ColorMapGAN: Unsupervised Domain Adaptation for Semantic Segmentation Using Color Mapping Generative Adversarial Networks ColorMapGAN:基于颜色映射生成对抗网络的无监督域适应语义分割
- 0.摘要
- 1.概述
- 2.相关工作
- 2.1.计算机视觉
- 2.2.遥感
- 2.3.对抗生成神经网络
- 2.4.我们的贡献
- 3.方法
- 3.1.整体架构
- 3.2.ColorMapGAN
- 3.2.1.生成器
- 3.2.2.Discriminator
- 4.实验
- 4.1.对比方法
- 4.2.实验设置
- 4.3.训练细节
- 4.4.结果
- 4.5.训练时间
- 5.结论
- 参考文献
0.摘要
由于大气影响、采集方式差异等多种原因,从不同地理位置采集的卫星图像往往存在较大的光谱波段差异。训练数据和测试数据的光谱分布之间的巨大变化导致目前最先进的监督学习方法输出的地图不令人满意。我们提出了一个新的语义分割框架,该框架的关键组成部分是颜色映射生成对抗网络(ColorMapGANs),它可以生成语义上与训练图像完全相同的虚假训练图像,但其光谱分布类似于测试图像的分布。然后,我们使用伪图像和训练后的真实图像来微调已经训练过的分类器。与现有的生成对抗网络(GANs)相反,ColorMapGAN中的生成器没有任何卷积层或池化层。它学习将训练数据的颜色转换为测试数据的颜色,只需要执行一次元素矩阵乘法和一次矩阵加法操作。由于ColorMapGAN的架构简单但功能强大的设计,所提出的框架在准确性和计算复杂性方面都比现有的方法有很大的优势。
1.概述

图1。领域适应问题的说明,其中我们描述了训练和测试图像,测试图像的基本真相,以及U-net预测的地图。在地面真相和预测地图中,红色、绿色和白色像素分别对应于建筑、树木和道路类别。(a) 训练形象。(b) 测试图像。(c) (b)的基本事实。(d) (b)的预测图。
随着卫星传感器技术的不断发展和完善,新一代卫星任务层出不穷,使得收集海量数据成为可能。大量的卫星数据给遥感界带来了新的挑战。语义分割或密集标注是指为图像中的每个像素指定一个主题标签。毫无疑问,在遥感界今天面临的挑战中,密集标记卫星图像是最重要的挑战之一,因为解决这一问题的好办法对生成和自动更新地图至关重要。
近年来,卷积神经网络(cnn)已成为最常用的语义分割工具。特别是U-net[1]及其变体[2]-[4]因其在医学成像和遥感等不同领域取得的巨大成功而受到越来越多的关注。上述cnn的主要局限性是对训练数据的极度敏感性。虽然当训练数据和测试数据来自相同的分布[5]时,它们的性能都很好,但当训练图像和测试图像的光谱波段存在较大差异时,它们的性能会严重下降。考虑到如今新一代的卫星以较短的重访时间从世界各地获取了大量图像,人们不能假设图像的分布总是相似的。此外,根据收集数据的时间和地点的不同,遥感图像可能会遇到很大的内部变化。例如,由于光照的不同,同一物体的颜色分布在一天中不同时间拍摄的图像中可能会有很大的差异。同样,由于大气的影响,在某些情况下,即使是由相同的卫星传感器收集的图像也可能具有非常不同的辐射计量,这使得分割任务更加困难。图1就是这样一个例子,同一颗卫星收集的训练数据和测试数据的颜色分布明显不同。如图1所示,即使是训练有素的U-net,被认为是目前对卫星图像[6]进行语义分割的最先进技术,其生成的地图也很差。
无监督域适应假设测试数据的任何部分都没有注释,目的是生成高质量的分割,即使在训练图像和测试图像之间存在较大的域转移。在这样的设置下,为了增加cnn的泛化能力,最简单也是最常用的方法之一就是应用各种数据增强技术使训练数据多样化,例如gamma校正和[7],[8]等。然而,尽管这些技术可以帮助cnn更好地进行归纳,但当训练数据和测试数据之间的光谱差异巨大时,这种改进通常是不够的。虽然领域自适应的良好解决方案对于各种应用都是必不可少的,但这一问题在遥感领域还没有得到深入研究。本节中指出的局限性促使我们为这个问题设计一种方法
2.相关工作
在本节中,我们总结了计算机视觉和遥感领域中现有的领域自适应方法
2.1.计算机视觉
文献中提出的大多数方法都是基于使用生成对抗网络(GANs)[9] -[11]对从训练数据和测试数据中提取的特征分布进行对齐。分布比对也可以在网络的多个层中进行,而不仅仅是最终输出[12]、[13]。Hong等人[14]对训练图像加入随机噪声。他们观察到,干扰训练图像有助于GAN更好地适应测试数据。Saito等人[15]引入了一种基于最大分类器差异的方法,该方法通过使用特定类的决策边界来校准分布。Zhang等人[16]提出的框架利用谷歌Street View收集未标注的图像并利用其特征。课程域适应(CDA)在全局和生成的超像素上执行对齐。现实导向适应(ROAD)[17]包含两个损失函数。第一种方法将训练图像中的训练模型的权值与ImageNet[18]中预训练模型的权值尽可能相似。第二种是通过将训练图像和测试图像划分为网格,最小化训练图像和测试图像之间的距离来处理空间感知域适应。
已经有人尝试通过规格化或规格化网络的特定层或通过自学习来解决领域适应问题。fully convolutional tribranch network (FCTN)[19]是属于自学习范畴的方法之一。所提出的网络结构由一个编码器和三个解码器组成。两个解码器对测试图像进行伪标记;另一种是对伪标签和测试图像进行学习。在类别平衡自训练(CBST)[20]中,提出了一种类别平衡自学习方法。引入新的归一化方法,正则化技术,或新的损失函数,专门针对领域适应问题的[21]-[24]进行了研究。Romijnders等[21]讨论了批处理归一化等传统归一化方法的局限性,提出了一种新的更适合域适应的域无关归一化层。Saito等人[22]引入了一种新的对抗性退出正则化技术。IBN - batch Normalization (instance - batch Normalization)-Net[23]将批处理规范化与实例规范化[25]相结合,提高了泛化能力。Zhu等人[24]提出了一种新的保守亏损
解决无监督域适应问题的另一种方法是在源域和目标域之间执行图像到图像的转换(I2I)。文献中现有的I2I方法可以执行一对一的[26]、[27]或多对多的[28]、[29]翻译。如果能够生成风格上与测试图像一致、语义上与原始训练图像一致的假训练图像,那么就可以使用这些假图像从头开始训练模型,或者根据原始数据对已经训练过的模型进行微调。这里主要的缺点是,通常由I2I方法生成的假训练图像包含了原始图像中不存在的人造物体和伪影。因此,原始训练图像与生成的伪训练图像的标注不匹配。因此,模型学习了错误的信息。为了克服这一限制,循环一致对抗域适应(CyCADA)[30]使用基于原始训练数据的分类器对原始和伪训练图像进行分割,并最小化分割之间的交叉熵损失。但是,如果训练数据和测试数据之间的域转移较大,从原始训练图像训练的分类器将很难分割出伪训练图像。如果训练图像的分割非常好,但是假训练图像的预测地图非常嘈杂,我们不能指望增加这样的损失来阻止人造物体的出现。另一种丰富训练数据的方法是进行神经风格转移,将一幅图像的内容和另一幅图像的风格结合起来[31]-[34]。然而,它们也不能保证语义结构会被保留。
2.2.遥感
Tuia et al.[35]在综述文章中详细阐述了,遥感领域中的领域适应方法可以分为四类:不变量特征的选择、分类器的适应、主动学习和数据分布的适应。第一类方法的主要目标是从训练数据中找到一个特征子集,它是测试数据的代表。例如,Bruzzone和Persello[36]提出了一种方法,通过定义一个新的标准函数来量化这两个任务,旨在选择既对测试数据是不变的,又对感兴趣的类是有区别的特征。Persello和Bruzzone[37]描述了一种通过基于内核的方法解决相同选择问题的方法
为了适应分类器的测试数据,现有的方法通常要么选择采用无标号的分类器测试数据直接或支持一个主动学习的方法,在注释器标签少量代表性样本的测试数据已经更新训练分类器。Bruzzone和Prieto[38]描述了一种方法,通过期望最大化(EM)算法更新未标记测试数据上先前训练的分类器的参数。然后,这种方法被扩展到另一个框架,在该框架中执行级联分类操作[39]。在[40]中,使用了多个级联分类器。Bruzzone和Marconcini[41]提出了域适应支持向量机(DASVM)。如果采用主动学习的方式来调整分类器,我们显然可以期望得到更好的结果,因为我们提供了部分测试数据来修改分类器。另一方面,样品的选择和手工标记可能会太贵。在Persello和Bruzzone[42]提出的方法中,分类器从测试数据中迭代学习少量新添加的样本,并去除一些分布与测试数据分布不匹配的训练样本。Matasci等人[43]提出的基于支持向量机(SVM)的方法也采用了类似的方法。另一种基于核的主动学习方法由Deng等人[44]提出。在[45]中研究了神经网络在主动学习中的应用。
对数据分布进行调整是一种常用的方法。为此,可以将训练数据和测试数据的分布对齐到一个公共空间中,或者将训练数据的分布与测试数据的分布对齐。在这两种情况下,我们期望从对齐的训练数据训练的模型产生更好的分割。上述比对可通过直方图匹配[46]、[47]、图匹配[48]、核主成分分析(KPCA)[49]、颜色一致性算法[50]或通过最大均值差异(MMD)[52]最小化训练数据与测试数据[51]之间的统计距离来进行。Ma等[53]通过质心和协方差对齐校正了每个类的训练数据和测试数据之间的域转移。Gross等人[54]提出了一种非线性特征归一化的对齐方法。在[55]中提出了一种新的张量对齐方法。如果域适应问题源于大气条件或采集过程中的差异,可以通过在预处理步骤中进行辐射校正[56]、[57]来纠正域移位。最近,Courty等人[58],[59]使用最优传输进行域适应。在[60]中研究了遥感数据域自适应的最优传输问题。此外,在GANs在计算机视觉领域得到广泛应用后,也有一些文章对其在遥感中的应用进行了研究。例如,Benjdira等人[61]使用CycleGAN[26]生成与测试数据相似的假训练数据。然后,用生成的假训练数据调整原始训练数据中已经训练过的模型。然而,与计算机视觉基准不同,遥感图像包含许多异构和复杂的结构。因此,由CycleGAN生成的假遥感图像的质量往往达不到预期的水平。
2.3.对抗生成神经网络
在机器学习中,我们可以将在监督环境下训练的模型分成两组:判别模型和生成模型。在图像分析领域,判别模型通常训练学习映射从高维输入到类标签的图像分类和分割问题。另一方面,生成模型的目的是估计数据样本的分布,以便从估计中提取新的样本。Goodfellow等[64]提出了GANs,这是一种训练生成模型的新方法。
GANs通常包括生成模型G和判别模型d。判别模型G的目标是估计真实数据的分布,并从估计中输出假数据。G以随机噪声z为输入,表示到数据空间G(z)的映射。我们用p(x)表示真实数据x的分布,用p(z)表示输入噪声变量的先验。假设真实数据x和虚假数据G(z)分别用1和0表示。D输出一个介于0和1之间的标量,目的是最大化正确标记x和G(z)的概率。换句话说,D的目标是区分真实数据和虚假数据。训练中最大的D的目标函数描述为
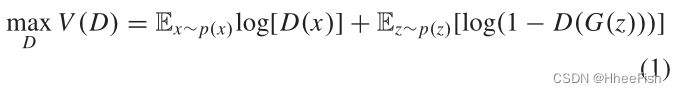
其中E为期望值。同时训练G使定义的目标函数最小化
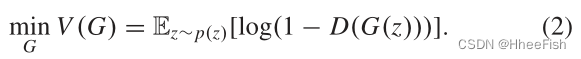
因此,G和D之间的极大极小对策可以表示为
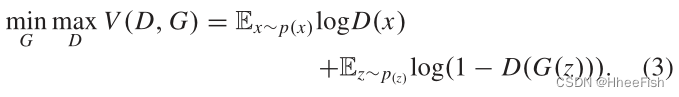
一旦D和G同时接受足够长的时间的训练,D就能很好地辨别真伪数据,G就能更好地生成与真实数据难以区分的虚假数据。
虽然GAN在浅多层感知器上工作良好,但当使用更复杂的网络时,它们在训练过程中会遇到不稳定问题。已经提出了几种解决不稳定问题的办法。在深度卷积生成对抗网络(deep convolutional generative adversarial networks, DCGAN)[65]中,在G和D中都使用了深度卷积网络来代替多层感知机,并引入了一定的架构约束来提高训练的稳定性。在WGAN[66]中,不是使用(3)中的对数,而是使用Wasserstein距离来计算分布之间的距离,并在训练阶段使用梯度裁剪。具有梯度惩罚的Wasserstein生成式对抗网络(WGAN- gp)[67]是WGAN的扩展,其中使用梯度惩罚来解决梯度裁剪的局限性。最小二乘生成式对抗网络(Least squares generative adversarial networks, LSGAN)[68]证明了在(3)中采用最小二乘损失函数可以使训练更加稳定。
最后,原始的GANs在[69]中被扩展到条件GANs,其中G和D不是由噪声z生成假数据,而是以一些额外的信息y为条件。y可以是类标签或来自其他模态的数据。在这个体系结构中,G学习了z和y的组合到数据空间的映射。假设y为源数据,x为目标数据,G的目的是学习从源域到目标域的映射。受这个想法的启发,条件gan已经被用于几个I2I工作[26],[62]。
2.4.我们的贡献
我们研究了用于语义分割的无监督域适应问题,其中训练图像和测试图像来自完全不同的地理位置,它们有显著的光谱分布差异,且测试图像的任何部分都没有标注。我们处理问题的方法类似于I2I方法;我们生成假的训练图像,就好像它们来自于测试图像的分布。如果我们将训练图像和测试图像(例如,从完全相同的地理区域但在不同的白天获得的图像)配对,而不是处理在不同地理区域获取的图像,那么问题就会更简单,我们可以进行配对I2I[62]。
这里的主要挑战是生成看起来像测试图像的假训练图像,同时保持它们与真实的训练图像在语义上一致,即使训练图像和测试图像没有配对。如果在伪训练图像中保留了原始训练图像的语义结构,我们可以利用真实训练图像和伪训练图像的注释,从原始训练数据中对已经训练的模型进行微调。在生成测试图像样式的伪训练图像时,I-A节中介绍的大多数I2I方法都不能保持原始训练图像的准确结构,尤其是在处理含有大量复杂、异构对象的卫星图像时。因此,虚假的训练图像与标注不匹配,导致模型学习到错误的信息。
这项工作的贡献如下:
- 颜色映射生成对抗网络(ColorMapGAN):我们的主要贡献是新的ColorMapGAN,它可以生成与原始训练图像在语义上完全相同的假训练图像(例如,物体的位置和形状,如道路、建筑和树木,与原始训练图像完全相同),且在视觉上与测试图像难以区分(即模拟训练图像中的物体,如树木和建筑物,测试图像具有相似的光谱分布)。为此,ColorMapGAN将训练图像的颜色转换为测试图像的颜色,而不对训练图像中的对象进行任何结构上的改变。
- 更高的准确性:在我们的实验中,我们执行城市到城市域的适应。我们利用由我们的方法生成的假训练图像和CycleGAN[26]、无监督图像到图像翻译网络(UNIT)[27]、多模态无监督图像到图像翻译(MUNIT)[28]、通过解纠缠表示(DRIT)的不同图像到图像翻译([29])、直方图匹配[47]、以及灰度世界算法[63],从原始训练图像微调训练的模型。我们还将我们的方法与AdaptSegNet[12]进行了比较,后者旨在使分类器直接适应测试数据。尽管它的架构设计简单,我们的框架使我们能够生成比其他更高精度的预测地图
- 低复杂度:与文献中现有的GANs不同,我们的生成器不执行任何卷积或池化操作。它转换训练图像的颜色只有一个元素矩阵乘法和一个矩阵加法。由于我们的生成器在架构上大大简化了现有的gan, ColorMapGAN的训练时间明显低于其他基于学习的方法。在我们的实验中,我们将我们的方法与CycleGAN[26]、UNIT[27]、MUNIT[28]、DRIT[29]、直方图匹配[47]和灰色世界算法[63]在运行时间方面进行了比较。
3.方法
3.1.整体架构
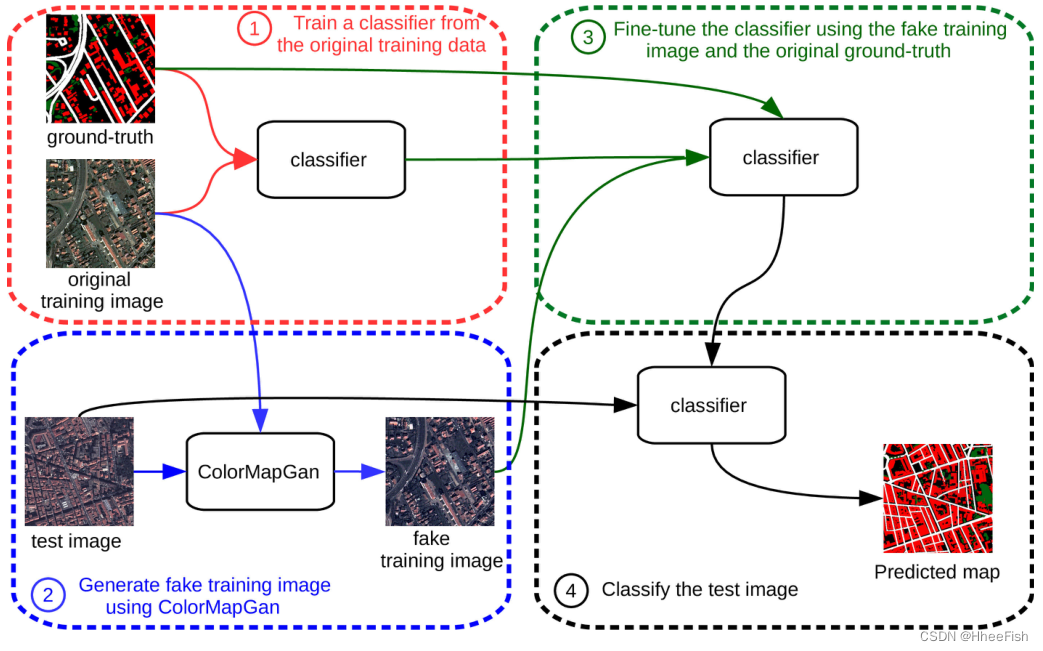
图2描绘了由四个步骤组成的总体框架 :
- 训练初始分类器:我们在原始训练数据上训练一个Unet。
- ColorMapGAN:我们生成的假训练图像在语义上与原始训练图像完全相同,但在视觉上与使用所提出的ColorMapGAN的测试图像尽可能相似。
- 微调:我们使用假训练图像和原始训练图像的地面真值微调步骤1中获得的模型。
- 分类:最后,我们对测试图像进行分类。
我们使用U-net[1]的一个稍加修改的版本作为分类器。我们将整流线性激活单元(RELU)替换为泄漏整流线性激活单元(泄漏RELU),以获得更好的性能[70]。我们还删除了每一层中的批处理规范化操作,因为它没有有效地使用内存。在该框架中,步骤1、3和4是自解释的,而步骤2需要进一步解释。
3.2.ColorMapGAN
3.2.1.生成器
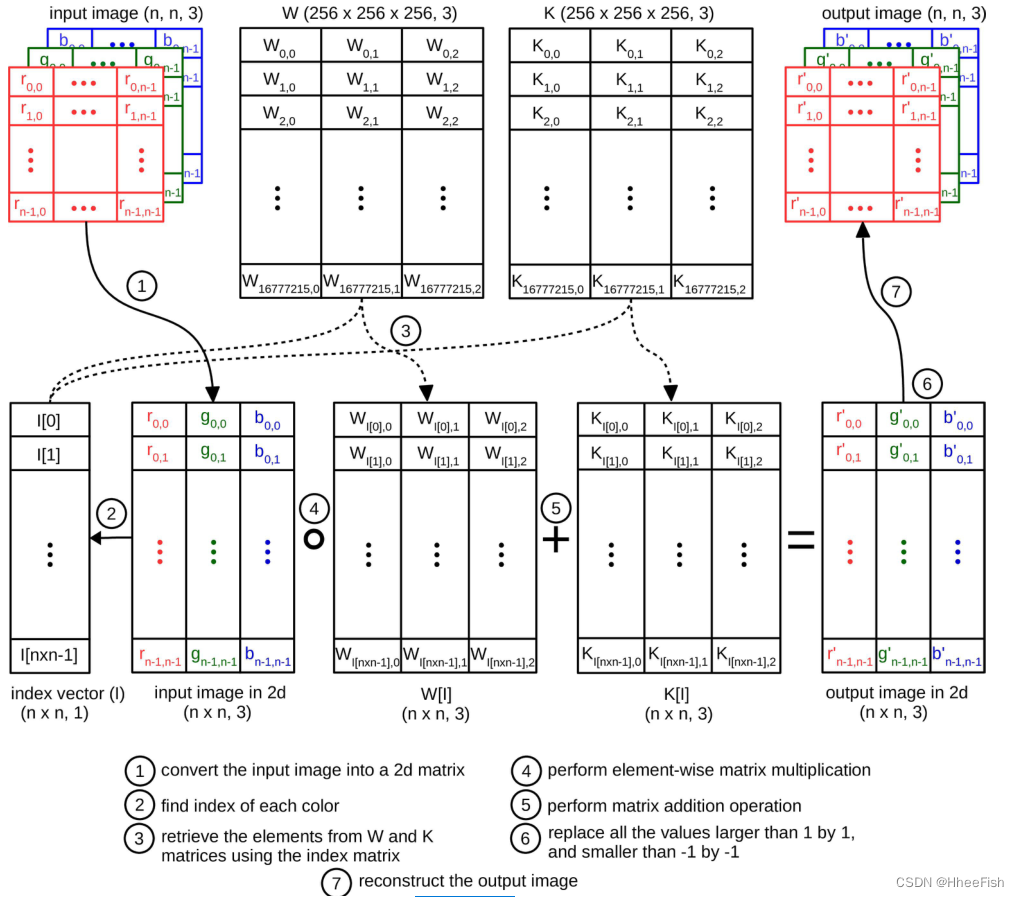
图3。生成器前馈通路的总体流程图。
提议的ColorMapGAN的新颖之处在于其生成器的架构简单但功能强大。
我们用X={x1,x2,…,xN}表示一组训练图像Patch,用Y={y1,y2,…,yM}表示一组测试图像Patch。G(X)对应于G生成的一组假训练补丁。G的目标是生成G(X),其光谱分布尽可能类似于Y的分布,同时保持G(X)和X在语义上完全相同。与文献中现有的GANs相反,我们没有在G中使用卷积层或池层来保留G(X)中X的确切语义。
假设X和Y由8位图像组成,包括红色、绿色和蓝色通道。我们用R={0,1,…,255},G={0,1,…,255},B={0,1,…,255}表示,以及像素的每个色带可以取的值。我们用RGB表示所有可能的16777216(256×256×256)色,RGB定义为
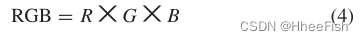
其中x代表笛卡尔积。为了将RGB转换为另一个颜色矩阵R’G’B’,W表示与RGB大小相同的缩放和K表示移位矩阵。RGB可以计算为
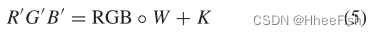
◦ 是逐元素乘积。G的唯一可学习参数是W和K。在训练开始之前,我们用1初始化W,用0初始化K。因此,在第一次迭代结束时,G的输入和输出完全相同。
计算的主要瓶颈(5)是计算复杂性。由于每个RGB、W、和K矩阵都有超过5000万个元素(256×256×256×3)
这里为什么说W、K的大小是(256256256,3)?
最开始,我以为,W、K的作用对象是一幅图,也就是说,W、K的逐元素是乘在图像的每个像素上的,但其实并不是这样的
W、K的逐元素是乘在R、G、B上的,比如说,物体A的颜色在源域的图像上是(255,255,255),而在目标域的图像上是(100,40,10),物体B的颜色在源域的图像上是(0,0,0),而在目标域的图像上是(155,155,20),W、K的作用是将源域上RGB的每个值投射到目标域上,RGB的每一个RGB组合都有对应的W、K,比如源域的(255,255,255),有一个在这个组合下WR=255,KR=255和WG=255,KG=255,而当(255,255,0)时,有一个WR=255,KR=255。这两个W和K的值是不一样的,为什么?因为色彩的组合不一样。也就是解释了为什么W、K的大小是(256256256,3)
色彩一共有256×256×256个组合,每个组合有3个缩放系数和平移系数,分别是R、G、B分量的缩放系数和平移系数
因此在GPU上执行(5)中定义的操作是不可行的。然而,训练图像Patch中的颜色数量远低于所有可能颜色的数量。因此,只更新W和K元素就足够了,它们可以变换训练Patch中可用的颜色。为此,我们使用一个索引向量I,它被定义为
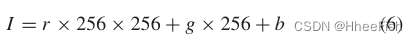
其中r、g、b是训练补丁中所有像素的红、绿和蓝值。找到I的元素后,我们对每个xi∈X和yj∈Y进行归一化并居中,首先除以127.5,然后减去1,使每个颜色通道的范围在−1到1之间。然后我们部分更新R’G’B’作为
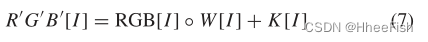
其中[·]运算对应于检索由给定向量索引的任意二维矩阵的行。然后,在R’G’ B’[I]时,我们用1替换大于1,用-1替换小于-1的元素。为了把R’G’B’[I]的所有值映射到0到255之间,使用定义的去正规化函数DN
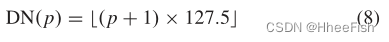
其中p是一个二维输入矩阵。将DN(R’G’B’[I])重构为输入patch的形状,得到G的最终输出。在每次训练迭代中,我们只更新W[I]和K[I]。
3.2.2.Discriminator
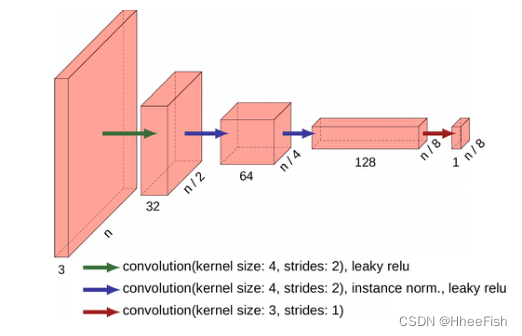
图4。鉴别器的结构。n对应于面片大小,每层下面的数字就是深度。
ColorMapGAN中的Discriminator在结构上与CycleGAN[26]的Discriminator相同(如图4所示)。该Discriminator不是对整个图像patch输出单个标量来判断patch的真伪,而是生成一个二维矩阵。矩阵中的每个元素用来局部判断输入patch是真还是假。然后取矩阵中所有元素的平均值,得到最终值。
正如第二节所提到的,GAN存在不稳定性问题;因此,我们提出了其他的目标函数来替代1-3。我们倾向于使用LSGAN[68]中提供的函数。因此,对于D,训练过程中最小化的目标函数为
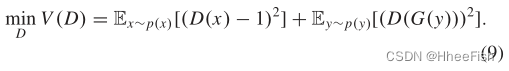
定义G的目标函数为
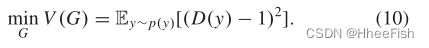
我们通过最小化9和10来同时训练D和G
4.实验

Fig. 5. Example close-ups from the Luxcarta data set. (a) Bad Ischl. (b) Villach. © Béziers. (d) Roanne
4.1.对比方法
- U-net[1]:我们简单地从训练图像训练一个U-net,并分割测试图像,而不执行任何类型的领域适应技术。
- CycleGAN[26]:在该方法中,除了G之外,还有一个generator F, G用来学习从训练图像到测试图像的映射,F用来学习从测试图像到训练图像的映射。该方法要求从训练图像到测试图像的映射和从测试图像到训练图像的连续映射再现原始训练图像。这个约束是通过最小化F(G(X))和X之间的L1范数以及G(F(Y))和Y之间的L1范数来实现的。
- UNIT [27]: UNIT的生成器有两个编码器Ex和y,两个解码器Gx和gy,编码器用于将X和y嵌入到一个公共空间。伪图像由Gx(E y(y))和gy (Fx(X))生成。在一个l变换中,X和Gx(yy (y)), ady和gy (Ex(X))具有相似的统计量。
- MUNIT[28]:将来自两个域的图像分解为内容代码和样式代码。为了生成假图像,将一个域的内容代码和另一个域的样式代码结合起来。AdaIN[71]用于组合。
- DRIT[29]:在方法论上,DRIT与MUNIT几乎相同。惟一的区别是,一个域的内容代码和另一个域的样式代码是通过连接来组合的。
6)直方图匹配[47]:对于每个颜色通道,我们将训练图像的直方图与测试图像的直方图进行匹配,以纠正图像之间的光谱移位。 - Gray W world[63]:是一种颜色恒常性算法[50]。该算法假设图像的平均颜色为自然灰度,任何与灰度的偏差都是由光源引起的。这种假设是用来消除光源的影响。我们使用灰色世界算法对训练和测试数据进行标准化。
- AdaptSegNet Single[12]:旨在训练一个能够很好地分割训练图像和测试图像的域不变网络。为此,分类器从训练图像和测试图像生成预测映射,而鉴别器迫使测试图像的预测映射看起来像训练图像的预测映射。在原文章中使用DeepLab v2[72]作为分类器。然而,该网络中的atrous空间金字塔池(ASPP)显著降低了对卫星图像的分割性能,特别是当图像中含有覆盖面积较小的目标时。因此,我们将ASPP从网络中去除,直接对最终的分类层进行上采样,以获得与训练图像完全相同大小的预测地图。
- AdaptSegNet Multiple[12]:在同一篇文章中,除了对训练图像和测试图像的最终预测进行对齐外,还给出了两个分类层和两个鉴别器的实验结果。我们还将我们的方法与这个策略进行了比较。
为了对ColorMapGAN和CycleGAN、UNIT、MUNIT、DRIT、直方图匹配和灰色世界进行公平的比较,我们用这些算法替换了框架中的第2步。对于灰色世界,我们也修改了第4步。我们对去除光源效应的测试图像进行分割,而不是对原始测试图像进行分割。
4.2.实验设置
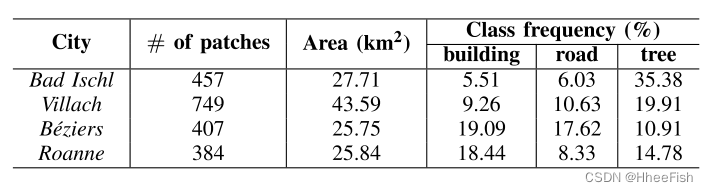
表1 luxcarta数据集的统计数据
为了进行我们的实验,我们使用了Luxcarta数据集,其中包含在欧洲四个城市获取的Pléiades图像:Bad Ischl(奥地利)、Villach(奥地利)、Béziers(法国)和Roanne(法国)。图像被转换为8位,其空间分辨率被数据集提供商降低到1 m。数据集中的图像包含红色、绿色和蓝色通道。提供了用于构建、道路和树类的完整注释。每个城市的特写示例如图5所示。我们把这些城市分成两对,第一对由Bad Ischl和Villach组成,第二对由Béziers和Roanne组成。使实验装置适用于无监督domainadaptation问题,当我们把城市分割成双,我们关注这两座城市的辐射线测定每一对尽可能不同,和属于同一个类的对象(如建筑)也有类似的结构特点。例如Béziers和Roanne的建筑密集,多为矩形,而Bad Ischl和Villach的建筑分布较稀疏,多为方形。然而,如图5所示,每对城市的光谱波段之间存在较大的域转移。我们最后的假设是,我们只能访问培训城市的注释。例如,当我们将Roanne分类为2对时,我们假设它的注释是不可用的;只有Béziers的基本真相是可以了解的。类似地,为了对Béziers进行分类,我们假设只有Roanne的基本事实是可访问的。
在预处理步骤中,我们将每幅卫星图像分割为256 × 256个训练patch,相邻patch之间的重叠像素为32个。表一报告了每个城市的补丁数量、覆盖的总面积和分类频率。对于量化性能评估,我们使用IoU(交集)[73]作为评价指标。
4.3.训练细节
在框架的第一步,我们使用Adam优化器训练一个U-net,其中学习率为0.0001,第一和第二矩估计的指数衰减率分别为0.9和0.999。在每次迭代中,我们随机抽取32个训练patch。我们通过随机水平/垂直翻转和0°/90°/180°/270°旋转应用在线数据增强。我们使用s叉熵作为损失函数,在计算损失时忽略背景类。我们对网络进行了2500次迭代优化。
在生成假训练图像阶段,在ColorMapGAN的每次训练迭代中,我们只从训练城市和测试城市随机采样一个patch。我们使用Adam优化器来更新生成器和鉴别器。由于生成器在架构上比鉴别器简单得多,我们倾向于用更大的学习率来优化它。对于生成器,学习率是0.0005,而我们将识别器的学习率设置为0.0001。我们训练ColorMapGAN进行8000次迭代,因为我们通过视觉检查验证了在这个迭代次数下获得了视觉上吸引人的结果。我们在伪训练图像上微调先前训练的网络,迭代750次。对于所有比较的方法,我们使用相关文章中指定的默认参数。
4.4.结果
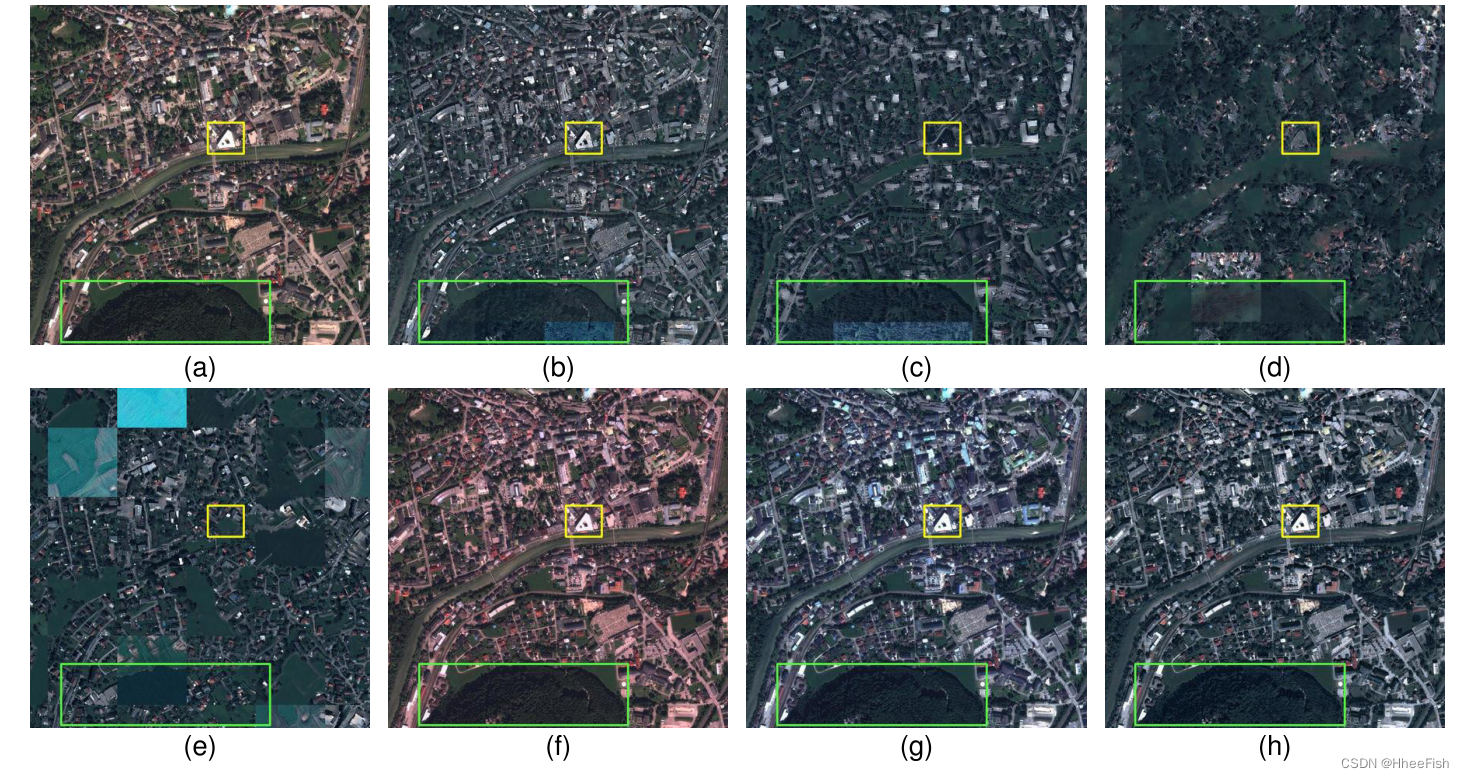
图6所示。原始的Bad Ischl和生成的假图像,用于生成Villach的地图。(一)Bad Ischl。(b) CycleGAN[26]。©UNIT[27]。(d) MUNIT[28]。(e) DRIT[29]。(f)灰色世界[63]。(g)匹配[47]的直方图。(h) ColorMapGAN(我们的)。
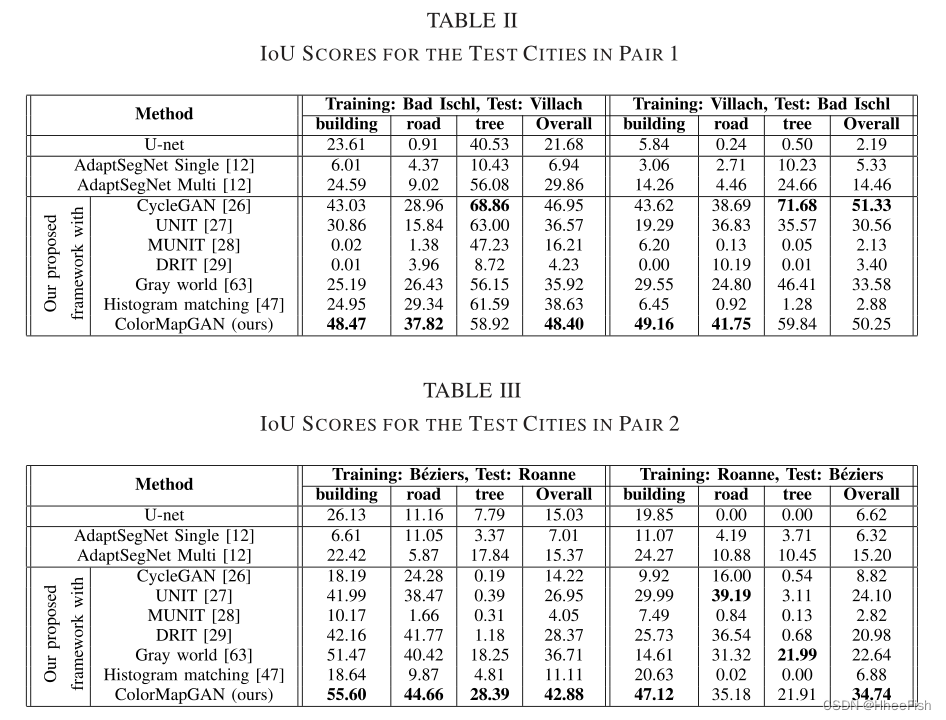

图7所示。原始的Villach和生成的假图像被用来为Bad Ischl生成地图。(一)维拉。(b) CycleGAN[26]。©UNIT[27]。(d) MUNIT[28]。(e) DRIT[29]。(f)灰色世界[63]。(g)匹配[47]的直方图。(h) ColorMapGAN(我们的)。
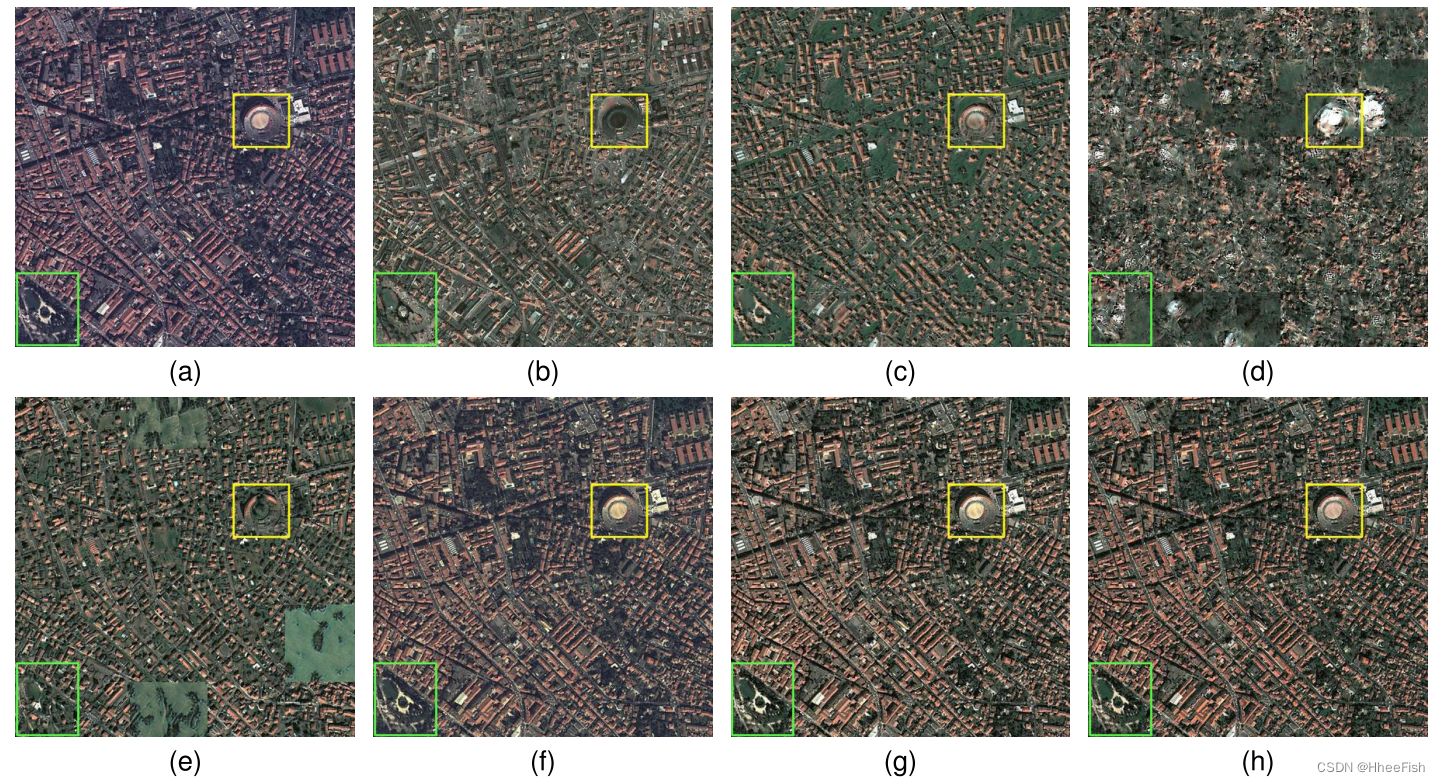
图8所示。原始Béziers和生成的虚假图像,用于生成地图的Roanne。(一)贝济耶。(b) CycleGAN[26]。©UNIT[27]。(d) MUNIT[28]。(e) DRIT[29]。(f)灰色世界[63]。(g)匹配[47]的直方图。(h) ColorMapGAN(我们的)

图9所示。原始Roanne和生成的虚假图像,用于生成地图Béziers。(一)Roanne。(b) CycleGAN[26]。©UNIT[27]。(d) MUNIT[28]。(e) DRIT[29]。(f)灰色世界[63]。(g)匹配[47]的直方图。(h) ColorMapGAN(我们的)。

图10. Villach维拉克的特写和相应的假照片。(一)Villach。(b) CycleGAN[26]。© ColorMapGAN。
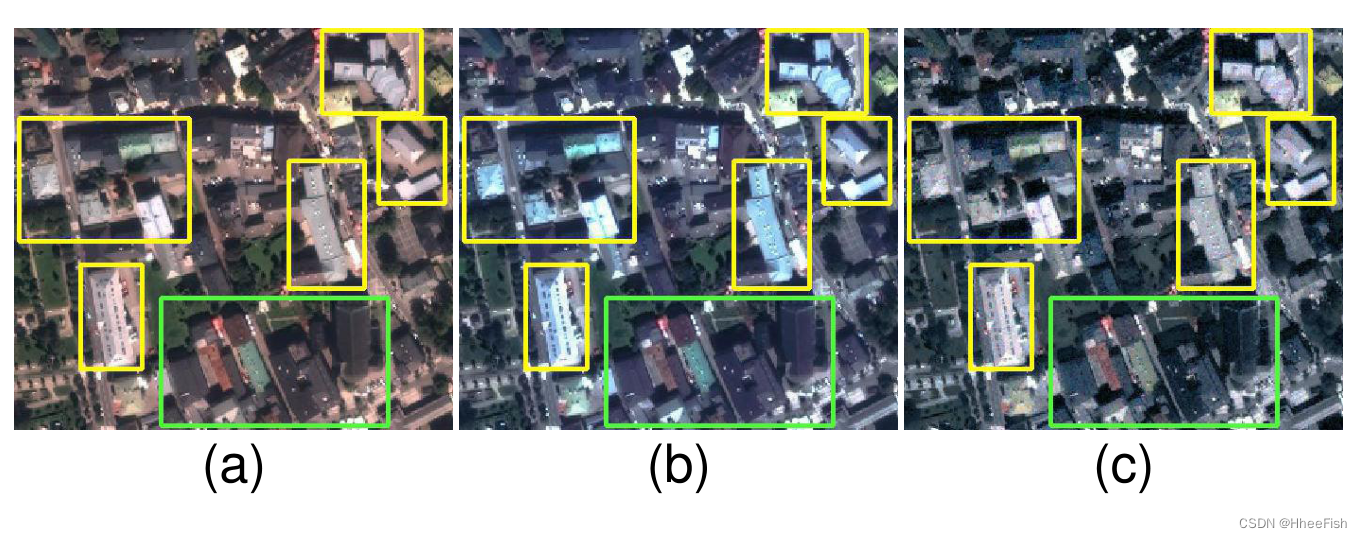
图11所示。Bad Ischl的特写和相应的假图片。(一)Bad Ischl。(b)Hist.mact[47]。© ColorMapGAN。
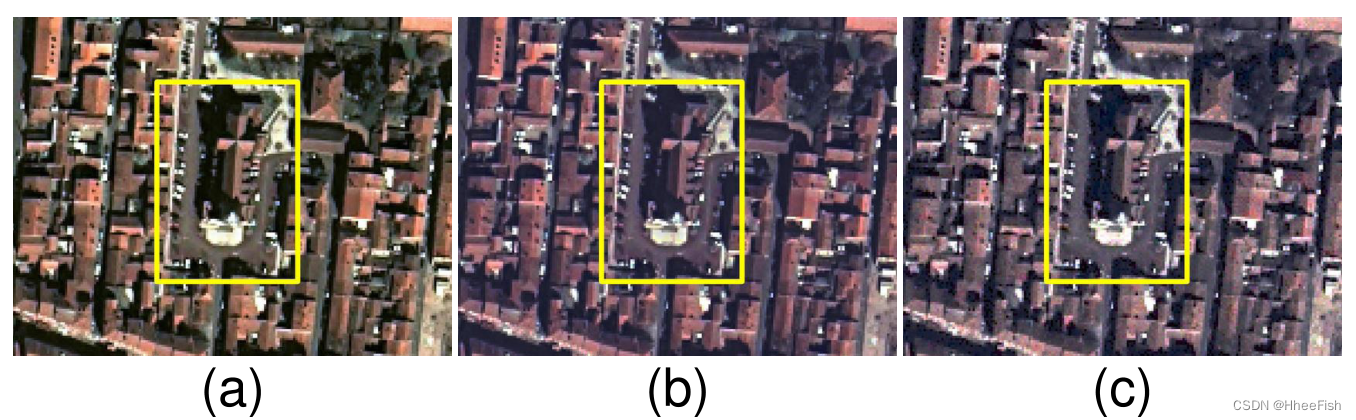
图12所示。罗安的特写和相应的假照片。(一)Bad Ischl。(b)Hist.mact[47]。© ColorMapGAN
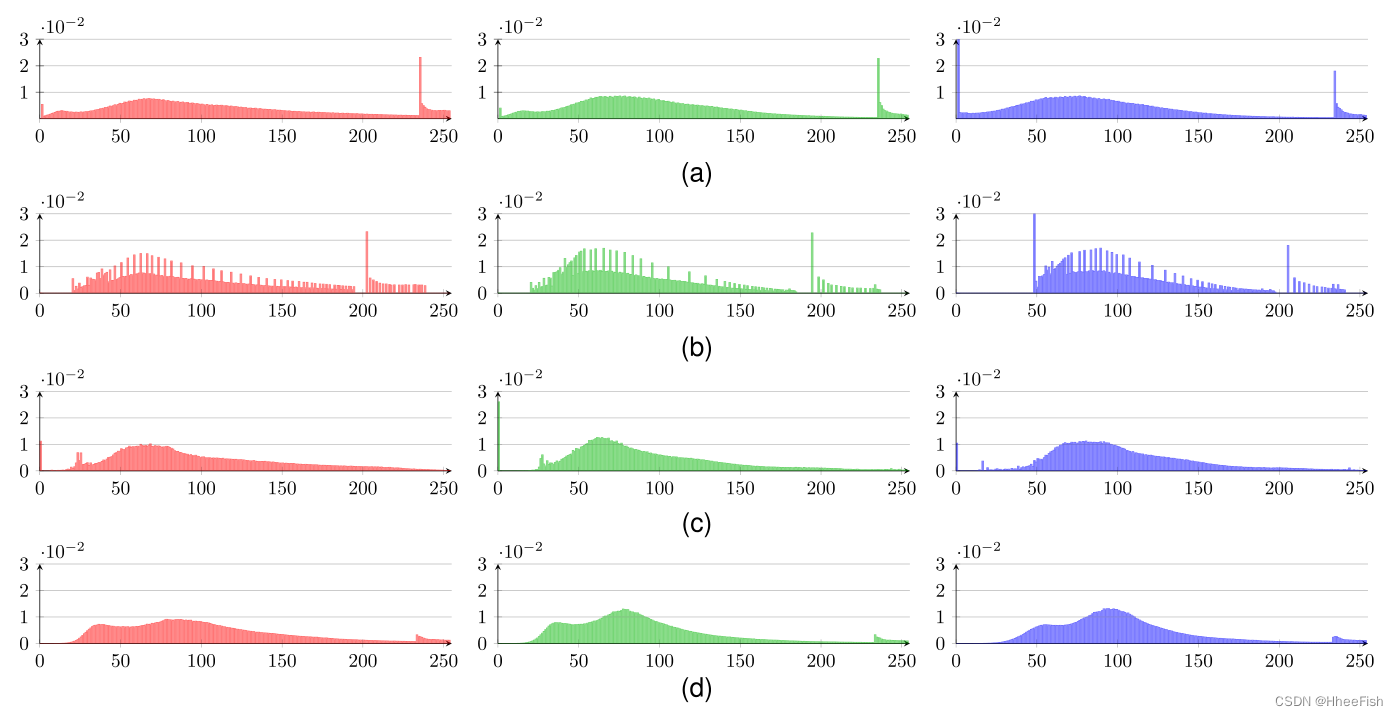
图13所示。建筑物像素的颜色直方图。红色、绿色和蓝色容器分别表示红色、绿色和蓝色通道的直方图。(一)Roanne。(b)直方图匹配生成的伪Roanne。©由ColorMapGAN生成的假Roanne。(d) Béziers

图14所示。Bad Ischl,地面真相和预测。建筑、道路和树类用红色、白色和绿色表示。(一)Ischl不好。(b)地面真理。© U-net[1]。(d) AdaptSegNet Single[12]。(e) AdaptSegNet Multi[12]。我们的框架包含(f) CycleGAN [26], (g) UNIT [27], (h) MUNIT [28], (i) DRIT [29], (j) Gray world [63], (k) Histogram matching [47], (l) ColorMapGAN。

图15所示。维拉克,地面真相和预言。建筑、道路和树类用红色、白色和绿色表示。(一)维拉。(b)地面真理。© U-net[1]。(d) AdaptSegNet Single[12]。(e) AdaptSegNet Multi[12]。我们的框架包含(f) CycleGAN [26], (g) UNIT [27], (h) MUNIT [28], (i) DRIT [29], (j) Gray world [63], (k) Histogram matching [47], (l) ColorMapGAN。

图16所示。Béziers,地面真相和预测。建筑、道路和树类用红色、白色和绿色表示。(一)贝济耶。(b)地面真理。© U-net[1]。(d) AdaptSegNet Single[12]。(e) AdaptSegNet Multi[12]。我们的框架包含(f) CycleGAN [26], (g) UNIT [27], (h) MUNIT [28], (i) DRIT [29], (j) Gray world [63], (k) Histogram matching [47], (l) ColorMapGAN。
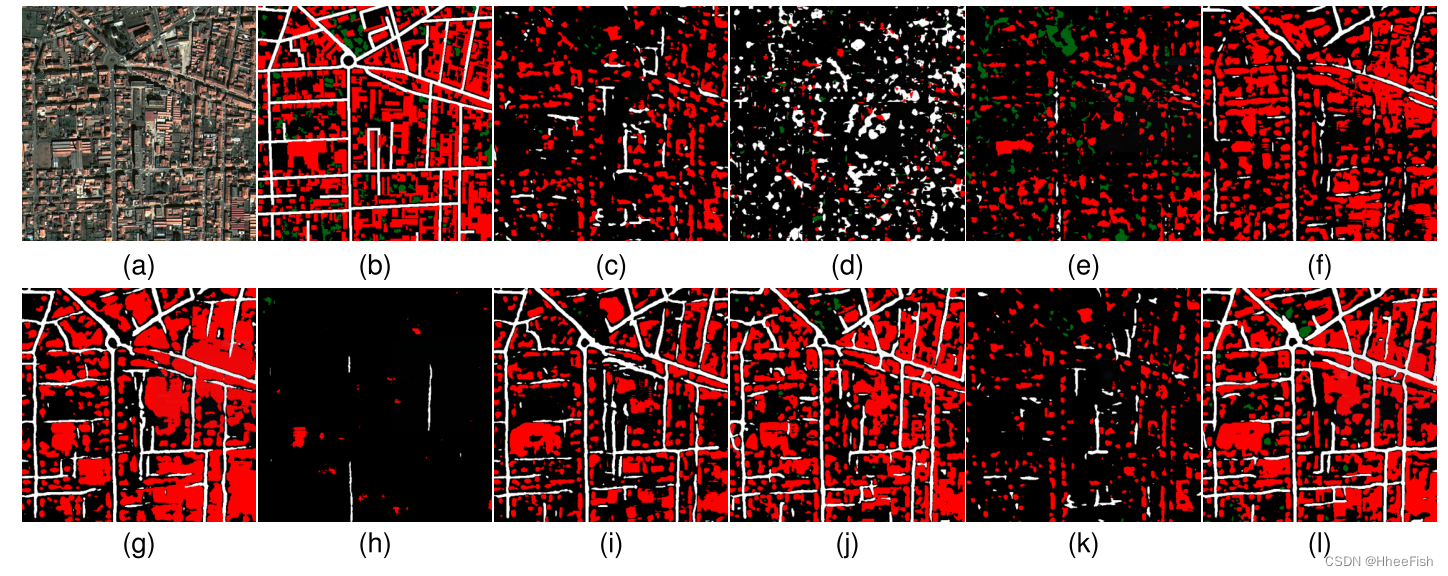
图17。Roanne,地面真相和预言。建筑、道路和树类用红色、白色和绿色表示。(一)Roanne。(b)地面真理。© U-net[1]。(d) AdaptSegNet Single[12]。(e) AdaptSegNet Multi[12]。我们的框架包含(f) CycleGAN [26], (g) UNIT [27], (h) MUNIT [28], (i) DRIT [29], (j) Gray world [63], (k) Histogram matching [47], (l) ColorMapGAN。
表II和表III描述了测试集中每种方法的IoU值。为了提供尽可能可靠的结果,我们在框架中对每个生成假数据的方法重复步骤3 20次,并报告表II和表III中的平均IoU值。重新运行框架的步骤3 20次是可行的,因为我们在这一步中只对分类器进行了750次的微调。然而,AdaptSegNet试图使分类器直接适应测试数据。因此,每次重复实验时,我们都需要从头开始训练分类器。出于这个原因,对于AdaptSegNet Single和Multi,我们只显示了三次运行的平均欠条值。
图6-9展示了部分来自配对的原始训练图像和CycleGAN、UNIT、MUNIT、DRIT、gray world、histogram matching、ColorMapGAN生成的伪训练图像。从图像中我们可以清楚地看到,MUNIT和DRIT完全破坏了图像的语义同一性。例如,原始图像中黄色和绿色矩形表示的结构要么被其他物体取代,要么在假图像中被扭曲。在某些情况下,UNIT似乎产生了更好的结果。例如,UNIT在对2中生成的虚假城市在语义上与原始图像相对一致,在风格上与测试城市相似。另一方面,配对1中的假城市有很多在原城市中不存在的人造物体。对于UNIT, MUNIT, DRIT,由于原始图像的伪图像和地面真实图像通常不匹配,网络在我们框架的第3步学习到了错误的信息。这些方法的另一个问题是,我们在假图像中观察到平铺效应。特别是在伪Villach图像中,patch之间的过渡不是连续的。原因是在生成伪图像时,由于无法将大型卫星图像直接拟合到GPU上,我们需要从每个patch中生成伪数据,并将其合并得到整个伪城市。然而,这些方法大多对相邻补丁产生不相关的输出。因此,如表II和表III所示,采用这些方法提出的框架对测试数据的处理效果较差。
如图6-9所示,利用灰度世界算法对训练图像和测试图像进行标准化,可以减少训练图像和测试图像之间的光谱差异。然而,在每对城市的假图像之间,我们仍然观察到光谱偏移;它没有完全纠正。因此,灰度世界算法的性能基本上优于UNIT、MUNIT和DRIT,但并没有达到预期的效果。
在AdaptSegNet中所使用的网络架构是非常深入的;因此,对于训练和测试图像,仅对最终分类层的输出进行对齐并不能获得良好的性能。但是,如果在多个层中执行对齐,则可以获得更好的性能,特别是当感兴趣的对象覆盖大片区域(如森林)时。例如,Villach的大部分树木都位于森林地区。对于这个城市上的树类,AdaptSegNet multi的IoU值为56.08%,略低于我们的框架的性能。然而,AdaptSegNet在分割小对象(如建筑物)和细对象(如道路)方面的性能并不理想。
乍一看,直方图匹配似乎工作得很好;训练城市的语义结构在模拟训练城市中得到了很好的保存,测试城市的风格完美地转移到了模拟训练城市中。但是,从表二和表三可以明显看出,这种方法的定量结果在大多数时候都很差。此外,CycleGAN和ColorMapGAN在成对1中生成的虚拟城市看起来很相似。然而,使用ColorMapGAN的框架和使用CycleGAN的框架在性能上仍然存在很大的差距。在对Villach进行分段时,对于道路等级,CycleGAN的IoU比ColorMapGAN低9%左右。类似地,ColorMapGAN优于CycleGAN 6%的构建类时分割坏Ischl。另一方面,CycleGAN在树类方面优于ColorMapGAN。为了更好地理解这种性能差异的原因,ColorMapGAN和CycleGAN的比较,以及ColorMapGAN和直方图匹配需要进一步分析。
1) ColorMapGAN VS CycleGAN[26]:首先,值得注意的是CycleGAN的性能不稳定。由于CycleGAN框架的输出与原始图像在语义上不一致,因此该框架在pair 2上的性能不理想。如图中黄色矩形所示。8号和9号,CycleGAN移除了原城市中存在的一些物体。对于建筑类和道路类,它在第1对上的性能比ColorMapGAN差有几个原因。首先,其输出的分辨率低于原始城市的分辨率和ColorMapGAN的输出。图10展示了Villach和图11的特写镜头。由ColorMapGAN和CycleGAN生成的相应假图像。伪图像之间的分辨率差异很容易在青色矩形的轮廓区域中发现。从更模糊的数据中学习显然会降低性能。其次,CycleGAN的输出有一些伪影,如图10中的黄色矩形所示。ColorMapGAN的生成器没有卷积、池和其他操作;因此,我们在ColorMapGAN的输出中没有观察到这种伪影。最后,由于内存限制,我们一块一块地生成假城市,CycleGAN生成的假图像中的一些相邻面片之间存在光谱差异[参见图6(b)中的绿色矩形]。这种差异导致网络表现出较低的性能。ColorMapGAN没有这个问题,因为它将每种颜色映射到另一种颜色。具有相同颜色的像素被映射到另一个完全相同的颜色,而不管其位置如何。因此,相邻的面片在光谱上是一致的,并且它们之间没有平铺效果。ColorMapGAN的一个缺点是,它似乎会略微平滑树木,这导致树木上的图案略微消失[参见图10(c)中的绿色矩形]。这可能就是为什么在树类的第1对上,使用CycleGAN的框架优于使用ColorMapGAN的框架。
2) ColorMapGAN VS直方图匹配[46]:直方图匹配的主要问题是它没有考虑上下文信息,只尝试将整个训练城市的直方图与整个测试城市的直方图进行匹配。相反,ColorMapGAN的鉴别器从生成器的输出和测试数据中提取高级特征,以确定哪个是真的,哪个是假的。换句话说,生成器生成一个假训练城市,其高级特征与从测试城市提取的高级特征对齐。因此,使用ColorMapGAN的拟议框架产生了显著改进的结果。如图11黄色矩形所示,当生成假坏Ischl时,直方图匹配将一些灰色屋顶转换为青色屋顶,而ColorMapGAN将它们保持为灰色。类似地,在图11中,我们观察到用绿色矩形突出显示的建筑物在直方图匹配的输出中有深紫色屋顶,在ColorMapGAN生成的图像中有黑色屋顶。Villach没有青色或深紫色屋顶的建筑,但有许多灰色或黑色屋顶的建筑[见图7(a)]。如果ColorMapGAN的生成器生成了青色或暗紫罗兰色的屋顶,鉴别器将很容易理解这些建筑是假的。因此,这样的建筑不会出现在ColorMapGAN的输出中。类似地,在生成伪Roanne的过程中,直方图匹配算法生成一些红色道路,如图12所示,由黄色矩形显示。在图12中,我们看到ColorMapGAN输出灰色道路。此外,ColorMapGAN生成屋顶为棕色的建筑,这可能比直方图匹配生成的屋顶为红色的建筑更具有代表性。如第一节所述,CNN对培训数据极其敏感。训练和测试数据之间的小范围变化可能会显著影响结果。此外,在图13中,我们描绘了Roanne中建筑物的颜色直方图、通过直方图匹配和ColorMapGAN生成的假Roanne以及Béziers。由于罗恩和贝兹是两个不同的城市,我们不能期望理想的假罗恩和贝兹的直方图完全相同。然而,我们希望他们彼此相似。虽然直方图匹配算法试图将训练城市的直方图与测试城市的直方图进行匹配,但假训练城市和测试城市的类直方图之间存在很大差异。如图13(b)所示,两者之间存在较大偏差 。相比之下,ColorMapGAN生成的假罗恩中的建筑的颜色直方图与贝塞尔中的建筑直方图更为相似。对于直方图匹配,我们也观察到了其他类的相同问题,但由于缺少空间,我们不包括其他类的直方图。
14-17用CycleGAN、UNIT、MUNIT、DRIT、gray world、直方图匹配和ColorMapGAN描述了我们提出的框架的预测。
4.5.训练时间
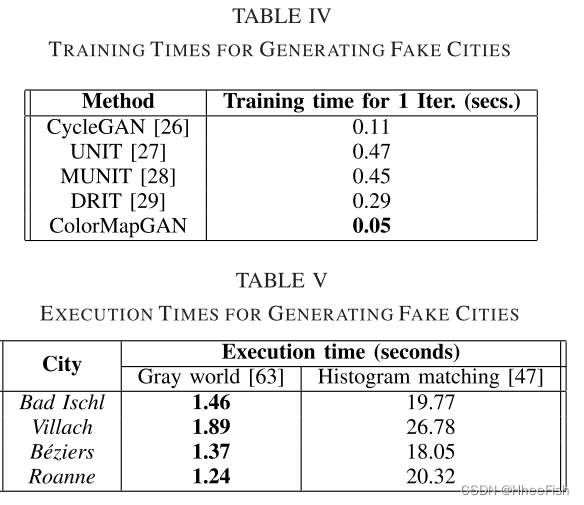
提议的框架ColorMapGAN、CycleGAN、UNIT、MUNIT和DRIT在Tensorflow中实现。1我们在Nvidia Geforce GTX1080 Ti GPU上进行了所有实验,该GPU具有11 GB的RAM。表IV报告了一次迭代中训练ColorMapGAN和其他基于学习的比较方法的运行时间。表四表明,ColorMapGAN的训练时间明显短于其他基于学习的方法。让我们再次指出,我们只为8000次迭代优化了ColorMapGAN。换句话说,我们只需要大约6.5分钟就可以训练它。另一方面,使用默认参数的其他基于学习的方法需要长时间的训练。同样值得注意的是,如表V所示,基于非学习的方法在更短的时间内生成输出。灰色世界算法的执行时间几乎是即时的,直方图匹配需要不到半分钟的时间。然而,基于非学习的方法的结果质量不足。
5.结论
在这篇文章中,我们提出了一个新的框架,从卫星图像生成高质量的地图,即使在训练图像和测试图像的光谱带之间存在较大的区域偏移。我们在两个城市对上验证了我们的方法,在每个城市对中执行了城市到城市域的自适应。我们的实验结果表明,该框架比现有的方法表现出更好的性能。我们还表明,与计算机视觉界开发的一些竞争性的未配对I2I方法相比,提出的ColorMapGAN生成假图像的时间要短得多。未来一个可能的方向可能是研究一个更困难的领域适应问题,除了光谱差异较大外,物体的形状,例如训练和测试图像中的建筑物,也有很大的不同。
参考文献
[1] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Medical Image Computing and Computer-Assisted Intervention—MICCAI. Munich, Germany: Springer, 2015, pp. 234–241.
[2] V . Iglovikov and A. Shvets, “TernausNet: U-Net with VGG11 encoder pre-trained on ImageNet for image segmentation,” 2018, arXiv:1801.05746.
[Online]. Available: http://arxiv.org/abs/1801.05746
[3] V . I. Iglovikov, S. Seferbekov, A. V . Buslaev, and A. Shvets, “TernausNetV2: Fully convolutional network for instance segmentation,” 2018, arXiv:1806.00844.
[Online]. Available: http://arxiv.org/abs/1806.00844
[4] A. Khalel, O. Tasar, G. Charpiat, and Y . Tarabalka, “Multi-task deep learning for satellite image pansharpening and segmentation,” in Proc. IGARSS, Jul. 2019, pp. 4869–4872.
[5] E. Maggiori, Y . Tarabalka, G. Charpiat, and P. Alliez, “High-resolution aerial image labeling with convolutional neural networks,” IEEE Trans. Geosci. Remote Sens., vol. 55, no. 12, pp. 7092–7103, Dec. 2017.
[6] B. Huang et al., “Large-scale semantic classification: Outcome of the first year of Inria Aerial Image Labeling Benchmark,” in Proc. IGARSS, Jul. 2018, pp. 6947–6950.
[7] O. Tasar, Y . Tarabalka, and P. Alliez, “Incremental learning for semantic segmentation of large-scale remote sensing data,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 12, no. 9, pp. 3524–3537, Sep. 2019.
[8] O. Tasar, Y . Tarabalka, and P. Alliez, “Continual learning for dense labeling of satellite images,” in Proc. IGARSS, Jul. 2019, pp. 4943–4946.
[9] J. Hoffman, D. Wang, F. Y u, and T. Darrell, “FCNs in the wild: Pixel-level adversarial and constraint-based adaptation,” 2016, arXiv:1612.02649.
[Online]. Available: http://arxiv.org/abs/1612.02649
[10] S. Sankaranarayanan, Y . Balaji, A. Jain, S. N. Lim, and R. Chellappa, “Learning from synthetic data: Addressing domain shift for semantic segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 3752–3761.
[11] Z. Murez, S. Kolouri, D. Kriegman, R. Ramamoorthi, and K. Kim, “Image to image translation for domain adaptation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 4500–4509.
[12] Y .-H. Tsai, W.-C. Hung, S. Schulter, K. Sohn, M.-H. Y ang, and M. Chandraker, “Learning to adapt structured output space for semantic segmentation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 7472–7481.
[13] H. Huang, Q. Huang, and P . Krahenbuhl, “Domain transfer through deep activation matching,” in Proc. ECCV, 2018, pp. 590–605.
[14] W. Hong, Z. Wang, M. Y ang, and J. Y uan, “Conditional generative adversarial network for structured domain adaptation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 1335–1344.
[15] K. Saito, K. Watanabe, Y . Ushiku, and T. Harada, “Maximum classifier discrepancy for unsupervised domain adaptation,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 3723–3732.
[16] Y . Zhang, P . David, and B. Gong, “Curriculum domain adaptation for semantic segmentation of urban scenes,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 2020–2030.
[17] Y . Chen, W. Li, and L. V . Gool, “ROAD: Reality oriented adaptation for semantic segmentation of urban scenes,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 7892–7901.
[18] O. Russakovsky et al., “ImageNet large scale visual recognition challenge,” Int. J. Comput. Vis., vol. 115, no. 3, pp. 211–252, Dec. 2015.
[19] J. Zhang, C. Liang, and C.-C.-J. Kuo, “A fully convolutional tri-branch network (FCTN) for domain adaptation,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), Apr. 2018, pp. 3001–3005.
[20] Y . Zou, Z. Y u, B. V . Kumar, and J. Wang, “Unsupervised domain adaptation for semantic segmentation via class-balanced self-training,” in Proc. ECCV, 2018, pp. 289–305.
[21] R. Romijnders, P. Meletis, and G. Dubbelman, “A domain agnostic normalization layer for unsupervised adversarial domain adaptation,” 2018, arXiv:1809.05298.
[Online]. Available: http://arxiv.org/abs/1809.05298
[22] K. Saito, Y . Ushiku, T. Harada, and K. Saenko, “Adversarial dropout regularization,” 2017, arXiv:1711.01575.
[Online]. Available: http://arxiv.org/abs/1711.01575
[23] X. Pan, P. Luo, J. Shi, and X. Tang, “Two at once: Enhancing learning and generalization capacities via IBN-Net,” in Proc. ECCV, 2018, pp. 464–479.
[24] X. Zhu, H. Zhou, C. Y ang, J. Shi, and D. Lin, “Penalizing top performers: Conservative loss for semantic segmentation adaptation,” in Proc. ECCV, 2018, pp. 568–583.
[25] D. Ulyanov, A. V edaldi, and V . Lempitsky, “Instance normalization: The missing ingredient for fast stylization,” 2016, arXiv:1607.08022.
[Online]. Available: http://arxiv.org/abs/1607.08022
[26] J.-Y . Zhu, T. Park, P . Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 2223–2232.
[27] M.-Y . Liu, T. Breuel, and J. Kautz, “Unsupervised image-to-image translation networks,” in Proc. NIPS, 2017, pp. 700–708.
[28] X. Huang, M.-Y . Liu, S. Belongie, and J. Kautz, “Multimodal unsupervised image-to-image translation,” in Proc. ECCV, 2018, pp. 172–189.
[29] H.-Y . Lee, H.-Y . Tseng, J.-B. Huang, M. Singh, and M.-H. Y ang, “Diverse image-to-image translation via disentangled representations,” in Proc. ECCV, 2018, pp. 35–51.
[30] J. Hoffman et al., “CyCADA: Cycle-consistent adversarial domain adaptation,” 2017, arXiv:1711.03213.
[Online]. Available: http://arxiv.org/abs/1711.03213
[31] L. A. Gatys, A. S. Ecker, and M. Bethge, “Image style transfer using convolutional neural networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 2414–2423.
[32] L. A. Gatys, M. Bethge, A. Hertzmann, and E. Shechtman, “Preserving color in neural artistic style transfer,” 2016, arXiv:1606.05897.
[Online]. Available: http://arxiv.org/abs/1606.05897
[33] J. Johnson, A. Alahi, and L. Fei-Fei, “Perceptual losses for real-time style transfer and super-resolution,” in Proc. ECCV. A m s t e r d a m , T h e Netherlands: Springer, 2016, pp. 694–711.
[34] D. Ulyanov, V . Lebedev, A. V edaldi, and V . S. Lempitsky, “Texture networks: Feed-forward synthesis of textures and stylized images,” in Proc. ICML, 2016, vol. 1, no. 2, p. 4.
[35] D. Tuia, C. Persello, and L. Bruzzone, “Domain adaptation for the classification of remote sensing data: An overview of recent advances,” IEEE Geosci. Remote Sens. Mag., vol. 4, no. 2, pp. 41–57, Jun. 2016.
[36] L. Bruzzone and C. Persello, “A novel approach to the selection of spatially invariant features for the classification of hyperspectral images with improved generalization capability,” IEEE Trans. Geosci. Remote Sens., vol. 47, no. 9, pp. 3180–3191, Sep. 2009.
[37] C. Persello and L. Bruzzone, “Kernel-based domain-invariant feature selection in hyperspectral images for transfer learning,” IEEE Trans. Geosci. Remote Sens., vol. 54, no. 5, pp. 2615–2626, May 2016.
[38] L. Bruzzone and D. F. Prieto, “Unsupervised retraining of a maximum likelihood classifier for the analysis of multitemporal remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 39, no. 2, pp. 456–460, Feb. 2001.
[39] L. Bruzzone and D. F. Prieto, “A partially unsupervised cascade classifier for the analysis of multitemporal remote-sensing images,” Pattern Recognit. Lett., vol. 23, no. 9, pp. 1063–1071, Jul. 2002.
[40] L. Bruzzone and R. Cossu, “A multiple-cascade-classifier system for a robust and partially unsupervised updating of land-cover maps,” IEEE Trans. Geosci. Remote Sens., vol. 40, no. 9, pp. 1984–1996, Sep. 2002.
[41] L. Bruzzone and M. Marconcini, “Domain adaptation problems: A DASVM classification technique and a circular validation strategy,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 32, no. 5, pp. 770–787, May 2010.
[42] C. Persello and L. Bruzzone, “Active learning for domain adaptation in the supervised classification of remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 50, no. 11, pp. 4468–4483, Nov. 2012.
[43] G. Matasci, D. Tuia, and M. Kanevski, “SVM-based boosting of active learning strategies for efficient domain adaptation,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 5, no. 5, pp. 1335–1343, Oct. 2012.
[44] C. Deng, X. Liu, C. Li, and D. Tao, “Active multi-kernel domain adaptation for hyperspectral image classification,” Pattern Recognit., vol. 77, pp. 306–315, May 2018.
[45] S. Ghassemi, A. Fiandrotti, G. Francini, and E. Magli, “Learning and adapting robust features for satellite image segmentation on heterogeneous data sets,” IEEE Trans. Geosci. Remote Sens., vol. 57, no. 9, pp. 6517–6529, Sep. 2019.
[46] S. Inamdar, F. Bovolo, L. Bruzzone, and S. Chaudhuri, “Multidimensional probability density function matching for preprocessing of multitemporal remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 46, no. 4, pp. 1243–1252, Apr. 2008.
[47] R. C. Gonzalez and R. E. Woods, Digital Image Processing, 3 r d e d . Upper Saddle River, NJ, USA: Prentice-Hall, Inc., 2006.
[48] D. Tuia, J. Munoz-Mari, L. Gomez-Chova, and J. Malo, “Graph matching for adaptation in remote sensing,” IEEE Trans. Geosci. Remote Sens., vol. 51, no. 1, pp. 329–341, Jan. 2013.
[49] A. A. Nielsen and M. J. Canty, “Kernel principal component and maximum autocorrelation factor analyses for change detection,” Proc. SPIE, vol. 7477, p. 74770T, Sep. 2009.
[50] V . Agarwal, B. Abidi, A. Koschan, and M. A. Abidi, “An overview of color constancy algorithms,” J. Pattern Recognit. Res., vol. 1, no. 1, pp. 42–54, 2006.
[51] G. Matasci, M. V olpi, M. Kanevski, L. Bruzzone, and D. Tuia, “Semisupervised transfer component analysis for domain adaptation in remote sensing image classification,” IEEE Trans. Geosci. Remote Sens., vol. 53, no. 7, pp. 3550–3564, Jul. 2015.
[52] G. Matasci, N. Longbotham, F. Pacifici, M. Kanevski, and D. Tuia, “Understanding angular effects in VHR imagery and their significance for urban land-cover model portability: A study of two multi-angle intrack image sequences,” ISPRS J. Photogram. Remote Sens., vol. 107, pp. 99–111, Sep. 2015.
[53] L. Ma, M. M. Crawford, L. Zhu, and Y . Liu, “Centroid and covariance alignment-based domain adaptation for unsupervised classification of remote sensing images,” IEEE Trans. Geosci. Remote Sens., vol. 57, no. 4, pp. 2305–2323, Apr. 2019.
[54] W. Gross, D. Tuia, U. Soergel, and W. Middelmann, “Nonlinear feature normalization for hyperspectral domain adaptation and mitigation of nonlinear effects,” IEEE Trans. Geosci. Remote Sens., vol. 57, no. 8, pp. 5975–5990, Aug. 2019.
[55] Y . Qin, L. Bruzzone, and B. Li, “Tensor alignment based domain adaptation for hyperspectral image classification,” 2018, arXiv:1808.09769.
[Online]. Available: http://arxiv.org/abs/1808.09769
[56] F. Pacifici, N. Longbotham, and W. J. Emery, “The importance of physical quantities for the analysis of multitemporal and multiangular optical very high spatial resolution images,” IEEE Trans. Geosci. Remote Sens., vol. 52, no. 10, pp. 6241–6256, Oct. 2014.
[57] K. I. Itten and P. Meyer, “Geometric and radiometric correction of TM data of mountainous forested areas,” IEEE Trans. Geosci. Remote Sens., vol. 31, no. 4, pp. 764–770, Jul. 1993.
[58] N. Courty, R. Flamary, and D. Tuia, “Domain adaptation with regularized optimal transport,” in Proc. Joint Eur. Conf. Mach. Learn. Knowl. Discovery Databases. Nancy, France: Springer, 2014, pp. 274–289.
[59] N. Courty, R. Flamary, D. Tuia, and A. Rakotomamonjy, “Optimal transport for domain adaptation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 9, pp. 1853–1865, Sep. 2017.
[60] B. Tardy, J. Inglada, and J. Michel, “Assessment of optimal transport for operational land-cover mapping using high-resolution satellite images time series without reference data of the mapping period,” Remote Sens., vol. 11, no. 9, p. 1047, 2019.
[61] B. Benjdira, Y . Bazi, A. Koubaa, and K. Ouni, “Unsupervised domain adaptation using generative adversarial networks for semantic segmentation of aerial images,” Remote Sens., vol. 11, no. 11, p. 1369, 2019.
[62] P . Isola, J.-Y . Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 1125–1134.
[63] G. Buchsbaum, “A spatial processor model for object colour perception,” J. Franklin Inst., vol. 310, no. 1, pp. 1–26, Jul. 1980.
[64] I. Goodfellow et al., “Generative adversarial nets,” in Proc. NIPS, 2014, pp. 2672–2680.
[65] A. Radford, L. Metz, and S. Chintala, “Unsupervised representation learning with deep convolutional generative adversarial networks,” 2015, arXiv:1511.06434.
[Online]. Available: http://arxiv.org/abs/1511.06434
[66] M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein GAN,” 2017, arXiv:1701.07875.
[Online]. Available: https://arxiv.org/abs/1701.07875
[67] I. Gulrajani, F. Ahmed, M. Arjovsky, V . Dumoulin, and A. C. Courville, “Improved training of wasserstein GANs,” in Proc. NIPS, 2017, pp. 5767–5777.
[ 6 8 ] X . M a o , Q . L i , H . X i e , R . Y . K . L a u , Z . W a n g , a n d S . P . S m o l l e y , “Least squares generative adversarial networks,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 2794–2802.
[69] M. Mirza and S. Osindero, “Conditional generative adversarial nets,” 2014, arXiv:1411.1784.
[Online]. Available: http://arxiv.org/ abs/1411.1784
[70] B. Xu, N. Wang, T. Chen, and M. Li, “Empirical evaluation of rectified activations in convolutional network,” 2015, arXiv:1505.00853.
[Online]. Available: http://arxiv.org/abs/1505.00853
[71] X. Huang and S. Belongie, “Arbitrary style transfer in real-time with adaptive instance normalization,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Oct. 2017, pp. 1501–1510.
[72] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Y uille, “DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 40, no. 4, pp. 834–848, Apr. 2018.
[73] G. Csurka, D. Larlus, and F. Perronnin, “What is a good evaluation measure for semantic segmentation?” in Proc. BMVC, vol. 27, 2013, pp. 32.1–32.11. [Online]. Available: http://www.bmva.org/bmvc/2013/ Papers/paper0032/index.html
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)