SphereFace算法详解_AI之路-CSDN博客_sphereface论文:SphereFace: Deep Hypersphere Embedding for Face Recognition 论文链接:https://arxiv.org/abs/1704.08063这篇是CVPR2017的poster,主要提出了A-softmax loss(angular softmax loss)用来改进原来的softmax loss。A-softmax loss简单讲就是在 https://blog.csdn.net/u014380165/article/details/76946380?spm=1001.2014.3001.5501
https://blog.csdn.net/u014380165/article/details/76946380?spm=1001.2014.3001.5501
这篇文章相当于把之前lsoftmax的理论应用到了人脸的领域,并且给出了很强的理论支撑。尤其是他在几何空间上对度量学习的人脸识别有很强的解释性。整体上就是引入了||w||=1和b=0的lsoftmax,使得类别预测仅取决于W和x之间的角度,对角度引申出来的决策边界加上margin,指导loss学习更好的边界,从而增加类间距,缩小类内距。
1. Abstract
在适当的度量空间中,have smaller maximal intra-class distance than minimal inter-class distance,最小的类间距要大于最大类内距。因此提出了angular softmax(A-softmax),enables CNNs to learn angularly discriminative features.让cnn学习角度判别特征。A-Softmax loss can be viewed as imposing discriminative constraints on a hypersphere manifold, which intrinsically matches the prior that faces also lie on a manifold.A-softmax loss可被视为对超球面流形施加区别性约束,其本质是与同样位于流形上的先验face相匹配。听起来差点意思,其实就是对决策边界施加了一个m,让model学了一个分的更开的边界,m就是区别性约束,而linear出的特征映射到高维的超球面上就是一块一块的区域。
2.Introduction

上图讨论了开集和闭集测试,左边是闭集测试,就是测试的数据是在训练集中出现过的,有id的,本质就是一个分类任务,右边是开集测试,测试的数据在训练集中没有出现,因为在训练集上训练的model的能力更多体现在特征提取上,在face vertification中是提取两张不在训练集中的图片的到的特征做距离计算,进而判断是否是同一个人,本质上是一个度量学习问题,the key is to learn discriminative large-margin features.关键是找出特征之间有判别力的边界,这也是作者为什么要加m的原因,加大决策边界。
对于开集问题,理论上是最大类内距离要小于最小类间距离,However, learning features with this criterion is generally difficult because of the intrinsically large intra-class variation and high interclass similarity that faces exhibit.通常这很难,数据集和现实情况中都不会有这么好的情况。怎么办?we propose to incorporate angular margin instead.加一个angular margin.通过优化A-softmax,决策区域变得更加分离,同时扩大类间margin和压缩类内的angular分布。
2.Deep hypershere embedding
2.1 revisiting the softmax loss
以一个二分类为例,softmax loss得到的后验概率为(此时是linear层+softmax,还未进入交叉熵):

其中x是输入的特征向量,W是linear层的权重,b是linear层的偏置,若预测为类1,则p1>p2,若预测为p2,则p1<p2。p的分母是一致,大小则取决于分子,都是e的指数函数,是递增的,因此属于那个类别取决于wx+b的值,此时决策边界就是(p1=p2)

将上式中的Wx写成向量乘法分解的形式,则是
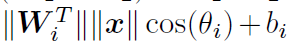
此时的角是在W和x之间的角度。将权重进行归一化并且偏置为0,即
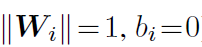
p1和p2用的是同一个x,则最终结果只取决于角度,决策边界变成了
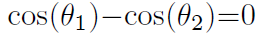
将W归一化(W模为1),偏置为0,就是上面的过程就是作者提到的modified softmax loss.它鼓励第i类特征比其他特征具有更小的角度 (更大的余弦距离),这使得W和特征之间的角度成为可靠的分类度量。因为cos是递减函数,类和类之间的角度越小,则两者之间余弦距离越大,就是同一类的扇形角越小,类间越紧凑。
上面讨论的是softmax的形式,下面给出softmax loss的形式:



Although we can learn features with angular boundary with the modified softmax loss, these features are still not necessarily discriminative. Since we use angles as the distance metric, it is natural to incorporate angular margin to learned features in order to enhance the discrimination power.至此,modified softmax loss的形式就给出了,即W归一化,b=0,它具备了学习angular边界特征能力,但是这些特征仍然不具有判别性,以前只是在欧式空间计算距离,现在变成了计算角度的边界。
3.2 Introducting angular margin to softmax loss
这一节其实就是引入了lsoftmax,A-softmax比lsoftmax就多了w归一化和b=0这两个约束条件。From the previous analysis of softmax loss,we learn that decision boundaries can greatly affect the feature distribution, so our basic idea is to manipulate decision boundaries to produce angular margin.从上面的分析可以知道,在softmax loss中,决策边界可以极大的影响特征分布,因此作者的想法就是操作决策边界以产生angular margin。
若属于类别1,则从modifed softmax loss中需要cos(角1)>cos(角2)才能正确分类x,如果我们要求cos(m*角1)>cos(角2),m是一个大于2的正整数,那么为了正确分类x,改怎么办?It is essentially making the decision more stringent than previous,because we require a lower bound of cos(angle1) to be larger than cos(angle2). The decision boundary for class 1 is cos(m*angle1)=cos(angle2).它本质上使决策比之前更加严格,因为它需要一个更低的边界,cos(angel1)并且大于cos(angle2),此时的决策边界变成了cos(m*angle1)=cos(angle2),这个地方和lsoftmax是完全一致的,就是我在loss侧把决策边界拉的更开了,让模型学的时候把类间距离拉开,这样类内也更加内聚了。下面两个式子就是A-softmax的表达式。


A-softmax从决策边界解释,A-Softmax loss adopts different decision boundary for different class (each boundary is more stringent than the original), thus producing angular margin.A-softmax对不同的类别采用不同的决策边界,每个边界比原始边界更加严格,从未产生angluar margin.

From original softmax loss to modified softmax loss, it is from optimizing inner product to optimizing angles.From modified softmax loss to A-Softmax loss, it makes the decision boundary more stringent and separated. The angular margin increases with larger m and be zero if m=1.上图是三个loss的决策边界公式,原始的softmax loss到modified softmax loss,从优化内积到优化角度,从modified softmax loss到A-softmax loss,使得决策边界更加严格和分离。

现在来解释一下这个图,linear层的输出设为2,即将所有的特征都放在二维平面上看,ace是原始2维平面的,bdf是映射到球面,黄和紫代表两个类别,ab是softmax loss的结果,可见分类边界并不好,学到的特征也无法通过angle来做分类,modified softmax loss可以通过角度来区别,A-softmax则划分的更好,可以进一步的通过angular margin来区别学到的特征。
3.3 hypersphere interpretation of A-softmax loss

作者给了个几何上的解释,A-softmax在超球面上就是一块一块类似圆的区域,投影到2d平台就是一个类似放射状的球形。
3.4 properties of A-softmax loss
给了两个证明,第一是二分类任务最小的m是:

多分类任务最小的m是:
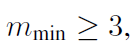
作者建议m取4.
4.experiments
 这个图是作者在CASIA Webface数据集上选了6个类训练的A-softmax结果图,linear输出的特征维度是3(可视化到球面上),可以看到m越大,球面上对应的小圆越来越分离和紧凑,这对应了A-softmax的几何意义,第二行上,随着m的增加负样本和正样本之间的angle也越变越大。
这个图是作者在CASIA Webface数据集上选了6个类训练的A-softmax结果图,linear输出的特征维度是3(可视化到球面上),可以看到m越大,球面上对应的小圆越来越分离和紧凑,这对应了A-softmax的几何意义,第二行上,随着m的增加负样本和正样本之间的angle也越变越大。
整篇文章来说,意义上就是引入了w=1,b=0的lsoftmax在人脸识别的问题上,论文写的很好,A-softamx分析了具有普遍意义的规律,在角度上多一个m,增加类和类之间的决策边界,让loss学一个更难的决策边界,从而促使每个模型学习的每个类间距离越大,类内距离越小。
更新:实测a-softmax和l-softmax都很难收敛,在分类任务上相较于lmcl(large margin cosine loss)要收敛的多,不建议在工程上用这两个loss,尤其是现在有更好的loss的情况下(在解决类间距类内距问题上)。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)