Linux通过时间片来控制每个任务的执行时间,每经过一个时间片就触发一次切换,通过不停的来回切换执行任务,当切换速度很快的时候,就像视觉暂留一样,给用户造成一个任务并行效果的假象。今天我们将一起来探究这个“幻术”背后的秘密~
我将任务切换分为两种方式,一种是时间片到了,硬件触发时钟中断导致进程发生的切换;还有一种是进程等待资源而进入睡眠状态导致的进程切换,下面让我们一起来见证奇迹的时刻!
我将模拟一个进程执行到触发时钟中断,然后发生切换的栈帧变化图,并配合文字来详细解释这一精妙的武功招式(图的左边是瞬移过去前的样子,右边是瞬移回来后的样子,注意栈的选择子变化和指令寄存器eip的变化)
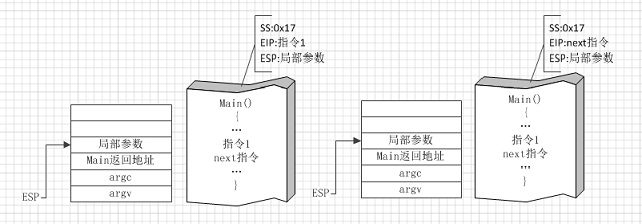 图①
图①
图①左侧描绘的是在进程执行指令1后耗尽时间片即将触发时钟中断的状体;右侧是从时钟中断服务程序返回的状态。
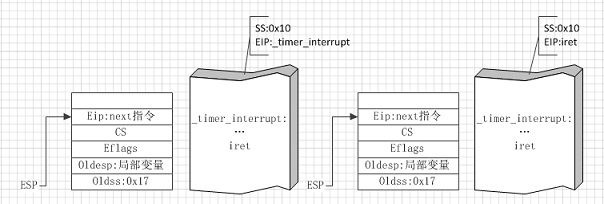 图②
图②
图②左侧是由用户态陷入内核态的时钟中断服务程序时的状态(注意esp指向的是内核栈),右侧是进程即将从内核态的时钟中断服务程序恢复到用户态时的状态。
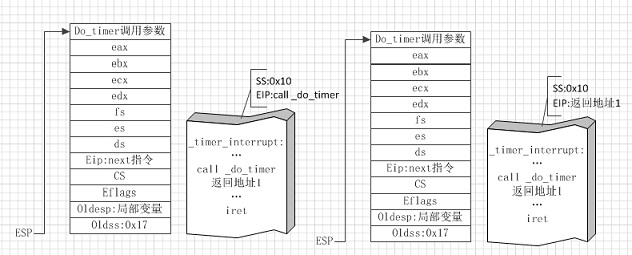 图③
图③
图③左侧是中断服务程序即将调用对应C处理函数do_timer时的状态,右侧是从do_timer函数返回时的状态
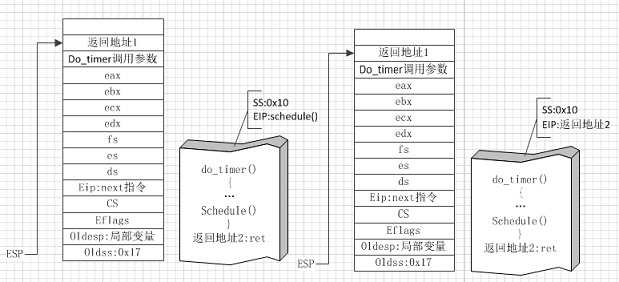 图④
图④
图④左侧是时钟中断C处理函数即将调用进程调度函数schedule时的状态,右侧是从进程调度函数返回时的状态
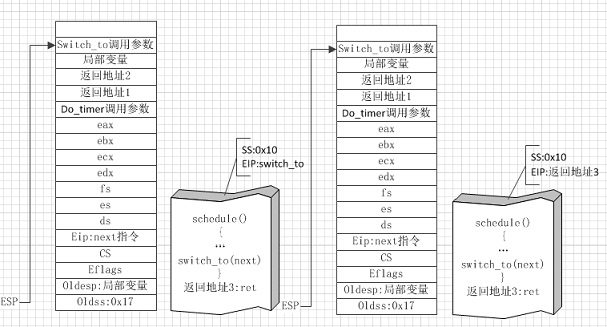 图⑤
图⑤
图⑤左侧是在遍历内核保存的所有进程的task信息后,决定下个时间片执行的进程为next时的状态,右侧是其他的进程执行schedule后,切换为本进程后,本进程重新执行并从switch_to返回时的状态
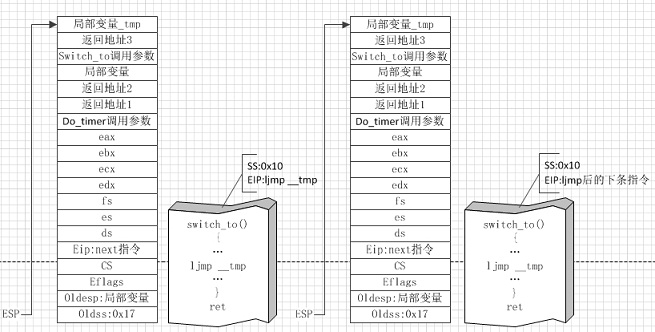 图⑥
图⑥
图⑥左侧是即将切换到其他进程时的状态,右侧是其他的进程执行schedule后,切换为本进程后,本进程重新执行时的状态。图⑥是进程切换的核心步骤,我们来看下switch_to的源码:
#define switch_to(n) {\
struct {long a,b;} __tmp; \
__asm__("cmpl %%ecx,_current\n\t" \
"je 1f\n\t" \
"xchgl %%ecx,_current\n\t" \
"movw %%dx,%1\n\t" \
"ljmp %0\n\t" \
"cmpl %%ecx,%2\n\t" \
"jne 1f\n\t" \
"clts\n" \
"1:" \
::"m" (*&__tmp.a),"m" (*&__tmp.b), \
"m" (last_task_used_math),"d" _TSS(n),"c" ((long) task[n])); \
}
通过这段汇编我们可以看到,__tmp.b保存的是edx寄存器的内容就是_TSS(n)即将要跳转的内容的tss结构的选择子(tss结构是存放在gdt表中的,忘记的童鞋可以回头看看笔记二的内容)。执行ljmp __tmp将会发生进程切换,CPU会自动将当前所有寄存器的值保存到当前进程的TSS中(所以本进程下次被切换回来的时候,还是继续执行switch_to的ljmp后的cmpl指令,而不是直接回用户态执行,由于自动保存了栈指针,而回溯信息是保存在内核栈上的,所以切换回来后依然能回到切换时的状态,沿着上面图的右侧逆向返回),然后从_tmp所指向的新进程的TSS中取出缓存所有的寄存器的值并重置所有寄存器,从而完成旧进程到新进程的切换,被唤醒的进程也是从ljmp后的cmpl指令开始执行的,整个过程如下图所示:
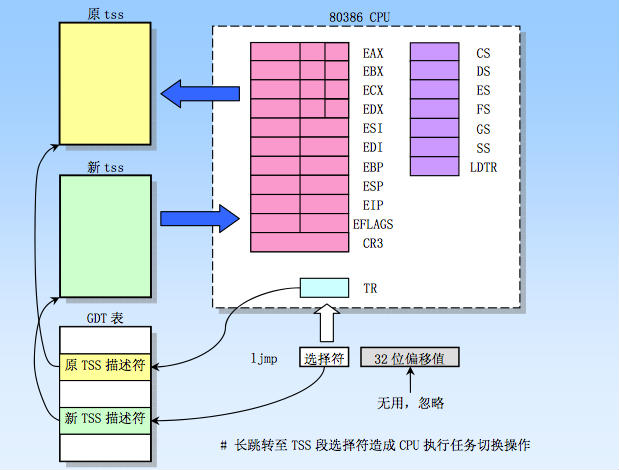
上面就是进程切换的过程,我们发现进程调度并不是由什么特殊的进程执行的,而是每个进程自己陷入内核后就成了执行进程调度的特殊进程,为什么可以这样做?因为所有进程的task信息都是在内核数据段的,所以当进程陷入内核态的时候,它就具备了超级进程所需的权限(内核级)、指令(内核进程调度代码)和数据(其他进程的task信息),而且每个进程都有自己独立的内核栈,使得每个进程都可以保存属于自己的执行信息和回溯信息(能进能退乃真正法器~),所以每个进程都可以成为“超级英雄”。
下面将要介绍的是进程切换的另一种情形,由于等待资源而导致的进程切换,同样我将模拟一个进程等待资源,然后发生切换的栈帧变化图,并配合文字来详细解释这一精妙的武功招式(图的左边是瞬移过去前的样子,右边是瞬移回来后的样子,注意栈的选择子变化和指令寄存器eip的变化)
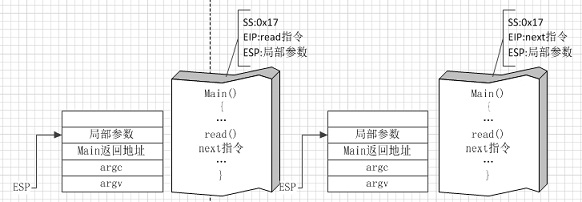 图①
图①
图①左侧是用户程序即将使用系统调用read读取磁盘数据时的状态,右侧是完成磁盘读取后返回时的状态
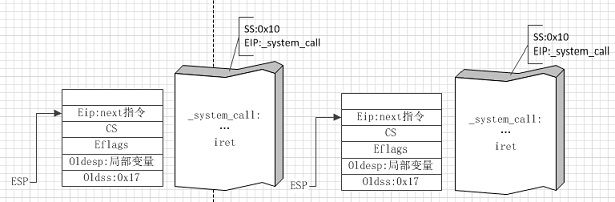 图②
图②
图②左侧是用户程序进入系统调用中断服务程序时的状态,右侧是准备从系统调用返回用户程序时的状态
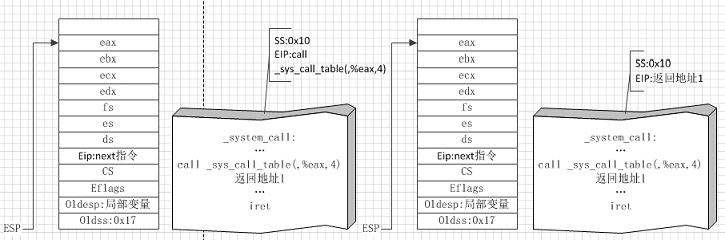 图③
图③
图③左侧是即将执行系统调用C函数sys_read时的状态,右侧是执行完sys_read后返回时的状态
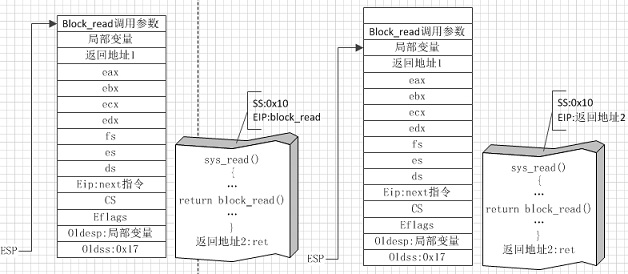 图④
图④
图④左侧是系统调用sys_read即将调用盘块读取函数时的状态,右侧是完成盘块读取后返回时的状态。
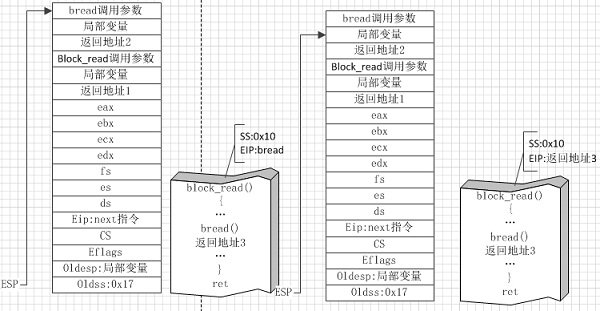 图⑤
图⑤
图⑤左侧是即将调用高速缓冲块读操作时的状态,右侧是完成盘块到高速缓冲块读操作返回时的状态
 图⑥
图⑥
图⑥左侧是即将调用获取空闲高速缓冲块函数时的状态,右侧是获取空闲高速缓冲块后返回时的状态
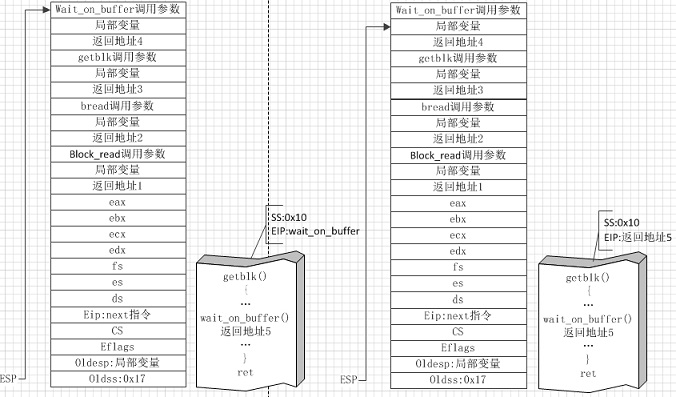 图⑦
图⑦
图⑦左侧是将要调用等待高速缓冲块解锁函数时的状态,右侧是等待高速缓冲块解锁后返回时的状态
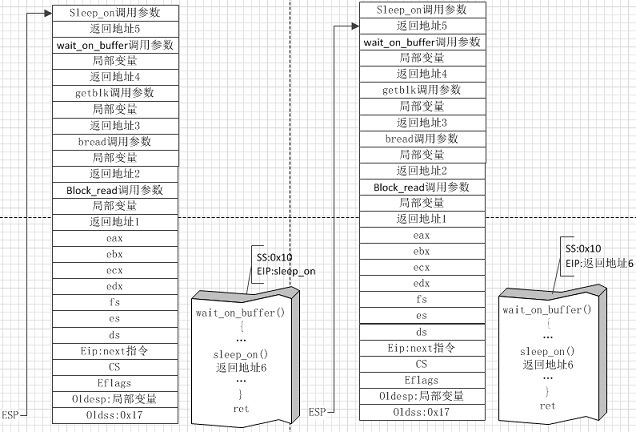 图⑧
图⑧
图⑧左侧是发现高速缓冲块被加锁,将要调用sleep_on函数进入等待时的状态,右侧是高速缓冲块解锁后进程被唤醒后从sleep_on函数返回时的状态
 图⑨
图⑨
图⑨左侧是将当前进程加入对应高速缓冲块等待队列后即将调用进程调度函数时的状态,右侧是进程在被高速缓冲块解锁唤醒后,经过其他进程的进程调度切换回来后从调度函数返回时的状态(这边假设等待链表只有一个等待进程,等待链表的形成和唤醒,我们在本节最末会详细讨论)
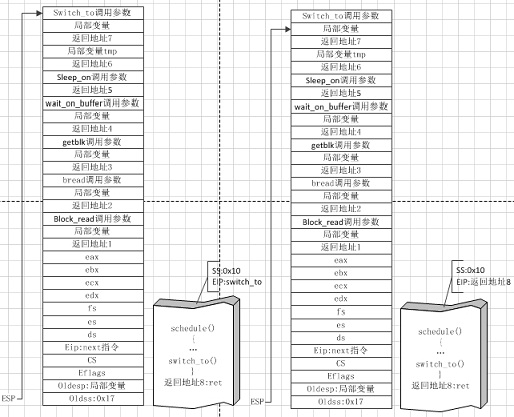 图(10)
图(10)
图(10)和上卷的时钟中断时的进程切换图⑤一样,这边就不再解释了
 图(11)
图(11)
图(11)和上卷的时钟中断时的进程切换图⑥一样,这边就不再解释了
通过对比我们发现,等待资源引起的进程切换和时钟中断最后几步都差不多,只不过进程调度schedule函数一个是在sleep_on函数里调用的,一个是在do_timer函数里调用的,而且它们切换回来的方式都差不多,都是通过其他进程执行schedule切换回来,只不过等待资源的进程在能被重新调度前还需要多一个唤醒步骤,接下来我们就讨论资源等待链的形成和唤醒过程。
我们先来看下sleep_on函数:
void sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
if (!p)
return;
if (current == &(init_task.task))
panic("task[0] trying to sleep");
tmp = *p;
*p = current;
current->state = TASK_UNINTERRUPTIBLE;
schedule();
if (tmp)
tmp->state=0;
}
等待链表的形成核心步骤就是第9和10行代码,如何通过这两步形成一个等待链表呢?其中一个关键就是内核栈,还记得我们前面讲解过的栈吗?栈保存了函数的局部变量,所以这边的tmp其实是保存在进程内核栈中的;另一个关键就是输入参数,输入参数是一个指向任务结构体指针的指针,我们来看下sleep_on函数的调用方式
static inline void wait_on_buffer(struct buffer_head * bh)
{
cli();
while (bh->b_lock)
sleep_on(&bh->b_wait);
sti();
}
我们可以看到传入的参数就是高速缓冲块的等待链表头指针,所以使用指针的指针我们就能在sleep_on中改变它的指向,第9行我们用内核栈中的局部变量保存了以前的等待链表,然后第10行我们将高速缓冲块的等待链表的头指针指向了当前进程的任务结构,即我们将当前进程加入了高速缓冲块的等待链表的头部,并且利用各个进程的内核栈形成了一个等待链表,就如下图一样(其中紫色部分就是进程的内核栈):
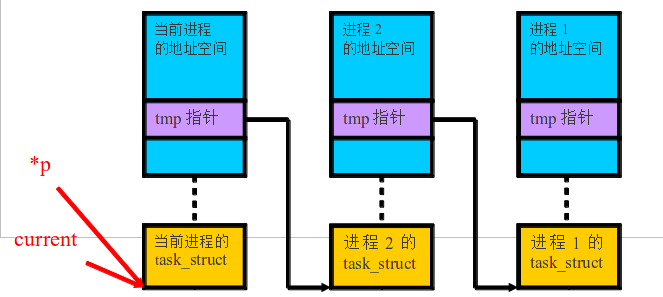
那么它们是如何被唤醒的呢?我们看到在sleep_on看到了进程的状态都被修改成了不可中断的等待状态,进程被重新调度的方式只有通过其他进程执行进程调度函数schedule切换回来,而进度调度函数schedule只会选择可执行状态的进程作为下个切换进程,所以我们要修改等待链表中的进程的状态,这样它们就能被进程调度函数schedule重新选择了。等待链表进程的唤醒有点类似多米诺骨牌!我们先来看下链表首部的进程是怎么唤醒的:
void brelse(struct buffer_head * buf)
{
if (!buf)
return;
wait_on_buffer(buf);
if (!(buf->b_count--))
panic("Trying to free free buffer");
wake_up(&buffer_wait);
}
void wake_up(struct task_struct **p)
{
if (p && *p) {
(**p).state=0;
*p=NULL;
}
}
我们会发现在高速缓冲块解锁后会调用wake_up函数唤醒等待链表首部的第一个进程,就是修改它的状态为可执行状态,那么其他的进程怎么被唤醒呢?我们前面知道在等待链表上的进程的内核空间都保存了下个等待进程的任务结构,所以当当前进程被重新调度并回溯到sleep_on函数后,会继续执行一段代码,而这段代码就像多米诺骨牌一样,不停的唤醒下个等待进程,下面我们就来看下这个神奇的代码(第5和第6行,tmp指向的是下个等待进程的任任务结构):
void sleep_on(struct task_struct **p)
{
;省略无关代码
schedule();
if (tmp)
tmp->state=0;
}
除了普通的sleep_on函数,还有一个可中断的sleep_on函数,就是下面的interruptible_sleep_on函数
void interruptible_sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
if (!p)
return;
if (current == &(init_task.task))
panic("task[0] trying to sleep");
tmp=*p;
*p=current;
repeat: current->state = TASK_INTERRUPTIBLE;
schedule();
if (*p && *p != current) {
(**p).state=0;
goto repeat;
}
*p=NULL;
if (tmp)
tmp->state=0;
}
两者的主要区别在于进程的等待状态一个是不可中断,一个是可中断的,造成的结果就是等待链表的首部可能会被插入其他等待进程,当本进程被切换回来后自己已经不是等待链表的首节点了,自己前面还插入了其他优先级高的等待进程,所以要优先唤醒前面的等待进程,办法就是唤醒等待链表首节点指向的进程,然后重新执行调度,重复这个过程直到自己重新变回等待链表首部,后面的步骤就和普通的sleep_on一样了(这边觉得Linux内核注释有点问题,*p=NULL并没有错,因为这个时候高速缓冲块的等待链表指针已经是指向的是本进程,而本进程已经被唤醒,链表其他部分是保存在本进程的内核栈的tmp中的,所以链表首部指针已经没用了,赋值为NULL是正确的,可以看下wake_up是怎么在唤醒链表首节点后处理等待链表指针的)
对于资源等待链表的形成和唤醒,我还有个改进方案,我会设置高速缓冲区的等待b_wait为一个int数组,大小为NR_TASK+1,为什么+1呢?因为sleep_on和interruptible_sleep_on唤醒都是先唤醒头部,然后依次唤醒后续任务,所以我们需要b_wait[0]来指明第一个任务(这个和task数组的下标一一对应,用数组来模拟链表),用于形成链表结构,而且0表示无等待任务,比-1好,因为初始化数组全为-1没有全0快,相应的函数也要改造下
①sleep_on函数要改造下,最后的if (tmp)tmp->state=0,改成修改b_wait[0]的值并去掉b_wait[b_wait[0]]=0
②在wake_up直接遍历等待队列数组,然后将所有等待队列的状态设置成可运行,然后一次清空整个等待数组,并且sleep_on函数最后的if (tmp)tmp->state=0也可以去掉了
①方案是和现在代码逻辑差不多,②方案就是改进方案,②可以一次性恢复所有等待进程,让所有进程都可以重新按优先级来调度,而原先的方式只能像多米诺骨牌一样依次唤醒,无法按照任务的实际紧急程度来跳跃式唤醒。这个只是想法,还未实践,主要是目前我还未发觉我需要深入研究Linux内核,等我学完其他黑客技术到了有实际需要的时候,我将会实际编译把内核然后继续深入研究
本节我们揭开了操作系统多任务这个幻术的秘密,下节我们将揭开操作系统另一个幻术------内存分配大法,它究竟是如何在一点点内存上运行这么多程序的?下节揭秘还在继续,敬请期待~
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)