参考
张钰,刘建伟,左信. 多任务学习[J]. 计算机学报, 2020.
Multi-task Learning 理论(多任务学习)
概述
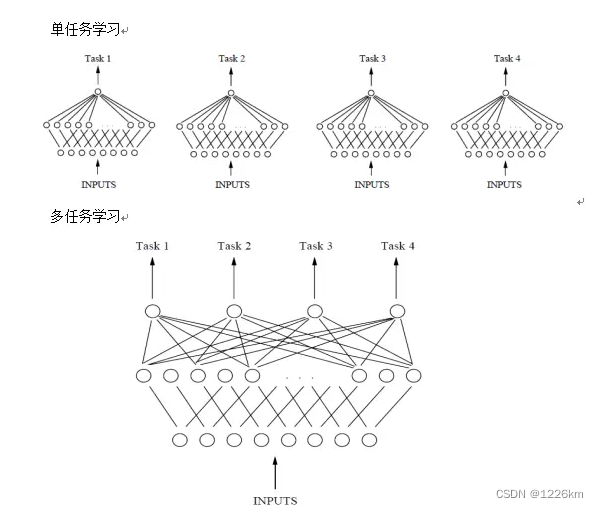
单任务独立学习
-
只使用单个任务的样本信息
-
局限性
:
1、忽略其它任务的经验信息,致使训练冗余重复和学习资源浪费,限制性能提升
2、对于训练样本少且特征维数高的任务,单任务学习出现秩亏且存在过拟合风险
多任务学习(MTL)
-
Multi-task Learning,MTL
-
属于
迁移学习
范畴
但其并不注重源领域和未知领域的知识迁移,主要利用域之间相似的知识信息(同时学习目标任务和源任务),提升特定任务的学习效果,注重领域知识的共享性
-
同时考虑多个相关任务
-
目的
:
利用任务间的内在关系,提高单个任务的泛化性能
-
方法
1、假设不同任务数据分布之间存在一定相似性
2、基于此通过共同训练和优化建立任务之间的联系
3、同时训练多个相关任务,并进一步挖掘训练中的特定领域信息以提高单个任务的泛化性能
-
优势
1、能够充分促进任务之间的信息交换
2、达到相互学习的目的
3、在各自任务样本容量有限的条件下,可从其它任务获得一定启发,增加单个任务样本空间大小
4、借助于学习过程中的信息迁移,间接利用其它任务数据
5、缓解对大量标注数据的依赖
6、提升各自任务学习性能
7、多任务之间平均了各自的噪声差异,得到了更一般的表示模型,可为相关特征提供额外的参考信息,有效降低单个任务过拟合和泛化能力差的风险
-
多任务情况
1、任务数据采集来源与分布相似,即可能存在共同的归纳偏置
2、但由于学习目的不完全相同,不能简单地将它们合并为一个任务
3、此时可看作是由多个相关任务组成,选择多个任务联合学习,从而获得一些潜在信息以提高各自任务的学习效果
多任务的类型
联合学习(joint learning)(对称)
-
也称
对称多任务学习
,不区分主任务和辅助任务
-
试图同时执行所有任务以便提高单个任务的学习性能,通过任务之间的特征信息迁移共同地提升所有任务的学习效率
-
联合学习多个分类任务有助于减少任务之间概率分布差异
自主学习(learning to learn)(非对称)
-
也称
非对称多任务学习
-
目标是利用源任务的信息来改进某些目标任务的学习性能,通常在源任务被学习后使用
-
与迁移学习不同,自主学习建立在共同学习基础上,要求源域与目标域分布具有相似性
非对称任务中的几种典型辅助任务
将输入变输出的逆多任务学习
-
有监督学习:输入和输出之间有明显区分,观测值为输入,待预测值为输出,也称为监督信号
-
借鉴无监督学习模式:将特征同时作为输入和输出,利用不同无监督样本的特征信息为彼此提供监督信号
-
方法:在有监督的多任务学习中如果存在比作为输入更有价值的特征,可以使用其它任务上的样本特征作为监督信号(因为附加辅助输出中的噪声往往小于附加辅助输入中的噪声),学习目标任务训练集上其它输入特征到这部分特征的映射关系,学习映射关系的过程可以作为辅助任务
Caruana. Promoting poor feature to supervisors:Some inputs work better as outputs. 1997.
对抗性多任务学习
-
受生成对抗网络启发
-
目的:得到对主要任务有利而与次要任务对抗的表示
-
不断利用辅助任务包含的相反信息,消除主要任务的噪声,从而学习到接近底层数据真实表示的特征
Shinohara. Adversarial multi-task learning of deep neural networks for robust speech recognition. 2016.
辅助任务提供注意力特征的多任务学习
-
单任务学习:
显著特征对学习结果影响较大,
不常用特征通常被忽略
-
但部分不常用特征对于任务的某些功能是必要的
-
可以通过辅助任务单独引入,在共同学习过程中将其放大,平衡显著特征带来的学习不充分问题
-
此类在目标任务中需要单独放大的特征一般称为需要注意力集中的特征
附加预测性辅助任务的多任务学习
-
辅助任务:离线过程中搜集与主任务相关的未知特征,也称为预测性任务
-
在线过程中为主任务提供额外信息,帮助主任务学习更合理的归纳表示
多任务学习算法
多任务学习的定义
-
给定
M
M
M
个任务
{
T
m
}
m
=
1
M
\{
{T_m}\}_{m=1}^M
{
T
m
}
m
=
1
M
-
第
m
m
m
个任务为
T
m
T_m
T
m
其训练集为
D
m
D_m
D
m
包含
n
m
n_m
n
m
个样本-标签对
{
x
m
,
j
,
y
m
,
j
}
j
=
1
n
m
\{
{x_{m,j},y_{m,j}}\}_{j=1}^{n_m}
{
x
m
,
j
,
y
m
,
j
}
j
=
1
n
m
,
x
m
,
j
∈
R
D
,
y
m
,
j
∈
R
x_{m,j}\in{R^D},y_{m,j}\in{R}
x
m
,
j
∈
R
D
,
y
m
,
j
∈
R
-
W
∈
R
D
×
M
W\in{R^{D×M}}
W
∈
R
D
×
M
表示权值矩阵,即多任务模型参数矩阵
-
ε
m
\varepsilon_m
ε
m
表示任务下的噪声
-
则有线性模型:
y
m
,
j
=
w
m
T
x
m
,
j
+
ε
m
y_{m,j}=w_m^T{x_{m,j}}+\varepsilon_m
y
m
,
j
=
w
m
T
x
m
,
j
+
ε
m
-
多数MTL算法的关键假设
:
所有任务都通过某种结构相互关联,多任务中任务信息共享是通过特征的联系实现的;
一般来说,多任务选取的特征属性都是相似的,而各个任务之间特征的重要性通过模型向量
w
m
w_m
w
m
反映;
在模型向量中所占比重相似,才能说明任务特征之间具有迁移性。
-
MTL的目的
:
通过学习
W
W
W
的不同结构来反映任务之间的关系
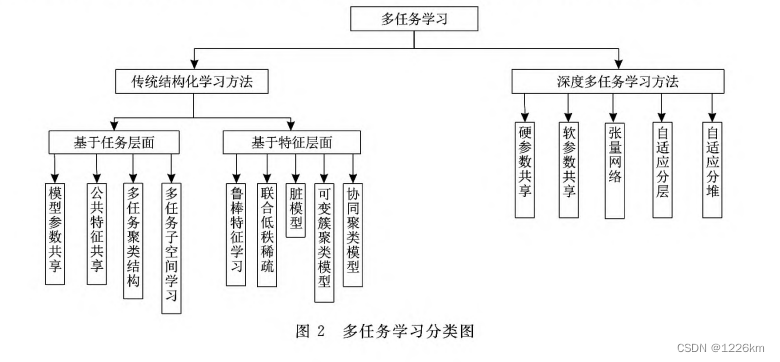
多任务算法的分类
学习模式不同
-
传统的结构化学习
不利用抽象后的特征,最终以结构约束的形式体现任务联系
-
深度多任务学习
改变特征的表现形式
学习结构不同
-
基于任务层面
将大部分特征视为彼此相关,且任务相关性是全局的
注重总体特征的共享迁移,一般同时考虑多个特征
-
基于特征层面
单独对各个任务中的特征进行建模
注重个体特征的共享迁移