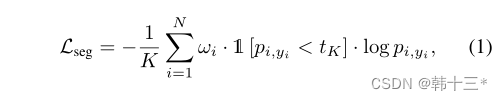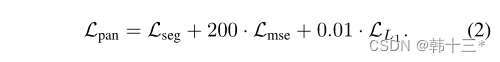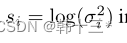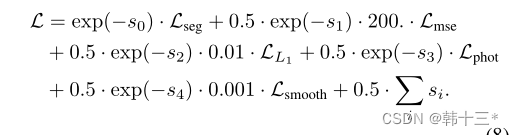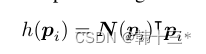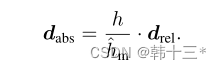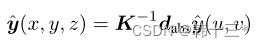ok,浅浅的点评一下好吧,这一篇开头吧我还觉得不错的,作为开创性的工作,我最疑惑的地方是他怎么避免不同任务损失之间损失平衡和梯度爆炸的问题的,结果看完才发现,用的前人的同调不确定度。。。怎么说呢?这篇论文感觉就是投了很多论文的大佬写出来的好故事。叙述真是不错,但实际工作几乎没有,所谓的开创,2018年的同调不确定性就已经将语义,实例还有深度估计放在一起做多任务了,而本文只是把这三个都换成了当前的网络,还有,把以前的监督深度估计,换成了无监督深度估计,其他两个不出意外的话,还是监督(我没看到相关描述)。这就尴尬了呀,还有所谓的DGC模块,也是采用了2020的密集几何约束模块,刚好全景分割可以进行实例分割,以前的地面点不准确,现在刚好可以优化一下。除此之外,无他。主体还是放在了深度估计方向,我觉得也就是这个方向做的人少或者稿件到了不是深度估计方向的评委手里面,但凡这些人查一下文献,估计这篇论文都很难过了。不过这也没办法,方法部分细看的人太少了(除了像我这种做这个方向的会细究,谁会仔细的看方法呢?),前面介绍和当前工作讲的是真好,评委估计都被迷惑了。。。值得学习!
首次提出了单目几何场景理解,并将单目几何场景理解定义为全景分割和自监督单目深度估计(场景理解是计算机视觉中的一个大类,图像分割,检测,识别都算是里面的一种任务,这个定义有点勉强了,还以为是国人,没想到是英文名字)。本文注重于提升响应速度。在KITTI和Cityscapes上进行了测试,效果良好。
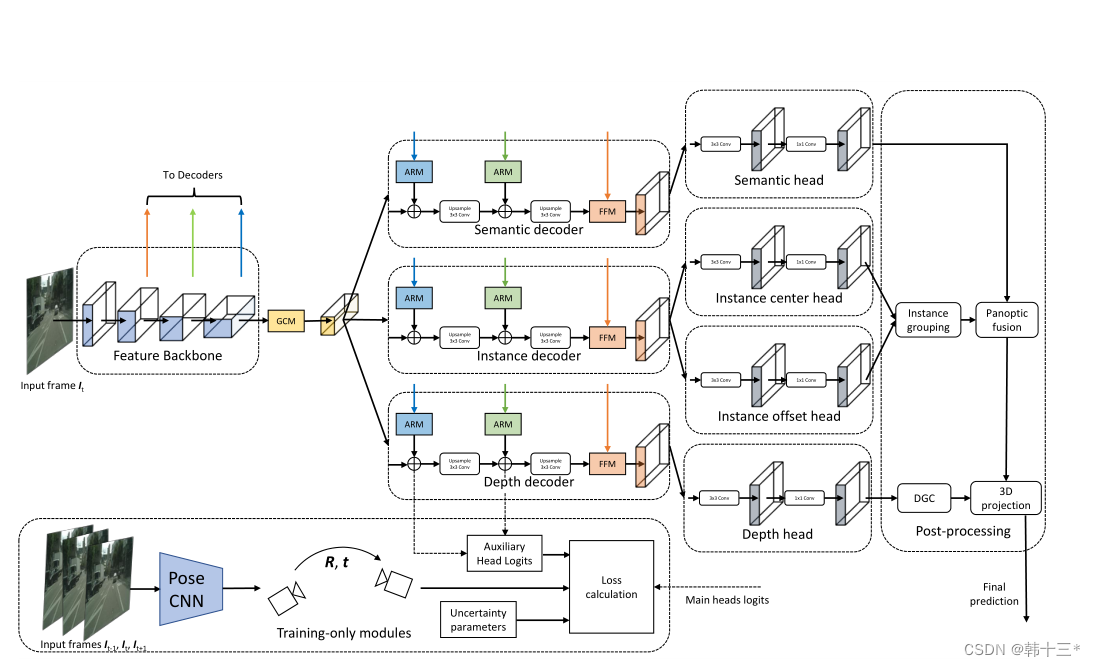
场景理解是自动驾驶的重要组成部分,场景理解中的一种重要任务是全景分割,共分为语义分割和实例分割。语义分割侧重于东西类,例如天空,道路等、实例分割侧重于事物类,例如可数的车辆,行人等。全景分割为图像中的每一个像素提供唯一的类标签,也为可数对象提供实例ID。但目前的研究都在提升全景分割的准备性而不是推理速度,使得目前的方法不适合集成在车感系统中。此外,2D图像提供的信息有限,3D图像可以使行为规划系统对当前环境有更好的推理结果。 由于相机测量模型的误差性,使得我们很难获得准确的深度注释。立体相机可以提供深度信息,但需要两个相机之间进行精确校准,并且在距离摄像头较远的区域,会出现很多立体匹配失败的缺失区域。相比之下,激光雷达传感器虽然可以获得准确的深地信息,并将测量结果投影到图像平面来作为标签,但是深度信息极其稀疏,无法得到逐像素的深度信息。而自监督单目深度估计,通过视频序列作为自监督方式,得到了较为准确的逐像素深度信息。 组合多个视觉任务需要更多的硬件资源,这样的方法在低资源环境中受到很大限制。多任务学习可以在单个网络中实现多个任务,但这也存在着损失平衡和梯度冲突的问题。在本文中,我们提出了MGNet,通过将全景分割最新的框架PD和自监督单目深度估计最新的框架Mono2进行融合,但本文更注重于推理速度的提升。本文提出了密集几何约束模块DGC的改进版本,使本文的全景预测进行尺度感知深度估计。
据本文所知,目前还没有与我们相似的组合算法,所以我们分别介绍了全景分割和自监督深度估计的相关工作,最后,我们讨论了多任务学习领域的相关工作。(多任务框架是未来神经网络发展的一个必经阶段,从我的角度来看,目前还没有达到百花齐放的时候。从论文的角度来说,做多任务框架是有一定的开创性的,但是在叙述过程中,怎样避免论文变成C=A+B,这可能是作者要注意的主要问题。传统的论文是针对某一个问题提出一个经过实验验证的解决方案,但多任务框架势必会存在多问题的主次问题,那如何建立主要矛盾就成为了比提出解决方案更为重要的步骤。这篇论文我个人认为在叙述上还是值得借鉴的。主要矛盾放在了深度估计和全景分割的响应缓慢上,在方向介绍中,先讲了全景分割,一句3D的全景分割比2D要好,提出图像缺失深度信息,最后介绍深度估计。过度流畅,叙述平滑。要是在深度估计中再讲一句全景分割有助于深度信息的获取那就更好了。在当前工作方面,由于先前没有同样的工作,所以分别介绍了全景分割和深度估计,最后讲多任务框架的相关工作,文章结构合理。后面如果写多任务框架的相关论文,可以参考本文结构。) 全景分割是用来同意语义分割和实例分割的任务,PD将实例掩膜表示为像素偏移和中心关键点,以前的一些工作和方法证明了PD的有效性。最新的方法直接用事物类的统一来预测全景分割。然而他们的方法计算量较大,不适合实时推理,目前只有少数作品关注了实时全景分割,Hou等人提出了一种具有高效数据流的方法,在城市景观的全分辨率图上可以达到30FPS,我们的工作在解决深度估计的额外任务时也可以达到类似的效果。 zhou等人首先提出采用单目视频的方式来作为自监督深度估计的输入,首次提出了采用相邻位姿的位姿约束来作为自监督单目深度估计的约束方式。Godard等人提出了一种自动掩膜方案,以避免低纹理和运动物体在深度估计中出现的空洞现象。xue等人提出了一种单目绝对深度估计方式,采用了DGC模块来作为相机位姿的计算方法,其中DGC为密集几何约束,本文将DGC改进后引入我们的模型,其中DGC与全景分割相互作用。 多任务框架已经得到研究人员广泛的关注,通过一个网络可以实现多个任务,这极大的节省了硬件资源,也提高了模型的泛化性。Goel等人提出了QuadroNet,这是一种能够实时预测2D边界框、全景分割和单目深度估计的模型。虽然该工作和我们的任务相似,但他们是采用监督方式训练的。Kingner等人采用语义分割和深度估计相结合的方式,而我们选择了全景分割和深度估计相结合的方式。
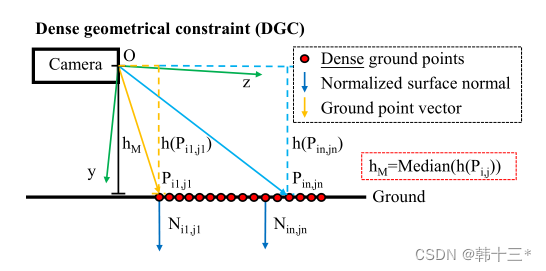
MGNet主体框架如下,采用轻量化主干网络作为编码器,使用全局上下文模块GCM最大化感受野。三个任务特定解码器采用注意力细化模块ARM和特征融合模块FFM来融合不同尺度的主干特征。任务特定的头奖不同特征融合为logits。全局分割分解为语义分割和实例分割两部分,实例分割分解为实例中心位置和实例偏移两个部分。后处理将实例分组到给定偏移预测的最近中心,最后基于多数投票分配语义。深度预测采用密集几何预测模块DGC来进行缩放,然后将全景预测转化为3D点云。姿态网络用来计算相邻帧的位姿关系以及用于多任务优化的不确定性参数,仅在训练时使用。 MGNet采用一个编码器,三个解码器的方式来作为整体架构,在编码器后加入全局上下文模块GCM,用来提取细粒度特征。全景分割方面,采用PD的加权自举交叉熵损失来进行语义分割。 全景分割的总损失为: 深度估计的损失和Mono2一样,这里就不放了。 同调不确定性加权:将两个损失相加的朴素方法可能不适合神经网络的优化,所以,本文采用同调不确定度来对每个任务进行加权。 后处理部分包括:实例分组、全景融合、深度缩放和3D投影。深度缩放部分采用DGC模块来获得真实比例。以前的DGC采用摄像机集合体的预测深度来估计每个地面点的相机高度,最终选择相机高度的中值来作为真实深度,然后对深度图进行比例缩放,以获得真实深度。但是以前的真实深度用于生成3D点云,通过检测点云的表面法向量来判断点是否为店面点,但这样会出现许多误报,例如车顶。而本文的DGC加入了全景分割,只对地面像素的点进行检测,有效的避免了上述问题的发生。 我们通过2D点可以恢复到3D点,在如下平面坐标系中,每一个地面点Pij的y坐标都可以近似于相机距离地面的实际高度所以当点Pij乘以法向量n = (0, 1, 0)⊺相当于把取出来,也就是如下公式。 h为相机实际高度,hm是估计相机的中值。 3D点云采用如下公式获得。
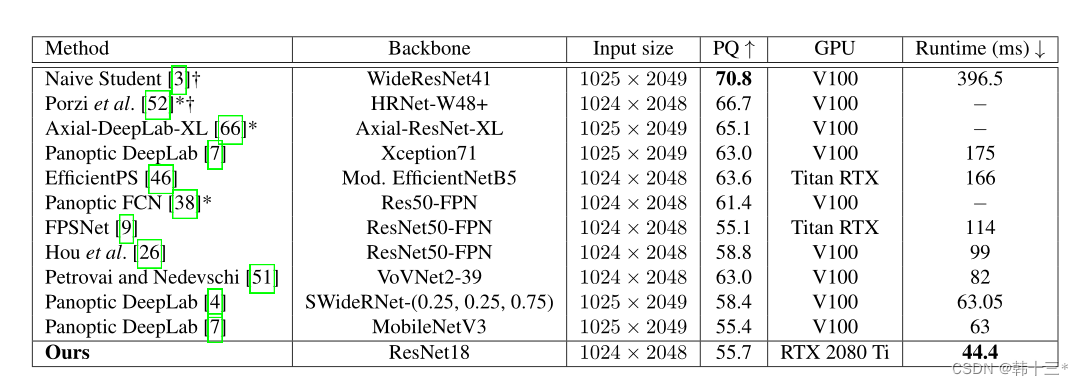
响应速度结果对比。