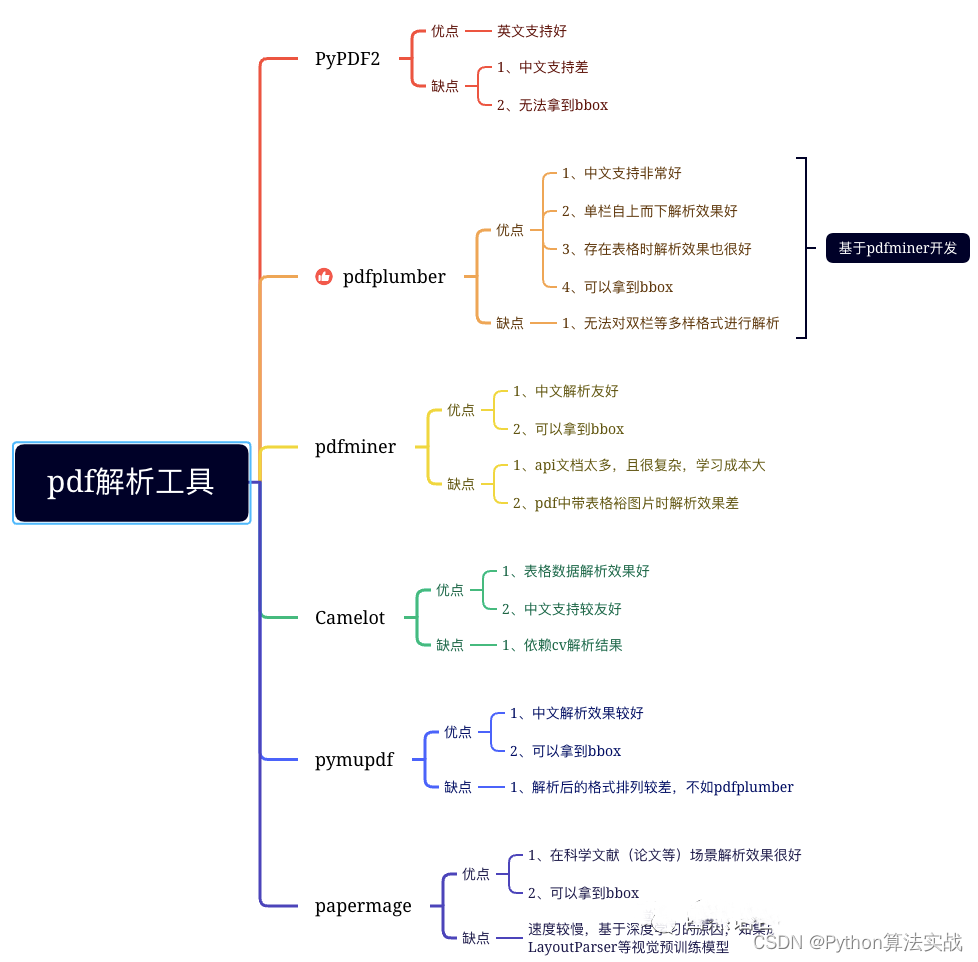
基于自有场景的版面分析
:常见的思路主要为,训练版面分析模型用于识别文档中各个
信息区块
,然后通过ocr工具解析特定区块中的文字信息。如果涉及复杂版面(如:双栏等),则需要根据
启发式规则
(根据bbox排序)进行信息区块的排序。常见的如:XY-CUT算法,xy_cut算法如:
import numpy as np
def xy_cut(bboxes, direction="x"):
result = []
K = len(bboxes)
indexes = range(K)
if len(bboxes) <= 0:
return result
if direction == "x":
# x first
sorted_ids = sorted(indexes, key=lambda k: (bboxes[k][0], bboxes[k][1]))
sorted_boxes = sorted(bboxes, key=lambda x: (x[0], x[1]))
next_dir = "y"
else:
sorted_ids = sorted(indexes, key=lambda k: (bboxes[k][1], bboxes[k][0]))
sorted_boxes = sorted(bboxes, key=lambda x: (x[1], x[0]))
next_dir = "x"
curr = 0
np_bboxes = np.array(sorted_boxes)
for idx in range(len(sorted_boxes)):
if direction == "x":
# a new seg path
if idx != K - 1 and sorted_boxes[idx][2] < sorted_boxes[idx + 1][0]:
rel_res = xy_cut(sorted_boxes[curr:idx + 1], next_dir)
result += [sorted_ids[i + curr] for i in rel_res]
curr = idx + 1
else:
# a new seg path
if idx != K - 1 and sorted_boxes[idx][3] < sorted_boxes[idx + 1][1]:
rel_res = xy_cut(sorted_boxes[curr:idx + 1], next_dir)
result += [sorted_ids[i + curr] for i in rel_res]
curr = idx + 1
result += sorted_ids[curr:idx + 1]
return result
def augment_xy_cut(bboxes,
direction="x",
lambda_x=0.5,
lambda_y=0.5,
theta=5,
aug=False):
if aug is True:
for idx in range(len(bboxes)):
vx = np.random.normal(loc=0, scale=1)
vy = np.random.normal(loc=0, scale=1)
if np.abs(vx) >= lambda_x:
bboxes[idx][0] += round(theta * vx)
bboxes[idx][2] += round(theta * vx)
if np.abs(vy) >= lambda_y:
bboxes[idx][1] += round(theta * vy)
bboxes[idx][3] += round(theta * vy)
bboxes[idx] = [max(0, i) for i in bboxes[idx]]
res_idx = xy_cut(bboxes, direction=direction)
res_bboxes = [bboxes[idx] for idx in res_idx]
return res_idx, res_bboxes
bboxes = [[58.54924774169922, 1379.6373291015625, 1112.8863525390625, 1640.0870361328125],
[60.1091423034668, 483.88677978515625, 1117.4927978515625, 586.197021484375],
[57.687435150146484, 1098.1053466796875, 387.9796142578125, 1216.916015625],
[63.158992767333984, 311.2080993652344, 1116.2508544921875, 365.2145080566406],
[138.85513305664062, 144.44039916992188, 845.18017578125, 198.04937744140625],
[996.1032104492188, 1053.6279296875, 1126.1046142578125, 1071.3463134765625],
[58.743492126464844, 634.3077392578125, 898.405029296875, 700.9544677734375],
[61.35755920410156, 750.6771240234375, 1051.1060791015625, 850.3980712890625],
[426.77691650390625, 70.69780731201172, 556.0884399414062, 109.58145141601562],
[997.040283203125, 903.5933227539062, 1129.2984619140625, 921.10595703125],
[59.40523910522461, 1335.1563720703125, 329.7382507324219, 1357.46533203125],
[568.9025268554688, 14.365530967712402, 1087.898193359375, 32.60292434692383],
[998.1250610351562, 752.936279296875, 1128.435546875, 770.4116821289062],
[59.6968879699707, 947.9129638671875, 601.4513549804688, 999.4548950195312],
[58.91489028930664, 1049.8773193359375, 487.3372497558594, 1072.2935791015625],
[60.49456024169922, 902.8802490234375, 600.7571411132812, 1000.3502197265625],
[60.188941955566406, 247.99755859375, 155.72970581054688, 272.1385192871094],
[996.873291015625, 637.3861694335938, 1128.3558349609375, 655.1572875976562],
[59.74936294555664, 1272.98828125, 154.8768310546875, 1295.870361328125],
[58.835716247558594, 1050.5926513671875, 481.59027099609375, 1071.966796875],
[60.60163116455078, 750.1132202148438, 376.1781921386719, 771.8764038085938],
[57.982513427734375, 419.16058349609375, 155.35882568359375, 444.25115966796875],
[1017.0194091796875, 1336.21826171875, 1128.002197265625, 1355.67724609375],
[1019.8740844726562, 486.90814208984375, 1127.482421875, 504.61767578125]]
res_idx, res_bboxes = augment_xy_cut(bboxes, direction="y")
print(res_idx)
# res_idx, res_bboxes = augment_xy_cut(bboxes, direction="x")
# print(res_idx)
new_boxs = []
for i in res_idx:
# print(i)
new_boxs.append(bboxes[i])
print(new_boxs)
常见的单模态(目标检测)深度学习模型方法:Yolo系列、mask-RCNN、faster-CNN等
常见的多模态深度学习模型方法:layoutlmv3等