DSformer:A Double Sampling Transformer for Multivariate Time Series Long-term Prediction
一篇发表在CIKM 2023上的基于transformer的时间序列预测模型
摘要
多变量长期预测任务
旨在预测未来较长一段时间的数据的变化,从而为决策提供参考。当前模型对时间序列的以下三个特征利用还不充分:全局信息、局部信息、变量相关性。由此文章提出DSformer(double sampling transformer)模型,该模型包含了double sampling(DS) block和 temporal variable attentioon(TVA) block。DS 块使用了下采样和片段采样将原始序列转换成特征向量,由此提取上面提到的全局信息和局部信息,TVA块利用时间注意力和变量注意力来从不同的维度挖掘和提取特征向量中的关键信息。此外,TVA块是基于并行实现的。这些信息汇总后传递给decoder来实现多变量长期预测。最后9个真实世界数据集上的实验结果表明,DSformer比当前的8个基线模型表现更好。
方法
将以下特征应用到时间序列分析任务中:变量相关性a、全局信息(周期性)b、局部信息c、变量相关性
这个和PatchTST得出的结论完全不同,PatchTST提出通道独立性,DSformer则提出变量相关性(其实就是通道)
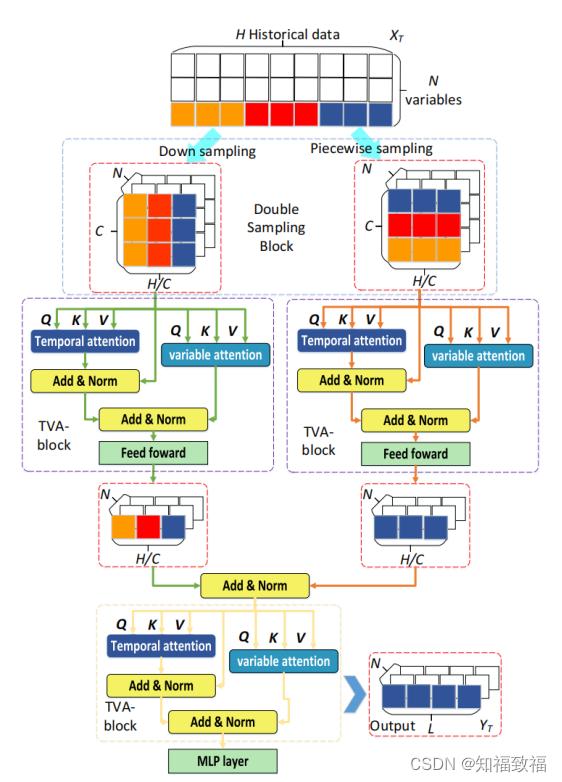
模型结构
创新型提出了三个组件,分别对应全局信息、局部信息、变量相关性
1.down sampling:下采样,采样间隔是i的话,形成i个等长的序列
2.piecewise sampling,片段采样,采样的两个片段之间有重叠
3.TVA,temporal attention and variable attention,时间注意力和变量相关性注意力
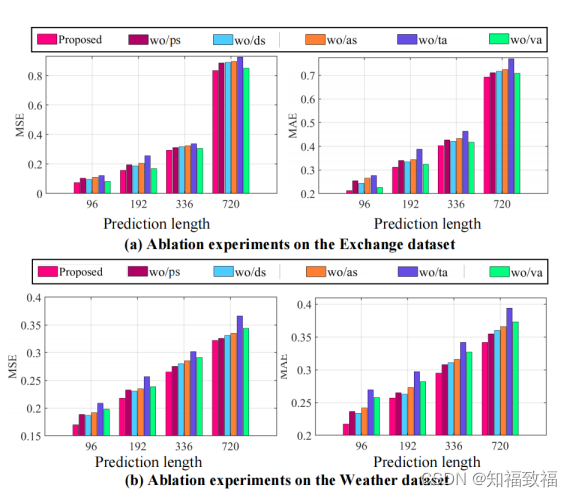
实验
消融实验,探究了移除下采样、移除片段采样、移除两种采样、移除时间注意力、移除变量注意力。消融实验上差异最明显的还是时间注意力,这和LLM4TS的实验结论是一致的,也很好理解,对于时间序列来说,时序注意力的重要性。
DSformer在对比实验里面也对比了PatchTST,但数据不是来自patchTST的论文,因为DSformer的实验的时间序列lookback windows长度和PatchTST设置不同(DSformer:96,PatchTST:336),可能作者又在自己的实验设置下重新跑实验了。
(相同设置pk不过人家,就改实验设置,也是一种智慧)
实验复现
本来想复现实验来着,但是找到的代码只包含了模型文件,没有具体地实验配置文件,就简单地看了看代码,工作量减减
下采样:
def down_sampling(data,n):
result = 0.0
for i in range(n):
line = data[:,:,i::n,:]
if i == 0:
result = line
else:
result = torch.cat([result, line], dim=3)
result = result.transpose(2, 3)
return result
片段采样
def Interval_sample(data,n):
result = 0.0
data_len = data.shape[2] // n
for i in range(n):
line = data[:,:,data_len*i:data_len*(i+1),:]
if i == 0:
result = line
else:
result = torch.cat([result, line], dim=3)
result = result.transpose(2, 3)
return result
self.query = nn.Conv1d(in_channels=dim_input,out_channels=dim_input,kernel_size=1)
self.key = nn.Conv1d(in_channels=dim_input,out_channels=dim_input,kernel_size=1)
self.value = nn.Conv1d(in_channels=dim_input,out_channels=dim_input,kernel_size=1)
self.laynorm = nn.LayerNorm([dim_input])
代码中的 nn.Conv1d 在这样的设置下实际上表示了一个 “1x1 卷积”。1x1卷积在一维情况下实际上类似于
对每个时间步的特征进行线性变换
,没有涉及实质性的空间相邻关系。这种操作通常用于调整特征图的深度或进行特征间的线性组合。这种卷积操作不会改变特征图的长度,只是在特征维度上进行组合和调整。