SQL 调优:对于记忆力比较强的人可以背以下内容:
MySQL性能优化21个最佳实践,一个一个分解给你看,还怕搞不定?_普通网友的博客-CSDN博客
更优雅的回答:
注意使用总分的表达方式:
我一般在进行sql优化的时候会从数据库的设计开始考虑比我我们在创建数据库的时候,我会尽量的选择最佳匹配的字段,例如,很多同学进行整形的字段设计的时候,一般都是用int,这其实会造成空间的浪费,我会根据具体的业务情况选择tinyint,smallint类型,也就是说在优化从数据的设计时候就开始了,当前这个只是前期的预防,更多的情况是在项目上线或者测试的时候发生的,那么我会从索引的优化,sql语句的优化,参数的调整,连接资源的监控等各个维度进行优化,比如之前我的XXXX项目中的xxxx表,数据量不大,只有几十万,但是依然很慢,通过执行计划发现有一个index intersect的描述,我怀疑是索引合并导致的查询比较慢,所以调整关闭了此参数,但是返现没有变化,后来又想可能是回表影响了查询,所以我创建了一个组合索引,执行之后发现时间变成了0.006s,快了奖金17倍,完成了此次的优化。---来自连老师的装逼
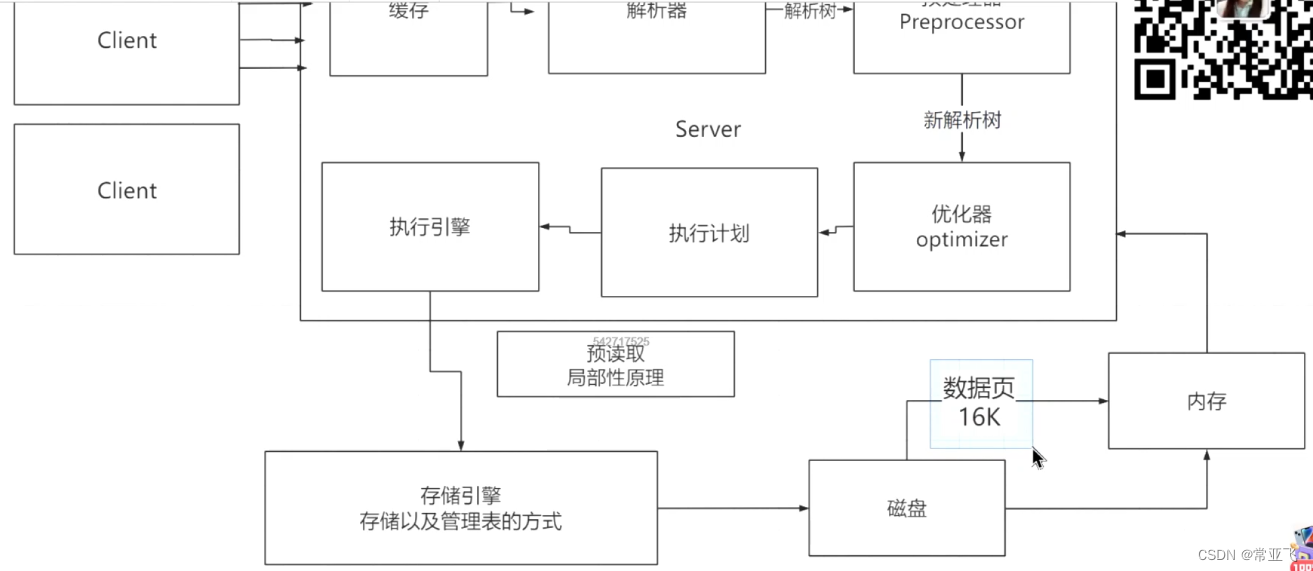
1.Mysql最大连接数默认是151,这个需要调整,生产环境比较复杂,可以简单记为内存/8M个连接数
2. 修改配置
3.作用域:如果mysql不重启,Global作用域作用于所有的会话
4.查询 缓存在mysql5.7中默认关闭,在mysql8.0中缓存彻底消失,查询缓存可以通过:show variables like 'query_cache%'来查看。
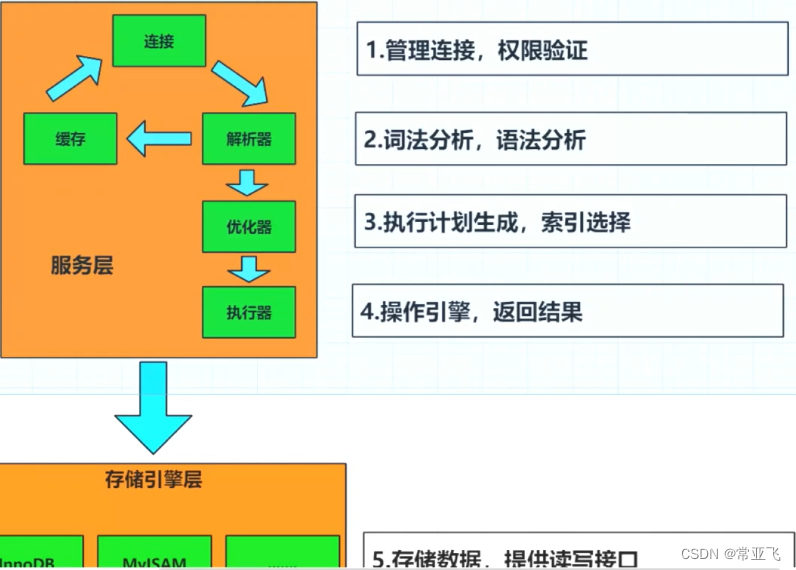
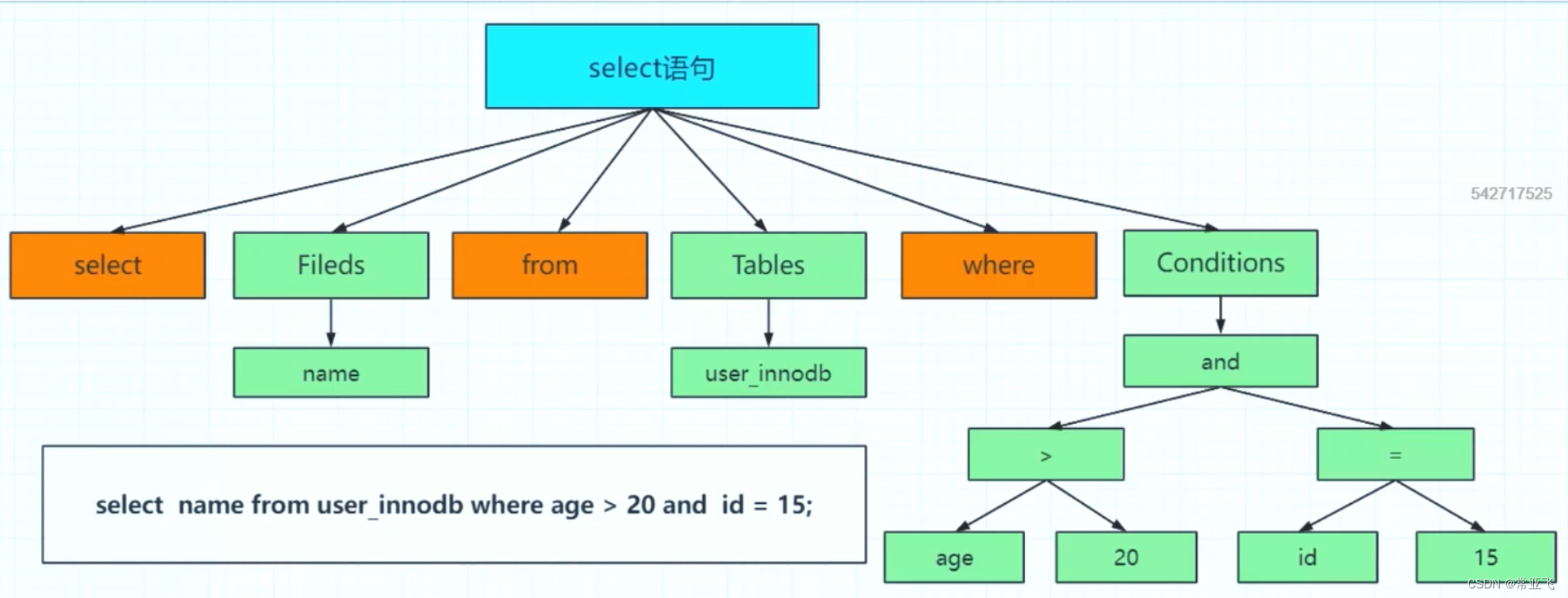
5.解析器的作用包括词法解析和语法解析
此法解析:
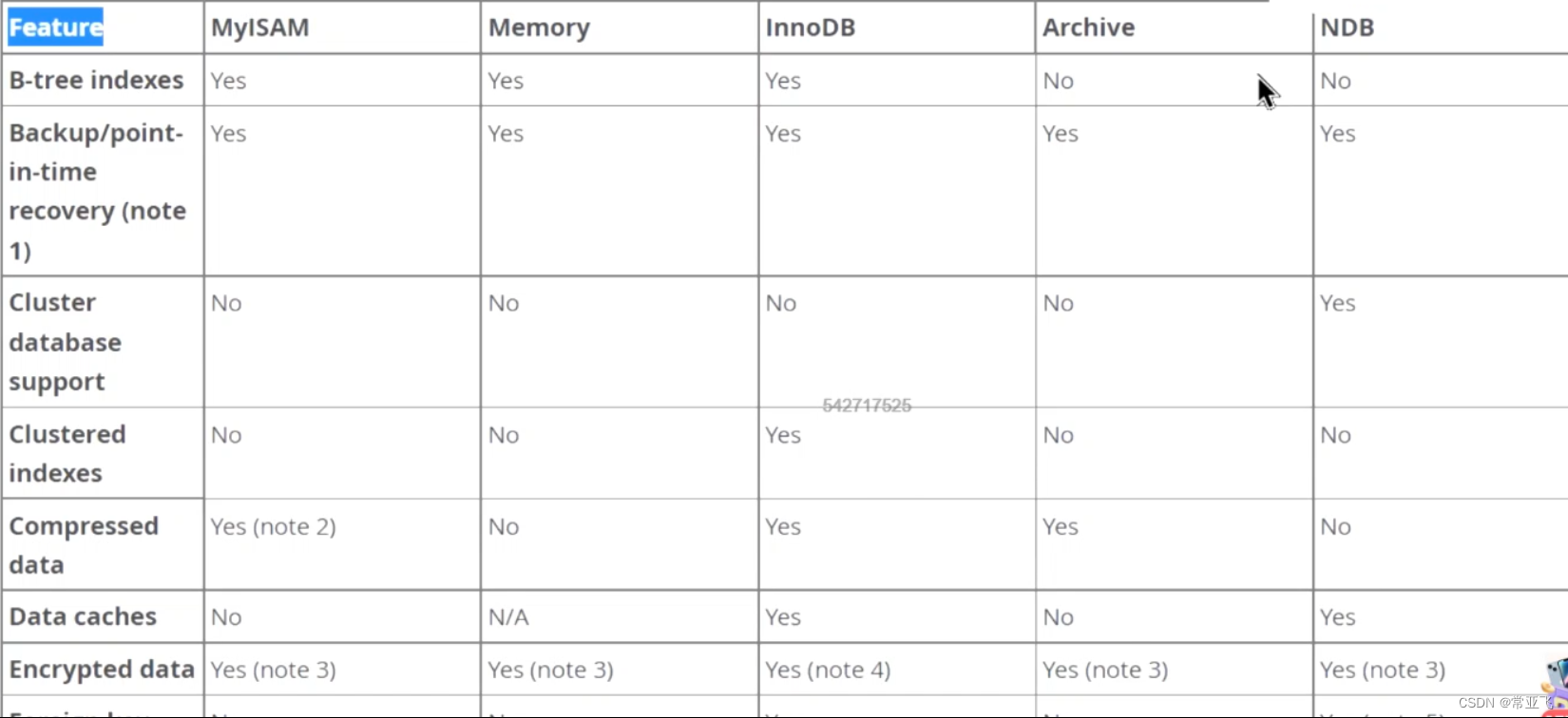
6.存储引擎的选择
5.7之前默认是myisam,5.7之后是Inno DB
InnoDB适合大数据量的读写并发
只有InnoDB和NDB支持事务
各种存储引擎的比较:
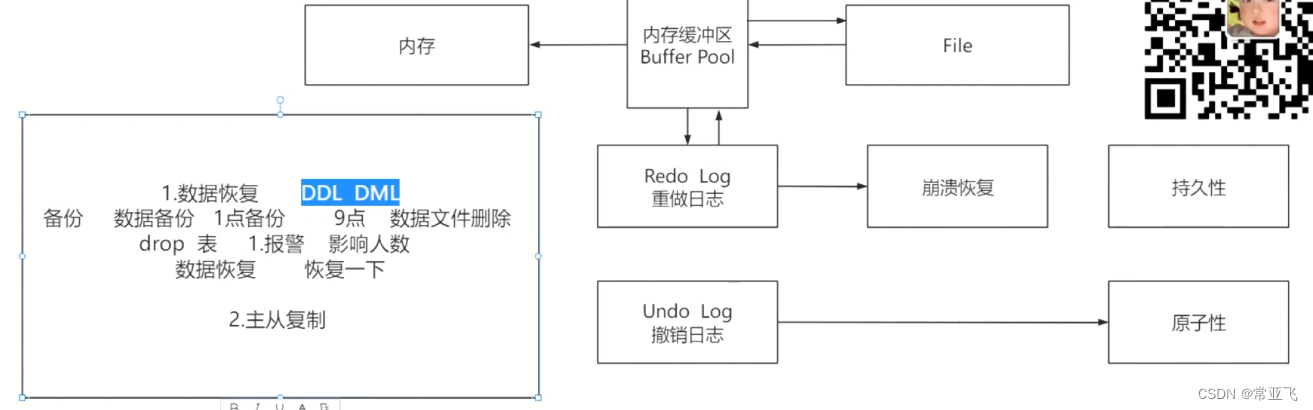
7.多余频繁操作的使用bufferpool缓存
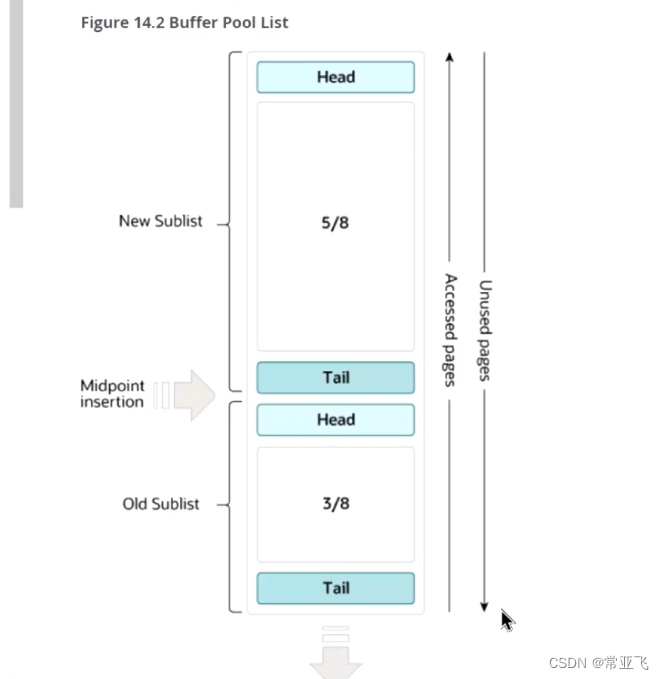
bufferpool能提升读写操作的效率,windows默认的是8M,linux默认128M,满了之后会对数据进行淘汰LRU:
List会进行分区,进入bufferpool之后首先放置在冷区(下面的3/8)的顶部,再次使用的时候放置到热区(上面的5/8),每次淘汰的时候从冷区底部开始淘汰
看当前的状态:
show variables like '%innodb_buffer_pool%'
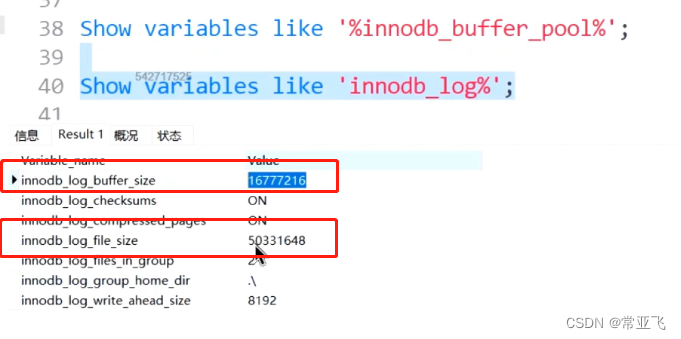
如果调整了bufferpool的大小,则日志大小也需要调整
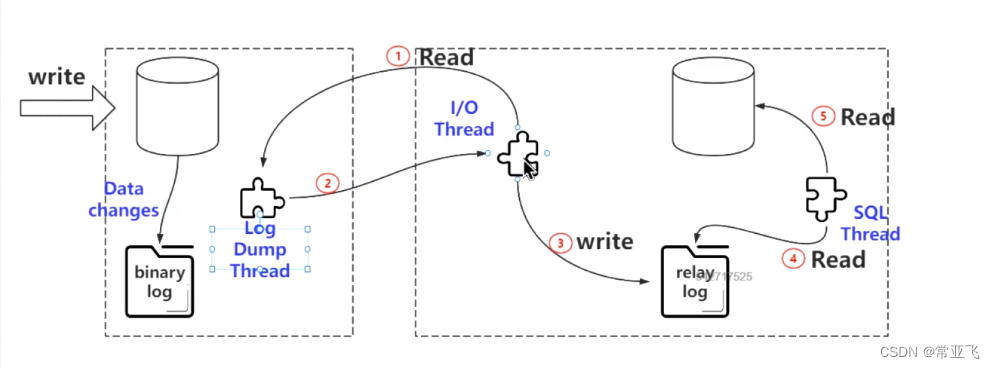
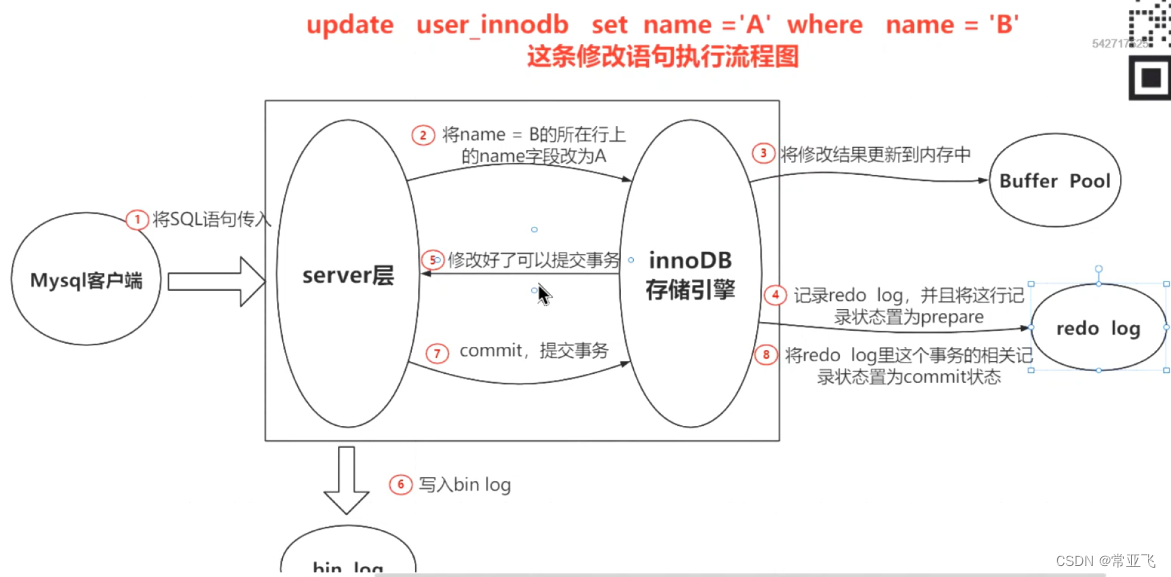
主从复制的过程

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)