浅谈操作系统与内存
对于计算机的发明,相信大家都有耳闻那个占地面积按平米算的第一台计算机。在那个时候,CPU的资源是极其珍贵的,随着这些年突飞猛进的发展,一片指甲盖大小的民用级CPU一秒钟能执行的指令数可以达到上亿级别。
随着计算能力的增长,芯片外围的硬件和配套的软件也是一路高歌,发生了天翻地覆的变化,今天我们简单回顾历史,来看一看操作系统和内存机制的演变,不仅要了解它们是怎样,同时也看看它们为什么会是这样。
CPU的运行
一说到CPU(Center processing unit),大家都觉得这是非常了不起的东西,我们的手机电脑都是由它进行核心控制,拥有掌管一切的能力,但是,它真的有传说中那么聪明么?
事实并非如此,CPU唯一的能力其实就是处理二进制数据,CPU的组成是这样的:
- CPU有三种总线:控制总线,地址总线,数据总线,这些总线统称为系统总线,主要用来与外设交换数据。
- 内部寄存器若干,一般只有几十个字节,普通寄存器负责传输数据,特殊寄存器如PC,SP,LD则控制程序流程。
- ALU-算数逻辑运算单元,既然是处理数据,当然也就依赖运算单元,这些运算单元只能处理加减乘法,其实严格来说,就是处理加法,减和乘是在加法基础上实现的。
这三个就是早期CPU的主要部件了,那它是怎么处理数据的呢?
系统总线负责与外部的数据交换,将交换的数据暂时放在寄存器中,然后CPU再从寄存器中获取数据使用算数逻辑运算单元进行运算,必要时将数据写回。
是的,仅此而已,CPU不能直接播放音乐,它也不能生成游戏界面,只是孜孜不倦地拿数据,处理数据,写回数据,像个一刻也不停的流水线工人。
系统的存储
上文中我们提到CPU的内部寄存器,因为是集成在CPU内部,所以速度非常快,但是同时也因为集成度的问题,CPU中一般只有几十字节的寄存器,这对于数据处理是远远不够的,所以当运行时存储空间不够的时候我们必须有另一个地方进行存储,这就是系统内存。
即使都是数据,也分别有不同的属性,比如是否需要掉电保存,数据处理的速率要求。
在程序执行时,需要在存储设备中保存一些运行参数,这部分存储数据的速率直接决定了程序运行速率,所以对这部分存储的要求是速度快,同时因为是存储运行时参数,所以不需要掉电保存。
在程序执行之外,需要保存大量的静态数据,比如用户数据,文件,这部分数据需要掉电能够保存,且要求可存储数据量大,由于访问并不频繁,所以对速率要求可以降低以节省成本。
由此,存储设备分化出了ram和rom两大类,ram有速率快,掉电不保存的特性,而rom是速率慢,存储量大,掉电保存。
ram和rom只是分别对应易失性存储器和非易失性存储器的统称,事实上ram有sram,sdram等等,而rom有eeprom,flash,硬盘等等。
微控制器和单板机
上面说到CPU的作用,可能你开始有疑问了,既然CPU只能处理简单的数据,那么它是怎么处理复杂软件的运行的呢?
这就是很多人的一个常见误区,将CPU和MCU,还有单板机搞混了。
MCU(Microcontroller unit):微控制器,又被称为单片微型计算机,常被直接称为单片机。它通常集成了CPU,rom,ram以及硬件控制器、外围电路等等,ram和rom的容量有限,接口电路也有限。
单板机:单板机是把微型计算机的整个功能体系电路(CPU、ROM、RAM、输入/输出接口电路以及其他辅助电路)全部组装在一块印制电板上,再用印制电路将各个功能芯片连接起来,一般来说资源比如主频、ram&rom容量要比MCU高出一大截。
事实上,在我们常见的手机电脑中,用户常说的CPU,事实上指的是单板机。而在嵌入式设备上,经常会使用到单片机。
常见的第二个误区就是:认为整个单板机(或者MCU)上只有CPU是可编程元件,其他部分都是硬件搭建起来的。
事实上,除了CPU,像各种硬件控制器比如gpio、i2c、dma或者硬盘控制器,这些都是可编程器件,只是这些控制器所扮演的都是一个从机角色,而主控是CPU。
CPU通过系统总线与各个控制器之间进行数据交互,通过特定的预定义的指令来控制控制器的行为:
比如控制gpio的操作,将某个引脚的电平从0设置成1,这样再配合上继电器等硬件上的电路,就可以实现220V电路的控制。
再者是通过控制gpio以通过预定义的控制协议与连接在另一端的设备进行通信。
又或者是告诉硬盘控制器,CPU需要访问某些数据,硬盘控制器将数据传递给CPU。
CPU就是这样通过将指令一级级地将数据传递给外设,通过在外设处理器中预定义了一些指令字段,外设接收CPU的数据相当于接收到控制指令,以此实现外设的控制。
而CPU本身则只是孜孜不倦地处理数据,反馈数据。
单片机到操作系统
在早期的CPU上,CPU都是顺序执行,一个CPU只运行一个程序,这样造成的问题就是:当程序在等待某个资源或者读写磁盘的时候,CPU就处于空闲状态,这对CPU来说是非常浪费的。由于CPU的资源非常珍贵,人们不得不想办法解决这个问题,所以就有人编写多任务程序:
一个CPU中可以存在多个任务,一个时刻只允许一个任务运行,当检测程序检测到某个任务处于空闲状态,就切换下一个任务运行。或者是当前任务主动放弃运行权,切换下一个任务运行。
这就是操作系统的原型,检测程序一般被称为调度器,遵循某种调度算法。
任务调度算法
调度算法又常被称为调度策略,目前的操作系统常用的调度策略有两种:
- 基于优先级的调度,优先级高的任务总是有权利抢到CPU的使用权,高优先级的任务通过主动睡眠和被动睡眠让出CPU使用权(如等待信号量,等待锁)
- 时间片机制,每个任务分配时间片,一般是ms级别的时间,当时间片用完就切换到下一个任务,营造一种所有任务同时运行的假象。
事实上,操作系统往往在基于上述调度算法的基础上,运行着更复杂的调度算法,比如以优先级为权重分配时间片,比如任务分组,不同的分组有不同的调度策略等等....
任务调度的执行原理
上文说到,操作系统的的最早雏形就是允许CPU中存在多个任务,通过某种调度算法来使每个任务交替运行。
那么,CPU到底是怎么做到这件事的呢?
首先我们要了解以下概念:时钟、中断,程序执行流的切换。
- 时钟:是CPU上最重要的部分之一,任何一个CPU都必须有时钟部分,它提供了CPU上时间的概念,系统不同部分之间的交互和同步都要靠时钟信号来进行同步。通俗来说,就像人类定义了时间的概念,我们才可以统一做到准时上下班,相约同一时间去做某事。CPU也是一样,在进行数据传输时,通信双方必须统一传输单元数据的时间,才能进行同步和数据解析。
- 中断:即使是目前非常简单的单片机,也提供中断功能。我们可以将中断理解为CPU中的突发事件需要紧急处理,这时CPU暂停处理原本任务转去处理中断,处理完中断之后再回头来处理原先的任务。
- 程序执行流的切换:CPU中一般会有多个寄存器,分为通用寄存器和特殊寄存器,通用寄存器用来存取CPU处理的数据,而特殊寄存器中需要提及的就是PC指针(程序计数器),SP(栈指针),PC指针中存储着下一条将要执行的指令地址,而SP指针则指向栈地址。
在正常情况下,程序顺序运行,PC指针也是按顺序装载需要执行程序的地址,CPU每次执行一条指令都会从PC指针读取程序执行地址,然后从执行地址上取到数据,执行相应动作,而栈则保存着函数调用过程中的信息(因为调用完需要返回到调用前状态)。
在发生中断的时候,因为需要跳转去执行中断服务函数,肯定需要更改程序执行流,在单片机上,CPU将会去查中断向量表,找到需要执行的函数地址装载到PC指针处,然后保存一些当前运行参数,比如寄存器数据,栈数据,下一个指令周期将会跳转执行中断服务函数。
既然程序的执行流可以由程序员自由控制,只要控制PC指针指向就可以,那么我们也可以预先定义两个任务,当一个任务空闲时,直接跳转执行到另一个任务,每个任务的运行参数比如寄存器数据,栈数据,使用的资源等等进行保存,在切换到某个任务时,只要将保存的信息恢复到原来的状态就可以继续运行任务,这种操作方式当然可以从两个延伸到多个,这就是操作系统的模型。
通常,保存信息的部分一般使用结构体链表,一般被称为任务控制块(每个操作系统的叫法不一样,但实现的思想是一样的),每个线程都有独立的栈空间以保存每个线程的运行时状态。
那么,我们怎么知道什么时候执行另一个任务呢?这就需要借助时钟中断提供一个时间的概念,任务的运行时间就以这个时钟中断作为度量,具体的做法就是每隔一个周期(通常非常短,1ms、10ms等)产生一次中断,在中断程序中检查是否需要切换任务运行,而切换的原因就比较多了,比如运行时间到了、等待某项资源自主休眠等等。
事实上,到这里,你已经了解了嵌入式实时系统的运行原理了,比如ucos,freeRTOS之类的,建议去看看相关源代码,尤其是ucos,代码量少且易懂,麻雀虽小五脏俱全。
嵌入式实时操作系统的内存限制
在早期的单片机上,程序运行在物理内存中,也就是说,程序在运行时直接访问到物理地址,在程序运行开始,将全部程序加载到内存中,所有的数据地址和程序地址就此固定。
在运行多任务系统时,比较直接的办法也是直接为每个任务分配各自需要的内存空间,比如总内存为100M,task1需要40M,task2需要50M,task3需要20M,那么最简单的办法是给task1分配40M,给task2分配50M,而task3,不好意思,内存不够了,不允许运行,这样简单的分配方式有以下问题:
- 地址空间不隔离 试想一下,所有程序都访问物理地址,那么就存在task1可以直接访问到task2任务内存空间的情况,这就给了一些恶意程序机会来进行一些非法操作,即使是非恶意但是有bug的程序,也可能会导致其他任务无法运行,这对于需要安全稳定的的计算机环境的用户是不能容忍的。
- 内存使用效率极低 由于没有有效的内存管理机制,通常在一个程序执行时,将整个程序装载进内存中运行,如果我们要运行task3,内存已经不够了,其实系统完全可以将暂时没有运行的task2先装入磁盘中,将task3装载到内存,当需要运行task2时,再将task2换回,虽然牺牲了一些执行效率,但总归是可以支持更多程序运行。
- 程序地址空间不确定 需要了解的是程序在编译阶段生成的可执行文件中符号地址是连续且确定的,即使实现了内存数据与磁盘的交换,将暂时不需要的任务放入磁盘而运行其他任务,程序每次装入内存时,都需要从内存中分配一段连续内存,这个空间是不确定的,但是在程序实现过程中,有些数据往往要求其地址空间是确定的,这就会给编写程序带来很大的麻烦。
虚拟内存机制
那么怎么解决这个问题呢?曾经有人说过一句名言:
计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决。
在这里这个道理同样适用,后来的操作系统设计者设计了一种新的模型,在内存中增加一层虚拟地址。
面对开发者而言,程序中使用的地址都是虚拟地址,这样,只要我们能妥善处理好虚拟地址到物理地址的映射过程,而这个映射过程被当作独立的一部分存在,就可以解决上述提到的三个问题:
- 首先,对于地址隔离,因为程序员操作的是虚拟地址,虚拟地址在最后会转化为物理地址,可能程序A访问的0x8000,转换到物理地址是0x3000,而程序B同样访问0x8000,但是会被转换到物理地址0x4000,这样程序中并不知道自己操作的物理地址,也操作不到实际的物理地址,因为虚拟地址的转换总会将地址映射到不冲突的物理地址上,同时进行检测,也就无从影响到别的任务执行。
- 对于内存使用率来说 建立完善的内存管理机制,可以更方便地进行内存与磁盘数据的交换,将空置的内存利用起来而不增加编程者的负担。
- 对于程序空间不确定 虚拟内存机制完美地解决了这个问题,在直接操作物理地址时,因为内存与磁盘的交换,可能导致函数或者变量地址的变化,原来程序中的数据必须进行更新。
而引入虚拟内存机制,程序员只操作虚拟地址,函数、变量虚拟地址不变,物理地址可能变化,但是程序员只需要关注虚拟地址就行了,虚拟地址到物理地址的转换就由内存管理部分负责。
既然增加了一个中间层,那么这个中间层最好是由独立的部分进行管理,实现这个功能的器件就是MMU,它接管了程序中虚拟地址和物理地址的转换,MMU一般直接集成在CPU中,不会以独立的器件存在。
内存分段分页机制
在经典32位桌面操作系统中,有32条地址线(特殊情况下可能36条),那么CPU可直接寻址到的内存空间为2^32字节,也就是4GB,虽说内存寻址可以到4G,但是常常在单板机上 并不会有这么大的物理内存。
根据实际情况而不同,可能是512M或者更少,但是由于虚拟内存机制的存在,程序看起来可操作的内存就是4GB,因为MMU总会找到与程序中的虚拟地址相对应的物理地址,在内存不够用时,它就会征用硬盘中的空间,在linux下安装系统时会让你分出一片swap分区,顾名思义,swap分区就是用来内存交换的。
那4GB这么大的内存,如果不进行组织,在CPU读写数据时将会是一场灾难,因为要找到一个数据在最坏的情况下需要遍历整个内存。
就像一个部队,总要按照军、师、旅、团、营、连、排、班来划分,如果全由总司令管理所有人,那也会是一场灾难。
因此,对于内存而言,衍生了分段和分页机制,根据功能划分段,然后再细分成页,一般一页是4K,当然,这其中会有根据不同业务的差别做一些特别的定制。
它的问题就是即使是只存储一个字节,也要用掉一页的内存,造成一定的浪费。
但是如果将分页粒度定得过细,将会造成访问成本的增加,因为在很多时候,进行访问都是直接使用轮询机制。而且,就像每本书都有目录和前言,段和页的信息都要在系统中进行记录,分页更细则代表页数更多,这部分的开销也就更多。这也是一种浪费。
就像程序中时间与空间的拉锯战,计算机中充满了妥协。
单片机与单板机程序执行的不同
处理器是否携带MMU几乎完全成了划分单片机和单板机的分界线。
带MMU的处理器直接运行桌面系统,如linux、windows之类的,与不带MMU的单片机相比,体现在用户眼前的最大区别就是进程的概念,一个进程就是一个程序的运行实体,使得桌面系统中可以同时运行多个程序,而每个程序由于虚拟机制的存在,看起来是独占了整个内存空间。
而不带MMU的处理器,一般是嵌入式设备,程序直接在物理地址上运行,支持多线程。
从程序的加载执行来说,桌面系统中程序编译完成之后存储在文件系统中,在程序被调用执行时由加载器加载到内存中执行。而在单片机中,程序编译生成的可执行文件一般是直接下载到片上flash(rom的一种)中。
32位单片机的寻址范围为4G,由于不支持虚拟内存技术,一般在总线上连接的ram不会太大,所以可以直接将rom也挂载在总线上,CPU可以直接通过总线访问flash上的数据,所以程序可以直接在片上flash中执行,在运行时只是将数据部分加载到ram中运行。
无系统单线程,嵌入式实时操作系统和桌面操作系统
可以在单板机上运行桌面操作系统,是不是运行单线程的单片机和嵌入式实时操作系统就可以抛弃了呢?
从功能实现上来说,单板机确实比单片机强很多,但是资源的增加同时带来成本的增加,所以在一些成本敏感的应用场合下反而是单片机的天下。
而对于操作系统而言,嵌入式实时操作系统由于没有一些臃肿的系统服务,有时反而有着比桌面系统更好的实时性,在实时性要求高的场合更是风生水起,比如无人机、车载系统。而且运行在单片机上,成本上更有优势。
对于嵌入式开发而言,很有必要了解这三种程序运行方式:无系统单线程,嵌入式实时操作系统,桌面操作系统。
- 无系统单线程很好理解,程序顺序执行,除了发生中断之后跳转执行中断服务函数,一般不会再发生程序执行流的切换,程序直接操作物理地址,常用于嵌入式小型设备,如灯、插座开关等等。
- 嵌入式实时操作系统:支持多线程的并发执行,多任务循环执行,遵循一定的调度算法,程序直接操作物理地址。例如ucos、free rtos,通常也在移植在资源相对较多的单片机上。
- 桌面操作系统:CPU自带MMU,所以支持虚拟内存机制,支持多进程和多线程编程,程序操作虚拟地址,在人机交互上有很好的表现。例如windows,linux,常用的手机、ipad、服务器、个人电脑。
在单片机上,无系统单线程模式可以很简单地切换到嵌入式实时操作系统,进行相应的移植即可。
但是是否能在其上运行桌面操作系统,是否集成MMU是一个决定性的因素。
/*********************************************************************
Windows核心编程:内存体系结构
1.进程的虚拟地址空间
每 个进程都有自己的虚拟地址空间。对32位进程来说,这个地址空间的大小为4GB,这是因为32位指针可以表示从0x00000000到 0xFFFFFFFF之间的任一值,指针在这个范围内可以有4 294 967 296个值,它们覆盖了进城的4GB地址空间。对62位进程来说,它们可以覆盖16EB地址空间,这个地址空间实在太大了!!!
每个进程有自己的私有地址空间,但是要记住这只是虚拟地址空间,不是物理存储器。为了能过正常读/写数据,我们需要把物理存储器分配或映射到相应的虚拟地址空间,否则将导致访问违规。
2.虚拟地址空间的分区
每个进程的虚拟地址空间被划分成许多分区(partition)。由于地址空间的分区依赖于操作系统的底层实现,因此会随着Windows内核的不同而略有变化。表1列出了各平台上对进程地址空间的分区。
表1:进程地址空间是如何划分的
分区
x 86 32位Windows
3 GB用户模式下的 x 86
32位Windows
x 64 64位Windows
IA-64 64位 Windows
空指针赋值分区
0x00000000
0x00000000
0x00000000'00000000
0x00000000'00000000
0x0000FFFF
0x0000FFFF
0x00000000'0000FFFF
0x00000000'0000FFFF
用户模式分区
0x00010000
0x00010000
0x00000000'00010000
0x00000000'00010000
0x7FFEFFFF
0xBFFEFFFF
0x000007FF'FFFEFFFF
0x000006FB'FFFEFFFF
64-KB
禁入分区
0x7FFF0000
0xBFFF0000
0x000007FF'FFFF0000
0x000006FB'FFFF0000
0x7FFFFFFF
0xBFFFFFFF
0x000007FF'FFFFFFFF
0x000006FB'FFFFFFFF
内核模式分区
0x80000000
0xC0000000
0x00000800'00000000
0x000006FC'00000000
0xFFFFFFFF
0xFFFFFFFF
0xFFFFFFFF'FFFFFFFF
0xFFFFFFFF'FFFFFFFF
空指针赋值分区:
保留该区域的目的是为了帮助程序员捕获对空指针的赋值。如果进程中的线程试图读取或写入位于这一分区内的内存地址,就会引发访问违规。没有任何办法可以让我们分配到位于这一地址区间内的虚拟内存。
用户模式分区:
这一分区是进程地址空间的驻地。对所有应用程序来说,进程的大部分数据都保存在这一分区。
内核模式分区:
系 统需要用这一空间来存放内核代码。设备驱动程序代码、设备输入/输出高速缓存、非分页缓冲池分配表、进程页面表,等等。驻留在这一分区内的任何东西为所有 进程共有。该分区中的所有代码和数据都被完全的保护起来。如果一个应用程序试图读取或写入位于这一分区中的内存地址,会引发访问违规。在默认情况下,访问 违规会导致系统先向用户显示一个消息框,然后结束该应用程序。
3.地址空间中的区域
当系统创建一个进程并赋予它地址空间时,可用地址空间中的大部分都是闲置的(free)或尚未分配的(unallocated)
。为了使用这部分地址空间,我们必须调用VirtualAlloc来分配其中的区域(region) 。分配区域的操作被称为预定(reserving) 。
当应用程序预定地址空间区域时,系统会确保区域的起始地址正好是分配粒度 (allocation granularity)的整数倍。分配粒度会根据不同的CPU平台而有所不同。目前,所有的CPU平台都使用相同的分配粒度,大小为64KB—也就是系统会把分配请求取整到64KB的整数倍。
当应用程序预定地址空间的一块区域时,系统会确保区域的起始地址正好是系统页面 大小的整数倍。页面是一个内存单元,系统通过它来管理内存。与分配粒度相似,页面大小会根据不同的CPU而有所不同。x86和x64系统使用的页面大小为4KB,IA-64系统使用的页面大小为8KB。
(即当我们预定地址空间时,分配粒度影响我们的起始地址,因为起始地址必须整除分配粒度。页面大小影响我们预定的大小,大于等于我们预定的大小,因为要是页面大小的整数倍。)
虽然系统规定应用程序在预定地址空间区域时起始地址必须是分配粒度的整数倍,但系统自己却不存在这样的限制。非常有可能出现的情况是,系统预定的区域的起始地址并非64KB的整数倍,但是预定的区域仍然必须是CPU页面大小的整数倍。
当程序不再需要访问所预定的地址空间区域时,应该释放该区域。通过调用VirtualFree函数来完成。
4.给区域调拨物理存储器
为了使用所预定的地址空间区域,我们还必须分配物理存储器,并将存储器映射到所预定的区域。这个过程称为调拨(committing)物理存储器。物理存储器始终都以页面为单位来调拨。我们通过调用VirtualAlloc函数来讲物理存储器调拨给所预定的区域。
当程序不再需要访问所预定区域中已调拨的物理存储器时,应该释放物理存储器。这个过程称为撤销调拨(decommitting)物理存储器,通过调用VirtualFree函数来完成。
( VirtualAlloc, VirtualFree具体使用在以后章节具体讨论 )
说明:预定只是在虚拟地址空间中预定区域,这时并未为该区域指定物理地址空间。通过调拨操作,我们将之前预定的虚拟地址空间绑定到特定的物理地址空间。
5、物理存储器和页交换文件
在老式的操作系统中,物理存储器被认为是极其中的内存的总量。当今的操作系统能让磁盘空间看起来像内存一样。磁盘上的文件一般被称为页交换文件 (paging file),其中包含虚拟内存,可供任何进程使用。
为了能够使用虚拟内存,操作系统需要CPU的大力协助。当线程试图访问存储器中的一个字节时,CPU必须知道该字节是在内存中还是在磁盘上。如果一台机器 准备了1GB的内存,硬盘上还有1GB的也交换文件,那么有用程序会认为可用内存的总量为2GB。当然,这台机器实际上并没有准备2GB的内存。实际上, 是操作系统与CPU分工协作,把内存中的一部分保存到也交换文件中,并在应用程序需要的时候再将页交换文件中的对应部分载入内存。因此,使用也交换文件可 以增大应用程序可用内存的总量。最好把物理存储器看成是保存在磁盘上的也交换文件中的数据。
当一个线程试图访问所属进程的地址空间中的一块数据时,有可能会出现两种情况。图1显示了经简化后的流程:
图1:把虚拟地址转换为物理存储器地址
系统需要在内存和也交换文件之间复制页面的频率越高,硬盘颠簸(thrash)得越厉害,系统运行得也越慢。
要让计算机跑的快,最好是增加内存。
不在页交换文件 中维护的物理存储器:
如 果每次运行一个程序时,系统都必须为该进程的代码和数据预定地址空间区域,为这些区域调拨物理存储器,然后把硬盘上的程序文件中的代码和数据复制到页交换 文件中已调拨的物理存储器中去。那么载入一个程序并让它运行起来会花费很长的时间。事实上,系统并不会执行刚才所说的这些操作。当用户要求执行一个应用程序时,系统会打开该应用程序对应的.exe文件并计算出应用程序的代码和数据的大小。然后系统会预定一块地址空间,并注明与该区域相关联的物理存储器就是.exe文件本身。 是的,系统并没有从页交换文件中分配空间,而是将.exe文件的实际内容用作程序预定的地址空间区域。这样一来,不但载入程序非常快,而且页交换文件也可以保持一个合理的大小。
当把一个程序位于磁盘上的文件映像(即一个.exe或DLL文件)用作地址空间区域对应的物理存储器时,我们称这个文件映像为内存映像文件 (memory mapped file)。当载入一个.exe或DLL时,系统会自动预定地址空间区域并把文件映像映射到该区域。
6.页面保护属性
我们可以给每个已分配的物理存储页指定不同的页面保护属性。表2列出了所有页面保护属性:
表2:内存页面保护属性
保护属性
描述
PAGE_NOACCESS
试图读取页面、写入页面或执行页面中的代码将引发访问违规。
PAGE_READONLY
试图写入页面或执行页面中的代码将引发访问违规。
PAGE_READWRITE
试图执行页面中的代码将引发访问违规。
PAGE_EXECUTE
试图读取页面或写入页面将引发访问违规。
PAGE_EXECUTE_READ
试图写入页面将引发访问违规。
PAGE_EXECUTE_READWRITE
对页面执行任何操作都不会引发访问违规
PAGE_WRITECOPY
试图执行页面中的代码将引发访问违规。试图写入页面将使系统为进程
单独创建一份该页面的私有副本(以页交换文件为后备存储器)
PAGE_EXECUTE_WRITECOPY
对页面执行任何操作都不会引发访问违规。试图写入页面将使系统为
进程单独创建一份该页面的私有副本( 以页交换文件为后备存储器 )
写时复制:
PAGE_WRITECOPY 和 PAGE_EXECUTE_WRITECOPY 存在的目的是为了节省内存和页交换文件的使用。 Windows 支持一种机制,允许两个或两个以上的进程共享同一块存储器。让所有的应用程序共享系统的存储页极大地提升了系统的性能,但另一方面,这也要求所有的应用程 序实例只能读取其中的数据或是执行其中的代码。如果某个应用程序实例修改并写入一个存储页,那么这等于是修改了其它实例正在使用的存储页,最终将导致混 乱。
为了避免此类混乱的发生,操作系统会给共享的存储页指定写时复制属性 。当系统把一个.exe或.dll映射到一个地址空间的时候,系统会计算有多少页面是可写的。(通常,包含代码的页面被标记为 PAGE_EXECUTE_WRITECOPY, 而包含数据的页面被标记为 PAGE_WRITECOPY )
具体通过两个图说明:
图2:修改数据前
图3:修改数据后
7.地址空间映射实例
表3:运行在32位x86版本的Windows上的一个地址空间映射的实例
基地址
类型
大小
块数
保护属性
描述
00000000
Free
65536
00010000
Mapped
65536
1
-RW-
00020000
Private
4096
1
-RW-
00021000
Free
61440
00030000
Private
1048576
3
-RW-
Thread Stack
00130000
Mapped
16384
1
-R--
00134000
Free
49152
00140000
Mapped
12288
1
-R--
00143000
Free
53248
00150000
Mapped
819200
4
-R--
00218000
Free
32768
00220000
Mapped
1060864
1
-R--
00323000
Free
53248
00330000
Private
4096
1
-RW-
00331000
Free
61440
00340000
Mapped
20480
1
-RWC
/Device/HarddiskVolume1/Windows/System32/en-US/user32.dll.mui
00345000
Free
45056
00350000
Mapped
8192
1
-R--
00352000
Free
57344
00360000
Mapped
4096
1
-RW-
00361000
Free
61440
00370000
Mapped
8192
1
-R--
00372000
Free
450560
003E0000
Private
65536
2
-RW-
003F0000
Free
65536
00400000
Image
126976
7
ERWC
C:/Apps/14 VMMap.exe
0041F000
Free
4096
00420000
Mapped
720896
1
-R--
004D0000
Free
458752
00540000
Private
65536
2
-RW-
00550000
Free
196608
00580000
Private
65536
2
-RW-
00590000
Free
196608
005C0000
Private
65536
2
-RW-
005D0000
Free
262144
00610000
Private
1048576
2
-RW-
00710000
Mapped
3661824
1
-R--
/Device/HarddiskVolume1/Windows/System32/locale.nls
00A8E000
Free
8192
00A90000
Mapped
3145728
2
-R--
00D90000
Mapped
3661824
1
-R--
/Device/HarddiskVolume1/Windows/System32/locale.nls
0110E000
Free
8192
01110000
Private
1048576
2
-RW-
01210000
Private
524288
2
-RW-
01290000
Free
65536
012A0000
Private
262144
2
-RW-
012E0000
Free
1179648
01400000
Mapped
2097152
1
-R--
01600000
Mapped
4194304
1
-R--
01A00000
Free
1900544
01BD0000
Private
65536
2
-RW-
01BE0000
Mapped
4194304
1
-R--
01FE0000
Free
235012096
739B0000
Image
634880
9
ERWC
C:/Windows/WinSxS/x86_microsoft.vc80.crt_1fc8b3b9a1e18e3b_8.0.50727.
312_none_10b2ee7b9bffc2c7/MSVCR80.dll
73A4B000
Free
24072192
75140000
Image
1654784
7
ERWC
C:/Windows/WinSxS/x86_microsoft.windows.common-controls_6595b64144ccf1df_6.0.6000.16386_none_5d07289e07e1d100/ comctl32.dll
752D4000
Free
1490944
75440000
Image
258048
5
ERWC
C:/Windows/system32/uxtheme.dll
7547F000
Free
15208448
76300000
Image
28672
4
ERWC
C:/Windows/system32/PSAPI.dll
76307000
Free
626688
763A0000
Image
512000
7
ERWC
C:/Windows/system32/USP10.dll
7641D000
Free
12288
76420000
Image
307200
5
ERWC
C:/Windows/system32/GDI32.dll
7646B000
Free
20480
76470000
Image
36864
4
ERWC
C:/Windows/system32/LPK.dll
76479000
Free
552960
76500000
Image
348160
4
ERWC
C:/Windows/system32/SHLWAPI.dll
76555000
Free
1880064
76720000
Image
696320
7
ERWC
C:/Windows/system32/msvcrt.dll
767CA000
Free
24576
767D0000
Image
122880
4
ERWC
C:/Windows/system32/IMM32.dll
767EE000
Free
8192
767F0000
Image
647168
5
ERWC
C:/Windows/system32/USER32.dll
7688E000
Free
8192
76890000
Image
815104
4
ERWC
C:/Windows/system32/MSCTF.dll
76957000
Free
36864
76960000
Image
573440
4
ERWC
C:/Windows/system32/OLEAUT32.dll
769EC000
Free
868352
76AC0000
Image
798720
4
ERWC
C:/Windows/system32/RPCRT4.dll
76B83000
Free
2215936
76DA0000
Image
884736
5
ERWC
C:/Windows/system32/kernel32.dll
76E78000
Free
32768
76E80000
Image
1327104
5
ERWC
C:/Windows/system32/ole32.dll
76FC4000
Free
11649024
77AE0000
Image
1171456
9
ERWC
C:/Windows/system32/ntdll.dll
77BFE000
Free
8192
77C00000
Image
782336
7
ERWC
C:/Windows/system32/ADVAPI32.dll
77CBF000
Free
128126976
7F6F0000
Mapped
1048576
2
-R--
7F7F0000
Free
8126464
7FFB0000
Mapped
143360
1
-R--
7FFD3000
Free
4096
7FFD4000
Private
4096
1
-RW-
7FFD5000
Free
40960
7FFDF000
Private
4096
1
-RW-
7FFE0000
Private
65536
2
-R--
8.数据对齐的重要性
相 对于操作系统的内存体系结构,数据对齐更多的是CPU体系结构的一部分。只有当访问已对齐的数据时,CPU的执行效率才最高。把数据的地址模除数据的大 小,如果结果为0,那么数据就是对齐的。如果CPU要访问的数据没有对齐,那么会有两种可能。第一种可能是CPU会引发一个异常,另一种可能是CPU会通 过多次访问已对齐的内存,来取得整个错位数据。
x86系统,一旦程序试图访问错位数据,CPU会自动执行必要的操作来访问错位数据。为了得到最佳的应用程序性能,我们在编写代码时应该尽量让数据对齐。因为与访问已对齐的数据相比,系统在最好的情况下页需要花两倍的时间来访问错位数据,而且情况可能会更糟。
/***************************************************
如何理解虚拟内存
为什么不直接使用物理内存
虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。
现代所有用于一般应用的操作系统都对普通的应用程序使用虚拟内存技术,老一些的操作系统,如DOS和1980年代的Windows,或者那些1960年代的大型机,一般都没有虚拟内存的功能
——维基百科
读完上面的信息,我们可以得知,虚拟内存这个概念是后来才提出的,一开始并没有虚拟内存。那个时候的计算机,程序指令所访问的内存地址就是物理内存地址. 也就是不得不把程序的全部装进内存当中,然后运行。物理内存其实就是插在计算机主板内存槽上的实际物理内存,CPU可以直接进行寻址.。物理内存的容量是固定的,但是寻址空间却取决于cpu地址线条数,如32位机,则寻址空间为2^32 = 4G,所以最大支只持4G的寻址空间,即使插了8G的内存条也只能使用4G内存
在这种直接使用物理内存的状态下就会产生一些问题:
- 内存空间利用率的问题
各个进程对内存的使用会导致内存碎片化,当要用malloc分配一块很大的内存空间时,可能会出现虽然有足够多的空闲物理内存,却没有足够大的连续空闲内存这种情况,东一块西一块的内存碎片就被浪费掉了
2. 读写内存的安全性问题
物理内存本身是不限制访问的,任何地址都可以读写,而现代操作系统需要实现不同的页面具有不同的访问权限,例如只读的数据等等
3. 进程间的安全问题
各个进程之间没有独立的地址空间,一个进程由于执行错误指令或是恶意代码都可以直接修改其它进程的数据,甚至修改内核地址空间的数据,这是操作系统所不愿看到的
4. 内存读写的效率问题
当多个进程同时运行,需要分配给进程的内存总和大于实际可用的物理内存时,需要将其他程序暂时拷贝到硬盘当中,然后将新的程序装入内存运行。由于大量的数据频繁装入装出,内存的使用效率会非常低
5. 等等
正因为有上面这些问题,大佬们设计了“虚拟内存”和相关的概念
The concept of virtual memory was first developed by German
physicist
Fritz-Rudolf Güntsch at the
Technische Universität Berlin in 1956 in his doctoral thesis
——维基百科
什么是虚拟内存
关于虚拟内存内部的结构可以参考进程虚拟地址空间的区域划分
每个进程创建加载的时候,会被分配一个大小为4G的连续的虚拟地址空间,虚拟的意思就是,其实这个地址空间时不存在的,仅仅是每个进程“认为”自己拥有4G的内存,而实际上,它用了多少空间,操作系统就在磁盘上划出多少空间给它,等到进程真正运行的时候,需要某些数据并且数据不在物理内存中,才会触发缺页异常,进行数据拷贝
更准确一点的说,系统将虚拟内存分割为称为虚拟页(Virtual Page,VP)的大小固定的块,每个虚拟页的大小为P = 2^p字节,类似地,物理内存被分割为物理页(Physical Page,PP),大小也为P字节(物理页也称为页帧(page frame))。
在任意时刻,虚拟页面都分为互不相交的三种:
- 未分配的:系统还未分配(或者创建)的页。未分配的块没有任何数据和它们相关联,因此也就不占用任何磁盘空间
- 未缓存的:没有缓存在物理存储器中的已分配页
- 缓存的:当前缓存在物理存储器中的已分配页
下图是一个示例:

这个示例展示了一个有8个虚拟页的小虚拟存储器,虚拟页0和3还没有被分配,因此在磁盘上还不存在。虚拟页1、4和6被缓存在物理存储器中。页2、5和7已经被分配了,但是当前并未缓存在主存中
操作系统向进程描述了一个完整的连续的虚拟地址空间供进程使用,但是在物理内存中进程数据的存储采用离散式存储(提高内存利用率),但是其实虚拟内存和物理内存之间的关系并不像上图中那样直接,其中还需要使用页表映射虚拟地址与物理地址的映射关系,并且通过页表实现内存访问控制。这个页表又是何方神圣?
什么是页表
页表是一种特殊的数据结构,存放着各个虚拟页的状态,是否映射,是否缓存.。进程要知道哪些内存地址上的数据在物理内存上,哪些不在,还有在物理内存上的哪里,这就需要用页表来记录。页表的每一个表项分为两部分,第一部分记录此页是否在物理内存上,第二部分记录物理内存页的地址(如果在的话)。当进程访问某个虚拟地址,就会先去看页表,如果发现对应的数据不在物理内存中,则发生缺页异常。
缺页异常的事等下再说,先体会一下虚拟内存究竟是如何通过页表与物理内存联系起来的,再看一个示例:

图中展示了一个页表的基本组织结构,页表就是一个页表条目(Page Table Entry,PTE)的数组,每个PTE由一个有效位(valid bit)和一个地址组成,有效位表明了该虚拟页当前是否存在于物理内存中,如果有效位是1,该PTE中就会存储物理内存中相应的物理页的起始地址。如果有效位是0,且PTE中的地址为null,这表示这个虚拟页还未被分配,而如果有效位是0且PTE中有地址,那么这个地址指向该虚拟页在磁盘上的起始位置
上图的示例展示了一个有8个虚拟页和4个物理页的系统的页表,四个虚拟页(VP1、VP2、VP4和VP7)当前存储于物理内存中,两个页(VP0和VP5)还未被分配(也就是什么都没存的虚拟内存,在磁盘和物理内存中都不存在这个空间),而剩下的页(VP3和VP6)已经被分配了,但是还未缓存进物理内存(也就是存在于磁盘上)
在上面的过程中,CPU读包含在VP1中的一个数据时,地址翻译硬件将虚拟地址作为一个索引找到页表中的PTE 2,然后再从PTE 2中保存的物理地址从真正的物理内存中读到这个数据,在有效位为1的PTE中成功找到对应的物理页就称之为页命中
而当试图访问一个有效位为0,但PTE中又保存了地址的虚拟内存中的数据时(也就是VP3和VP6的情况,数据保存在磁盘中),就是DRAM缓存不命中,一般将这种状况称为缺页异常(page fault)。触发缺页异常后,系统会调用内核中的缺页异常处理程序,该程序会选择一个牺牲页(牺牲页的选择有具体的算法,在这里不做讨论),在此例中就是存放在PP3中的VP4,内核将修改后的VP4重新拷贝回磁盘,并且修改VP4中的页表条目,将有效位改成0,反映出VP4不再存在于物理内存中这一事实。接下来,内核从磁盘拷贝VP3到存储器中的PP3,更新PTE3,随后返回。当异常处理程序返回时,它会重新启动导致缺页的指令,再次从试图访问该虚拟地址开始,这时有效位是1,于是正常页命中,从物理地址中读取内存
其实页表的工作原理也就是虚拟内存的工作原理了,接下来我们再总结一下
虚拟内存的工作原理
当一个进程试图访问虚拟地址空间中的某个数据时,会经历下面两种情况的过程:
- CPU想访问某个虚拟内存地址,找到进程对应的页表中的条目,判断有效位, 如果有效位为1,说明在页表条目中的物理内存地址不为空,根据物理内存地址,访问物理内存中的内容,返回
- CPU想访问某个虚拟内存地址,找到进程对应的页表中的条目,判断有效位,如果有效位为0,但页表条目中还有地址,这个地址是磁盘空间的地址,这时触发缺页异常,系统把物理内存中的一些数据拷贝到磁盘上,腾出所需的空间,并且更新页表。此时重新执行访问之前虚拟内存的指令,就会发现变成了情况1.
总结
虚拟存储器的工作原理是有一些复杂,即使上文中描述的也并不全是最真实的计算机中的工作方式,比如PTE由一个有效位和一个地址字段组成其实是为了便于理解而假设出来的。
但是这种方式成功的解决了上文中提到的直接使用物理内存会出现的问题,比如物理内存中离散式存储,虚拟内存中连续存储解决了物理内存碎片化资源利用率过低的问题;每个进程只能访问自己独立的用户空间而内核空间是共用的解决了进程间的安全问题;缺页异常和选择牺牲页的算法提高了内存读写的效率......
我们应该对虚拟存储器的工作原理有深层次的理解,可以更好的帮助我们理解系统是如何工作的,也可以帮助我们避免在使用malloc这类的管理虚拟存储器的分配程序时遇到的一些错误
/*********************************************************
物理内存,运行内存,虚拟内存有什么区别?
作者:破城
链接:https://www.zhihu.com/question/25659063/answer/722820860
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
物理内存=运行内存
就是指计算机的安装内存“通俗的讲就是内存条的大小”
虚拟内存指的是把硬盘中的一部分空间用来当做内存使用。
虚拟内存在硬盘上存在的是一个文件 PAGEFILE.SYS
虚拟内存可以自己通过操作系统设置虚拟内存的大小。

这个是在WIN7帮助下虚拟内存设置的方式。(机房电脑)
下面是正经解释
为了更好理解我们把正在运行的程序分为三级
第一级命中率最高
第二级命中率中等
第三级命中率最低
这时候我们要引入一个新的名词CPU缓存
这个我们可以在CPU的性能参数中看到单位一般为MB
现在我们捋一下这三个名词
CPU缓存(单位MB 通常在几MB或几十MB)
运行内存(单位GB 通常在8G 16G 32G 等)
虚拟内存(单位MB 通常跟运行内存大小差不多“个人设定”)
他们的运行速度是CPU缓存>运行内存>虚拟内存
CPU缓存的作用:是为了解决CPU跟内存之间数据传输速度不匹配的问题。
虚拟内存的作用:是为了解决计算机在运行较大的程序时内存不足的情况。
那么我们上面说的第一级程序就会放在CPU缓存中以便使本来就不大的缓存发挥更大的作用。
第二级程序就是放在内存中的。
第三级程序就会在虚拟内存中。
其实在内存足够大的时候 虚拟内存存在的意义就不是很大了。另外由于虚拟内存是在硬盘上的,它的速度要比内存慢的多,虚拟内存其实就是为了运行很大的程序的一种妥协的办法,妥协了软件的运行速度。
作者:极致Linux内核
链接:https://www.zhihu.com/question/25659063/answer/2735952833
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
首先,让我们看下虚拟内存:
第一层理解
1.每个进程都有自己独立的4G内存空间,各个进程的内存空间具有类似的结构
2.一个新进程建立的时候,将会建立起自己的内存空间,此进程的数据,代码等从磁盘拷贝到自己的进程空间,哪些数据在哪里,都由进程控制表中的task_struct记录,task_struct中记录中一条链表,记录中内存空间的分配情况,哪些地址有数据,哪些地址无数据,哪些可读,哪些可写,都可以通过这个链表记录
3.每个进程已经分配的内存空间,都与对应的磁盘空间映射

问题:
计算机明明没有那么多内存(n个进程的话就需要n*4G)内存
建立一个进程,就要把磁盘上的程序文件拷贝到进程对应的内存中去,对于一个程序对应的多个进程这种情况,浪费内存!
第二层理解
1.每个进程的4G内存空间只是虚拟内存空间,每次访问内存空间的某个地址,都需要把地址翻译为实际物理内存地址
2.所有进程共享同一物理内存,每个进程只把自己目前需要的虚拟内存空间映射并存储到物理内存上。
3.进程要知道哪些内存地址上的数据在物理内存上,哪些不在,还有在物理内存上的哪里,需要用页表来记录
4.页表的每一个表项分两部分,第一部分记录此页是否在物理内存上,第二部分记录物理内存页的地址(如果在的话)
5.当进程访问某个虚拟地址,去看页表,如果发现对应的数据不在物理内存中,则缺页异常
6.缺页异常的处理过程,就是把进程需要的数据从磁盘上拷贝到物理内存中,如果内存已经满了,没有空地方了,那就找一个页覆盖,当然如果被覆盖的页曾经被修改过,需要将此页写回磁盘
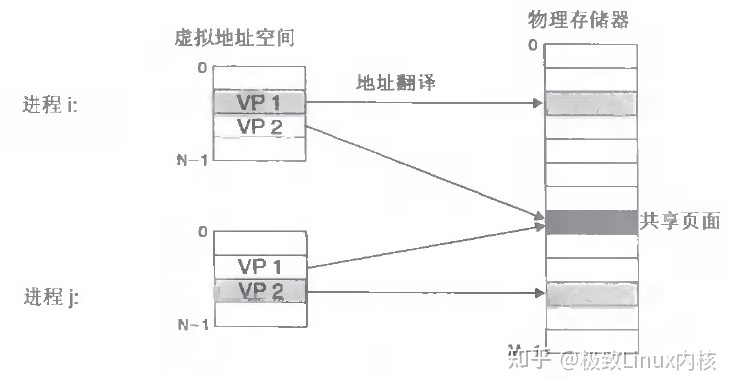
总结:
优点:
1.既然每个进程的内存空间都是一致而且固定的,所以链接器在链接可执行文件时,可以设定内存地址,而不用去管这些数据最终实际的内存地址,这是有独立内存空间的好处
2.当不同的进程使用同样的代码时,比如库文件中的代码,物理内存中可以只存储一份这样的代码,不同的进程只需要把自己的虚拟内存映射过去就可以了,节省内存
3.在程序需要分配连续的内存空间的时候,只需要在虚拟内存空间分配连续空间,而不需要实际物理内存的连续空间,可以利用碎片。
另外,事实上,在每个进程创建加载时,内核只是为进程“创建”了虚拟内存的布局,具体就是初始化进程控制表中内存相关的链表,实际上并不立即就把虚拟内存对应位置的程序数据和代码(比如.text .data段)拷贝到物理内存中,只是建立好虚拟内存和磁盘文件之间的映射就好(叫做存储器映射),等到运行到对应的程序时,才会通过缺页异常,来拷贝数据。还有进程运行过程中,要动态分配内存,比如malloc时,也只是分配了虚拟内存,即为这块虚拟内存对应的页表项做相应设置,当进程真正访问到此数据时,才引发缺页异常。
补充理解:
虚拟存储器涉及三个概念: 虚拟存储空间,磁盘空间,内存空间

可以认为虚拟空间都被映射到了磁盘空间中,(事实上也是按需要映射到磁盘空间上,通过mmap),并且由页表记录映射位置,当访问到某个地址的时候,通过页表中的有效位,可以得知此数据是否在内存中,如果不是,则通过缺页异常,将磁盘对应的数据拷贝到内存中,如果没有空闲内存,则选择牺牲页面,替换其他页面。
mmap是用来建立从虚拟空间到磁盘空间的映射的,可以将一个虚拟空间地址映射到一个磁盘文件上,当不设置这个地址时,则由系统自动设置,函数返回对应的内存地址(虚拟地址),当访问这个地址的时候,就需要把磁盘上的内容拷贝到内存了,然后就可以读或者写,最后通过manmap可以将内存上的数据换回到磁盘,也就是解除虚拟空间和内存空间的映射,这也是一种读写磁盘文件的方法,也是一种进程共享数据的方法 共享内存
接下来我们来讨论下物理内存:
在内核态申请内存比在用户态申请内存要更为直接,它没有采用用户态那种延迟分配内存技术。内核认为一旦有内核函数申请内存,那么就必须立刻满足该申请内存的请求,并且这个请求一定是正确合理的。相反,对于用户态申请内存的请求,内核总是尽量延后分配物理内存,用户进程总是先获得一个虚拟内存区的使用权,最终通过缺页异常获得一块真正的物理内存。
1.物理内存的内核映射
IA32架构中内核虚拟地址空间只有1GB大小(从3GB到4GB),因此可以直接将1GB大小的物理内存(即常规内存)映射到内核地址空间,但超出1GB大小的物理内存(即高端内存)就不能映射到内核空间。为此,内核采取了下面的方法使得内核可以使用所有的物理内存。
1).高端内存不能全部映射到内核空间,也就是说这些物理内存没有对应的线性地址。不过,内核为每个物理页框都分配了对应的页框描述符,所有的页框描述符都保存在mem_map数组中,因此每个页框描述符的线性地址都是固定存在的。内核此时可以使用alloc_pages()和alloc_page()来分配高端内存,因为这些函数返回页框描述符的线性地址。
2).内核地址空间的后128MB专门用于映射高端内存,否则,没有线性地址的高端内存不能被内核所访问。这些高端内存的内核映射显然是暂时映射的,否则也只能映射128MB的高端内存。当内核需要访问高端内存时就临时在这个区域进行地址映射,使用完毕之后再用来进行其他高端内存的映射。
由于要进行高端内存的内核映射,因此直接能够映射的物理内存大小只有896MB,该值保存在high_memory中。内核地址空间的线性地址区间如下图所示:

从图中可以看出,内核采用了三种机制将高端内存映射到内核空间:永久内核映射,固定映射和vmalloc机制。
2.物理内存管理机制
基于物理内存在内核空间中的映射原理,物理内存的管理方式也有所不同。内核中物理内存的管理机制主要有伙伴算法,slab高速缓存和vmalloc机制。其中伙伴算法和slab高速缓存都在物理内存映射区分配物理内存,而vmalloc机制则在高端内存映射区分配物理内存。
伙伴算法
伙伴算法负责大块连续物理内存的分配和释放,以页框为基本单位。该机制可以避免外部碎片。
per-CPU页框高速缓存
内核经常请求和释放单个页框,该缓存包含预先分配的页框,用于满足本地CPU发出的单一页框请求。
slab缓存
slab缓存负责小块物理内存的分配,并且它也作为高速缓存,主要针对内核中经常分配并释放的对象。
vmalloc机制
vmalloc机制使得内核通过连续的线性地址来访问非连续的物理页框,这样可以最大限度的使用高端物理内存。
3.物理内存的分配
内核发出内存申请的请求时,根据内核函数调用接口将启用不同的内存分配器。
3.1 分区页框分配器
分区页框分配器 (zoned page frame allocator) ,处理对连续页框的内存分配请求。分区页框管理器分为两大部分:前端的管理区分配器和伙伴系统,如下图:

管理区分配器负责搜索一个能满足请求页框块大小的管理区。在每个管理区中,具体的页框分配工作由伙伴系统负责。为了达到更好的系统性能,单个页框的申请工作直接通过per-CPU页框高速缓存完成。
该分配器通过几个函数和宏来请求页框,它们之间的封装关系如下图所示。

这些函数和宏将核心的分配函数__alloc_pages_nodemask()封装,形成满足不同分配需求的分配函数。其中,alloc_pages()系列函数返回物理内存首页框描述符,__get_free_pages()系列函数返回内存的线性地址。
3.2 slab分配器
slab 分配器最初是为了解决物理内存的内部碎片而提出的,它将内核中常用的数据结构看做对象。slab分配器为每一种对象建立高速缓存。内核对该对象的分配和释放均是在这块高速缓存中操作。一种对象的slab分配器结构图如下:

可以看到每种对象的高速缓存是由若干个slab组成,每个slab是由若干个页框组成的。虽然slab分配器可以分配比单个页框更小的内存块,但它所需的所有内存都是通过伙伴算法分配的。
slab高速缓存分专用缓存和通用缓存。专用缓存是对特定的对象,比如为内存描述符创建高速缓存。通用缓存则是针对一般情况,适合分配任意大小的物理内存,其接口即为kmalloc()。
3.3 非连续内存区内存的分配
内核通过vmalloc()来申请非连续的物理内存,若申请成功,该函数返回连续内存区的起始地址,否则,返回NULL。vmalloc()和kmalloc()申请的内存有所不同,kmalloc()所申请内存的线性地址与物理地址都是连续的,而vmalloc()所申请的内存线性地址连续而物理地址则是离散的,两个地址之间通过内核页表进行映射。
vmalloc()的工作方式理解起来很简单:
1).寻找一个新的连续线性地址空间;
2).依次分配一组非连续的页框;
3).为线性地址空间和非连续页框建立映射关系,即修改内核页表;
vmalloc()的内存分配原理与用户态的内存分配相似,都是通过连续的虚拟内存来访问离散的物理内存,并且虚拟地址和物理地址之间是通过页表进行连接的,通过这种方式可以有效的使用物理内存。但是应该注意的是,vmalloc()申请物理内存时是立即分配的,因为内核认为这种内存分配请求是正当而且紧急的;相反,用户态有内存请求时,内核总是尽可能的延后,毕竟用户态跟内核态不在一个特权级。
/*********************************************************************************
一、物理和虚拟寻址
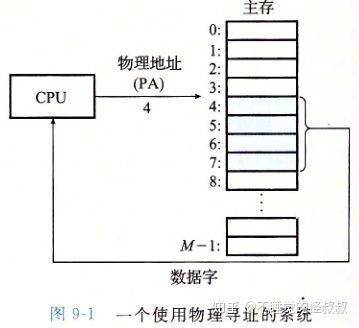
早期的PC使用物理寻址,现代处理器使用虚拟寻址。
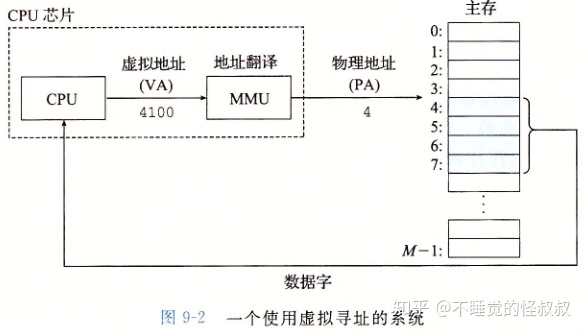
CPU芯片上叫做内存管理单元(MMU)的专用硬件,利用存放在主存中的查询表来动态翻译虚拟地址,该表的内容由操作系统管理。
二、地址空间
地址空间是一个非负整数地址的有序集合:
- 虚拟地址空间
- 物理地址空间 —— 对应于系统中实际拥有的DRAM容量
主存中的每字节都有一个选自虚拟地址空间的虚拟地址和选自物理地址空间的物理地址。
三、虚拟内存
虚拟内存被组织为一个由存放在磁盘上的N个连续的字节大小的单元组成的数组。每字节都有一个唯一的虚拟地址。
VM系统将虚拟内存(磁盘)分割为虚拟页(Virtual Page, VP),物理内存(DRAM)被分割为物理页(Physical Page, PP)。
虚拟页可以分为:
- 未分配的 —— 还没有和磁盘中的某个磁盘空间建立对应关系
- 缓存的 —— 虚拟页中的数据已缓存到物理内存
- 未缓存的 —— 虚拟页中的数据还未缓存到物理内存
3.1、DRAM缓存的组织结构
由于访问磁盘的开销很大(磁盘比DRAM慢大约100000多倍),所以DRAM缓存不命中的开销很大。所以虚拟内存的特征:
- 虚拟页往往很大,通常是4KB~2MB。
- DRAM缓存是全关联的,即任何虚拟页都可以放置在任何的物理页中。
- DRAM缓存不会直写回磁盘,它会尽可能将写回磁盘的操作延迟。
3.2、页表
操作系统软件、MMU(内存管理单元)中的地址翻译硬件和存放在物理内存中的页表联合提供虚拟内存的逻辑操作机制(是否页命中、如何替换牺牲页等等)。
页表将虚拟页映射到物理页,每次地址翻译硬件将一个虚拟地址转换为物理地址时,都会读取页表。
页表就是一个页表条目(Page Table Entry, PTE)的数组。
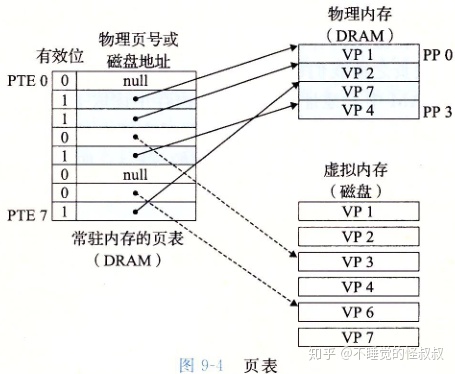
3.3、页命中
地址翻译硬件将虚拟地址作为一个索引来定位PTE,并根据有效位判断是否页命中(虚拟页的数据是否缓存到物理内存中)。如果页命中则从相应PTE中读取物理内存地址。
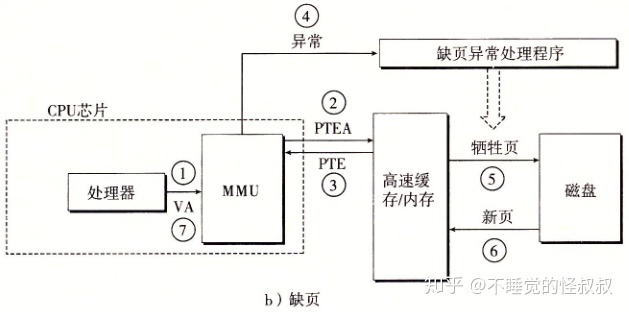
3.4、缺页
页不命中称为缺页,此时会触发一个缺页异常,缺页异常调用内核中的缺页异常处理程序。(异常控制流机制-故障)
异常处理程序将对应的虚拟页复制到物理内存中的牺牲页(按需页面调度),随后重新启动导致缺页的指令(返回到当前指令),此时页命中。
3.5、分配页面
调用malloc产生的底层操作是在磁盘中分配虚拟页,并更新页表中对应的PTE。
3.6、局部性
局部性原则保证了在任意时刻,程序将趋向于在一个较小的活动页面集合上工作,这个集合叫做工作集。
如果工作集的大小超出了物理内存的大小,那么这时页面将不断地自DRAM换进换出(抖动),导致程序性能下降。
四、虚拟内存作为内存管理的工具
操作系统为每个进程提供了一个独立的页表,以此来为每个进程提供一个独立的虚拟地址空间。因此每个进程都使用相同的内存映像格式。

多个虚拟页面可以映射到同一个共享物理页面上。
VM简化了链接和加载、代码和数据共享,以及应用程序的内存分配:
- 简化链接 —— 由于地址空间的一致性,所以允许链接器生成完全链接的可执行文件,这些可执行文件是独立于物理内存中代码和数据的最终位置的。
- 简化加载 —— 使得容易向内存中加载可执行文件和共享对象文件。
- 简化共享 —— 操作系统通过将不同进程中适当的虚拟页面映射到相同的物理页面,从而安排多个进程共享这部分代码的一个副本,而不是在每个进程中都包括单独的内核和C标准库的副本。
- 简化内存分配 —— 操作系统没有必要分配k个连续的物理页面,页面可以随机地分散在物理内存中。
五、虚拟内存作为内存保护的工具
用户进程对虚拟地址空间中的数据读写有权限约束:
- 不能修改只读代码段
- 不能读、写内核的代码
- 不能读、写其他进程的私有内存
- 不能修改与其他进程共享的虚拟页面,除非所有共享者显式地允许它这么做(进程间通信)
内部进制是通过在PTE上添加额外的许可位来实现读、写的权限约束。

- SUP位表示进程是否必须运行在内核(超级用户)模式下才能访问该页。
- READ位和WRITE位控制对页面的读和写访问。
六、地址翻译

地址翻译是一个N元素的虚拟地址空间(VAS)中的元素和一个M元素的物理地址空间(PAS)中元素之间的映射:


页表基址寄存器(Page Table Base Register,PTBR)指向当前页表。
通过虚拟页号(Virtual Page Number,VPN)找寻对应的物理页号(Physical Page Number,PPN)。
虚拟页面偏移(Virtual Page Offset,VPO)和物理页面偏移(Physical Page Offset,PPO)是相同的。
物理地址是由物理页号和虚拟页面偏移串联起来得到的。
1)页面命中时,执行的步骤(完全由硬件来处理):
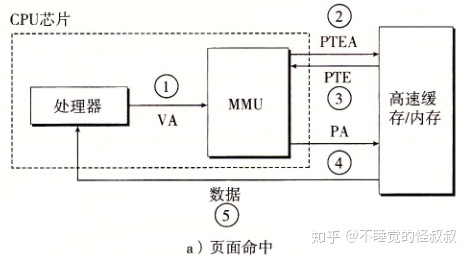
2)缺页时,执行的步骤(硬件和操作系统内核协作完成):
6.1、结合高速缓存和虚拟内存
大多数系统使用物理寻址来访问SRAM高速缓存。
高速缓存无需处理保护问题,因为访问权限的检查是地址翻译过程的一部分。

6.2、利用TLB加速地址翻译
MMU中包括了一个关于PTE的小的缓存,称为翻译后备缓冲器(Translation Lookaside Buffer, TLB)。
TLB是一个用于缓存PTE的设备,其中每一行都保存着一个由单个PTE组成的块。

从虚拟页号中提取用于与TLB构成映射的信息:
- TLB索引(TLBI) —— 组选择或者集合选择,有 T=2t 个组或集合。
- TLB标记(TLBT) —— 行匹配
在TLB中命中PTE和没有命中PTE时执行的步骤:

6.3、多级页表
使用一个单独的页表来进行地址翻译,会导致页表非常大,因此通常使用层次结构的页表(多级页表)。
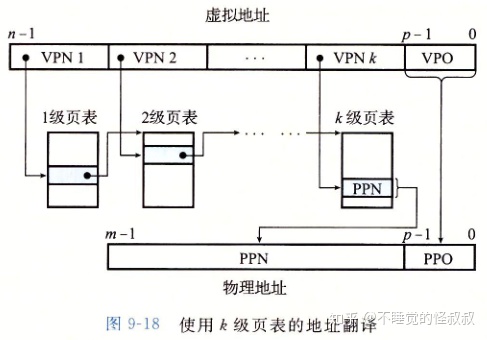
多级页表相当于树结构,它从两个方面减少了内存要求:
- 如果一级页表中的一个PTE是空的,相应的二级页表就不会存在
- 只有一级页表才需要总是在主存中。虚拟内存系统可以在需要时创建、页面调入或调出二级页表。
通过将不同层次上页表的PTE缓存起来,使得带多级页表的地址翻译并不比单级页表慢很多。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)