论文地址:https://arxiv.org/abs/1810.09502
Abstract
MAML是目前通过元学习进行少样本学习的最佳方法之一。MAML简单,优雅和非常强大,然而,它有各种各样的问题,如神经网络结构非常敏感,经常导致不稳定,需要艰苦的超参数搜索稳定训练和实现高泛化和计算非常昂贵的训练和推理时间。在本文中,作者对MAML提出了各种修改,不仅稳定了系统,而且大大提高了MAML的泛化性能、收敛速度和计算开销,称之为MAML++。
1 INTRODUCTION
MAML,作者建议学习一个初始化的基本模型,这样应用非常少的梯度步骤对训练集基本模型,适应模型可以实现强大的泛化性能验证集(验证集由新的样本从相同的类训练集)。回到元模型和基模型的定义后,在MAML中,元模型是有效的初始化参数。这些参数用于初始化基本模型,然后将其用于支持集上的特定于任务的学习,然后在目标集上进行评估。MAML是一个简单而优雅的元学习框架,它在许多设置中取得了最先进的结果。然而,MAML遭受各种各样的问题: 1)导致不稳定,2)限制模型的泛化性能,3)减少框架的灵活性,4)增加系统的计算开销5)要求模型经过昂贵的(需要时间和计算)超参数调优之前可以稳健地工作在一个新的任务。
在本文中作者提出了MAML++,一种改进的MAML框架提供MAML的灵活性以及许多改进,如健壮和稳定的训练,自动学习的内环超参数,大大提高了计算效率在推理和训练和显著提高了泛化性能。
3 MODEL AGNOSTIC META LEARNING
MAML为网络学习良好的初始化参数,这样在几镜头数据集上经过几步的标准训练后,网络将在少样本任务上表现良好。
将基本模型定义为一个具有元参数θ的神经网络 。我们想要学习一个初始的θ = θ0,在对来自支持集
。我们想要学习一个初始的θ = θ0,在对来自支持集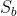 的数据进行少量N次的梯度更新步骤以获得
的数据进行少量N次的梯度更新步骤以获得 后,网络在该任务的目标集
后,网络在该任务的目标集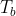 上表现良好。这里b是一批支持集任务中特定支持集任务的索引。这一组N个更新步骤被称为内环更新过程。
上表现良好。这里b是一批支持集任务中特定支持集任务的索引。这一组N个更新步骤被称为内环更新过程。
来自支持任务Sb的数据经过i步后更新的基本网络参数可以表示为:

其中α为学习速率, 为在任务b上经过训练i次后的基本网络权重,
为在任务b上经过训练i次后的基本网络权重, 为(i−1)(即上一步骤)更新步骤后支持集的损失。假设我们的任务批处理大小为B,可以定义一个元目标,它可以表示为:
为(i−1)(即上一步骤)更新步骤后支持集的损失。假设我们的任务批处理大小为B,可以定义一个元目标,它可以表示为:

其中,上式已经明确地表示了 对
对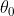 的依赖性,由展开(1)给出。目标(2)根据在所有任务中使用该初始化的总损失来衡量一个初始化的质量。这个元目标现在被最小化,以优化初始参数值。正是这个初始的包含了跨任务的知识。这个元目标的优化被称为外环更新过程
的依赖性,由展开(1)给出。目标(2)根据在所有任务中使用该初始化的总损失来衡量一个初始化的质量。这个元目标现在被最小化,以优化初始参数值。正是这个初始的包含了跨任务的知识。这个元目标的优化被称为外环更新过程
元参数的结果更新可以表示为:

其中,β为一个学习速率, 表示任务b的目标集上的损失。
表示任务b的目标集上的损失。
在本篇论文中,使用交叉熵损失
3.1 MODEL AGNOSTIC META-LEARNING PROBLEMS
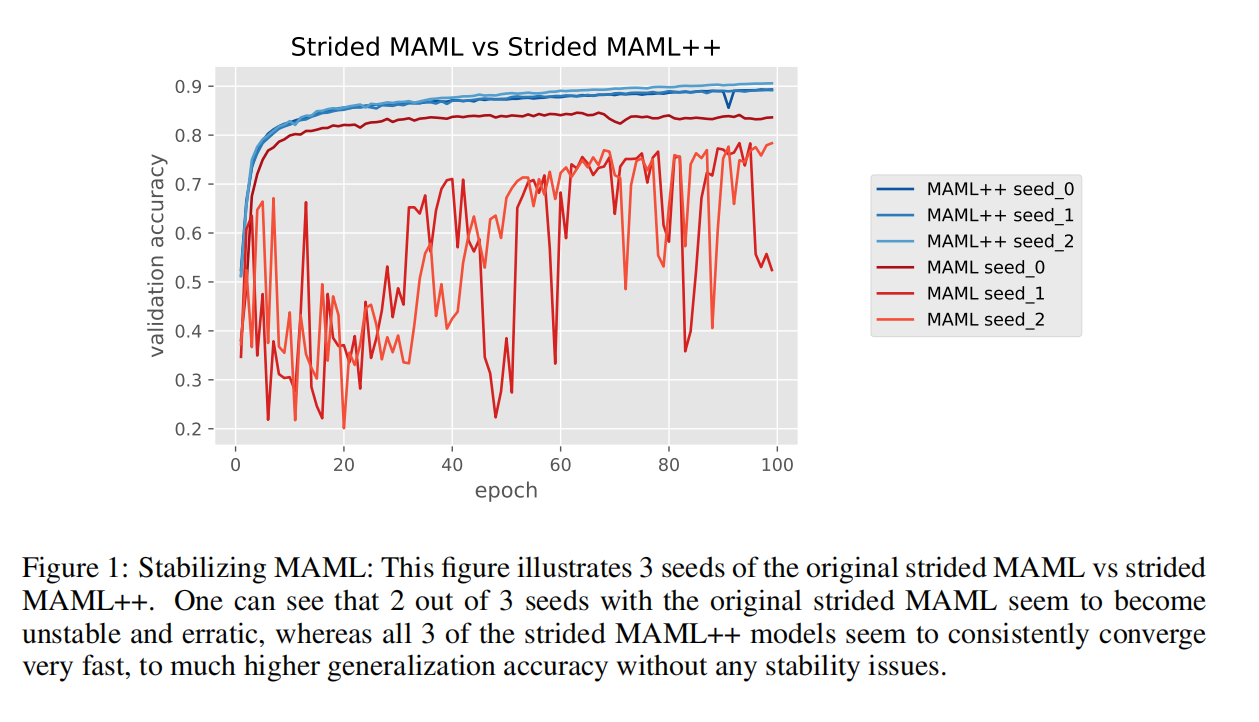
Training Instability: 根据神经网络结构和整体超参数设置,MAML在训练过程中可能非常不稳定,如图1所示。优化外环包括通过由同一网络组成的展开内环反向传播导数。这本身就可能导致梯度问题。然而,梯度问题被模型体系结构进一步复杂化,这是一个标准的没有残差连接的4层卷积网络。没有任何残差连接意味着每个梯度必须多次通过每个卷积层;实际上,这些梯度将乘以相同的一组参数多次。经过多次反向传播后,展开网络的大深度结构和缺乏残差连接会分别导致梯度爆炸和梯度递减问题。
Second Order Derivative Cost: 通过梯度更新步骤进行优化需要计算二阶梯度,这是非常昂贵的计算。MAML的作者提出使用一阶近似来将过程加速3倍,但是使用这些近似可能会对最终的泛化误差产生负面影响。在Reptile中(Nichol等人,2018),作者在基模型上应用标准SGD,然后从初始化参数到基模型参数的步骤。Reptile的结果各不相同,在某些情况下超过MAML,而在其他情况下产生的结果低于MAML。在不牺牲泛化性能的情况下减少计算时间的方法尚未提出。
Absence of Batch Normalization Statistic Accumulation: 影响泛化性能的另一个问题是在原始MAML论文的实验中使用批归一化的方式。使用当前批的统计信息用于批规范化,而不是累积运行统计信息。这导致批归一化的效果较差,因为学习到的偏差必须适应各种不同的平均值和标准差,而不是单一的平均值和标准差。另一方面,如果批归一化使用累积的运行统计量,它最终会收敛到一些全局均值和标准差。这就只留下一个均值和标准差来学习偏差。使用运行统计数据而不是批处理统计数据,可以大大提高收敛速度、稳定性和泛化性能,因为归一化特征将导致更平滑的优化景观(Santurkar et al.,2018)。
Shared (across step) Batch Normalization Bias: MAML中批标准化的另一个问题是,批标准化偏差没有在内环中更新;相反,在所有基础模型的迭代中都使用了相同的偏差。这样做隐式地假设所有的基本模型在整个内部循环更新过程中都是相同的,因此通过它们的特性的分布也同样相同。这是一个错误的假设,因为在每次内环更新中,一个新的基础模型被实例化,它与前一个模型足够不同,从偏差估计的角度来看是一个新的模型。因此,为基础模型的所有迭代学习一组单一的偏差可能会限制性能。
Shared Inner Loop (across step and across parameter) Learning Rate: 影响泛化和收敛速度(就训练迭代而言)的一个问题是对所有参数和所有更新步骤使用共享学习速率的问题。这样做会引入两个主要问题。有一个固定的学习速率需要进行多个超参数搜索来找到特定数据集的正确学习率;这个过程的计算代价非常高,这取决于搜索是如何完成的。
作者在(Li et al.,2017)中提出了为网络的每个参数学习学习速率和更新方向。这样做解决了必须手动搜索正确的学习率的问题,也允许单个参数有更小或更大的学习率。然而,这种方法也带来了它自己的问题。学习每个网络参数的学习速率意味着增加计算工作量和增加内存使用,因为网络包含在40K到50K之间的参数,这取决于数据点的维数。
Fixed Outer Loop Learning Rate: 在MAML中,作者使用具有固定学习率的Adam来优化元目标。使用分段调度或余弦函数退火学习速率已被证明对在多种设置下实现最先进的泛化性能至关重要。因此,我们认为使用静态学习速率会降低MAML的泛化性能,这也可能是优化速度较慢的一个原因。此外,有一个固定的学习速率可能意味着必须花费更多的(计算)时间来调整学习速率。
4 STABLE, AUTOMATED AND IMPROVED MAML
Gradient Instability → Multi-Step Loss Optimization (MSL): MAML的工作原理是在基础网络完成对支持集任务的所有内环更新后计算的目标集损失。相反,我们建议在实现支持集任务的每一步之后,最小化由基础网络计算的目标集损失。更具体地说,我们提出损失最小化是每次支持集损失更新后的目标集损失的加权和。公式:

β是一个学习率,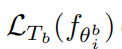 表示在任务b上训练i次的目标集损失,
表示在任务b上训练i次的目标集损失,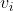 表示每次目标集损失的权重。
表示每次目标集损失的权重。
通过使用上面提出的多步长损失,我们改进了梯度传播,因为现在每一步的基础权重直接接收梯度(对于当前的步长损失)和间接接收梯度(来自后续步骤的损失)。在第3节中描述的原始方法中,除了最后一个步骤外,每一步的基本网络权值都由于反向传播而被隐式地优化,这导致了MAML存在的许多不稳定性问题。然而,使用多步骤损失缓解了这个问题,如图1所示。此外,我们采用了对每一步的损失的退火加权。最初,所有的损失对总体损失的贡献都是相等的,但随着迭代次数的增加,我们减少了早期步骤的贡献,并缓慢地增加了后期步骤的贡献。这样做是为了确保随着训练的进行,最后一步的损失得到了优化器更多的关注,从而确保它达到了可能的最低损失。如果不使用退火,我们发现最终的损失可能高于原始方法。
Second Order Derivative Cost → Derivative-Order Annealing (DA): 使MAML提高计算效率的一种方法是减少所需的内环更新的数量在这一段中,我们提出了一种直接减少每步计算开销的方法。MAML的作者提出了使用梯度导数的一阶近似。然而,他们在整个训练阶段都应用了一阶近似。相反,我们建议随着训练的进展而退火导数顺序。更具体地说,我们建议在训练阶段的前50个阶段内使用一阶梯度,然后在训练阶段的剩余时间内切换到二阶梯度。更具体地说,我们建议在训练阶段的前50个阶段内使用一阶梯度,然后在训练阶段的剩余时间内切换到二阶梯度。我们的经验证明,这样做大大加快了前50个epoch,同时允许二阶训练,以实现二阶梯度为模型提供的强泛化性能。另一个有趣的观察结果是,导数阶退火实验显示没有发生爆炸或递减的梯度,这与更不稳定的二阶实验相反。在开始使用二阶导数之前使用一阶参数可以作为一种强的预训练方法,它可以学习不太可能产生梯度爆炸/递减问题的参数。
Absence of Batch Normalization Statistic Accumulation → Per-Step Batch Normalization Running Statistics (BNRS): 在MAML 的原始实现中,作者仅使用当前的批处理统计数据作为批处理归一化统计数据。我们认为,这导致了第3.1节中描述的各种不良影响。为了缓解这些问题,我们建议使用运行的批处理统计信息来进行批处理标准化。在MAML上下文中,批规范化的简单实现需要在内环快速知识获取过程的所有更新步骤中共享运行的批统计信息。然而,这样做会导致不希望的结果,即存储的统计信息在网络的所有内环更新中共享。这将导致优化问题,并可能减慢或完全停止优化,因为学习参数的复杂性越来越增加,可以在网络参数的各种更新中工作。一个更好的选择是按步制收集统计数据。为了收集每步运行统计数据,需要实例化网络中每个批标准化层的运行均值集(其中N为内环更新步骤的总数)和运行标准差集,并分别通过优化过程中所采取的步骤来更新运行统计数据。每步批标准化方法应该加快MAML的优化,同时潜在地提高泛化性能。
Shared (across step) Batch Normalization Bias → Per-Step Batch Normalization Weights and Biases (BNWB): 在MAML的论文中,作者训练了他们的模型来学习每一层的一组偏差。这样做是为了假设通过网络的特征的分布是相似的。然而,这是一个错误的假设,因为基本模型被更新了很多次,从而使得特征分布彼此之间越来越不同。为了解决这个问题,我们建议在内环更新过程中每一步学习一组偏差。这样做,意味着批处理标准化将学习到特定于在每个集合上看到的特征分布的偏差,这将提高收敛速度、稳定性和泛化性能。
Shared Inner Loop Learning Rate (across step and across parameter) → Learning Per-Layer Per-Step Learning Rates and Gradient Directions (LSLR): Li等人(2017)之前的工作表明,学习基础结构中每个参数的学习速率和梯度方向可以提高系统的泛化性能。然而,这也导致了参数数量的增加和计算开销的增加。因此,我们建议,学习网络中每一层的学习速率和方向,以及在基础网络的每个适应过程中学习不同的学习速率。为每个参数学习每个层的学习速率和方向应该会减少所需的内存和计算,同时在更新步骤中提供额外的灵活性。此外,对于每个学习的学习速率,将有N个学习速率的实例,每一步将采取一个。通过这样做,参数可以自由地学习降低每一步的学习率,这可能有助于缓解过拟合。
Fixed Outer Loop Learning Rate → Cosine Annealing of Meta-Optimizer Learning Rate
(CA): 在MAML中,作者使用了一个静态的学习速率来实现元模型的优化器。通过使用阶跃函数(He et al.,2016)或余弦函数(Loshchilov & Hutter,2016)来退火学习速率,在具有更高泛化能力的学习模型中已被证明是至关重要的。余弦退火调度在产生最先进的结果方面特别有效,同时消除了在学习速率空间上进行任何超参数搜索的需要。因此,我们建议将余弦退火调度应用于元模型的优化器(即元优化器)。退火学习速率可以使模型更有效地拟合训练集,从而产生更高的泛化性能。
4.1 DATASETS
Omniglot和Mini-Imagenet
4.2 EXPERIMENTS
4.3 RESULTS
每种提出的方法都可以单独优于MAML,然而,最显著的改进来自于每层学习的每步学习率和每步批处理标准化方法。在5 way 1-shot任务中达到99.47%,在20 way Omniglot任务中,MAML++在1-shot和5-shot任务中分别达到97.76%和99.33%。MAML++还展示了在达到最佳验证性能所需的训练迭代方面改进的收敛速度。此外,多步损失优化技术大大提高了模型的训练稳定性,如图1所示。

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)