转载自https://www.leiphone.com/news/201807/RQ4sBWYqLkGV4ZAW.html,有删节
【嵌牛导读】:在本文中,我们将逐步分解卷积操作的原理,将他与标准的全连接网络联系起来,并且探索如何构建一个强大的视觉层次,使其成为高性能的图像特征提取器。
【嵌牛鼻子】: 全连接网络 图像特征提取器
【嵌牛提问】:卷积操作是如何与全连接网络联系起来的?如何通过卷积操作构建一个图像特征提取器?
【嵌牛正文】:
近几年随着功能强大的深度学习框架的出现,在深度学习模型中搭建卷积神经网络变得十分容易,甚至只需要一行代码就可以完成。
但是理解卷积,特别是对第一次接触卷积神经网络的人来说,经常会对诸如卷积核、滤波器、通道等概念和他们的堆叠架构感到困惑。然而卷积是强大且高度可扩展的概念,在本文中,我们将逐步分解卷积操作的原理,将他与标准的全连接网络联系起来,并且探索如何构建一个强大的视觉层次,使其成为高性能的图像特征提取器。
2 维卷积:操作
2 维卷积是一个相当简单的操作:从卷积核开始,这是一个小的权值矩阵。这个卷积核在 2 维输入数据上「滑动」,对当前输入的部分元素进行矩阵乘法,然后将结果汇为单个输出像素。

一个标准的卷积 [1]
卷积核重复这个过程知道遍历了整张图片,将一个二维矩阵转换为另一个二维矩阵。输出特征实质上是在输入数据相同位置上的加权和(权值是卷积核本身的值)
输入数据是否落入这个「大致相似区域」,直接决定了数据经过卷积核后的输出。这意味着卷积核的尺寸直接决定了生成新的特征时汇合了多少(或几个)输入特征。
这与全连接层完全相反。在上面的例子中,我们的输入特征为 5*5=25,输出数据为 3*3=9. 如果我们使用标准的全连接层,就会产生一个 25*9=225 个参数的权值矩阵,每个输出都是所有输入数据的加权求和。卷积操作允许我们只用 9 个参数来实现这个变换,每个输出特性不用「查看」每个输入特征,而是只是「查看」来自大致相同位置的输入特征。请注意这一点,因为这对我们后面的讨论至关重要。
一些常用的技术
在我们继续介绍卷积神经网络之前,介绍两种卷积层中常用的技术:Padding 和 Strides
Padding:如果你看到上面的动画,那么会注意到在卷积核滑动的过程中,边缘基本会被「裁剪」掉,将 5*5 特征矩阵转换为 3*3 的特征矩阵。边缘上的像素永远不在卷积核的中心,因为内核没有任何东西可以扩展到边缘之外。这并不理想,因为我们经常希望输出的尺寸等于输入。

一些 padding 操作 [1]
Padding 做了一些非常机智的办法来解决这个问题:用额外的「假」像素(通常值为 0,因此经常使用的术语「零填充」)填充边缘。这样,在滑动时的卷积核可以允许原始边缘像素位于其中心,同时延伸到边缘之外的假像素,从而产生与输入相同大小的输出。
Striding:运行卷积层时,我们通常希望输出的尺寸是比输入更低。这在卷积神经网络中是常见的,在增加信道数量的同时空间尺寸减小。其中一种方法是使用池化层(例如,取每 2×2 网格的平均值/最大值将空间维度减半)。还有一种方法是使用 Striding:

一个步长为 2 的卷积操作 [1]
Stride 的想法是改变卷积核的移动步长跳过一些像素。Stride 是 1 表示卷积核滑过每一个相距是 1 的像素,是最基本的单步滑动,作为标准卷积模式。Stride 是 2 表示卷积核的移动步长是 2,跳过相邻像素,图像缩小为原来的 1/2。Stride 是 3 表示卷积核的移动步长是 3,跳过 2 个相邻像素,图像缩小为原来的 1/3
越来越多的新网络结构,比如 ResNet,已经完全抛弃了池化层。当需要对图像进行缩小时会采用 Stride 方法。
多通道版本
当然,上图仅涉及具有单个输入通道的图像。实际上,大多数输入图像都是 3 通道的,通道数只会增加你的网络深度。通常会将图像的通道视作一个整体,强调其整体的一面而不关注各自的差异。

大部分时候,我们都处理 RBG 的三通道图像 (Credit: Andre Mouton)

滤波器:卷积核的集合
这两个术语之间有着本质的区别:仅在 1 通道的情况下,滤波器和内核这两个术语等价,在一般情况下,它们是不同的。每个过滤器实际上是卷积核的集合,图层的每个输入通道都有一个卷积核,并且是唯一的。
卷积层中的每个滤波器都只输出一个通道,他们是这样实现的:
滤波器的每个卷积核在各自的输入通道上「滑动」,产生各自的计算结果。一些内核可能比其他内核具有更大的权重,以便比某些内核更强调某些输入通道(例如,滤波器的红色通道卷积核可能比其他通道的卷积核有更大的权重,因此,对红色通道特征的反应要强于其他通道)。
然后将每个通道处理的结果汇在一起形成一个通道。滤波器的卷积核各自产生一个对应通道的输出,最后整个滤波器产生一个总的输出通道。


最后一个术语:偏置。偏置在这里的作用是对每个输出滤波器增加偏置项以便产生最终输出通道。

其他数量滤波器的生成都和单滤波器相同:每个滤波器使用不同的卷积核集合和具有上述过程的标量偏差项来处理输入数据,最终产生一个输出通道。然后将它们连接在一起以产生总输出,其中输出通道的数量是过滤器的数量。在输出数据送入另一个卷积层之前,通常还要应用非线性激活函数。重复上述操作即可完成网络的搭建。
2 维卷积:直觉
卷积仍然是线性变换
即使有了卷积层的机制,仍然很难将它与标准的前馈网络联系起来,而且它仍然不能解释为什么卷积会扩展到图像数据处理领域,并且在这方面表现的很好。
假设我们有一个 4×4 的输入,我们需要将其转换成 2×2 的阵列。如果我们使用前馈网络,我们会先将 4×4 的输入转换成长度为 16 的向量,然后输入一个拥有 16 个输入和 4 个输出的密集连接层。可以为这一层想象一个权值矩阵 W :

总而言之,有 64 个参数。
尽管卷积核运算一开始看起来很奇怪,但它仍然是一个线性变换,有一个等价的变换矩阵。如果我们将大小为 3 的核 K 应用于变换后的 4×4 输入,来得到 2×2 的输出,等价的变换矩阵将是:

这里有 9 个参数
(注意:虽然上面的矩阵是一个等价的变换矩阵,但实际操作通常是作为一个非常不同的矩阵乘法来实现的 [2])
卷积,作为一个整体,仍然是一个线性变换,但同时,这也是一种与众不同的变换。一个有 64 个元素的矩阵,只有 9 个参数被重复使用。每个输出节点只能看到特定输入的数量(核内部的输入)。与其他输入没有任何交互,因为权值被设置为 0。
将卷积操作看作是权值矩阵的先验是很有用的。在这篇文章中,我预先定义了网络参数。例如,当你使用预先训练的模型做图像分类时,前提是使用预先训练的网络参数,作为密集链接层的一个特征提取器。
从这层意义上说,有一个直觉就是为什么两个都很有效呢(与他们的替代者比较)。迁移学习的效率比随机初始化高出多个数量级,因为你只需要优化最终全连接层的参数,这意味着您可以拥有出色的性能,每个类只有几十个图像。
这里,你不需要优化所有 64 个参数,因为我们将其中的大部分设置为 0(而且始终保持这个值),剩余的转化成共享参数,这将导致实际上只需要优化 9 个参数。这个效率很重要,当从 MNIST 的 784 个输入转换成实际的 224×224×3 个图像时,将会有 150000 个输入。密集层视图将输入减半为 75000 个,这仍然需要 100 亿个参数。相比而言,ResNet-50 总共只有 2 千 500 万个参数。
所以,将一些参数固定为 0,邦定参数提高效率,但与迁移学习不同,在迁移学习中,我们知道先验是不是好的,因为它依赖于大量的图像,我们如何知道这个的好坏呢?
答案就在特征组合中,前面的参数是要学习的参数。
局部性
在这片文章的开始,我们讨论了以下问题:
卷积核只从一个小的局部区域组合像素来形成输出。也就是说,输出特性只从一个小的局部区域「看到」输入特性。
卷积核被应用于整个图像,以产生输出矩阵。
所以随着反向传播从网络的分类节点一路过来,卷积核拥有一个有趣的任务,从局部输入中学习权值,生成特征。此外,因为卷积核本身被应用于整个图像,卷积核学习的特征必须足够通用,可以来自于图像的任何部分。
如果这是任何其他种类的数据,例如,APP 安装的分类数据,这将会是一场灾难,因为你的应用程序安装数量和应用类型是相邻的,并不意味着它们有任何与应用安装日期和使用时间一样常见的「本地的、共享的特性」。当然,它们可能有一个可被发现的潜在高层次的特征(例如。人们最需要的是哪些应用程序),但这并没有给我们足够的理由相信前两个的参数和后两个的参数完全相同。这四种可能是任意的(一致的)顺序,并且仍然有效!
然而,像素总是以一致的顺序出现,而且附近的像素互相影响。例如,如果某像素附近所有像素都是红色的,那么该像素极有可能也是红色的。如果有偏差,这是一个有趣的反常现象,可以转化成一个特征,所有这些偏差可以通过与周围像素的比较检测出来。
这个想法实际上是很多早期的计算机视觉特征提取方法的基础。例如,对于边缘检测,你可以使用 Sobel 边缘检测滤波器,这是一个具有固定参数的核,运算过程和标准的单通道卷积一样:

使用垂直边缘检测卷积核
对于没有边缘的阵列(例如天空背景),大部分像素是一样的值,所以卷积核在这些点输出为 0。对于有垂直边缘的阵列,边缘左右两侧的像素是不同的,卷积核的计算结果也是非零的,从而揭示边缘。在检测局部范围内异常时,卷积核一次只作用于 3 × 3 的阵列,但是当应用到整个图像时,也足以在全局范围内检测到来自于在图像的任何位置的某个特定的特征,!
所以我们在深度学习中所做的关键区别是问这个问题:有用的核能被学习吗?对于以原始像素为基础的初始层,我们可以合理地期望具有相当低水平特征的特征检测器,如边、线等。
深度学习研究有一个专注于神经网络可解释性的完整分支。这一分支最强大的工具之一是使用优化方法可视化特征 [3]。核心思想很简单:优化图像(通常是使用随机噪声初始化)来激活滤波器,使其尽可能强壮。这确实很直观:如果经过优化的图像完全被边缘填充,这就是过滤器本身所寻找并被激活的强有力的证据。使用这个,我们可以窥视到学习的过滤器,结果是惊人的:

来自 GoogLeNet[3] 第一个卷积层的 3 个不同通道的特征可视化,注意,即便它们检测到不同的边缘类型时,它们仍然是很低级的边缘检测器。

来自第二和第三个卷积的通道 12 的特征可视化。
这里需要注意的一个重要的事情是经过卷积的图像仍然是图像。来自图像左上角的小阵列像素输出依然位于左上角。所以你可以在另一个上面运行另一个卷积层(比如左边的两个)来提取更深层的特征,这我们可以想象到。
然而,无论我们的特征探测器能检测到多深,没有任何进一步的改变,它们仍然只能在非常小的图像上运行。无论你的探测器有多深,你都无法从 3×3 阵列中检测到人脸。这就是感受域的概念。
感受域
任何 CNN 架构的一个基本的设计选择是输入的大小从开始到网络的末端变得越来越小,而通道的数量越来越深。如之前所述,这个经常是通过步长或池化层完成的。Locality 决定了输出层看到的前一层的输入。感受域决定了从输出的角度看到的整个网络的原始输入区域。
条纹卷积的概念是我们只处理一个固定的距离,而忽略中间的那些。从不同的视角,我们只保持固定距离的输出,而移去剩余部分 [1]。

3×3 卷积,步长 2
然后我们对输出应用非线性,然后根据通常情况,在上面叠加另一个新的卷积层。这就是有趣的地方。即使我们将有相同大小和相同局部区域的核(3×3),应用到条纹卷积的输出,核将会拥有更大的感受域:

这是因为条纹层的输出仍然代表相同图像。它不像调整大小那样裁剪,唯一的问题是,输出中的每个像素都是一个较大区域(其他像素被丢弃)的「代表性」,从原始输入的相同的粗糙位置。因此,当下一层的核在输出上运行时,它实际运行于从更大的区域收集的像素上。
(注意:如果你熟悉扩张卷积,注意上面的不是扩张卷积。两个都是增加感受域的方法,扩张卷积是一个单独层,而这是发生在一个正规卷积上,之后是条纹卷积,中间帧是非线性)

对每个主要的卷积块集合的通道进行可视化,显示复杂性的逐步增加 [3]
这个感受域的扩展允许卷积层将低层次的特性(线,边)与更高层次的特征(曲线,纹理)组合,就像我们在 mixed3a 层中看到的那样。
紧接着是池化/ 跨越层 , 网络继续为更高级别的特性(部件、模式)创建检测器。如我们在 mixed4a 所看到的。
网络中,图像尺寸的重复减小,导致在卷积的第五个块中,其输入大小仅 7×7,与 224×224 的输入相比。从这点来看,每个单独像素代表了 32×32 像素阵列,这是相当大的。
与前面的层相比,对前面的层来说,一个激活意味着检测一个边界,而这里,7×7 上的激活就是一个高级的特征,例如鸟类。
整个网络从少量的滤波器(GoogLeNet 有 64 个),只能检测低级的特征,发展到拥有大量滤波器(在最终的卷积网络中有 1024 个),每个滤波器用于查找特定的高级特征。之后是池化层,将每个 7×7 阵列精简成 1 个像素,每个通道都是一个拥有一个与整个图像对应的感受域的特征检测器。
与前向传播网络所完成的工作相比,这里的输出令人惊讶。一个标准前向传播网络从图像的像素集合中生成抽象的特征向量,需要大量难以处理的数据进行训练。
卷积神经网络,with the priors imposed on it, 通过学习低级别的特征检测器开始,它的感受域逐层扩展,学习将那些低级的特征逐渐与高层的特征融合;不是每个单个像素的抽象结合,而是强大的视觉层次的概念。
通过检测第级别的特征,并使用它们检测高级别特征,随着视觉层次的发展,最终能够检测整个视觉概念,例如人脸、鸟类、树木等,这就是为什么它们如此强大,但却能有效地利用图像数据。
关于对抗攻击的最后说明
有了视觉层次卷积神经网络的构建,我们可以很合理地假设他们的视觉系统与人类相似。他们在处理真实世界的图像时表现很棒,但是它们在某些方面也失败了,这强烈地表明他们的视觉系统和人类的并不完全相似。最主要的问题:对抗样本 [4],这些样本被做了特别修改导致模型被愚弄。

对人类来说,两张图片明显都是熊猫,但对模型来说,并不是这样。[4]
如果人类能够注意到那些导致模型失败的被篡改的例子,那么对抗样本就不是问题了。问题是,这些模型容易受到样本的攻击,这些样本只被稍微修改过,而且显然不会欺骗任何人类。这为模型打开了一扇门,很小的失败,对于从自动驾驶汽车到医疗保健的广泛应用来说,是相当危险的。
对抗攻击的鲁棒性是目前高度活跃的研究领域,许多论文、甚至竞赛和解决方案的课题肯定会改善 CNN 的架构,使其变得更安全、更可靠。
结论
卷积神经网络是允许计算机视觉从简单的应用程序扩展到为复杂的产品和服务提供动力的模型,从你的照片库中的人脸检测到做出更好的医学诊断。它可能会是计算机视觉向前发展的关键方法,或者一些新的突破。
链接:https://www.jianshu.com/p/fc9175065d87
1.知乎上排名最高的解释
首先选取知乎上对卷积物理意义解答排名最靠前的回答。
不推荐用“反转/翻转/反褶/对称”等解释卷积。好好的信号为什么要翻转?导致学生难以理解卷积的物理意义。
这个其实非常简单的概念,国内的大多数教材却没有讲透。
直接看图,不信看不懂。以离散信号为例,连续信号同理。
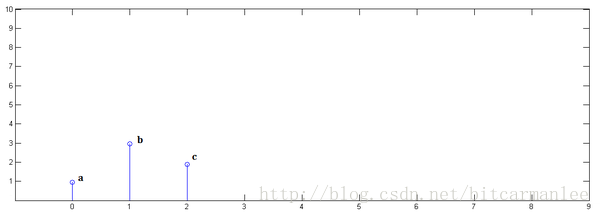
已知x[0] = a, x[1] = b, x[2]=c
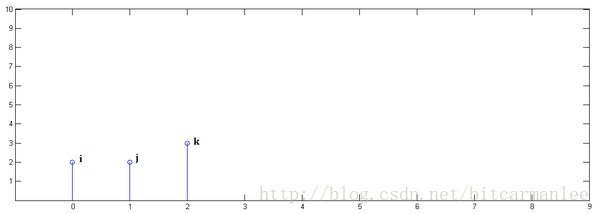
已知y[0] = i, y[1] = j, y[2]=k
下面通过演示求x[n] * y[n]的过程,揭示卷积的物理意义。
第一步,x[n]乘以y[0]并平移到位置0:
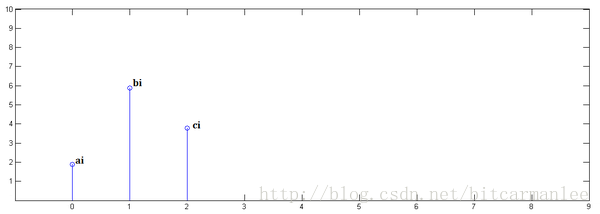
第二步,x[n]乘以y[1]并平移到位置1
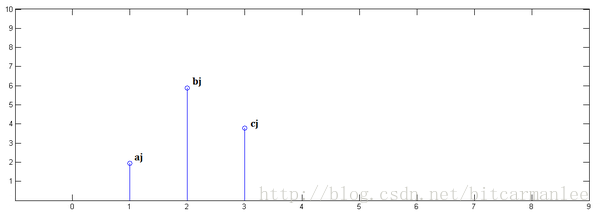
第三步,x[n]乘以y[2]并平移到位置2:
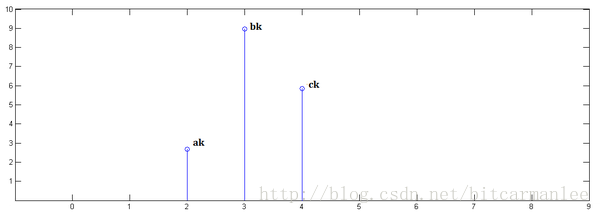
最后,把上面三个图叠加,就得到了x[n] * y[n]:
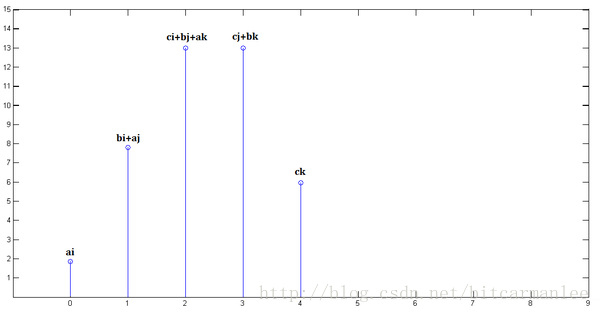
简单吧?无非是平移(没有反褶!)、叠加。
从这里,可以看到卷积的重要的物理意义是:一个函数(如:单位响应)在另一个函数(如:输入信号)上的加权叠加。
重复一遍,这就是卷积的意义:加权叠加。
对于线性时不变系统,如果知道该系统的单位响应,那么将单位响应和输入信号求卷积,就相当于把输入信号的各个时间点的单位响应 加权叠加,就直接得到了输出信号。
通俗的说:
在输入信号的每个位置,叠加一个单位响应,就得到了输出信号。
这正是单位响应是如此重要的原因。
在输入信号的每个位置,叠加一个单位响应,就得到了输出信号。
这正是单位响应是如此重要的原因。
在输入信号的每个位置,叠加一个单位响应,就得到了输出信号。
这正是单位响应是如此重要的原因。
以上是知乎上排名最高的回答。比较简单易懂。
有个回复也可以参考:
楼主这种做法和通常教材上的区别在于:书上先反褶再平移,把输入信号当作一个整体,一次算出一个时间点的响应值;而楼主把信号拆开,一次算出一个信号在所有时间的响应值,再把各个信号相加。两者本质上是相同的。
2.卷积的另外解释
卷积表示为
使用离散数列来理解卷积会更形象一点,我们把y(n)的序列表示成, 这是系统响应出来的信号。
同理,的对应时刻的序列为
其实我们如果没有学过信号与系统,就常识来讲,系统的响应不仅与当前时刻系统的输入有关,也跟之前若干时刻的输入有关,因为我们可以理解为这是之前时刻的输入信号经过一种过程(这种过程可以是递减,削弱,或其他)对现在时刻系统输出的影响,那么显然,我们计算系统输出时就必须考虑现在时刻的信号输入的响应以及之前若干时刻信号输入的响应之“残留”影响的一个叠加效果。
假设0时刻系统响应为,若其在1时刻时,此种响应未改变,则1时刻的响应就变成了,叫序列的累加和(与序列的和不一样)。但常常系统中不是这样的,因为0时刻的响应不太可能在1时刻仍旧未变化,那么怎么表述这种变化呢,就通过h(t)这个响应函数与x(0)相乘来表述,表述为,具体表达式不用多管,只要记着有大概这种关系,引入这个函数就能够表述在1时刻究竟削弱了多少,然后削弱后的值才是在1时刻的真实值,再通过累加和运算,才得到真实的系统响应。
再拓展点,某时刻的系统响应往往不一定是由当前时刻和前一时刻这两个响应决定的,也可能是再加上前前时刻,前前前时刻,前前前前时刻,等等,那么怎么约束这个范围呢,就是通过对这个函数在表达式中变化后的中的m的范围来约束的。即说白了,就是当前时刻的系统响应与多少个之前时刻的响应的“残留影响”有关。
当考虑这些因素后,就可以描述成一个系统响应了,而这些因素通过一个表达式(卷积)即描述出来不得不说是数学的巧妙和迷人之处了。
3.卷积的数学定义
前面讲了这么多,我们看看教科书上对卷积的数学定义。

4.卷积的应用
用一个模板和一幅图像进行卷积,对于图像上的一个点,让模板的原点和该点重合,然后模板上的点和图像上对应的点相乘,然后各点的积相加,就得到了该点的卷积值。对图像上的每个点都这样处理。由于大多数模板都是对称的,所以模板不旋转。卷积是一种积分运算,用来求两个曲线重叠区域面积。可以看作加权求和,可以用来消除噪声、特征增强。
把一个点的像素值用它周围的点的像素值的加权平均代替。
卷积是一种线性运算,图像处理中常见的mask运算都是卷积,广泛应用于图像滤波。
卷积关系最重要的一种情况,就是在信号与线性系统或数字信号处理中的卷积定理。利用该定理,可以将时间域或空间域中的卷积运算等价为频率域的相乘运算,从而利用FFT等快速算法,实现有效的计算,节省运算代价。
5.补充
另外在知乎上看到非常好也非常生动形象的解释,特意复制粘贴过来。(知乎马同学的解释)
从数学上讲,卷积就是一种运算。
某种运算,能被定义出来,至少有以下特征:
1.首先是抽象的、符号化的
2.其次,在生活、科研中,有着广泛的作用
比如加法:
1.a+b,是抽象的,本身只是一个数学符号
2.在现实中,有非常多的意义,比如增加、合成、旋转等等
卷积,是我们学习高等数学之后,新接触的一种运算,因为涉及到积分、级数,所以看起来觉得很复杂。
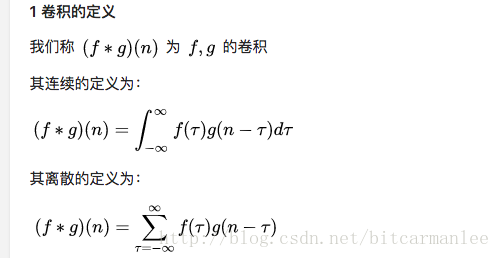
这两个式子有一个共同的特征:

这个特征有什么意义?
只看数学符号,卷积是抽象的,不好理解的,但是,我们可以通过现实中的意义,来习惯卷积这种运算,正如我们小学的时候,学习加减乘除需要各种苹果、糖果来帮助我们习惯一样。
我们来看看现实中,这样的定义有什么意义。
2 离散卷积的例子:丢骰子
我有两枚骰子:

把这两枚骰子都抛出去:

求:两枚骰子点数加起来为4的概率是多少?
这里问题的关键是,两个骰子加起来要等于4,这正是卷积的应用场景。
我们把骰子各个点数出现的概率表示出来:

那么,两枚骰子点数加起来为4的情况有:
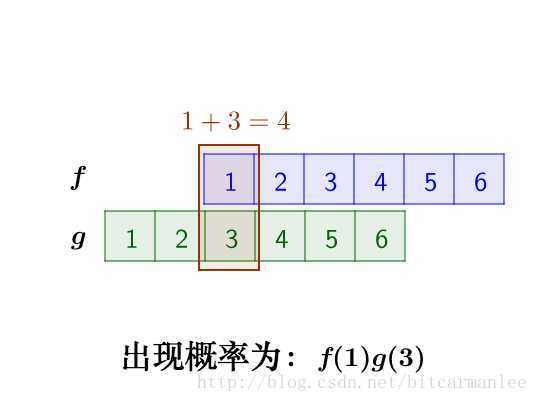
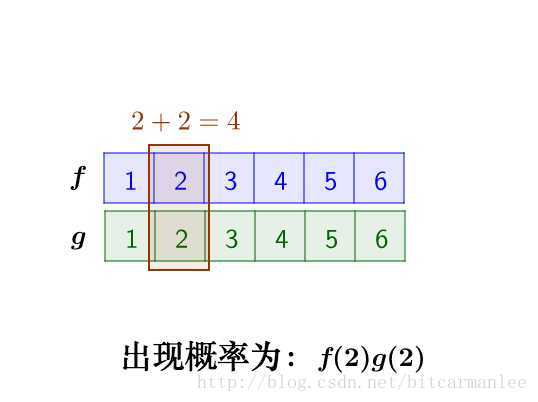
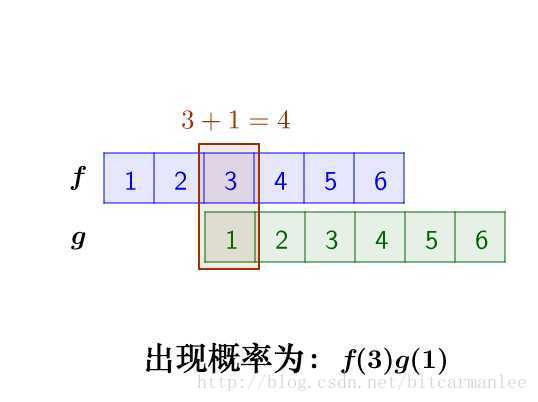
因此,两枚骰子点数加起来为4的概率为:
f(1)g(3)+f(2)g(2)+f(3)g(1)
符合卷积的定义,把它写成标准的形式就是:
3 连续卷积的例子:做馒头
楼下早点铺子生意太好了,供不应求,就买了一台机器,不断的生产馒头。
假设馒头的生产速度是 f(t) ,那么一天后生产出来的馒头总量为:
馒头生产出来之后,就会慢慢腐败,假设腐败函数为 g(t) ,比如,10个馒头,24小时会腐败:
想想就知道,第一个小时生产出来的馒头,一天后会经历24小时的腐败,第二个小时生产出来的馒头,一天后会经历23小时的腐败。
如此,我们可以知道,一天后,馒头总共腐败了:
这就是连续的卷积。
4 图像处理
4.1 原理
有这么一副图像,可以看到,图像上有很多噪点:
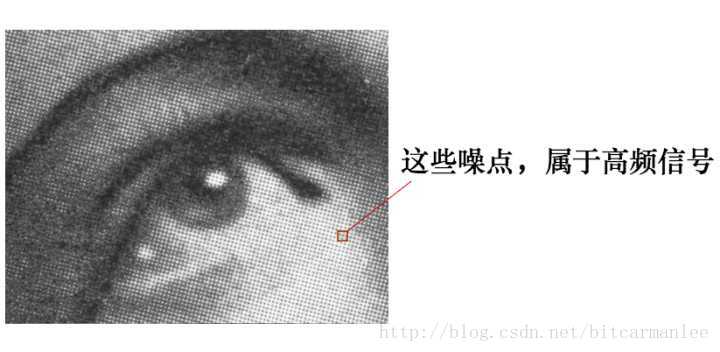
高频信号,就好像平地耸立的山峰:

看起来很显眼。
平滑这座山峰的办法之一就是,把山峰刨掉一些土,填到山峰周围去。用数学的话来说,就是把山峰周围的高度平均一下。
平滑后得到:

4.2 计算
卷积可以帮助实现这个平滑算法。
有噪点的原图,可以把它转为一个矩阵:

然后用下面这个平均矩阵(说明下,原图的处理实际上用的是正态分布矩阵,这里为了简单,就用了算术平均矩阵)来平滑图像:
记得刚才说过的算法,把高频信号与周围的数值平均一下就可以平滑山峰。
比如我要平滑 点,就在矩阵中,取出点附近的点组成矩阵 f ,和 g 进行卷积计算后,再填回去

要注意一点,为了运用卷积, g 虽然和 f 同维度,但下标有点不一样:


写成卷积公式就是:
要求,一样可以套用上面的卷积公式。
这样相当于实现了 g 这个矩阵在原来图像上的划动(准确来说,下面这幅图把 g 矩阵旋转了 ):
6.另外一个关于卷积的有意思的解释
看了好多关于卷积的答案,看到这个例子才彻底地理解了这个过程~
关于卷积的一个血腥的讲解
比如说你的老板命令你干活,你却到楼下打台球去了,后来被老板发现,他非常气愤,扇了你一巴掌(注意,这就是输入信号,脉冲),于是你的脸上会渐渐地(贱贱地)鼓起来一个包,你的脸就是一个系统,而鼓起来的包就是你的脸对巴掌的响应,好,这样就和信号系统建立起来意义对应的联系。下面还需要一些假设来保证论证的严谨:假定你的脸是线性时不变系统,也就是说,无论什么时候老板打你一巴掌,打在你脸的同一位置(这似乎要求你的脸足够光滑,如果你说你长了很多青春痘,甚至整个脸皮处处连续处处不可导,那难度太大了,我就无话可说了哈哈),你的脸上总是会在相同的时间间隔内鼓起来一个相同高度的包来,并且假定以鼓起来的包的大小作为系统输出。好了,那么,下面可以进入核心内容——卷积了!
如果你每天都到地下去打台球,那么老板每天都要扇你一巴掌,不过当老板打你一巴掌后,你5分钟就消肿了,所以时间长了,你甚至就适应这种生活了……如果有一天,老板忍无可忍,以0.5秒的间隔开始不间断的扇你的过程,这样问题就来了,第一次扇你鼓起来的包还没消肿,第二个巴掌就来了,你脸上的包就可能鼓起来两倍高,老板不断扇你,脉冲不断作用在你脸上,效果不断叠加了,这样这些效果就可以求和了,结果就是你脸上的包的高度随时间变化的一个函数了(注意理解);如果老板再狠一点,频率越来越高,以至于你都辨别不清时间间隔了,那么,求和就变成积分了。可以这样理解,在这个过程中的某一固定的时刻,你的脸上的包的鼓起程度和什么有关呢?和之前每次打你都有关!但是各次的贡献是不一样的,越早打的巴掌,贡献越小,所以这就是说,某一时刻的输出是之前很多次输入乘以各自的衰减系数之后的叠加而形成某一点的输出,然后再把不同时刻的输出点放在一起,形成一个函数,这就是卷积,卷积之后的函数就是你脸上的包的大小随时间变化的函数。本来你的包几分钟就可以消肿,可是如果连续打,几个小时也消不了肿了,这难道不是一种平滑过程么?反映到剑桥大学的公式上,f(a)就是第a个巴掌,g(x-a)就是第a个巴掌在x时刻的作用程度,乘起来再叠加就ok了,大家说是不是这个道理呢?我想这个例子已经非常形象了,你对卷积有了更加具体深刻的了解了吗?
参考资料:
1.https://www.zhihu.com/question/22298352
2.http://blog.csdn.net/yeeman/article/details/6325693
3.http://muchong.com/html/201001/1773707.html
4.https://www.zhihu.com/question/39753115
5.https://zh.wikipedia.org/wiki/%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C
6.http://blog.csdn.net/tiandijun/article/details/40080823
7.https://zh.wikipedia.org/wiki/%E5%8D%B7%E7%A7%AF%E5%AE%9A%E7%90%86
8.https://www.zhihu.com/question/19714540/answer/14738630 如何理解傅里叶变换公式?
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)







