前言
在做机器学习模型调优的时候,往往会通过一系列的操作去提升调优效率,其中有一种技术就是合理运用早停策略。
关于数据集:本文直接使用kaggle的数据集,你可以直接点击链接下载。
一、入门
1.验证集性能和迭代次数的关系
我们这里选用lightgbm算法作为演示,随机选择了一些参数值,然后设置n_estimators=1000,接下来我们来看一下验证集的性能和n_estimators的关系。
data = pd.read_csv('..\resource\data.csv',index_col=0)
Y = data.pop('target')
X = data
x_train,x_eval,y_train,y_eval = train_test_split(X,Y, test_size=0.2, random_state=623)
#模型训练
clf = lgb.LGBMClassifier(max_depth=4,n_estimators=1000,learning_rate=0.07)
clf.fit(x_train,y_train,eval_set=[(x_eval,y_eval)])
#获取验证集的结果
evals_results = clf.evals_result_['valid_0']['multi_logloss']
#画图
plt.plot(evals_results)
plt.vlines(100, 1.09, evals_results[100],color="red")
plt.vlines(np.argmin(evals_results), 1.09, evals_results[np.argmin(evals_results)],color="red")
plt.vlines(800, 1.09, evals_results[800],color="red")
plt.title('eval_metric_curve')
plt.xlabel('n_estimators')
plt.ylabel('multi_logloss')
plt.ylim(1.09,1.13)
plt.show()

从上面的结果图上我们可以看到,在实际训练的过程当中,如果只训练到第一根红线的位置,明显模型欠拟合,如果一直训练下去,训练到第三根红线的时候,明显模型过拟合了,最好的位置是第二根红线所在的位置,这时候,模型在验证集上的性能最优。
2. 引入早停策略
如上面分析,如果训练时间过短,模型还没有收敛,如果训练时间过长,模型开始过拟合,这个时候我们可以在fit阶段加入early_stopping_rounds参数,整体代码修改如下:
clf = lgb.LGBMClassifier(max_depth=4,n_estimators=1000,learning_rate=0.07)
clf.fit(x_train,y_train,eval_set=[(x_eval,y_eval)],early_stopping_rounds=50)
evals_results = clf.evals_result_['valid_0']['multi_logloss']
plt.plot(evals_results)
plt.title('eval_metric_curve')
plt.xlabel('n_estimators')
plt.ylabel('multi_logloss')
plt.show()
print('best training score:',min(evals_results))
scorer=get_scorer('neg_log_loss')
score = scorer(clf,x_eval,y_eval)
print('finnal model score:',score*scorer._sign)

同时使用了早停策略之后,模型会直接使用过程中最优的模型,如下图所示:
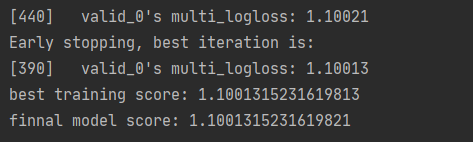
对比如果不使用早停策略的话,使用的是最终的一个过拟合模型,如下图所示:
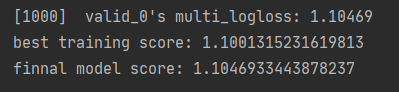
二、进阶
以上介绍的是单个模型在训练的时候,我们一般可以使用较大的n_estimators+early_stopping_rounds进行模型的训练,但是在实际项目当中,还会涉及到模型如何调优的问题,这里我们以常见的GridSearchCV来演示一下。
这里我们基于上面的内容,继续来探索最优的几个其他参数,代码如下:
from sklearn.model_selection import GridSearchCV
lightgbm_param_grid = {"max_depth":[3,4,5],
"num_leaves" : [20,31,50],
"reg_alpha":[0.1,0.5,1],
"reg_lambda":[0.001,0.005,0.01]
}
clf = lgb.LGBMClassifier(n_estimators=300,learning_rate=0.07)
Gclf = GridSearchCV(clf,param_grid = lightgbm_param_grid, cv=5, scoring="neg_log_loss",n_jobs= 4,verbose = 1)
Gclf.fit(x_train,y_train)
print(Gclf.best_params_)
通过上面的代码,我们可以进一步去获取最优的lightgbm参数,但是需要考虑到这里训练总次数一共是
参数组合(81) * 交叉验证(5) = 405次的训练次数。那这里又会出现一些新的需求
1. 在指定时间内搜索
老板刚刚给我打电话,说你现在手上的模型明天就得正式提测,那对于我来说,我就只有一个晚上的时间可以进行最后的调参了,所以我不得不考虑到我总共只有10h小时的时间了,那么上面的代码需要进行如下修改(伪代码)。
with Timer as Searching:
这里还是做原来的参数调优
if Searching.duration > 10*60*60:
搜索超过10h,结束整个任务,然后保存最优的模型参数
这样一来,第二天早上九点我可以直接得到最优参数,然后进行提测(不然可能你会发现第二天你来了,程序还在运行,停止的话,什么都没有了,不停止的话,测试部已经开始在催你了)
2. 模型达到某一性能即可
两周前我们的模型的最优性能是98.6%的准确度,这个时候客户很满意我们的性能,然后告诉我们后天正式下单,这个时候,我的老板走过来告诉我,这可是一个大客户,你现在还有一点时间,你在调优调优,争取让性能突破98.6%的水平,给客户留下一个好印象,那这个时候我就想着在尝试尝试呗,看一下性能能不能继续突破98.8%,那整体代码设计修改如下:
In search step:
if 当前模型的性能超过98.8%:
停止整个程序,保存最优模型性能
3. 连续N次性能都没有提升
机器学习的性能瓶颈往往不在于模型参数,而在于你提供的数据特征是什么水平(而想要做出非常优秀的特征,往往又需要对实际业务非常了解),所以尽管在时间充裕的情况下,一直进行参数调优的意义其实不会太大。所以可能会出现你用2h和用8h进行参数搜索的最终结果是一样的情况,那这个时候我们可以修改我们的整体代码如下:
In search step:
if 当前模型性能 < 历史模型最优性能:
统计当前已经多少轮性能没有进一步提升了
if 轮数 > 阈值:
停止整个程序,保存最优模型
备注:连续N次性能都没有提升一般不适用于网格搜索,因为网格搜索搜索效率不会随着搜索次数的增多而提升,而对于常见的贝叶斯优化,遗传搜索算法,随着先验知识的累计,搜索效率是会提升的。
附:建模技巧
还是以上面的数据集为例,我们上面入门篇的时候,得到的模型最优性能是1.10013,现在我们尝试使用hypergbm[https://github.com/DataCanvasIO/HyperGBM],来进一步提升模型的性能。
在hypergbm中,支持的早停策略如下:

from sklearn.model_selection import train_test_split
from hypergbm import make_experiment
from sklearn.metrics import get_scorer
data = pd.read_csv('..\resource\data.csv',index_col=0)
df_trian,df_test = train_test_split(data, test_size=0.2, random_state=623)
target = 'target'
exp1 = make_experiment(df_train,
target=target,
log_level='info',
max_trilas=10000,
early_stopping_time_limit=10*3600)
exp2 = make_experiment(df_train,
target=target,
log_level='info',
max_trilas=10000,
early_stopping_reward=1.1)
exp3 = make_experiment(df_train,
target=target,
log_level='info',
max_trilas=10000,
early_stopping_rounds=50)
estiamtor = exp2.run()
scorer=get_scorer('neg_log_loss')
score = scorer(estimator,df_test,df_test[target])
score
附2:
同样的你在使用hypergbm进行建模的时候,可以设置n_estimators较大,然后使用单模型的早停策略即可。代码如下:
from hypergbm.search_space import GeneralSearchSpaceGenerator
search_space_ = GeneralSearchSpaceGenerator(n_estimators= 900)
exp4 = make_experiment(df_train,
target=target,
log_level='info',
max_trilas=100,
search_space=search_space_,
estimator_early_stopping_rounds = 100,
)
estiamtor = exp4.run()
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)