大模型评估指标
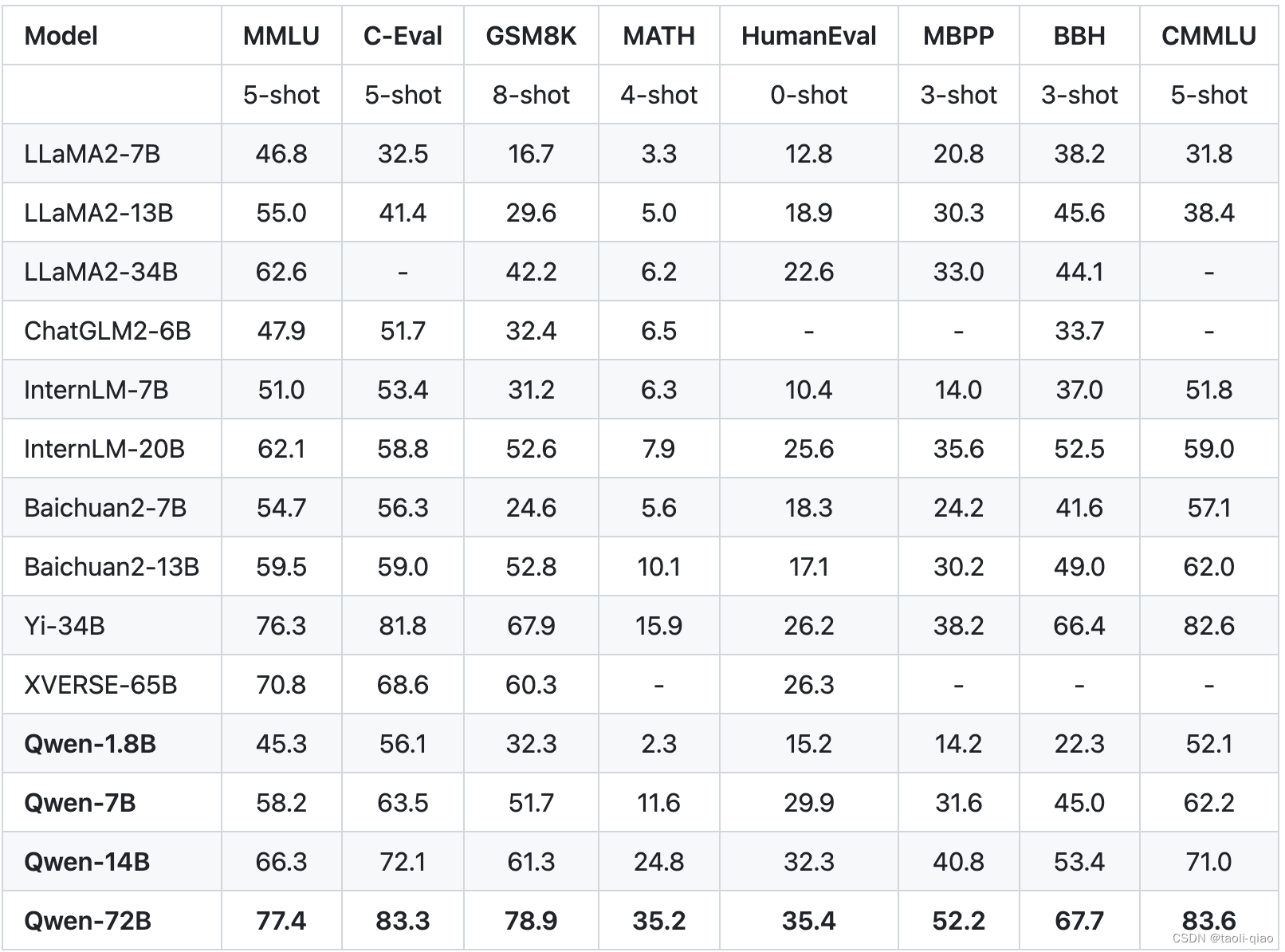
对于AI大模型,可以从哪些方面来进行评估呢?要进行大模型评估,首先需要熟悉有哪些评估指标。大模型有哪些评估指标呢?先从查看开源大模型的官网开始,看看开源大模型给出了哪些评估指标数据。下图是Qwen、Llama的评估指标
下图是Qwen官网给出的评估指标数据,可以看到,Qwen用了多个数据集对大模型进行了评估。
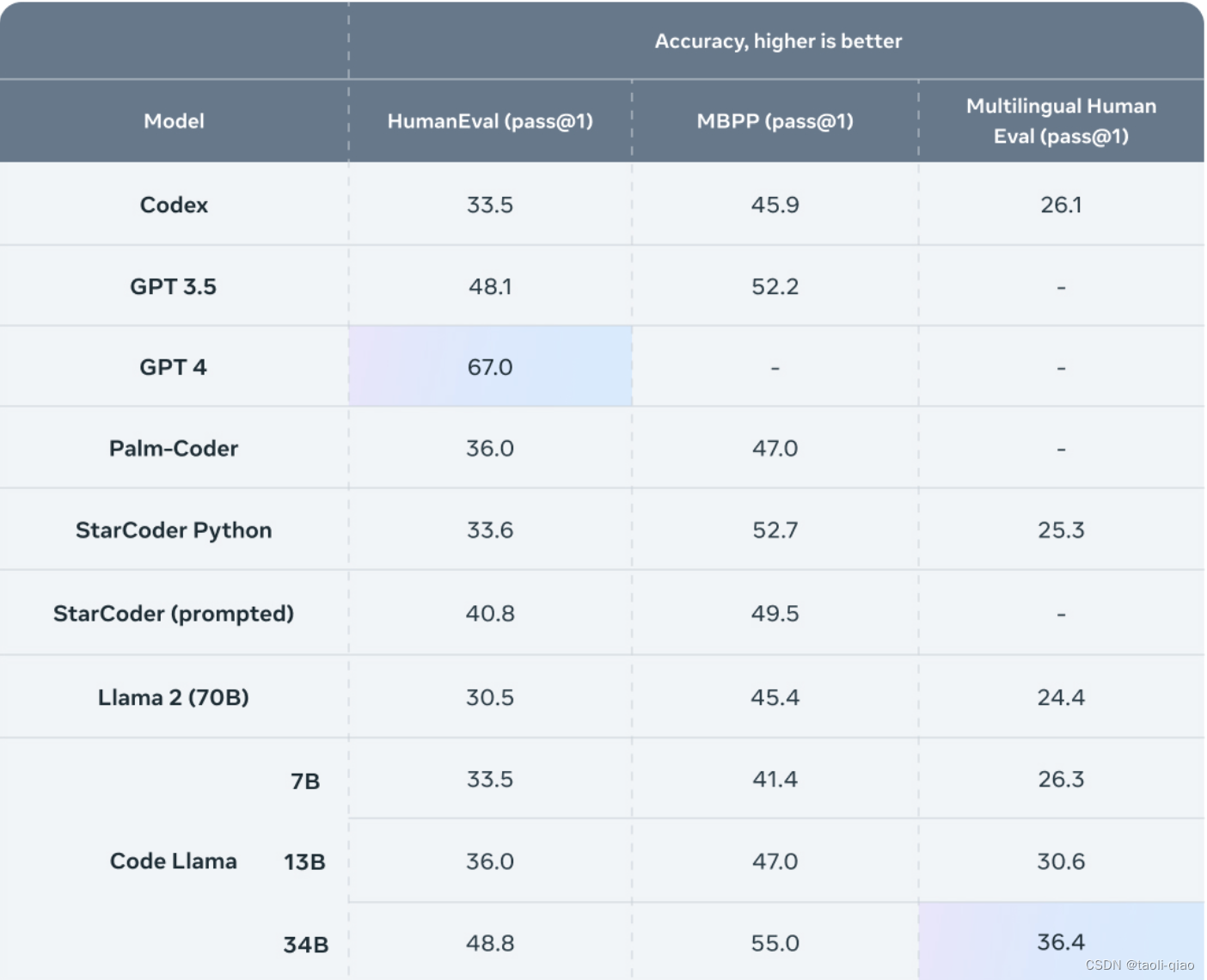
Llama官网给出的评估指标数据,主要是针对代码编写能力,这里使用了HumanEval,MBPP和Multingual Human Eval指标。
那么上面的各项指标具体代表什么含义呢?背后使用了什么数据集进行评估呢?接下来将一一介绍。
评估指标含义
MMLU:
mmlu数据集
包含来自各个知识领域的多项选择题。该数据集涵盖了人文学科、社会科学、自然科学以及其他一些对某些人学习至关重要的领域。数据集包括57个任务,其中包括初等数学、美国历史、计算机科学、法律等内容。通过这个数据集可以评估大模型在不同领域的推理能力。
CMMLU
:CMMLU数据集是一个综合性的中文评估基准,由MBZUAI、上海交通大学、微软亚洲研究院共同推出,在评估语言模型在中文语境下的知识和推理能力方面极具权威性。
一句话理解就是中文版本的MMLU。
C-Eval
:C-Eval是一个全面的中文基础模型评估套件,它包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别,
一句话理解就是中文版本的mmlu
。
GSM-8K
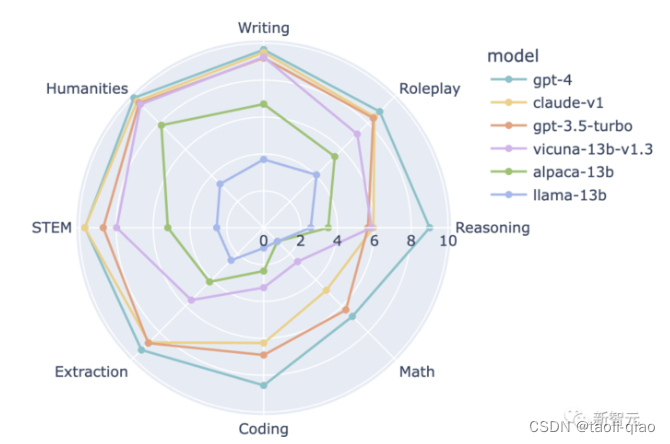
:GSM8K是由人类问题作者创建的8.5K高质量语言多样化小学数学单词问题的数据集,通过这套数据集可以评估大模型的数学推理运算能力。下图是考察大模型8大方面能力,例如写作,人文,推理,角色扮演等,众所周知,数学运算是所有大模型能力最弱的部分。GSM8K数据集就是专门用来评估大模型数学运算能力的。
HumanEval:
HumanEval是一个用于评估代码生成能力的数据集,由OpenAI在2021年推出。 这个数据集包含164个手工编写的编程问题,每个问题都包括一个函数签名、文档字符串(docstring)、函数体以及几个单元测试。 这些问题涵盖了语言理解、推理、算法和简单数学等方面。
MBPP
:MBPP(Mostly Basic Programming Problems)是一个数据集,主要包含了974个短小的Python函数问题,由谷歌在2021年推出,这些问题主要是为初级程序员设计的。 数据集还包含了这些程序的文本描述和用于检查功能正确性的测试用例。一句话理解,和HumanEval一样,也是用于评估大模型代码生成能力的数据集。
BBH
:一个包含23个具有挑战性的 BIG-Bench 任务的套件,我们称之为 BIG-Bench Hard(BBH)。这些任务是先前语言模型评估未能超越平均人类评分者的任务。
Multi-HumanEval:
包含多种编程语言的数据集,一句话理解就是HumanEval只包含了python的编程问题,multi-humaneval包含的多种编程语言,例如java,go,javascript等等。
HumanEval-X
:HumanEval-X 是一个用于评估代码生成模型的多语言能力的基准测试。 它包含了820个高质量的人工制作的数据样本(每个样本都包含测试用例),涵盖了Python、C++、Java、JavaScript和Go这五种编程语言,可用于各种任务,如代码生成和翻译。一句话理解:HumanEval-X数据集和Multi-HumanEval数据集作用相同,只是数据集推出的机构不同而已。
如果完成评估
在了解了评估指标背后的数据集含义后,如何通过数据集完成评估呢?从实现评估的纬度看,上面的数据集可以分为3类。
选择题类型的数据集
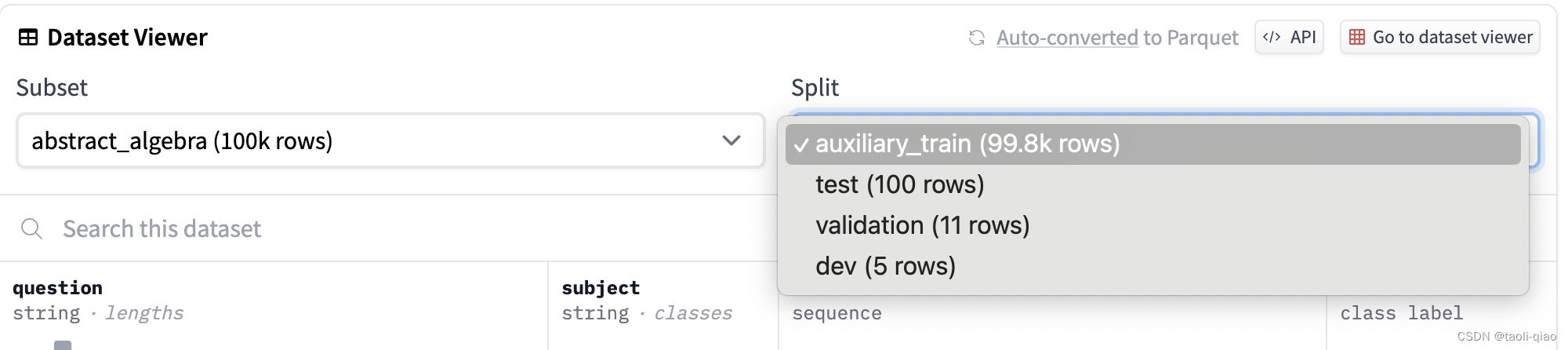
第一类是选择题类型,例如mmlu,cmmlu,c-eval等都属于这种类型。对于选择题类型的评估数据。原理是:将问题输入给大模型,大模型返回的选择题答案与正确答案进行比较,正确答案的占比作为评估数据的指标值。上面的5-shot指:在输入问题给大模型时,给出5个参考样例。实际每个数据集不同类型的问题中都split出了test/validation/train/dev数据集,其中dev数据集只有5条,这5条通常用于shot数据。具体如下图所示,上面提到的所有数据集都可以在
Huggingface
上查看到。
代码编写类型的数据集
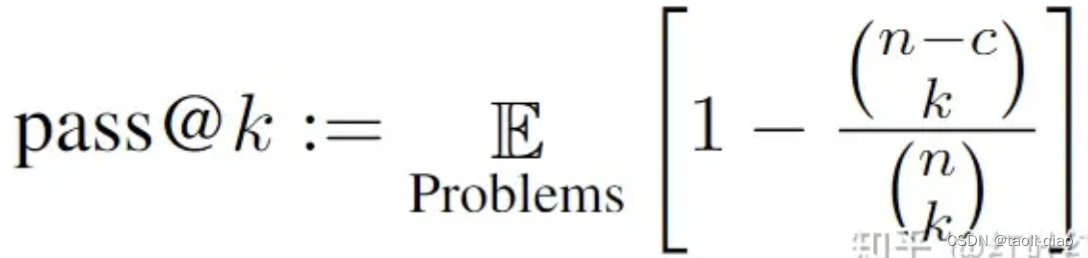
第二类是代码编写类型的数据集,这里评估的原理是:每一条数据中都带了单元测试,大模型编写的代码与数据集中单元测试进行组合,如果单元测试通过,则认为编写的代码正确。当然,在计算Pass@k值的时候,并不是简单使用通过单元测试的量/总数据集的百分比来计算的。Pass@k有个详细的计算公式,具体如下所示,这里暂不会对公式的计算过程进行详细介绍,在后面源代码解释部分,会详细说明该公式的计算过程。下图是pass@k的计算公式。
数学题目类型
第三类是从大模型生成的response中提取答案,例如GSM-8K。对于数学类运算问题,在输入给大模型的input text中,通常都会添加step by step的提示语信息。这样,大模型会生成一个计算数学问题的推演过程,在进行评估时,需要从response中提取出最终的答案。然后,和数据集中的正确答案进行对比,从而得到大模型在数学方面的能力分数。
总结而言,使用三种不同类型数据集,在编写脚本进行评估时,有三种范式,具体如下:

上面只观察了Qwen和Llama大模型公布的评估指标,那还有其他常用大模型评估指标么?我们再来看看其他大模型,例如
Baichuan
和
CodeGeeX2
。
下图是Baichuan官网给出的一些评估指标,这里使用的还是mmlu和c-eval数据集,只是将数据集中的数据进行了进一步的细分,来观察不同纬度的得分。

另外,Baichuan模型的官网还使用了
Gaokao
和AIGEval的数据集进行评估,这两个数据集都是选择题类型,所以,从实现评估脚本的纬度来看,和mmlu评估方式一样,属于第一种类型。
CodeGeeX2是一款专门用于代码生成的大模型,如下图所示,官网给出的指标主要是pass@1,pass@10,pass@100等指标。属于上面第二种类型。
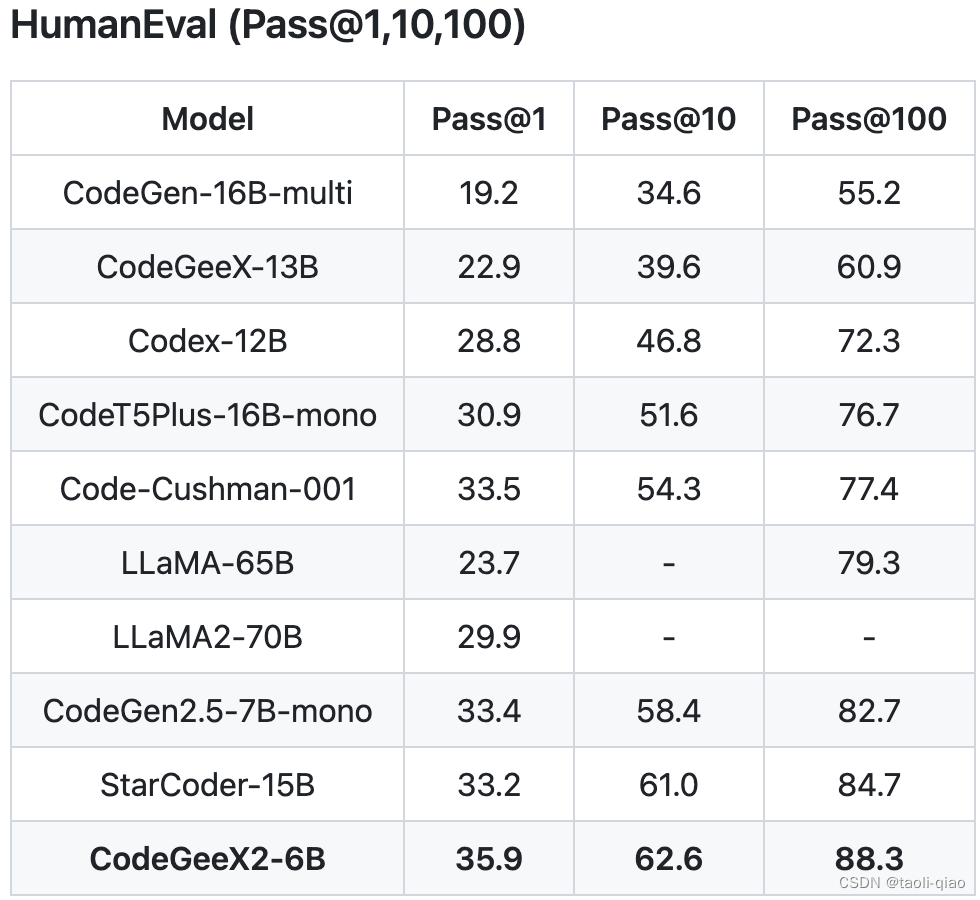
其中,HumanEval-X数据集是一个用于评估代码生成模型的多语言能力的基准测试。 它包含了820个高质量的人工制作的数据样本(每个样本都包含测试用例),涵盖了Python、C++、Java、JavaScript和Go这五种编程语言,可用于各种任务,如代码生成和翻译等。同
multi-humaneval数据集作用相同。
以上就是对大模型评估的理论介绍,下一篇博客将从源代码实现层面出发,一步步分析如何通过python脚本调用LLM生成这些指标。