这篇文章是MAML的升级版本,即MAML++。他针对MAML的一些不足之处做了对应的改进,如稳定性、收敛速度、表现力等均得到提升。
由于自己的算法实现中有用到MAML,为了让整体算法有一个好的性能,就来阅读了下这篇MAML升级版——MAML++。
参考列表:
①MAML++论文解读
②模拟退火算法简介
③模拟退火算法详解
④MAML++PyTorch源码
How to Train your MAML
- 前言
-
- MAML
-
- MAML++
- 存在的6个问题
- Q1 Training Instability
- Q2 Second Order Derivative Cost
- Q3 Absence of Batch Normalization Statistic Accumulation
- Q4 Shared (across step) BN Bias
- Q5 Shared Inner Loop (across step and parameter) Lr
- Q6 Fixed Outer Loop Lr
- MAML++的解决方案
- Multi-Step Loss Optimization
- Derivative Annealing
- LSLR
- CA
- 实验结果
- 总结
前言
作者指出MAML的不足之处,针对这些不足之处做出相应改善,形成MAML++算法。
MAML的不足之处
- 对网络结构敏感。
- MAML训练不稳定。
- MAML需要进行较大的超参数调节。
- 计算量大。
MAML vs MAML++
Figure 1:
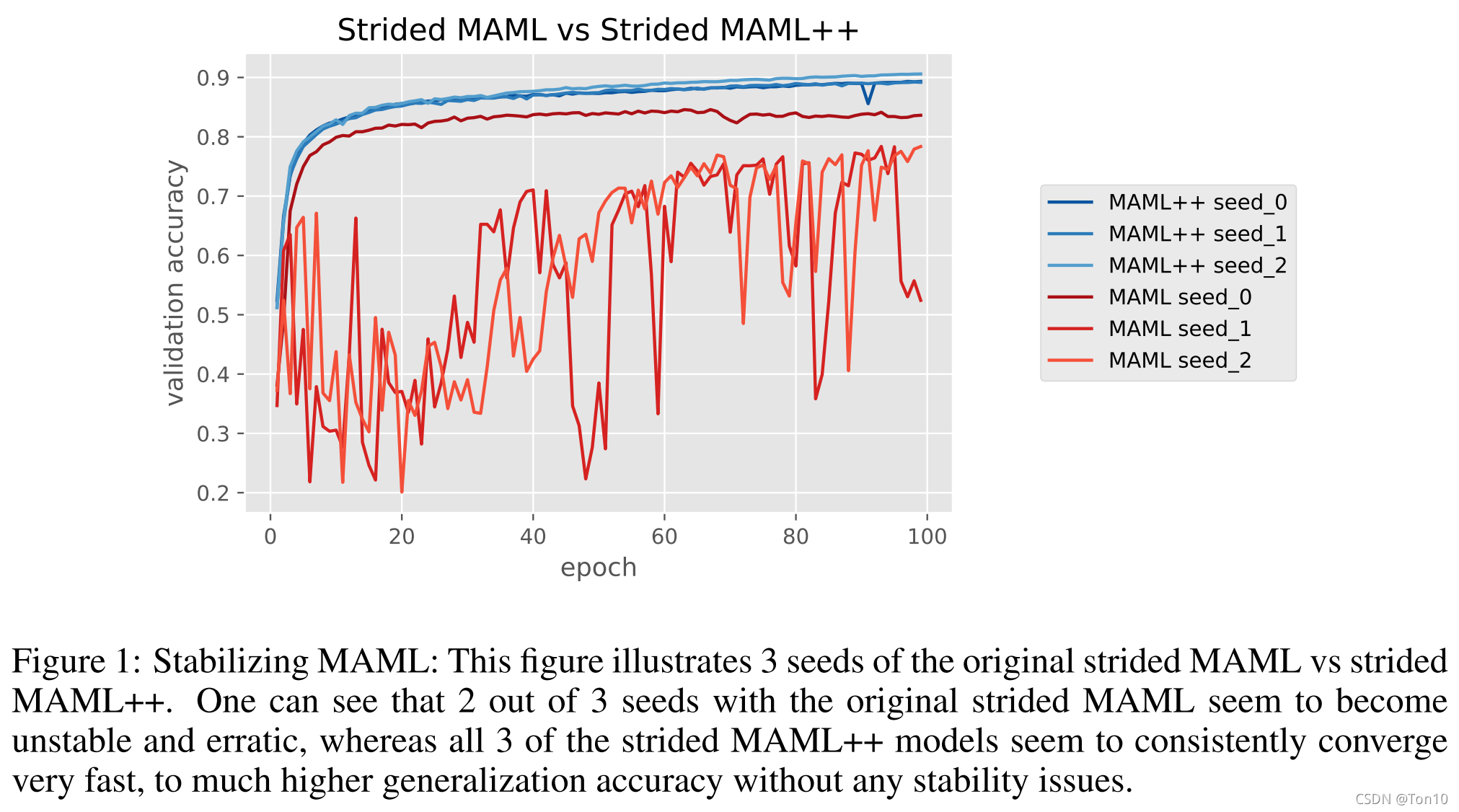
这是一组在MAML和MAML++之间对比的结果,可以看出MAML++在训练过程中更加稳定、收敛速度更快且表现力更强(正确率)。
MAML
MAML是2017年的paper,应该是比较熟悉的一篇文章了。
MAML简介
①关于MAML论文笔记,点这里。
②关于MAML简化版本FOMAML,点这里。
③关于MAML升级版本Meta-SGD,点这里。
MAML的功能
学习到一个既具备可以适应到很多环境(或者叫task),又可以快速适应(指内更新只更新一次)到具体某个新的task上的合适的参数。
合适的含义:假设参数都是一维的
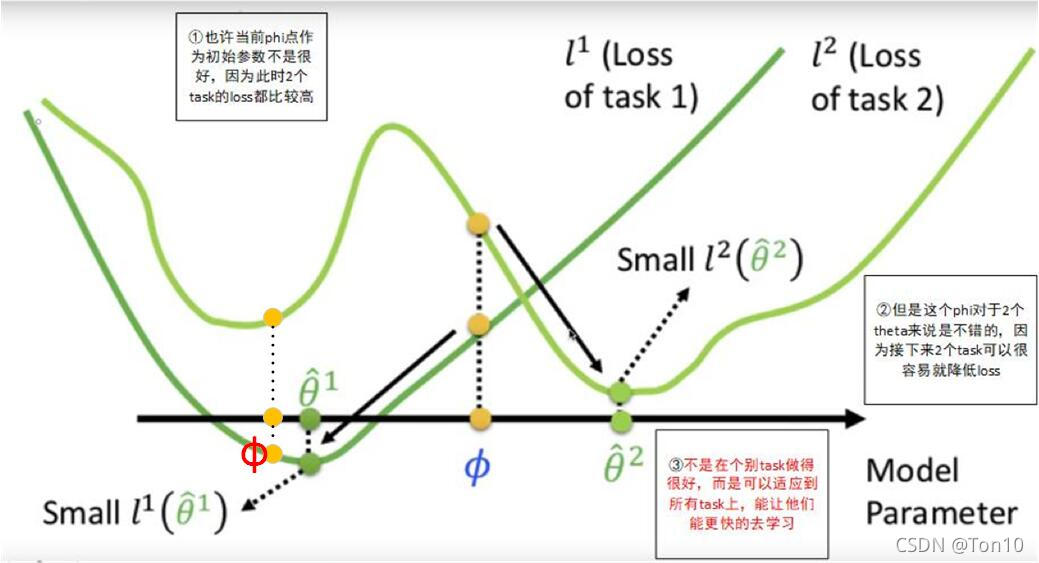
- MAML的训练结果是蓝色的
ϕ
\phi
ϕ,而不是红色的
ϕ
\phi
ϕ。
- 虽然红色的
ϕ
\phi
ϕ在2个
l
o
s
s
loss
loss上拥有更低的值,但是MAML训练的目标是要降低Fast-weights
θ
\theta
θ在各自task上的
l
o
s
s
loss
loss。
- 显然蓝色的
ϕ
\phi
ϕ在经过一次内更新之后可以更快速地使
θ
1
\theta_1
θ1、
θ
2
\theta_2
θ2在各自地task上达到最低的
l
o
s
s
loss
loss;而红色的
ϕ
\phi
ϕ很难通过一次更新使得
θ
2
\theta_2
θ2到达属于task2的最低
l
o
s
s
loss
loss点。
- 因此MAML训练的核心就是训练出一个Meta-Learner的参数
ϕ
\phi
ϕ,要求是这个
ϕ
\phi
ϕ经过一次内更新之后得到的
θ
\theta
θ在各自的task上达到最低的
l
o
s
s
loss
loss值。这里要注意的是——不是
∑
i
L
T
i
(
f
i
(
ϕ
)
)
\sum_i\mathcal{L}_{\mathcal{T}_i}(f_i(\phi))
∑iLTi(fi(ϕ))最低,而是要
∑
i
L
T
i
(
f
i
(
θ
i
)
)
\sum_i\mathcal{L}_{\mathcal{T}_i}(f_i(\theta_i))
∑iLTi(fi(θi))最低。
- 综上所述,也许当前蓝色
ϕ
\phi
ϕ作为初始参数不是很好,因为此时2个task的
l
o
s
s
loss
loss都比较高;但是这个
ϕ
\phi
ϕ对于2个
θ
\theta
θ来说是不错的,因为接下来2个task可以很容易就降低
l
o
s
s
loss
loss;MAML训练的目标不是在个别task上做到最优参数
θ
∗
\theta^*
θ∗,而是可以适应到所有task上,能让他们更快的去学习,这也就是为什么MAML的
L
o
s
s
Loss
Loss设计成所有task的
l
o
s
s
loss
loss之和的平均。
MAML核心公式
设
θ
=
θ
0
\theta=\theta_0
θ=θ0是Meta-Learner的参数
ϕ
\phi
ϕ的初始值,一般都做随机化处理;
S
b
S_b
Sb是support-set;
θ
i
b
\theta^b_i
θib是task b在第
i
i
i次更新之后的Learner参数,故对于每一个task b,MAML的内更新为:
θ
i
b
=
θ
i
−
1
b
−
α
∇
θ
L
S
b
(
f
θ
i
−
1
b
(
θ
i
−
1
b
)
)
(1)
\theta^b_i=\theta^b_{i-1}-\alpha\nabla_\theta\mathcal{L}_{S_b}(f_{\theta^b_{i-1}}(\theta^b_{i-1}))\tag{1}
θib=θi−1b−α∇θLSb(fθi−1b(θi−1b))(1)虽然MAML的特点就是更新一次,并不是说只能更新一次。
设
θ
N
b
(
θ
0
)
\theta_N^b(\theta_0)
θNb(θ0)表示从
θ
0
\theta_0
θ0开始,在task b上内更新N次到达的参数值;
T
b
T_b
Tb指的是在Query-set,故MAML外更新的目标函数为:
L
m
e
t
a
(
θ
0
)
=
∑
b
=
1
B
L
T
b
(
f
θ
N
b
(
θ
0
)
(
θ
N
b
)
)
(2)
\mathcal{L}_{meta}(\theta_0) = \sum^{\mathcal{B}}_{b=1}\mathcal{L}_{T_b}(f_{\theta^b_N(\theta_0)}(\theta^b_N))\tag{2}
Lmeta(θ0)=b=1∑BLTb(fθNb(θ0)(θNb))(2)外更新的目标函数和内更新不一样,外更新是在所有task上的平均值。需要注意的
θ
N
b
(
θ
0
)
\theta^b_N(\theta_0)
θNb(θ0)是在Query-set做的update,FOMAML就是在此基础上对MAML进行简化——省去了二阶导数的求取。
有了损失函数,就可以做MAML的外更新:
θ
0
=
θ
0
−
β
∇
θ
∑
b
=
1
B
L
T
b
(
f
θ
N
b
(
θ
0
)
)
(3)
\theta_0 = \theta_0 - \beta\nabla_\theta\sum^\mathcal{B}_{b=1}\mathcal{L}_{T_b}(f_{\theta^b_N(\theta_0)})\tag{3}
θ0=θ0−β∇θb=1∑BLTb(fθNb(θ0))(3)可以看出来标准的MAML算法对网络权值的更新是基于最后一个时间步
N
N
N上所有测试集上损失函数的平均值;每一次时间步从
0
→
N
0\to N
0→N都是在同一个测试集上完成的。
MAML++
文章的论述结构就是指出MAML的6个问题,然后针对6个问题提出改进方案,也就是说改进了MAML一路过关升级,灭掉自己存在6个问题之后,就能升级到MAML++。
存在的6个问题
Q1 Training Instability
作者指出MAML的训练很不稳定。我们在做外循环的时候,由于Fast_weights需要多次通过网络产生,那么在从外循环backward的时候,就会从外循环梯度回传到内循环,并且网络的每一层都会被回传好几次,这样就会容易产生梯度爆炸或者梯度衰减,就很麻烦。并且如果你的网络结构的深度很大时,那么别说整个网络会被传几次的问题了,光传完一个网络就可能出现梯度爆炸或者梯度衰减。那么当梯度值会出现较大的问题时,参数的更新自然就会出事,那么通过这个参数产生的结果出现不稳定现象也是正常的,详情见上述Figure 1。针对梯度不稳定现象,作者提出了MSL(详情见后文)来解决。
Q2 Second Order Derivative Cost
标准MAML使用全二阶偏导下的参数更新,虽然理论上会很好的泛化性能,但是对计算资源与训练时间的消耗是不友好的。
Q3 Absence of Batch Normalization Statistic Accumulation
由于这部分在自己的算法中没有涉及,就没有去详细了解。
Q4 Shared (across step) BN Bias
由于这部分在自己的算法中没有涉及,就没有去详细了解。
Q5 Shared Inner Loop (across step and parameter) Lr
MAML有一个升级版本叫Meta-SGD,是一种去自己学习MAML内更新学习率
α
\alpha
α的元学习算法。该算法实现简单,但是由于需要针对model的每一个参数去学习一个learning rate,故对于计算资源以及存储资源的消耗是很大的,尤其是当你的model具有很大的参数的时候,Meta-SGD确实需要消耗一部分存储资源。
Q6 Fixed Outer Loop Lr
标准MAML的外循环采用固定学习率
β
\beta
β,这就意味着需要花费一定的时间去找到一个合适的学习率,这种静态学习率会使得算法不那么灵活。
MAML++的解决方案
Multi-Step Loss Optimization
这个MSL是用于解决MAML不稳定性的,也是全文这么多技巧中最有效的方法,它主要由2部分组成:
-
标准的MAML算法如公式(3)所示,meta-learner参数的更新取决于所有测试集上最后一步的loss值,因此你拿着这个值去做backward的时候,之前几个step的参数只能被隐式的优化,他们产生的loss无法直接拿来显式的优化,因此算法的稳定性就会欠缺一些。因此其核心思想就是改单步(最后一个step)为多步(Multi-Step)。属于是用消耗训练时间、计算量的代价来换取算法的稳定性,因为你反向传播的次数会变多。具体的loss结构如下: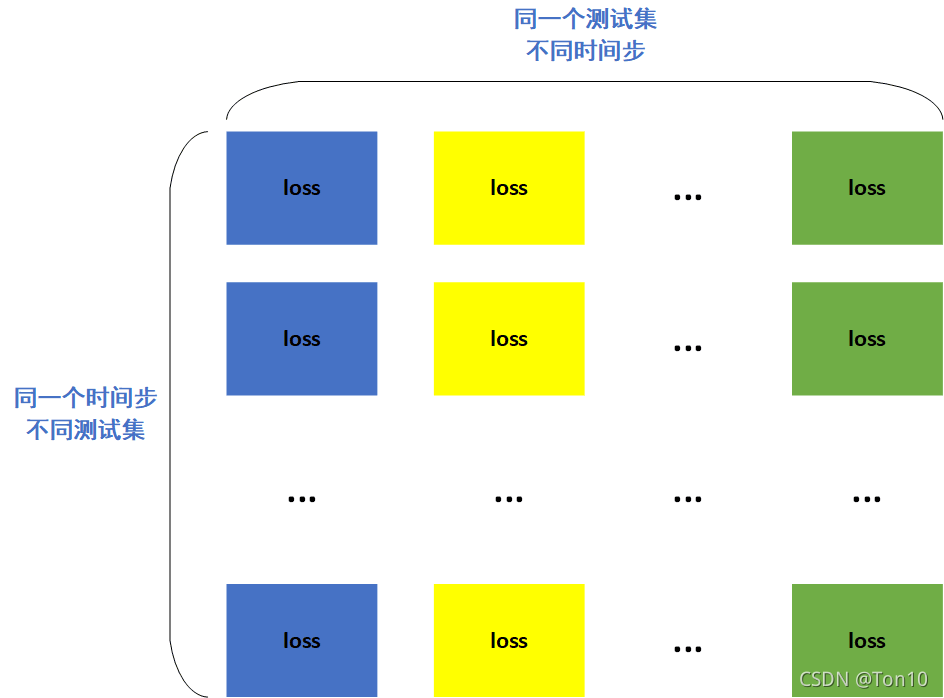 纵向是一个子list,里面是同一个时间步,但是每个loss来源于不同的测试集;横向是不同的几个子list,表示同一个测试集的不同时间步,绿色的最后一个时间步的loss。经典的MAML就是将绿色的全部加起来然后做backward,而MAML++的做法是将所有的格子都加起来,然后从左到右不同颜色的格子分别赋予不同的权值,相同颜色的权值一样(从左到右依次是时间步
0
→
N
0\to N
0→N)。
纵向是一个子list,里面是同一个时间步,但是每个loss来源于不同的测试集;横向是不同的几个子list,表示同一个测试集的不同时间步,绿色的最后一个时间步的loss。经典的MAML就是将绿色的全部加起来然后做backward,而MAML++的做法是将所有的格子都加起来,然后从左到右不同颜色的格子分别赋予不同的权值,相同颜色的权值一样(从左到右依次是时间步
0
→
N
0\to N
0→N)。
-
另一个改进是加入了退火权重因子
v
i
v_i
vi 如上图所示,这个因子针对不同的loss会有不同的值,越是往后的step具有更大的权重分配,毕竟后面的step更加重要,更加准确嘛,所以理应得到更大的关照。我自己在实现的时候,使用的是指数式滑动平均,类似于软更新
τ
\tau
τ的做法。
如上图所示,这个因子针对不同的loss会有不同的值,越是往后的step具有更大的权重分配,毕竟后面的step更加重要,更加准确嘛,所以理应得到更大的关照。我自己在实现的时候,使用的是指数式滑动平均,类似于软更新
τ
\tau
τ的做法。
总的来说,MSL的提出使得MAML的稳定性得到提升,同时算法的性能也得了加强!
Derivative Annealing
导数退火算法:核心思想就是标准MAML算法(存在二阶偏导计算)和FOMAML(将标准MAML简化成一阶偏导)共同使用。
标准MAML采用二阶偏导:优点是计算准确,泛化能力强;缺点是backward消耗时间久,对计算资源消耗较大。
FOMAML采用一阶偏导近似二阶:优点是计算速度快;缺点是泛化能力不如二阶偏导,毕竟是近似的,就不那么准确。
那么作者的提出的思想也很简单:就是前50个episodes采用FOMAML,之后的训练采用二阶偏导。这么做的好处就是既能加快训练速度,又可以保证足够的泛化能力。这种做法包含着退火的思想,“粗糙”的近似能让模型得到更好的训练。
作者还指出一个有意思的发现:DA比单独使用标准MAML算法更加稳定,FOMAML的训练相当于标准MAML的一种预训练,让后期MAML对模型的训练更好之外,可以避免标准MAML算法出现梯度衰减、梯度爆炸现象。
LSLR
LSLR主要针对的是Li et al.(2017)提出的Meta-SGD算法并做出相应改善(关于Meta-SGD的论文以及笔记):
 如上图所示,Meta-SGD针对网络每个参数都会去学习一个
l
e
a
r
n
i
n
g
−
r
a
t
e
learning-rate
learning−rate以及一个搜索方向。本文作者提出这样比较消耗计算资源,相应的提出针对网络的每个层去学习一个
l
e
a
r
n
i
n
g
−
r
a
t
e
learning-rate
learning−rate以及一个搜索方向。
如上图所示,Meta-SGD针对网络每个参数都会去学习一个
l
e
a
r
n
i
n
g
−
r
a
t
e
learning-rate
learning−rate以及一个搜索方向。本文作者提出这样比较消耗计算资源,相应的提出针对网络的每个层去学习一个
l
e
a
r
n
i
n
g
−
r
a
t
e
learning-rate
learning−rate以及一个搜索方向。
CA
余弦退火调整学习率(Cosine Annealing scheduling):
余弦退火是一种简单有效的动态调整学习率的算法,其主要利用余弦函数缓慢下降、迅速下降、再缓慢下降的函数特征来映射到学习率的变化上,其中的退火指的是学习率在下降到余弦函数的最低点之后会立即回到最大值点,开启新的一个周期,这样的话就可以帮助模型逃离出次优点,去寻找更好的次优点(甚至全局最优),如下图所示(图来自上面的链接):
 这里讲的是对MAML算法的外循环,也就是Meta-leraner训练的优化。之前标准的MAML算法采用静态(固定)的外循环学习率。固定的学习率使得超参数的调节十分苦难而且不灵活。作者指出CA算法可以使得外循环学习率
β
\beta
β动态可变,而且可以提高算法的性能。
这里讲的是对MAML算法的外循环,也就是Meta-leraner训练的优化。之前标准的MAML算法采用静态(固定)的外循环学习率。固定的学习率使得超参数的调节十分苦难而且不灵活。作者指出CA算法可以使得外循环学习率
β
\beta
β动态可变,而且可以提高算法的性能。
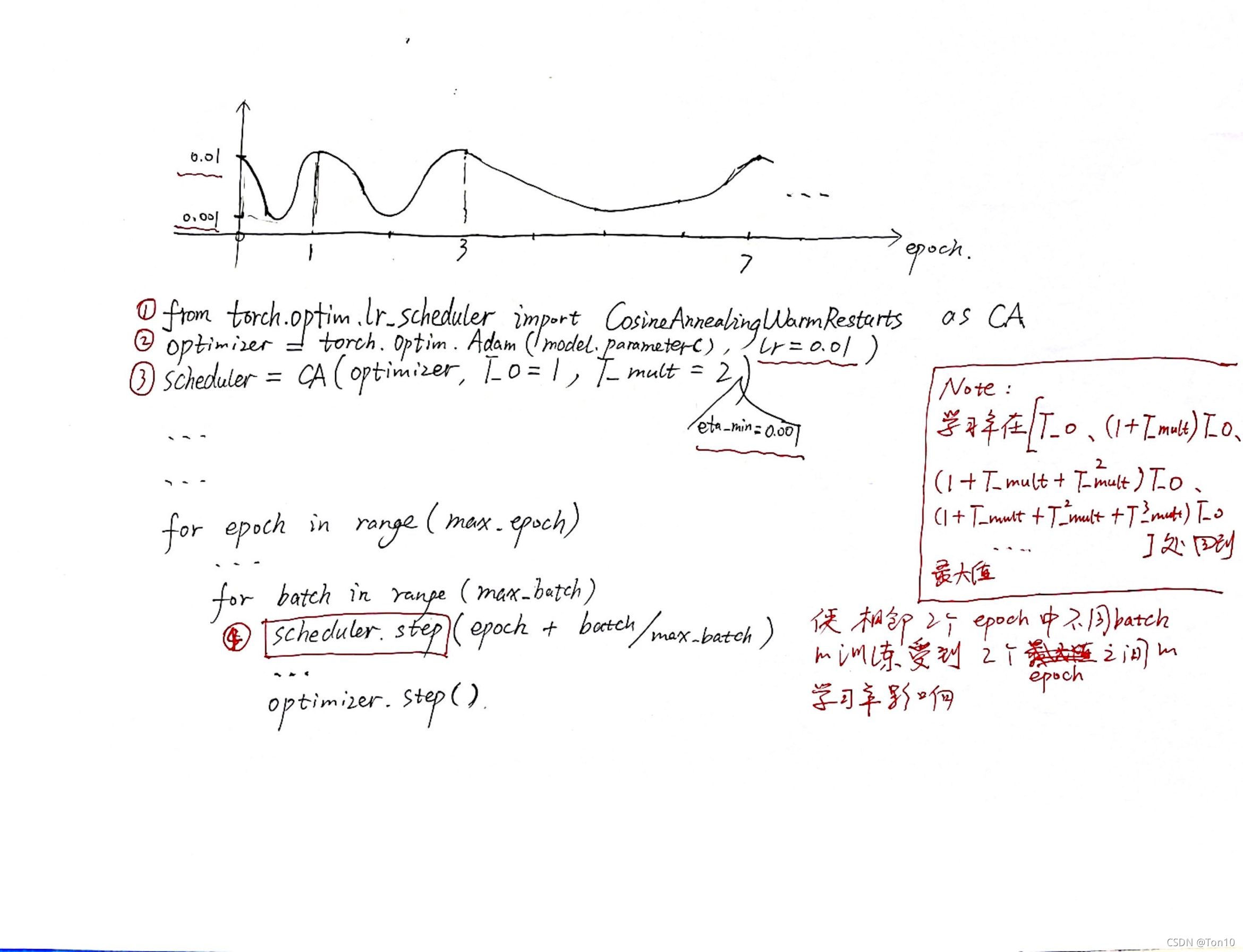
PyTorch提供了有关余弦退火的实现:
- 一篇不错的参考文章点这里。
- 官网介绍:①torch.optim.lr_scheduler.CosineAnnealingLR、②torch.optim.lr_scheduler.CosineAnnealingWarmRestarts
- 还有我自己整理的一张用法框架说明:
实验结果
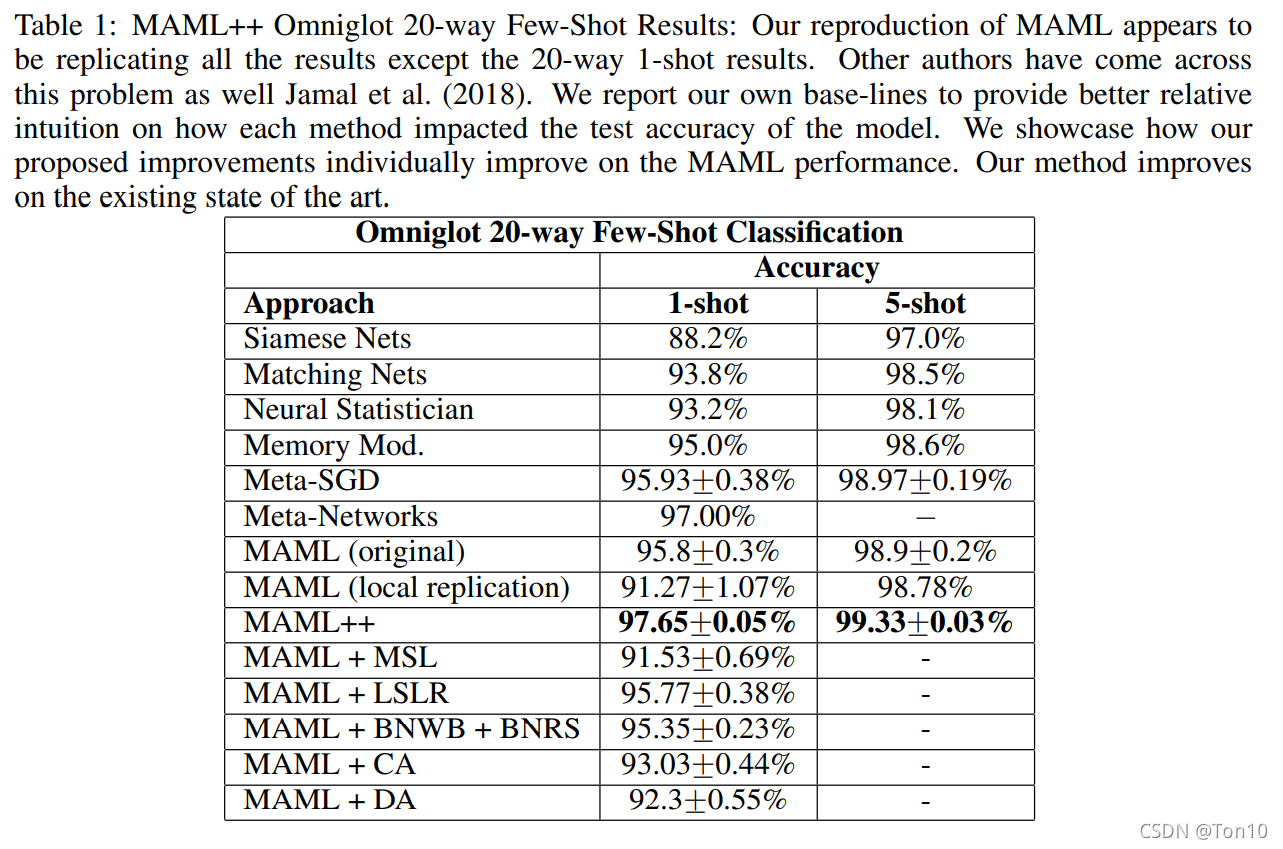 从实验结果来看,单个技巧对MAML的提升不明显,有的甚至不如标准MAML,但是组合拳的效果对标准MAML有了较大的提升。
从实验结果来看,单个技巧对MAML的提升不明显,有的甚至不如标准MAML,但是组合拳的效果对标准MAML有了较大的提升。
提升效果如下:
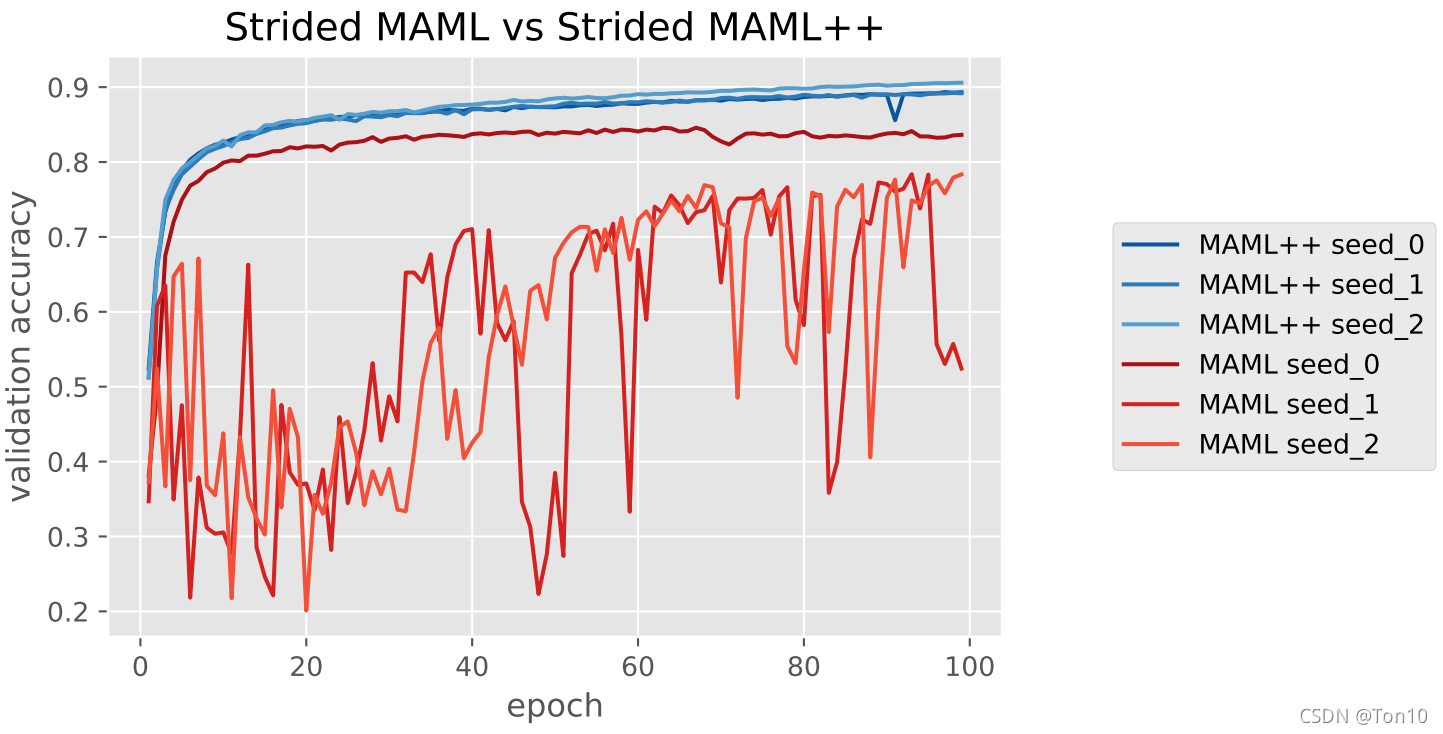 MAML++在泛化性能(表现力)和稳定性上都远胜于标准MAML算法!
MAML++在泛化性能(表现力)和稳定性上都远胜于标准MAML算法!
总结
- MSL可用于提升MAML的稳定性以及泛化性能,但会降低算法速率以及增加计算资源消耗。
- DA可以增加MAML训练效率以及缓解梯度爆炸、消失问题。
- LSLR可以减少Meta-SGD给MAML算法带来增加的存储消耗问题,同时可以有一个可学习的内循环学习率
α
\alpha
α。
- CA可以为MAML带来动态调整的外更新学习率
β
\beta
β,可以帮助算法缓解次陷入次优解的问题。
以上就是MAML++带来的几个小技巧,大家在用MAML的时候可以看情况往自己的MAML里添加,总的来说还是几个不错的idea!
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)