, 1.40000000e+01, 2.00000000e+01]])
Vmap除了为您提供了简易的编程体验外,将循环逻辑下沉至函数的各个基元操作中,结合分布式并行优化以获得更高的执行性能。
默认情况下,vmap的输入输出沿第一个轴进行批处理,如果您的输入和输出并不总是期望沿0轴批处理,可以通过in_axes和out_axes参数进行指定。您可以为所有输入或输出位置分别指定批处理轴索引,也可以为所有输入或输出指定相同的批处理轴索引。
w_batch_t = ops.transpose(w_batch, (1, 0))
auto_vectorization_conv = vmap(convolve, in_axes=(0, 1), out_axes=1)
output = auto_vectorization_conv(x_batch, w_batch_t)
ops.transpose(output, (1, 0))

Tensor(shape=[3, 3], dtype=Float32, value=
[[ 8.00000000e+00, 1.40000000e+01, 2.00000000e+01],
[ 8.00000000e+00, 1.40000000e+01, 2.00000000e+01],
[ 8.00000000e+00, 1.40000000e+01, 2.00000000e+01]])
对于多个输入的场景,您还可以指定只对其中的某些入参进行批处理,如上述场景变为求一组一维向量与某一权重的卷积,可在in_axes参数中的输入对应位置配置None即可,None表示不沿任何轴进行批处理。
auto_vectorization_conv = vmap(convolve, in_axes=(0, None), out_axes=0)
auto_vectorization_conv(x_batch, w)

Tensor(shape=[3, 3], dtype=Float32, value=
[[ 8.00000000e+00, 1.40000000e+01, 2.00000000e+01],
[ 8.00000000e+00, 1.40000000e+01, 2.00000000e+01],
[ 8.00000000e+00, 1.40000000e+01, 2.00000000e+01]])
为保证自动向量化计算逻辑的正确性,vmap内部会根据输入的维度和轴索引以及批处理大小等信息进行校验,详细参数限制可参考mindspore.vmap。
高阶函数的嵌套
Vmap本质上是一种高阶函数,它将函数作为输入,并返回可应用于批处理数据的向量化函数。用法上它允许和其他框架提供的高阶函数进行嵌套组合使用。
vmap与vmap嵌套使用,应用于两层以上的批处理逻辑。
hyper_x = Tensor([[1., 2., 3., 4., 5.], [2., 3., 4., 5., 6.], [3., 4., 5., 6., 7.]], mindspore.float32)
hyper_w = Tensor([[1., 1., 1.], [2., 2., 2.], [3., 3., 3.]], mindspore.float32)
hyper_vmap_ger = vmap(vmap(convolve, in_axes=[None, 0]), in_axes=[0, None])
hyper_vmap_ger(hyper_x, hyper_w)
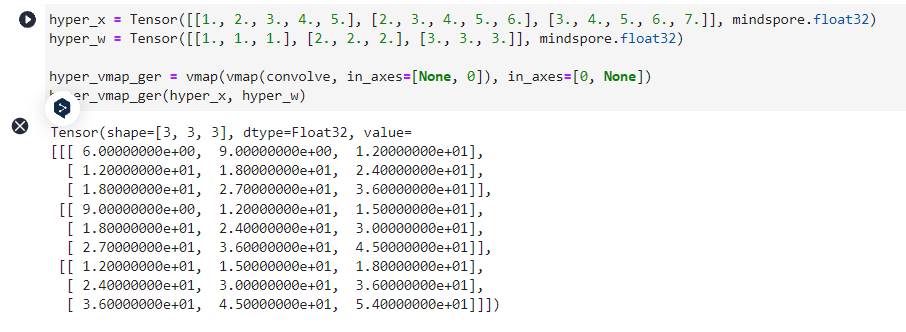
Tensor(shape=[3, 3, 3], dtype=Float32, value=
[[[ 6.00000000e+00, 9.00000000e+00, 1.20000000e+01],
[ 1.20000000e+01, 1.80000000e+01, 2.40000000e+01],
[ 1.80000000e+01, 2.70000000e+01, 3.60000000e+01]],
[[ 9.00000000e+00, 1.20000000e+01, 1.50000000e+01],
[ 1.80000000e+01, 2.40000000e+01, 3.00000000e+01],
[ 2.70000000e+01, 3.60000000e+01, 4.50000000e+01]],
[[ 1.20000000e+01, 1.50000000e+01, 1.80000000e+01],
[ 2.40000000e+01, 3.00000000e+01, 3.60000000e+01],
[ 3.60000000e+01, 4.50000000e+01, 5.40000000e+01]]])
grad内部嵌套vmap使用,应用于计算向量化函数的梯度等场景。
from mindspore import grad
def forward_fn(x, y):
out = x + 2 * y
out = ops.sin(out)
return ops.reduce_sum(out)
x_hat = Tensor([[1., 2., 3.], [2., 3., 4.]], mindspore.float32)
y_hat = Tensor([[2., 3., 4.], [3., 4., 5.]], mindspore.float32)
grad_vmap_ger = grad(vmap(forward_fn), grad_position=(0, 1))
grad_vmap_ger(x_hat, y_hat)
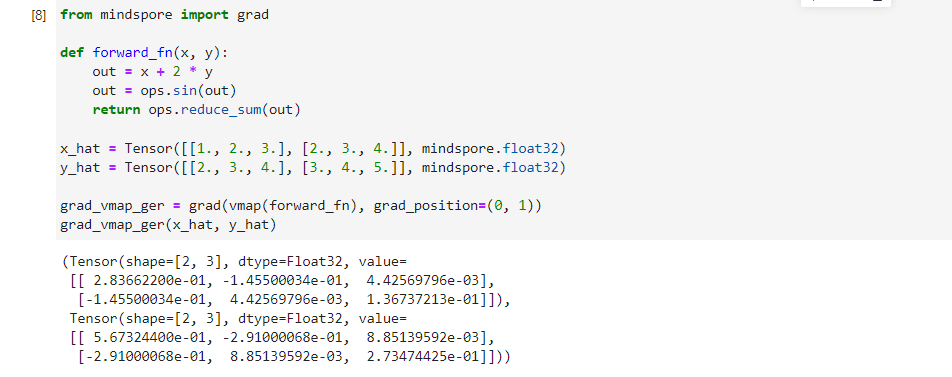
(Tensor(shape=[2, 3], dtype=Float32, value=
[[ 2.83662200e-01, -1.45500034e-01, 4.42569796e-03],
[-1.45500034e-01, 4.42569796e-03, 1.36737213e-01]]),
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 5.67324400e-01, -2.91000068e-01, 8.85139592e-03],
[-2.91000068e-01, 8.85139592e-03, 2.73474425e-01]]))
vmap内部嵌套grad使用,应用于计算批量梯度、高阶梯度计算等场景,如计算Jacobian矩阵。
vmap_grad_ger = vmap(grad(forward_fn, grad_position=(0, 1)))
vmap_grad_ger(x_hat, y_hat)
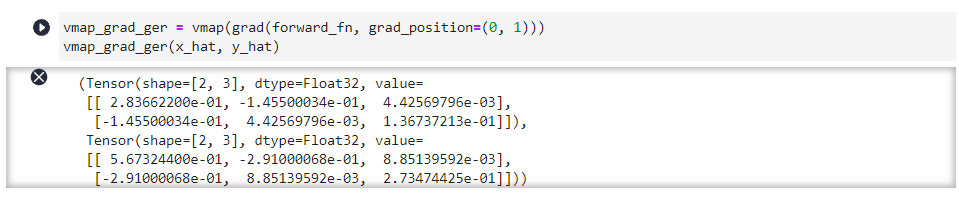
(Tensor(shape=[2, 3], dtype=Float32, value=
[[ 2.83662200e-01, -1.45500034e-01, 4.42569796e-03],
[-1.45500034e-01, 4.42569796e-03, 1.36737213e-01]]),
Tensor(shape=[2, 3], dtype=Float32, value=
[[ 5.67324400e-01, -2.91000068e-01, 8.85139592e-03],
[-2.91000068e-01, 8.85139592e-03, 2.73474425e-01]]))
Cell的自动向量化
之前的用例我们都是以函数对象作为输入,下面将介绍Cell对象结合vmap的用法。这是一个简单定义的全连接层的例子。
import mindspore.nn as nn
from mindspore import Parameter
from mindspore.common.initializer import initializer
class Dense(nn.Cell):
def __init__(self, in_channels, out_channels, weight_init='normal', bias_init='zeros'):
super(Dense, self).__init__()
self.scalar = 1
self.weight = Parameter(initializer(weight_init, [out_channels, in_channels]), name="weight")
self.bias = Parameter(initializer(bias_init, [out_channels]), name="bias")
self.matmul = ops.MatMul(transpose_b=True)
self.bias_add = ops.BiasAdd()
def construct(self, x):
x = self.matmul(x, self.weight)
output = self.bias_add(x, self.bias)
return output
input_a = Tensor([[1, 2, 3], [4, 5, 6]], mindspore.float32)
input_b = Tensor([[2, 3, 4], [5, 6, 7]], mindspore.float32)
input_c = Tensor([[3, 4, 5], [6, 7, 8]], mindspore.float32)
dense_net = Dense(3, 4)
print(dense_net(input_a))
print(dense_net(input_b))
print(dense_net(input_c))
inputs = mnp.stack([input_a, input_b, input_c])
vmap_dense_net = vmap(dense_net)
print(vmap_dense_net(inputs))
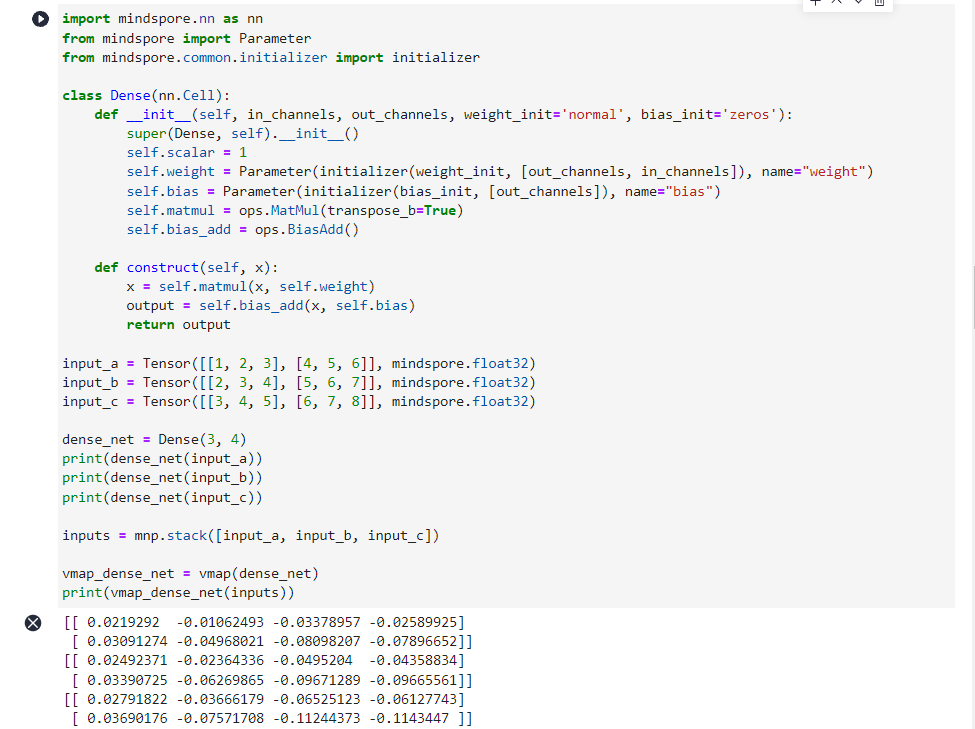
[[ 0.0219292 -0.01062493 -0.03378957 -0.02589925]
[ 0.03091274 -0.04968021 -0.08098207 -0.07896652]]
[[ 0.02492371 -0.02364336 -0.0495204 -0.04358834]
[ 0.03390725 -0.06269865 -0.09671289 -0.09665561]]
[[ 0.02791822 -0.03666179 -0.06525123 -0.06127743]
[ 0.03690176 -0.07571708 -0.11244373 -0.1143447 ]]
[[[ 0.0219292 -0.01062493 -0.03378957 -0.02589925]
[ 0.03091274 -0.04968021 -0.08098207 -0.07896652]]
[[ 0.02492371 -0.02364336 -0.0495204 -0.04358834]
[ 0.03390725 -0.06269865 -0.09671289 -0.09665561]]
[[ 0.02791822 -0.03666179 -0.06525123 -0.06127743]
[ 0.03690176 -0.07571708 -0.11244373 -0.1143447 ]]]
Cell和函数式的自动向量化用法基本一致,只需要将vmap的第一个入参替换为Cell实例即可,Vmap将construct转换为作用于批处理数据的向量化construct。另外,该用例中初始化函数定义了两个Parameter参数,
Vmap对于这类执行函数的自由变量的处理等同于将其作为入参并配置对应in_axes位置为None的场景。
通过这种方式,我们可以实现批量输入在同一个模型上进行训练或推理等功能,与现有网络模型输入支持batch轴输入的区别在于,利用Vmap实现的批处理维度更加灵活,不局限于NCHW等输入格式。
模型集成场景
模型集成场景将来自多个模型的预测结果组合在一起,传统的实现方式是通过分别在某些输入上运行各个模型,然后将各自的预测结果组合在一起。假如您正在运行的是具有相同架构的模型,那么您可以借助Vmap将它们进行向量化,从而实现加速效果。
该场景下涉及权重数据的向量化,如果您运行的模型是通过函数式编程形式实现,即权重参数在模型外部定义并通过入参传递给模型操作,那您可以直接通过配置in_axes的方式进行相应的批处理。而MindSpore框架为了提供便捷的模型定义功能,绝大部分nn接口的权重参数都在接口内部定义并初始化,这意味着模型中的权重参数在原始Vmap中无法对权重进行批处理,改造成通过入参传递的函数式实现需要额外工作量。不过您不必担心,MindSpore的vmap接口已经替您优化了该场景。您只需要将运行的多个模型实例以CellList的形式传入给vmap,框架即可自动实现权重参数的批处理。
让我们演示如何使用一组简单的CNN模型来实现模型集成推理和训练。
class LeNet5(nn.Cell):
"""
LeNet-5网络结构
"""
def __init__(self, num_class=10, num_channel=1):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid')
self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid')
self.fc1 = nn.Dense(16 * 5 * 5, 120)
self.fc2 = nn.Dense(120, 84)
self.fc3 = nn.Dense(84, num_class)
self.relu = nn.ReLU()
self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
def construct(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.conv2(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x

假设我们正在验证同一模型架构在不同权重参数下的效果,让我们模拟四个已经训练好的模型实例和一份batch大小为16,尺寸为32 x
32的虚拟图像数据集的minibatch。
net1 = LeNet5()
net2 = LeNet5()
net3 = LeNet5()
net4 = LeNet5()
minibatch = Tensor(mnp.randn(3, 1, 32, 32), mindspore.float32)

相较于利用for循环分别运行各个模型后将预测结果集合到一起,Vmap能够一次运行获得多个模型的预测结果。
注意,由于vmap的实现机制,会对设备运行内存有要求,使用vmap可能会占用更多内存,请用户根据实际场景使用。
nets = nn.CellList([net1, net2, net3, net4])
vmap(nets, in_axes=None)(minibatch)
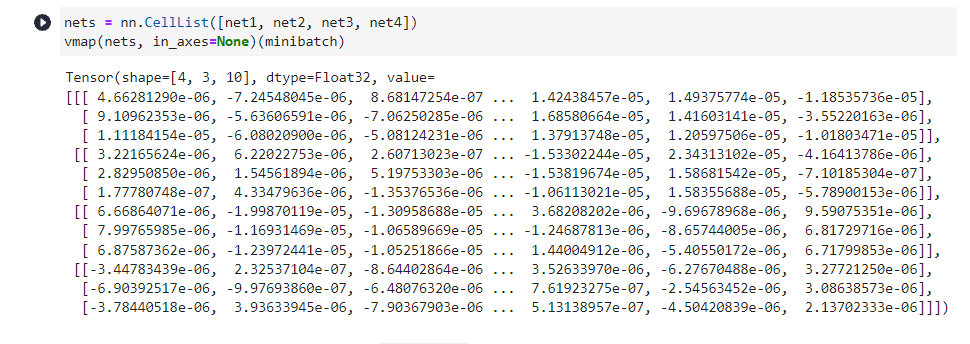
Tensor(shape=[4, 3, 10], dtype=Float32, value=
[[[ 4.66281290e-06, -7.24548045e-06, 8.68147254e-07 ... 1.42438457e-05, 1.49375774e-05, -1.18535736e-05],
[ 9.10962353e-06, -5.63606591e-06, -7.06250285e-06 ... 1.68580664e-05, 1.41603141e-05, -3.55220163e-06],
[ 1.11184154e-05, -6.08020900e-06, -5.08124231e-06 ... 1.37913748e-05, 1.20597506e-05, -1.01803471e-05]],
[[ 3.22165624e-06, 6.22022753e-06, 2.60713023e-07 ... -1.53302244e-05, 2.34313102e-05, -4.16413786e-06],
[ 2.82950850e-06, 1.54561894e-06, 5.19753303e-06 ... -1.53819674e-05, 1.58681542e-05, -7.10185304e-07],
[ 1.77780748e-07, 4.33479636e-06, -1.35376536e-06 ... -1.06113021e-05, 1.58355688e-05, -5.78900153e-06]],
[[ 6.66864071e-06, -1.99870119e-05, -1.30958688e-05 ... 3.68208202e-06, -9.69678968e-06, 9.59075351e-06],
[ 7.99765985e-06, -1.16931469e-05, -1.06589669e-05 ... -1.24687813e-06, -8.65744005e-06, 6.81729716e-06],
[ 6.87587362e-06, -1.23972441e-05, -1.05251866e-05 ... 1.44004912e-06, -5.40550172e-06, 6.71799853e-06]],
[[-3.44783439e-06, 2.32537104e-07, -8.64402864e-06 ... 3.52633970e-06, -6.27670488e-06, 3.27721250e-06],
[-6.90392517e-06, -9.97693860e-07, -6.48076320e-06 ... 7.61923275e-07, -2.54563452e-06, 3.08638573e-06],
[-3.78440518e-06, 3.93633945e-06, -7.90367903e-06 ... 5.13138957e-07, -4.50420839e-06, 2.13702333e-06]]])
又或者,我们期望得到多个模型分别执行不同minibatch数据的预测结果。
模型集成场景下,vmap的第一个入参应为CellList类型,需要确保每个模型的架构完全相同,否则无法保证计算正确性,如果in_axes不为None是需保证模型数量与映射轴索引对应的axis_size一致,以实现一一映射关系。
minibatchs = Tensor(mnp.randn(4, 3, 1, 32, 32), mindspore.float32)
vmap(nets, in_axes=0)(minibatchs)

Tensor(shape=[4, 3, 10], dtype=Float32, value=
[[[ 6.52808285e-06, -4.15002341e-06, -3.80283609e-06 ... 1.54428089e-05, 1.44425348e-05, -9.00016857e-06],
[ 7.39091365e-06, -5.19960076e-06, 3.83916813e-07 ... 1.67857870e-05, 1.80104271e-05, -1.56435199e-05],
[ 1.11604741e-05, -7.59019804e-06, 2.54263796e-07 ... 1.21071571e-05, 1.66683039e-05, -1.09967377e-05]],
[[ 1.48978233e-06, 1.02267529e-06, 1.33801677e-06 ... -1.32894393e-05, 1.36311328e-05, -3.29658405e-06],
[ 1.09956818e-06, -5.06103561e-07, 3.04885953e-06 ... -1.76028752e-05, 1.66466998e-05, -1.17290392e-06],
[ 2.96090502e-06, 1.87074147e-06, 5.76813818e-06 ... -1.09994007e-05, 1.35614964e-05, -2.19983576e-06]],
[[ 6.74323928e-06, -1.03955799e-05, -6.92168396e-06 ... 4.88165415e-06, -5.40378596e-06, 3.09346888e-06],
[ 7.28906161e-06, -1.34921102e-05, -1.00995640e-05 ... 9.44596650e-07, -6.40979761e-06, 1.26146606e-05],
[ 9.43304440e-06, -1.61852931e-05, -1.16265892e-05 ... 5.31926253e-06, -1.28484417e-05, 8.03831313e-07]],
[[-5.51165886e-06, -1.09487860e-06, -6.07781249e-06 ... 7.51453626e-06, -3.29403338e-06, 3.45475746e-06],
[-6.27516283e-06, 1.40756754e-06, -9.18502155e-06 ... 4.16079911e-06, -5.30383022e-06, 5.12517454e-06],
[-6.19608954e-06, 5.12868655e-06, -1.00337056e-05 ... 2.93281119e-07, -6.52256404e-06, 3.62988635e-06]]])
除了支持模型集成推理外,结合Vmap特性同样能够实现模型集成训练。
from mindspore.common.parameter import ParameterTuple
class TrainOneStepNet(nn.Cell):
def __init__(self, net, lr):
super(TrainOneStepNet, self).__init__()
self.loss_fn = nn.WithLossCell(net, nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean'))
self.weight = ParameterTuple(net.trainable_params())
self.adam_optim = nn.Adam(self.weight, learning_rate=lr, use_amsgrad=True)
def construct(self, batch, targets):
loss = self.loss_fn(batch, targets)
grad_weights = grad(self.loss_fn, grad_position=None, weights=self.weight)(batch, targets)
self.adam_optim(grad_weights)
return loss
train_net1 = TrainOneStepNet(net1, lr=1e-2)
train_net2 = TrainOneStepNet(net2, lr=1e-3)
train_net3 = TrainOneStepNet(net3, lr=2e-3)
train_net4 = TrainOneStepNet(net4, lr=3e-3)
train_nets = nn.CellList([train_net1, train_net2, train_net3, train_net4])
model_ensembling_train_one_step = vmap(train_nets)
images = Tensor(mnp.randn(4, 3, 1, 32, 32), mindspore.float32)
labels = Tensor(mnp.randint(1, 10, (4, 3)), mindspore.int32)
for i in range(1, 11):
loss = model_ensembling_train_one_step(images, labels)
print("Step {} - loss: {}".format(i, loss))
vmap(nets, in_axes=None)(minibatch)
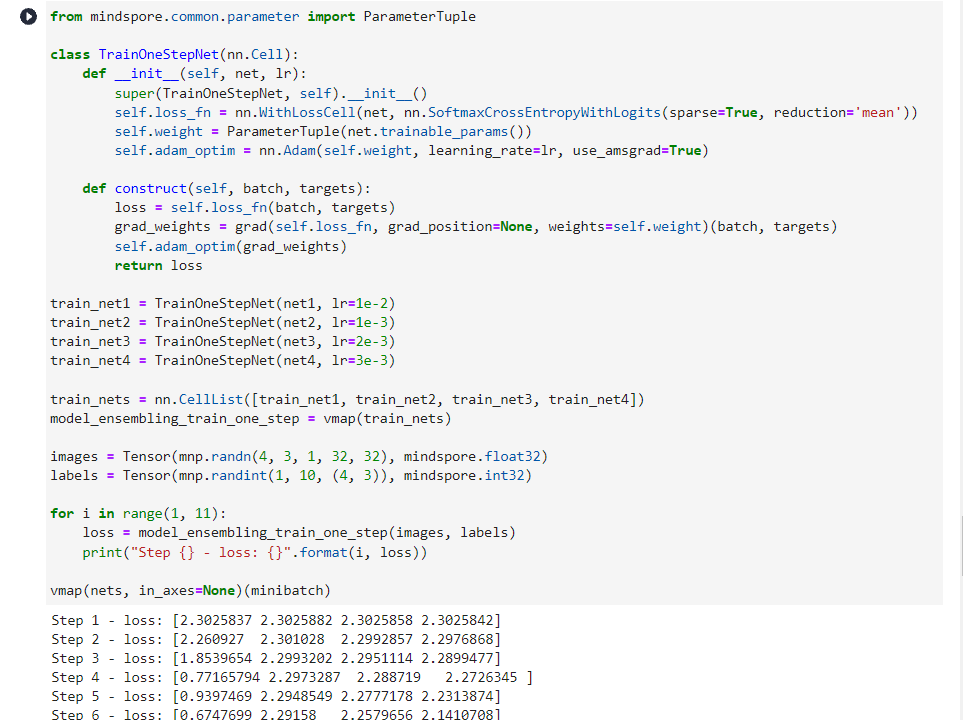
Step 1 - loss: [2.3025837 2.3025882 2.3025858 2.3025842]
Step 2 - loss: [2.260927 2.301028 2.2992857 2.2976868]
Step 3 - loss: [1.8539654 2.2993202 2.2951114 2.2899477]
Step 4 - loss: [0.77165794 2.2973287 2.288719 2.2726345 ]
Step 5 - loss: [0.9397469 2.2948549 2.2777178 2.2313874]
Step 6 - loss: [0.6747699 2.29158 2.2579656 2.1410708]
Step 7 - loss: [0.64673084 2.2870557 2.2232006 1.966973 ]
Step 8 - loss: [1.0506033 2.2806385 2.1645374 1.6848679]
Step 9 - loss: [0.612196 2.2714498 2.0706694 1.3499321]
Step 10 - loss: [0.8843982 2.258316 1.9299208 1.1472267]
Tensor(shape=[4, 3, 10], dtype=Float32, value=
[[[-1.91058636e+01, -1.92182674e+01, 1.06328402e+01 ... -1.87287464e+01, -1.87855473e+01, -2.02504387e+01],
[-1.94767399e+01, -1.95909595e+01, 1.08379564e+01 ... -1.90921249e+01, -1.91503220e+01, -2.06434765e+01],
[-1.96521702e+01, -1.97674465e+01, 1.09355783e+01 ... -1.92643051e+01, -1.93227654e+01, -2.08293762e+01]],
[[-4.07293849e-02, -4.27918807e-02, 5.22112176e-02 ... -4.67570126e-02, -3.88025381e-02, 4.88412194e-02],
[-3.91553082e-02, -4.11494374e-02, 5.00433967e-02 ... -4.48847115e-02, -3.73134986e-02, 4.68519926e-02],
[-3.80369201e-02, -3.99325565e-02, 4.84890938e-02 ... -4.35365662e-02, -3.62745039e-02, 4.54225838e-02]],
[[-5.08784056e-01, -5.05123973e-01, 5.20882547e-01 ... 4.72596169e-01, -5.00697553e-01, -4.60489392e-01],
[-4.80103493e-01, -4.76664037e-01, 4.91507798e-01 ... 4.46062207e-01, -4.72493649e-01, -4.34652239e-01],
[-4.81168061e-01, -4.77702975e-01, 4.92583781e-01 ... 4.47029382e-01, -4.73524809e-01, -4.35579300e-01]],
[[-3.66236401e+00, -3.25362825e+00, 3.51312804e+00 ... 3.77490187e+00, -3.36864424e+00, -3.34358120e+00],
[-3.49160767e+00, -3.10209608e+00, 3.34935308e+00 ... 3.59894991e+00, -3.21167707e+00, -3.18782210e+00],
[-3.57623625e+00, -3.17717075e+00, 3.43059325e+00 ... 3.68615556e+00, -3.28948307e+00, -3.26504302e+00]]])
经过模型集成训练的模型除了可以集成推理之外,仍然可以单独进行推理。
net1(minibatch)

Tensor(shape=[3, 10], dtype=Float32, value=
[[-1.91058636e+01, -1.92182674e+01, 1.06328402e+01 ... -1.87287483e+01, -1.87855473e+01, -2.02504387e+01],
[-1.94767399e+01, -1.95909595e+01, 1.08379564e+01 ... -1.90921249e+01, -1.91503220e+01, -2.06434765e+01],
[-1.96521702e+01, -1.97674465e+01, 1.09355783e+01 ... -1.92643051e+01, -1.93227654e+01, -2.08293762e+01]])
总结
本教程重点在于介绍Vmap的场景使用说明,本质上自动向量化并非将循环逻辑执行于函数外部,而是将循环下沉至函数的各个基元操作中,并将映射轴信息在基元操作间传递,从而保证计算逻辑的正确性。Vmap的性能收益主要来自于各个基元操作所对应的VmapRule实现,由于循环下沉至算子层级,因而更容易结合并行技术进行性能优化,如果您有自定义算子的场景也可以尝试为自定义算子实现特定的VmapRule,从而获得更好的性能。对于性能极致追求的场景还可以再结合图算融合特性进行优化。
Vmap特性当前支持GPU、CPU平台,Ascend平台功能仍在不断完善中。
在Vmap包含控制流的场景中,当前仅支持每个批处理分支具有相同处理操作或控制流逻辑中所有变量均无切分轴的场景。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)