编辑 | 智能车情报局
点击下方
卡片
,关注“
自动驾驶之心
”公众号
ADAS巨卷干货,即可获取
点击进入→
自动驾驶之心【BEV感知】技术交流群
本文只做学术分享,如有侵权,联系删文
导读:
本文提出了一种用于自动驾驶数据采集的自动或半自动标注系统,该系统既适用于研发阶段的车辆数据采集,也适用于量产阶段的客户数据采集。该方案同时为激光雷达和相机构建了一个3D场景半自动标注系统,它还允许独立运行激光雷达的点云标注或相机的视觉重建3D数据标注,以及两者(激光雷达和相机)的联合标注。本文提出的标注系统同时支持 BEV 感知和Occupancy(占用)感知,不仅适用于 BEV 网络的开发,也有助于占用网络的研究。
01
前言
现如今,自动驾驶已被公认为是一个“长尾分布”问题,需要不断发现极端案例数据,以提高解决方案的性能,获取有价值的数据、标注数据、模型训练、验证和部署等构成了开发自动驾驶的数据闭环。提供自动驾驶数据平台的云服务公司,都有半自动或自动标注业务功能,但大多侧重于2D图像,而非真实的3D场景。
Tesla在这一领域已经展现出强大的实力,自动标注能力突出。它充分利用纯视觉传感器数据构建整个自动标注大模型,通过深度学习方法从视觉重构中获取许多3D标注信息,如障碍物检测和道路(车道线)分割,以及运动、深度和本体车辆轨迹估计等。与此同时,谷歌 WayMo 和 Uber ATG 也推出了基于激光雷达数据的物体自动标注方法,可以从点云数据中分割出静态背景和动态车辆、行人,并分别细化静态背景和动态前景的结构。自制高清地图,标注车道标线、路沿、斑马线甚至箭头和文字等地图元素,也引起了更多关注。
目前,从传感器数据中标注静态背景大多通过 SLAM 或 SfM 方法完成 ,但对于移动物体而言,这仍然是一项挑战 。与视觉系统相比,激光雷达作为主动3D传感器具有天然优势。然而在实际中,视觉系统的3D标注存在明显问题,不能获得较好的准确性和鲁棒性。现有方法依旧存在一些薄弱环节:
1)自动驾驶场景数据的3D自动/半自动标注方法仍缺乏有效的开发模式,需要大量的人工工作来修正标注不准确的错误;
2)使用激光雷达和相机组合的自动驾驶数据3D自动/半自动标注系统相对较少,大多使用激光雷达或相机独立采集的数据标注任务;
3)在动态物体的3D自动/半自动数据标注方面仍然缺乏成熟的解决方案,尤其是在纯视觉领域;
4)目前,缺乏同时支持 BEV(鸟瞰)网络和Occupancy(占用)网络的标注工具设计和开发。
02
数据获取和系统配置
作为自动驾驶数据采集系统,需要设置GNSS、IMU、摄像头、毫米波雷达和 LiDAR 等传感器。其中,激光雷达可能不是量产车辆的标准配置,因此量产车辆上获得的数据不包括三维激光雷达点云。摄像头的配置可以观测车辆附近的 360 度环境,6 个摄像头、5 个毫米波雷达和 1 个 360 度扫描 LiDAR。
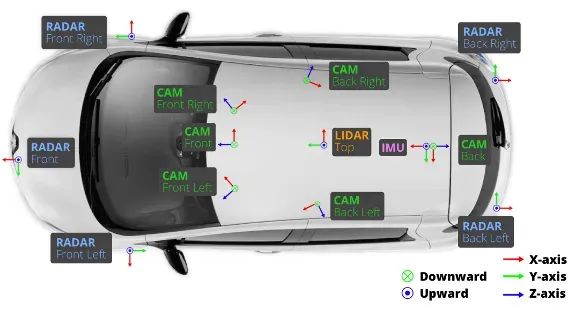
▲图1|Nuscenes数据集车辆传感器配置
如果需要收集多模态传感器数据,则需要进行传感器校准,这涉及到确定每个传感器数据之间的坐标系关系,例如相机校准、相机-激光雷达校准、激光雷达-IMU校准和相机-雷达校准。此外,传感器之间需要使用统一的时钟(以全球导航卫星系统为例),然后使用特定信号触发传感器的操作。例如,激光雷达的传输信号可以触发照相机的曝光时间,而照相机的曝光时间是时间同步的。
作为自动驾驶开发平台,需要从车辆端和服务器云端支撑整个数据闭环系统,包括车辆端的数据采集和初步筛选、云端数据库基于主动学习的挖掘、自动标记、模型训练和仿真测试(仿真数据也可用于模型训练),以及模型部署回车辆端,数据选择和数据标注是决定数据闭环效率的关键模块。
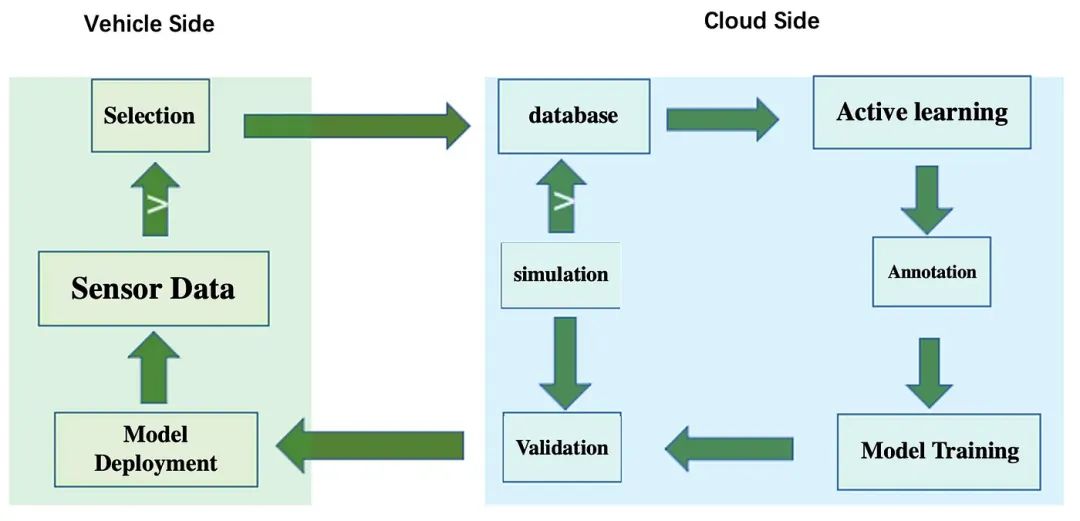
▲图2|数据闭环架构
数据标注任务分为研发阶段和量产阶段:
1)研发阶段主要涉及开发团队的各种数据采集载体,其中包括激光雷达,这样激光雷达就能为相机的图像数据提供3D点云数据,从而提供3D真实值。例如,BEV(鸟瞰)视觉感知需要从二维图像中获取 BEV 输出,这就涉及到透视投影和3D信息推测;
2)在量产阶段,数据主要由乘用车客户或商用车运营客户提供。这些数据大多没有激光雷达数据,或者只是有限视场(如前方)的3D点云。因此,对于摄像头图像数据,需要估算或重建3D数据以进行标注。
03
传感器数据标注的传统方法
3.1 激光雷达数据标注
深度学习模型算法需要数据进行训练,而传统方法可以进行无监督数据处理。首先,针对激光雷达数据,本文提出了3D点云标注的传统算法框架,如图 3 所示:
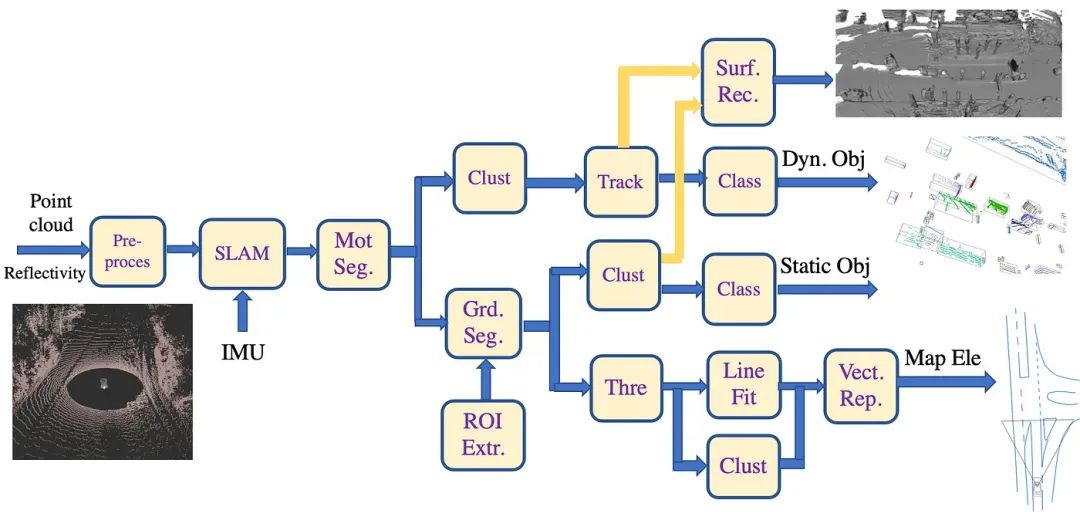
▲图3|激光雷达数据标注示意图
具体流程如下:
1)“预处理”模块包括点云数据的坐标转换(如极坐标表示法、测距图像或 BEV 图像)、去噪滤波和采样(包括“填补”缺失点云的“漏洞”)。在“SLAM”模块中优化点云和 IMU 数据序列,以进行激光雷达-IMU 测距估算和背景束调整 (BA),同时生成车辆运动轨迹;
2)由于激光雷达每次采集的视角不同且坐标变化较大,过多的障碍点会影响物体3D框架的提取。因此,“ROI extr”模块可从原始点云中筛选出感兴趣的区域;根据本体车辆的行驶轨迹和已知地图信息,可确定一个大致的道路区域作为 ROI;
3)每一帧点云数据都包含大量地面点,检测的目的是获取道路障碍物信息,这就需要对地面点云进行进一步分割。“grd seg”模块用于定位地面点云,路边也是行车道路的边界,这里可以采用分段平面拟合的方法,将点云沿 x 轴方向分为多段,然后应用 RANSAC 平面拟合方法提取每段中的地面点。检测道路边界时,设置距离阈值(15-30 厘米),以确保地面点包含所有道路边界点;
4)对于“grd seg”模块输出的非道路点云,在“clust”模块中,静态对象(障碍物)采用无监督聚类方法形成多个聚类,每个聚类代表一个障碍物(如交通锥和停车位)。聚类方法可以简单地使用欧氏距离进行聚类,如 K-means 或 DBSCAN;
5)在另一个“clust”模块中,移动物体(障碍物)也采用无监督聚类方法形成多个聚类,每个聚类代表一个障碍物(如车辆、行人、自行车等),算法与上一步相同;
对于运动物体,可在“Track”模块中使用3D卡尔曼滤波算法来确定物体在前一帧和后续帧中的点云关联和轨迹,从而获得更平滑的三维帧位置和姿态;根据物体的运动情况,可对多帧点云进行对齐,以构建更密集的点云输出(即刚性物体,如车辆;对于可变形物体,如行人,效果会减弱);
6)对于集群中的障碍物(包括静态和动态障碍物),可在两个不同的 "clust "模块中使用特征提取和分类器进行识别;此外,还可对每个集群进行三维立方体拟合,并计算障碍物的属性,如中心点、中心点、长度、宽度等;
7)“surf rec”模块对动态物体跟踪对齐的点云和静态物体聚类的点云处理,并运行形状恢复算法;
8)对于道路交通标线,如车道标线、斑马线和人行道标线,利用点云的反射值进行过滤,在“thre”模块中剔除路面上未标注的点云,在“clust”模块中将剩余的点连接到聚类中,并给出相应的车道标线和斑马线类别;
9)为了检测道路边界性,需要提取道路点云特征,如相邻点的高度差、平滑度和水平距离。然后,在“thre”模块中获得候选道路边界点,最后在“line fit”模块中对连接点进行片断逼近,并给出道路边界类别;
10)然后,在“Vect Rep”模块中用折线对这些路标进行分割和标记;
11)最后,将所有标注投影到车辆坐标系上,即单帧(激光雷达或摄像头),以获得最终标注。
如图 4 所示,激光雷达-IMU中关于“SLAM”模块的参考框架如下:
1)激光雷达的原始点在 10 毫秒(IMU 为 100Hz 更新)和 100 毫秒(激光雷达为 10Hz 更新)之间累积,累积的点云称为扫描数据;
2)为进行状态估计,新扫描的点云将使用紧耦合迭代卡尔曼滤波框架(IEKF)注册到大局部地图中维护的地图点(即里程测量)上;
3)地图使用增量 KD 树(ikd-tree)存储。 在状态估计方面,新扫描的点云与地图点(即odometry)通过一个紧密耦合的迭代卡尔曼滤波框架(IEKF)在一个大型局部地图中保持一致;
4)地图通过一个增量 kd-tree (ikd-tree)存储;观测方程是点云与地图之间的直接匹配;除了 k 近邻搜索(k-NN),它还支持增量地图更新(即点插入、向下平移);
5)在状态估计方面,新扫描的点云与地图点(即odometry)通过一个紧密耦合的迭代卡尔曼滤波框架(IEKF)在一个大型局部地图中保持一致。 如果激光雷达的当前 FoV 范围越过地图边界,则会从 ikd 树中删除离激光雷达姿态最远的地图历史点;
6)优化的姿态估计会将新扫描的点注册到全局坐标系,并以里程计速率将其插入 ikd 树(即映射),然后将其合并到地图中。
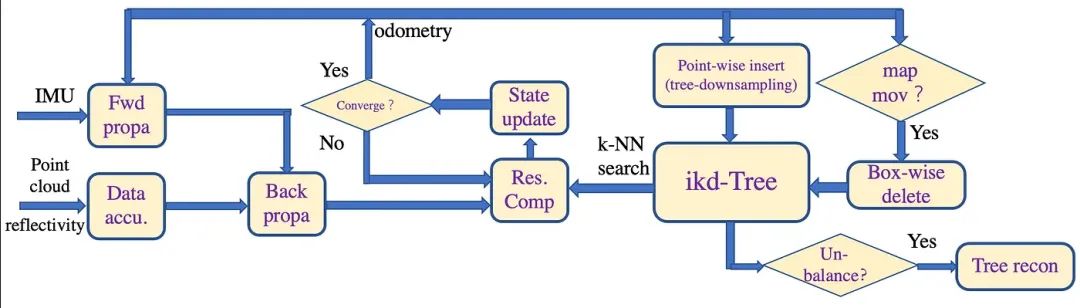
▲图4|激光雷达-IMU测距估算
3.2 多相机图像数据标注
对于多相机图像数据,本文提出了一种标注视觉数据的传统方法,即3D标注框架,具体流程如下:
1)首先,“SLAM/SFM”模块利用多相机视觉-IMU里程测量重建静态背景的特征点云;参考架构如图 6 所示(详细内容将在后面介绍);
2)同时,在“Mot Seg”模块中,根据运动轨迹选择运动与背景运动不同的匹配特征点对,并将其发送到“Clust”模块,以获得运动物体的不同特征点对(去除一些孤立的点对);
3)然后在“SLAM/SFM”模块中对特征点对进行聚类,以进行3D重建(其中 IMU 只负责自我车辆的运动,不参与动态物体的运动估计),其参考架构如图 7 所示(详细内容将在后面介绍);获得点云聚类后,将其拟合为3D物体(CAD 模型或矩形框);
4)为了恢复无特征图像区域中的遗漏点云,在“super-pixel seg.”模块中进行图像分割,并将带有重建特征点云的超像素反投影到3D空间(采用深度插值),形成密度更高的点云;然后将3D物体拟合到“Obj. Recog”模块进行分类(根据从超像素中提取的 RGB 特征,构建物体分类器,如基于 SVM 或 MLP 的分类器);
5)在“Grd. Det”模块对特征点云进行路面拟合,其中可选的“ROI Ext”模块能够用于根据估计的自我车辆轨迹选择路面作为感兴趣区域;然后将路面点云投影到图像中,并使用“reg.grow”模块中的泛洪填充算法获得路面面积;
6)在拟合路面的基础上,找到不在路面上的静态物体(障碍物)点云,然后在“clust”模块中生成特征点云簇,之后将其拟合为3D物体(CAD 模型或矩形框);同样,使用步骤 3) 中应用的“super-pixel seg”模块,可获得密度更高的重构;之后我们拟合3D物体,并进入“obj recog”模块进行分类;
7)动态物体 SLAM 和静态物体聚类得到的点云进入“surf recons”模块,运行形状恢复算法;
8)基于路面点云拟合得到路面方程,然后对路面标线进行处理:一种方法是首先在“Img Proc”模块中对路面区域进行灰度阈值二值化(如Otsu方法)、边缘检测(如Canny算子)和直线拟合(如Hough变换)。获取检测到的车道线、斑马线和道路边缘,然后将其投影回路面,称为IPM(逆投影映射); 另一种方式是先对路面图像逐像素进行IPM,然后在“Img Proc”中对IPM图像进行与上述类似的操作。 模块获取检测到的车道线、斑马线、道路边缘,这是路面的实际检测结果;
9)在“Vect Rep”模块中,对车道标线、斑马线和道路边缘进行分割,然后用分段折线进行标注;
10)最后,将所有标注投影到车辆坐标系上,即单帧上,得到最终标注。
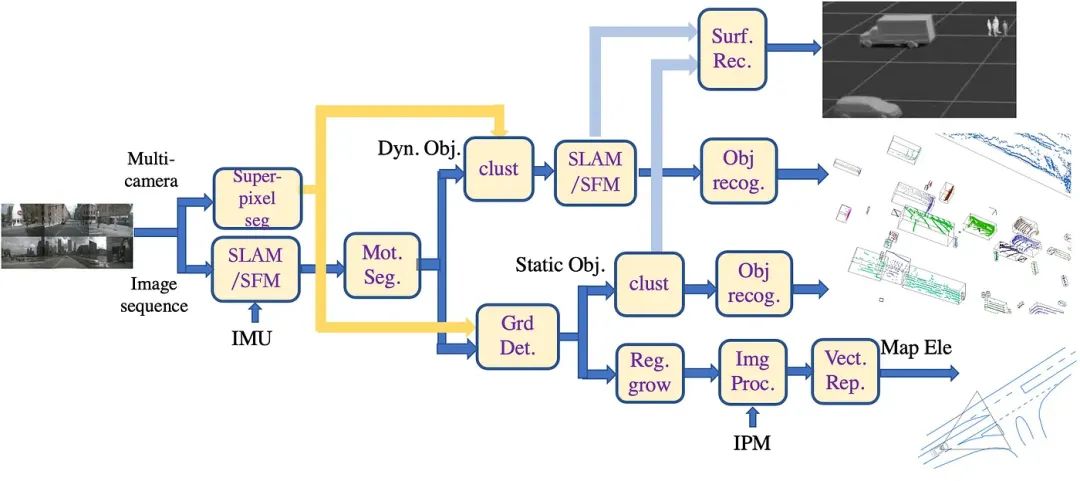
▲图5|多相机数据标注
下述图 6 则是图 5 中多摄像机-IMU SLAM 的参考架构,由三个阶段组成。
前两个阶段的目的是线性初始化估计器,并在没有先验知识的情况下获得摄像机-IMU 校准的初始值;在第三阶段,利用前两个阶段的初始值,通过非线性优化开发紧密耦合的状态估计器。
初始化结构基本上是通过多次运行单目摄像头-IMU 系统的 VINS(视觉-惯性导航系统)来获得的。假设多个摄像头尚未校准(如果摄像头已经校准,则可以直接给出初始值),因此初始阶段不考虑摄像头之间的特征匹配。旋转校准与手眼校准过程类似,而平移校准将把 VINS 滑动窗口估计技术扩展到多台摄像机。在初始化步骤的基础上,根据摄像机之间的相对姿态,建立同一摄像机(时间)和不同摄像机(空间)之间的特征跟踪。直观地说,视场重叠的摄像头可以实现特征的三维三角测量。另一方面,如果摄像机之间没有重叠视场,或者特征点距离太远,系统就会退化为多个单目 VINS 配置。
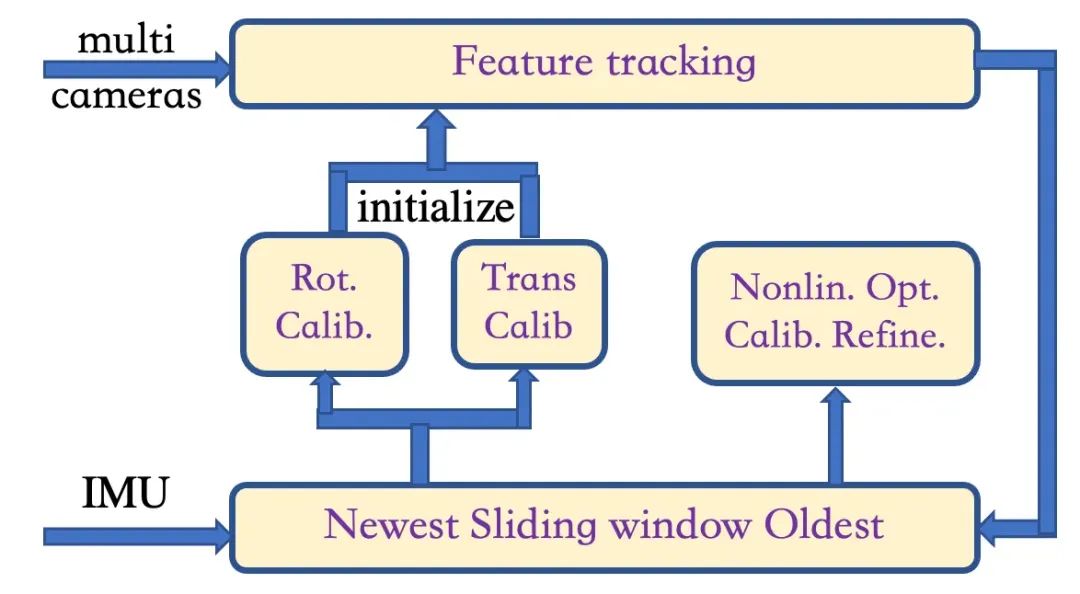
▲图6|多相机-MU SLAM
前面所提到的多摄像头SLAM框架包括三个模块:多摄像头视觉定位、全景建图和闭环校正。
多摄像头视觉定位的目标是实时获取车辆的6D位姿。 基于多相机空间感知模型,可以通过多相机图像帧快速估计姿态。 定位过程可以分为三个状态:初始化、跟踪和重新定位。
地图系统根据匹配的特征点构建稀疏点云来创建地图,每个地图点由特征点描述符组成,从而使地图可重复使用。 为了避免地图太大,它只为满足特定条件的关键帧构建地图。 关键帧由从多相机图像中提取的特征组成。 为了表示关键帧之间的共视信息,以关键帧为节点,以两帧之间共享地图点的数量作为边的权重来构建共视图。 权重越大意味着更多的帧共享观察结果。 映射过程包括同步和异步两种。 同步映射使用任意一对摄像机参与3D场景构建过程。 异步映射利用公共视图中的当前和先前关键帧来对地图点进行三角测量。
闭环检测是系统检测是否回到之前场景的能力,基于闭环检测的修正可以大大提高系统的全局一致性。 基于闭环信息,可以同时修正轨迹和地图。
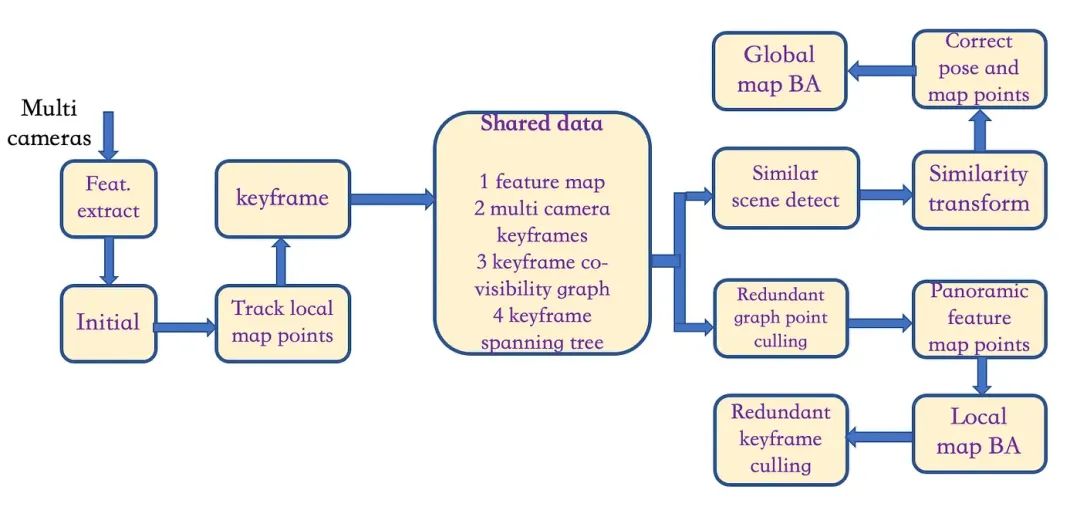
▲图7|多相机SLAM
3.3 激光雷达-多相机数据联合标注
基于提供的LiDAR点云和多相机图像数据,可以用传统方法对其进行联合标注,如图8所示:
1)输入的LiDAR数据经过“预处理”模块进行点云滤波处理,然后与多相机图像数据组合进入“SLAM”模块。 这里,LiDAR点云被投影到图像平面上形成深度网格,与用于车辆里程计的IMU联合估计,并重建3D密集点云图。 架构如图9所示(后面会详细介绍);
2)类似图3,然后进入“Mot Seg”模块获取运动物体和静止背景,同时运动物体还运行“Clust”模块、“Track”模块、“Obj Recog”模块获取运动障碍物 标注;
3)另一方面,在静止背景上运行“grd seg”模块会产生两部分:静态物体(障碍物)和路面:前者类似于图3,运行“clust”模块和“obj recog” ”模块获取静态障碍物标签,而后者类似于图5,运行“reg Growth”模块、“img proc”模块(基于路面方程的IPM)和“vect rep”模块获取折线 道路车道线、斑马线和道路边界的标记;
4)动态目标跟踪和静态目标聚类得到的点云进入“surf recon”模块并执行形状恢复算法;
5)最后将所有标注投影到单帧的车辆坐标系上,得到最终的标注。
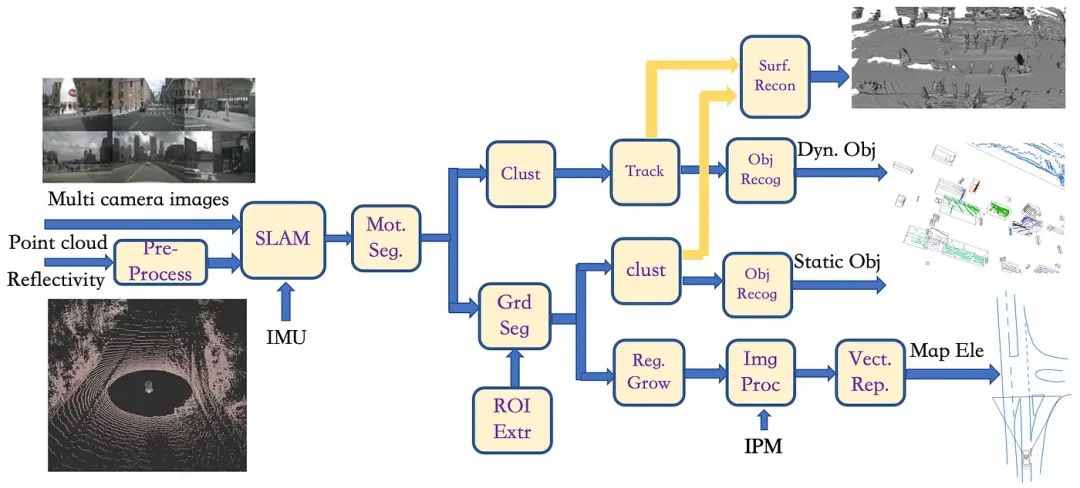
▲图8|LiDAR+多相机数据标注
下述图 9 则显示了激光雷达-多摄像头-IMU SLAM 框架:
1)将激光雷达点云投射到每个相机上形成深度网格,同时对每个图像进行特征检测和跟踪以获得初始姿态;
2)深度网格和2D特征位置可结合在一起计算2D特征的深度(注:此处每个相机-激光雷达构成一个 SLAM 管道);
3)然后,使用特征跟踪数据和 IMU 数据初始化估计器;
4)之后,使用 IMU 的姿态、速度和来自 IMU 预积分的偏差以及相机帧特征创建滑动窗口。非线性优化过程用于执行状态估计;
5)获得滑动窗口的估计状态后,与闭环检测(位置识别)模块一起执行全局姿态图优化,最后获得3D点云图。
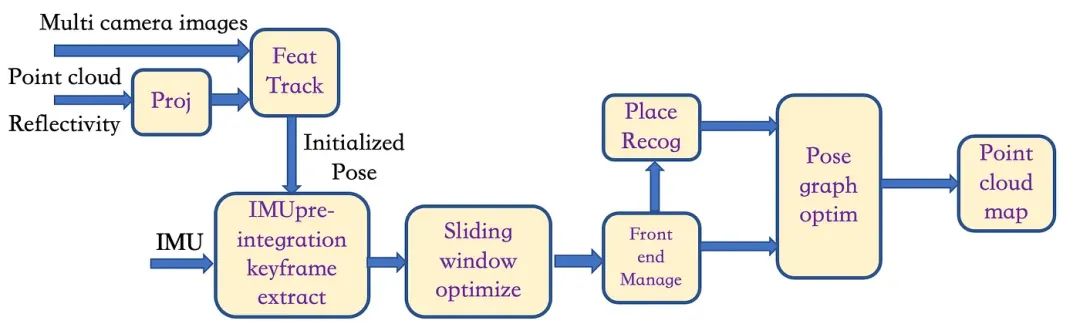
▲图9|LiDAR-相机-IMU SLAM
04
传感器标注的半传统方法
上一节3中处理激光雷达点云和相机图像的传统方法存在一些问题,如激光雷达的点云聚类、基于反射阈值的检测和线拟合,以及图像的超像素分割、区域生长、二值化和边缘检测,这些方法在复杂场景中往往效果不佳。下面将引入一些深度学习模型来加以改进。
4.1 激光雷达数据标注
首先,针对LiDAR点云,本文提出了半传统的标注方法框架,具体流程如下:
1)与图3类似,这个框架也包括“预处理”模块、“SLAM”模块(其架构如图4所示)和“mot seg”模块。 然后,在“inst seg”模块中,直接对与背景不同的移动物体执行基于点云的检测,而神经网络模型用于从点云中提取特征图(例如PointNet 和PointPillar);
2)之后与图3类似,在“Track”模块中,我们对每个分割对象进行时间关联,以获得动态对象的3D边界框的标注;
3)对于静态背景,经过“Grd Seg”模块后,被判断为非路面的点云进入另一个“Inst Seg”模块进行物体检测,然后可以获得静态物体的bbox边界框;
4)对于路面的点云,输入到“Semantic Seg”模块,然后基于深度学习模型,我们利用反射强度对与图像相似的语义对象进行逐像素分类,即 车道标记、斑马线和道路区域。 通过检测道路边界得到路缘石,最后在“Vect Rep”模块中进行基于折线的标注;
5)跟踪的动态物体点云和实例分割得到的静态物体点云进入“surf recon”模块并运行形状恢复算法;
6)最后,将所有标注作为单帧投影到车辆坐标系上,得到最终的标注。
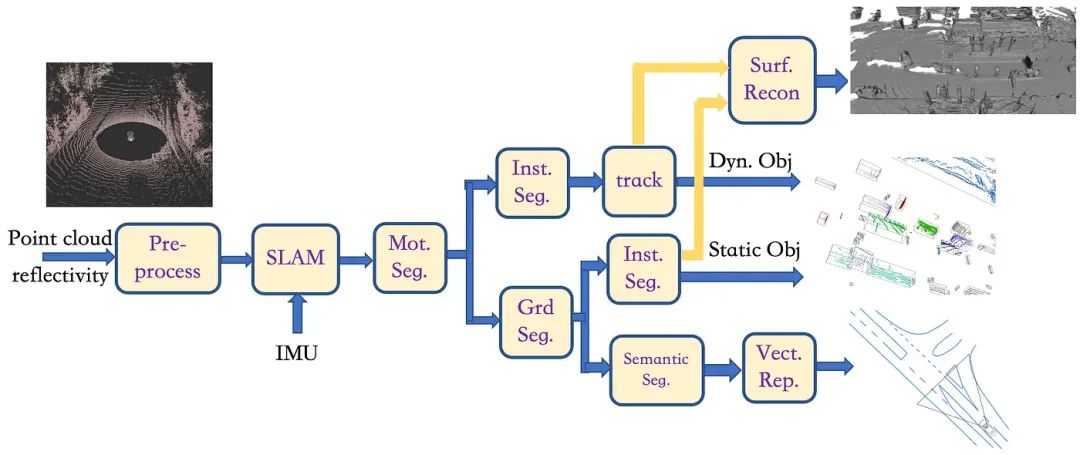
▲图10|LiDAR数据标注框架流程
4.2 多相机图像数据标注
对于来自多个相机的图像数据,本文提出了半传统的3D标注框架,具体流程如下:
1)首先在多相机的图像序列中使用“inst seg”、“深度图”和“光流”三个模块,分别计算实例分割图、深度图和光流图; “inst seg”模块使用深度学习模型来定位和分类一些对象像素,例如车辆和行人,“深度图”模块使用深度学习模型来估计两个连续的像素级运动 基于单目视频的帧形成虚拟立体视觉来推断深度图,“光流”模块使用深度学习模型直接推断两个连续帧的像素运动; 三个模块尝试使用无监督学习的神经网络模型;
2)基于深度图估计,“SLAM/SFM”模块可以获得类似于RGB-D+IMU传感器的密集3D重建点云,(类似于激光雷达+相机+IMU的SLAM框架,如 如图9所示,仅省略了将激光雷达点云投影到图像平面上的步骤); 同时,实例分割结果实际上允许从图像中去除障碍物,例如车辆和行人,同时基于本体车辆里程计和光流估计进一步区分“mot seg”模块中的静态和动态障碍物 ;
3)实例分割得到的各种动态障碍物将在接下来的“SLAM/SFM”模块中重建,类似于RGB-D传感器的SLAM架构,可以是单目的扩展 SLAM,如图7所示; 然后,它将“inst seg”的结果传输到“obj recog”模块并标注对象点云的3D边界框;
4)对于静态背景,“grd det”模块将区分静态物体和道路点云,以便静态障碍物(如停车车辆和交通锥)将“inst seg”模块的结果传输到“obj recog” ”模块,标注点云的 3D 边界框;
5)从“SLAM/SFM”模块获得的动态物体点云和从“grd det”模块获得的静态物体点云进入“Surf Recon”模块运行形状恢复算法;
6)路面点云仅提供拟合的3D路面。 从图像域“inst seg”模块中可以获得路面面积。 基于自我里程计,可以进行图像拼接。 在拼接的路面图像上运行“seman seg”模块后,可以获得车道标线、斑马线和道路边界。 然后,使用“vectrep”模块进行多线标记;
7)最后,将所有标注作为单帧投影到车辆坐标系上,得到最终的标注。
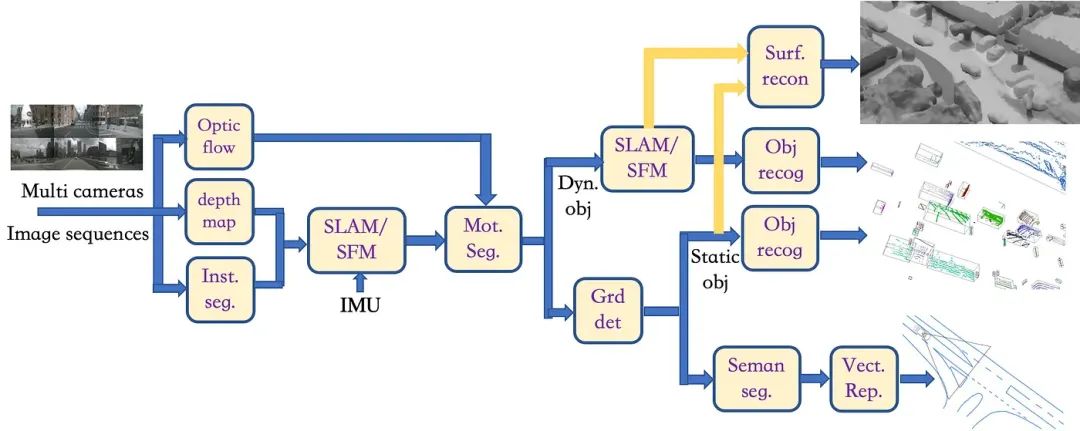
▲图11|多相机图像数据的3D标注框架流程
4.3 激光雷达-多相机数据联合标注
因此针对LiDAR和摄像头的数据,本文提出了一种半传统的联合数据标注方法框架,具体流程如下:
1)当多相机图像和LiDAR点云同时存在时,将图11中的“光流”模块替换为“场景流”模块,该模块基于深度学习模型估计3D点云的运动; 将“深度图”模块替换为“深度复杂”模块,该模块使用神经网络模型来完成将点云投影(插值和“孔填充”)到图像平面上获得的深度, 然后反投影回3D空间生成点云; 将“inst seg”模块替换为“seman. seg.” 模块,使用深度学习模型根据对象类别来标记点云;
2)随后,密集的点云和IMU数据将进入“SLAM”模块来估计里程计(其架构如图4所示),并选择标记为障碍物(车辆和行人)的点云。 同时,预估的场景流量也会进入“mot seg”模块,进一步区分移动障碍物和静态障碍物;
3)之后,与图10类似,一旦运动物体经过“inst seg”模块和“track”模块,就获得了运动物体的标注; 同样,经过“grd seg”模块后,静态障碍物被“inst seg”模块标记; 地图元素,例如车道标记、斑马线和道路边缘,是通过运行“seman. 段。” 模块中的拼接路面图像和对齐的点云,然后进入“vectrep”模块进行折线标记;
4)跟踪获得的动态物体点云和实例分割获得的静态物体点云进入“surf recon”模块,该模块运行形状恢复算法;
5)最后,将所有标注作为单帧投影到车辆坐标系上,得到最终的标注。
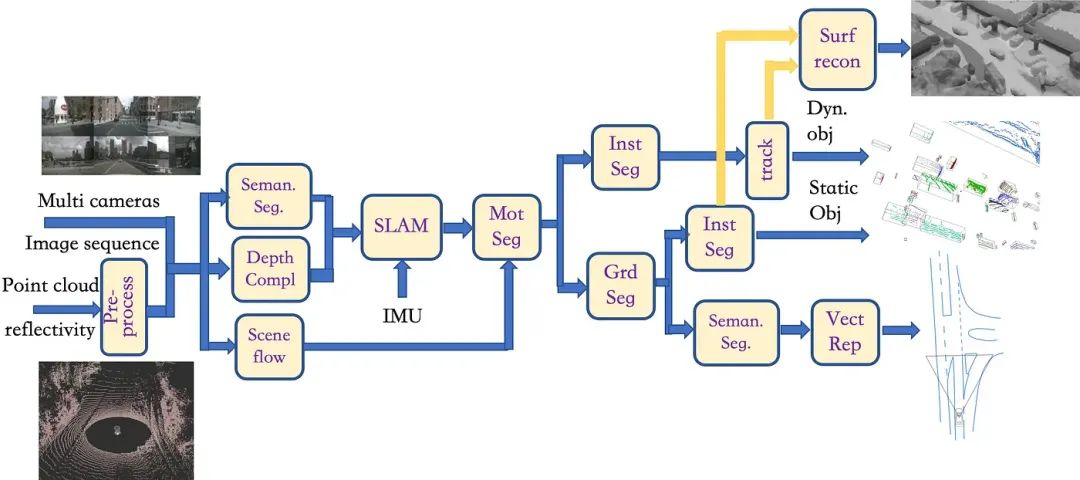
▲图12|LiDAR和相机联合标注框架
05
基于深度学习的数据标注方法
最后,基于一定数量的标注数据,系统能够构建完整的深度学习神经网络模型来标注激光雷达点云和相机图像数据,包括独立的激光雷达点云标注模型、独立的相机图像标注模型、 以及LiDAR点云和多相机图像数据的联合标注模型。
5.1 激光雷达数据标注
本文为完整的深度学习模型设计了LiDAR点云标注系统,具体流程如下:
1)首先,在“voxe-lization”模块中,点云被分成均匀间隔的体素网格,生成3D点和体素之间的多对一映射; 然后进入“Feat Encod”模块,将体素网格转换为点云特征图(使用PointNet 或PointPillar);
2)一方面,在“视图变换”模块中,将特征图投影到BEV上,其中组合了特征聚合器和特征编码器,然后在BEV空间中进行BEV解码,划分成两个头:一个头检测“Map Ele Det”模块中道路地图元素的关键点和类别(即回归和分类),例如车道标记、斑马线和道路边界,其结构类似于基于Transformer架构的DETR模型,同样使用可变形注意力模块,输出关键点的位置及其所属元素的ID; 这些关键点被嵌入到“PolyLine Generator”模块中,该模块也是基于 Transformer 架构的模型。 基于BEV特征和初始关键点,折线分布模型可以生成折线的顶点并获得地图元素的几何表示; 另一个头通过“obj det”模块进行BEV物体检测,其结构类似于PointPillar模型;
3)另一方面,3D点云特征图可以直接进入“3D Decod”模块,通过3D反卷积获得多尺度体素特征,然后在“Occup”中进行上采样和类别预测。 生成体素语义分割的模块。
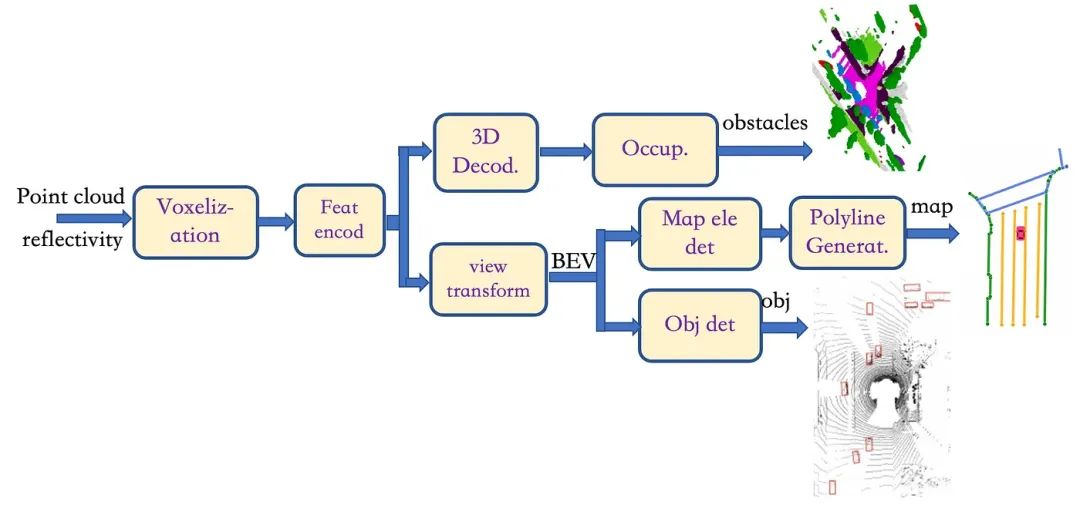
▲图13|LiDAR数据标注框架
5.2 多相机图像数据标注
然后本文设计了一个完整的深度学习模型的多相机图像标注系统,具体流程如下:
1)多相机图像首先通过“backbone”模块进行编码,例如EfficientNet或RegNet加FPN/Bi-FPN,然后分为两条路径;
2)一方面,图像特征进入“视图变换”模块,通过深度分布或Transformer架构构建BEV特征,然后分别转到两个不同的头:类似于图13,一个 head通过“地图元素检测器”模块和“折线生成器”模块输出地图元素的矢量化表示; 另一个头通过“BEV obj Detector”模块获取obj BEV边界框,可以使用Transformer架构或类似的PointPillar架构来实现;
3)另一方面,在“2D-3D变换”模块中,2D特征编码根据深度分布投影到3D坐标,其中高度信息被保留; 获得的相机体素特征然后进入“3D解码”模块以获得多尺度体素特征,然后进入“Occupancy”模块进行类别预测以生成体素语义分割。
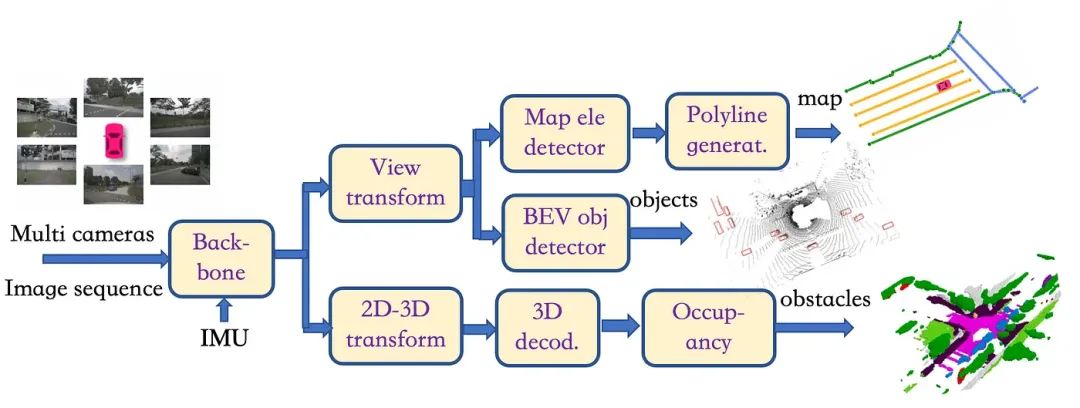
▲图14|多相机数据标注框架
5.3 激光雷达-多相机数据联合标注
最后本文设计了一个激光雷达点云+相机图像数据联合标注的深度学习系统,其详细模型架构如下:
1)相机图像进入“backbone”模块,获取2D图像编码特征;
2)LiDAR点云进入“voxe-lizat”和“feat encod”模块获取3D点云特征;
3)之后分为两条路:
-通过“视图变换”模块将点云特征投影到BEV,同时通过另一个“视图变换”模块基于Transformer或深度分布提取图像特征; 然后我们在“Feat concat”模块中将这两个特征连接在一起; 接下来,转到两个不同的头:一个头通过“BEV obj Detector”模块,类似于PointPillar架构,并获取BEV对象边界框; 另一个头通过“Map Ele Detector”模块和“polyLine Generator”模块输出地图元素的矢量化表示;
-图像特征通过“2D-3D变换”模块投影到3D坐标上,保留高度信息,然后在另一个“feat concat”模块中与点云特征连接以形成体素特征; 接下来,进入“3D Decod”模块和“Occup”模块,得到体素语义分割。
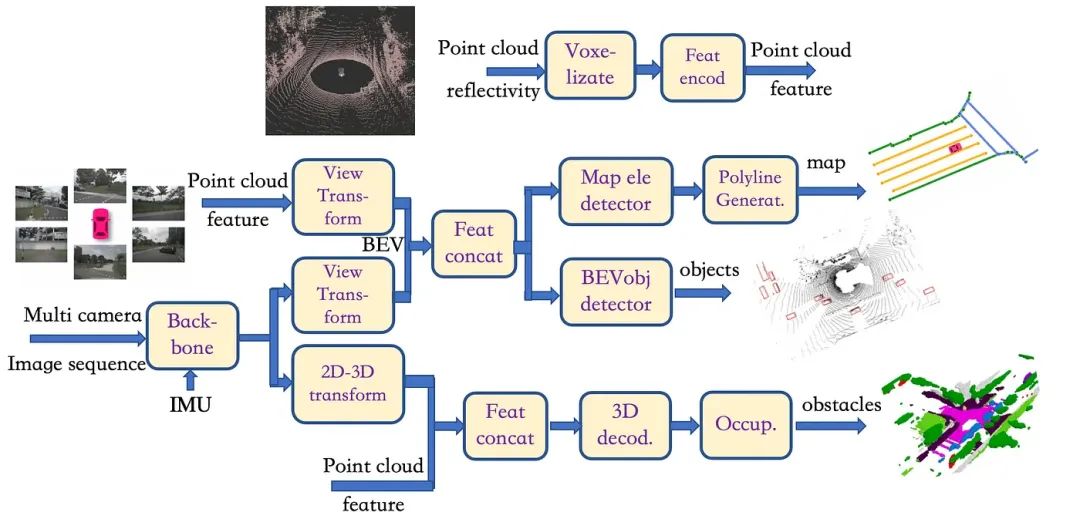
▲图15 LiDAR-多相机数据联合标注模型架构
06
结语
本文提出的自动驾驶数据标注系统实施指南,结合了传统方法和深度学习方法,可以满足研发阶段和量产阶段的需求。 同时,传统方法需要一些人工辅助,为下一步的全深度学习方法提供训练数据。
参考文献:
[1] B Yang, M Bai, M Liang, W Zeng, R Urtasun, “Auto4D: Learning to Label 4D Objects from Sequential Point Clouds”, arXiv 2101.06586, 3, 2021
[2] C R. Qi,Y Zhou,M Najibi,P Sun,K Vo,B Deng,D Anguelov,“ Offboard 3D Object Detection from Point Cloud Sequences”,arXiv 2103.05073, 3, 2021
[3] N Homayounfar, W Ma, J Liang, et al., “DAGMapper: Learning to Map by Discovering Lane Topology”, arXiv 2012.12377, 12, 2020
[4] B Liao, S Chen, X Wang, et al., “MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction”, arXiv 2208.14437, 8, 2022
[5] J Shin, F Rameau, H Jeong, D Kum, “InstaGraM: Instance-level Graph Modeling for Vectorized HD Map Learning”, arXiv 2301.04470, 1, 2023
[6] M Elhousni, Y Lyu, Z Zhang, X Huang , “Automatic Building and Labeling of HD Maps with Deep Learning”, arXiv 2006.00644, 6, 2020
[7] K Tang, X Cao, Z Cao, et al., “THMA: Tencent HD Map AI System for Creating HD Map Annotations”, arXiv 2212.11123, 12, 2022
① 全网独家视频课程
BEV感知
、毫米波雷达视觉融合
、
多传感器标定
、
多传感器融合
、
多模态3D目标检测
、
点云3D目标检测
、
目标跟踪
、
Occupancy、
cuda与TensorRT模型部署
、
协同感知
、
语义分割、
自动驾驶仿真、
传感器部署、
决策规划、轨迹预测
等多个方向学习视频(
扫码即可学习
)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,
这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频
,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦
目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流
等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,
欢迎联系我们!
