本次采集实战,以 http://www.ccgp.gov.cn 为例,定向采集该站的政府采购信息。本文中,用到的采集类,请参考老顾的python入门23天和28天两篇文章。本文中所有出现的相关知识,在老顾的python入门系列文章中都有介绍,请缺课的同学自行补习。如果有其它语言采集池的同学想转到python做采集,可以私信老顾,一起讨论下哦。
---------------------------------------
之前,我们已经对 scrapy 做了否定,为什么呢,他不好用么?怎么说呢,他不能说不好用,但是不太符合老顾的习惯了,毕竟,老顾在没有使用 python 之前,就已经搞了7、8年的采集了,有很多采集,都已经形成自己的习惯了,比如,对ccgp这个网站的政采信息采集,老顾只定义了一个xml,然后放到老顾自己的采集工具里,他就可以正确的运行了,并不比scrapy什么的要差啊。老顾总不能为了转 python,就把以前所有定义好的信息全部放弃,就为了适应scrapy吧?多的不说,老顾手上的采集目标站点好几百个。。。难道你要我从新写好几百个蜘蛛?开玩笑吧。所以,老顾的目标是,将原有的站点信息导入到 python 中,一样可以使用~~~~加油!老顾!
说了那么多,先放一个站点的示例:以ccgp为例
<Sites>
<Site type="2" filter="1" name="中国政府采购" url="http://www.ccgp.gov.cn/">
<settings>
<charset>utf-8</charset>
<hasfilename>false</hasfilename>
</settings>
<regex>
<reg>
<![CDATA[http://[^"]+/cggg/(?![^"]+?\.html?)\w+/[^"]+(?<![/\\])(?=[/\\]?")]]>
</reg>
<settings>
<charset>utf-8</charset>
<hasfilename>false</hasfilename>
</settings>
<regex id="ccgplist">
<match>
<reg><))*?title=)(?=([\s\S](?!<li(?!\w)))*?\d+\.htm)([\s\S](?!<li(?!\w)))*</li(?!\w)[^<>]*?>]]></reg>
<url><![CDATA[http://[^"]+]]></url>
<item name="time"><![CDATA[(?<=发布时间:<span>)[^<>]*(?=</span>)]]></item>
<item name="area"><![CDATA[(?<=地域:<span>)[^<>]*(?=</span>)]]></item>
<settings>
<charset>utf-8</charset>
<hasfilename>true</hasfilename>
</settings>
<regex>
<item name="title"><![CDATA[(?<=<(h\d+)(?!\w)[^<>]*?>)([\s\S](?!<\1(?!\w)))*?(?=</\1(?!\w)[^<>]*?>)]]></item>
<item name="content"><![CDATA[(?<=(?:<(div) class="(vT_detail_content w760c|vF_detail_content)">|<div id="sign_content">))(([^<]|<(?!/?\1(?!\w))[^<>]*>)*|<\1(?!\w)[^<>]*>(?<DEPTH>)|</\1(?!\w)[^<>]*>(?<-DEPTH>))*(?(DEPTH)(?!))(?=</div>)]]></item>
</regex>
</match>
</regex>
<regex>
<page next="ccgplist">
<reg><![CDATA[(?<=<script language="javascript">Pager\(\{size:)\d+(?=, current:0, prefix:'index',suffix:'htm'\}\);</script>)]]></reg>
<loop>[url]index_[i].htm</loop>
</page>
</regex>
</regex>
</Site>
</Sites>
这是 ccgp 站点采集的定义了,其中,入口只有一个,根据入口,获得政采列表的链接,每个节点的大概意义参考下图

也就是我们的第一个 reg 节点中的信息,他用正则描述了这些公告的链接
http://[^"]+/cggg/(?![^"]+?\.html?)\w+/[^"]+(?<![/\\])(?=[/\\]?")
其中,每一个采集时,都有一个编码设置,一个包含文件名设置,用来方便计算我们的路径,前文也已经提到过了,他无法自动识别,所以我们在规则中给出他是不是需要在链接后追加/。
取得了列表页后,就可以得到列表中的每一项内容了,这就是第二个 reg 节点给出的信息了
<li(?!\w)(?=([\s\S](?!<li(?!\w)))*?title=)(?=([\s\S](?!<li(?!\w)))*?\d+\.htm)([\s\S](?!<li(?!\w)))*</li(?!\w)[^<>]*?>
同样是正则来提取页面中的内容
在 reg 节点后,跟随了一个 url 节点,这个节点是提取终端页链接的,用来采集终端页,获取更多信息,比如正文、采购方什么的
然后,最下边,我们有一个page节点,这个是用来定义翻页的,包括翻页链接的格式,是否有前缀、后缀什么的,毕竟每个站的翻页都有自己的规律,通过前缀后缀就可以把这些规律描述出来了。
嗯。。。通过这么一个站点的定义,大概就了解了,为什么老顾不愿意去转 scrapy 了,毕竟站点那么多,一个一个用 scrapy实现麻烦不说,还有很多更细致的需求也不能重用,代码重复率太高太高了,不符合开发人员的习惯。
好了,现在已经给出了这个原有的定义,现在老顾的工作就是写一个类,用来解析这个xml并开始采集,嗯,暂时先不多线程运行,先实现了采集再说,更多需求咱们边做边说
老顾先获取原来的配置信息中,ccgp 的节点
from lxml import etree as ET
x = ET.parse(r'D:\\**********\\config.xml')
root = x.getroot()
sites = root.findall('.//Sites/Site')
print(ET.tostring(sites[0]).decode('utf8'))
第一个问题来了,汉字都变成 unicode 格式的了

print(ET.tostring(sites[0],encoding='utf8').decode('utf8'))
使用这个指令,子节点的中文到是都转出来了,当前节点的属性,还是unicode格式的

先不管这个了,我们先用变量 ccgp 引用这个站点设置
ccgp = sites[0]
print(ccgp.attrib)
结果,准备获取属性时,发现他又不乱码了。。。我也是服气了

不管他,先做个简单的测试
import re
from spider import Ajax
from lxml import etree as ET
x = ET.parse(r'D:\\work\\source\\CaiGou_Gather_Services\\CaiGou_Gather_Test\\config.xml')
root = x.getroot()
sites = root.findall('.//Sites/Site')
ccgp = sites[0]
ajax = Ajax()
def spider(target):
tag = target.tag
if tag.lower() == 'site':
url = target.attrib['url']
charset = target.findall('./settings/charset')[0].text
isDirectory = target.findall('./settings/hasfilename')[0].text
reg = target.findall('./regex/reg')[0].text.strip()
if isDirectory == 'false':
url = re.sub('/$','',url) + '/'
ajax.charset = charset
html = ajax.Http(url)
urls = re.findall(reg,html,re.I)
print(urls)
spider(ccgp)
先看看入口解析,能不能得到下一步的链接,运行后,结果符合预期

那么,我们就可以正式制作这个类了
import re
from lxml import etree as ET
from spider import Ajax
class XmlSettings:
def __init__(self,file):
'''初始化'''
self.version = '0.1'
self.ajax = Ajax()
self.xml = ET.parse(file)
self.root = self.xml.getroot()
self.sites = self.root.findall('.//Sites/Site')
self.queue = []
self.done = []
def parse(self,element,html=None,url=None):
tag = element.tag
if element.findall('./settings/charset'):
charset = element.findall('./settings/charset')[0].text
isDirectory = element.findall('./settings/hasfilename')[0].text
else:
charset = element.getparent().findall('./settings/charset')[0].text
isDirectory = element.getparent().findall('./settings/hasfilename')[0].text
if tag.lower() == 'site':
url = element.attrib['url']
if isDirectory == 'false':
url = re.sub('/$','',url) + '/'
self.queue.append(url)
html = self.ajax.Http(url)
nodes = element.findall('./regex')
for node in nodes:
self.parse(node,html)
if tag.lower() == 'regex':
if element.findall('./reg'):
reg = element.findall('./reg')[0].text.strip()
urls = re.findall(reg,html,re.I)
for url in urls:
if isDirectory == 'false':
url = re.sub('/$','',url) + '/'
self.queue.append(url)
html = self.ajax.Http(url)
nodes = element.findall('./regex')
for node in nodes:
self.parse(node,html,url)
if element.findall('./match'):
nodes = element.findall('./match')
for node in nodes:
self.parse(node,html,url)
if element.findall('./page'):
reg = element.findall('./page/reg')[0].text.strip()
next = element.findall('./page/loop')[0]
prefix = ''
start = 1
maxPage = 0
pages = re.findall(reg,html,re.I)
if 'start' in next.attrib:
start = int(next.attrib['start'])
if 'prefix' in next.attrib:
prefix = next.attrib['prefix']
if pages:
maxPage = int(pages[0])
for i in range(start,maxPage+1):
next_url = next.text.strip()
next_url = next_url.replace('[i]',str(i))
next_url = next_url.replace('[fullurl]',url)
next_url = next_url.replace('[url]',url)
next_url = next_url.replace('[querystring]',url)
self.queue.append(next_url)
html = self.ajax.Http(next_url)
node = element.getparent().findall('./regex/match')[0]
#self.parse(node,html,next_url)
if tag.lower() == 'match':
regex = element.findall('./reg')[0].text.strip()
prefix = element.findall('./url')[0].attrib['prefix'] if 'prefix' in element.findall('./url')[0].attrib else ''
postfix = element.findall('./url')[0].attrib['postfix'] if 'postfix' in element.findall('./url')[0].attrib else ''
matches = re.finditer(regex,html,re.I)
for m in matches:
match = m.string[m.span()[0]:m.span()[1]]
print(match)
先简单的实现一些定义,其中parse方法算是递归方法了,当然这只是暂时的,因为真正要实现采集,还要考虑并发,考虑对方服务器封IP策略,考虑自己计算机运行速度等,这些咱们暂且先都不考虑,先看看能不能实现翻页,能不能得到终端页
在这段代码中,当碰到 regex/page 节点时,计算翻页,什么前缀,什么querystring全都考虑进来了,毕竟有的翻页是 /index_2.shtml,有的则是 /list.php?pg=2 这样的格式,所以,我这里定义的变量也相对多了一点,next_url就是计算完页码后的链接地址,为了测试,老顾把所有采集的页面链接,都放到了 queue 列表中了,我们可以在外边打印下 queue
from spider import XmlSettings
yy = XmlSettings(r'D:\\work\\source\\CaiGou_Gather_Services\\CaiGou_Gather_Test\\config.xml')
yy.parse(yy.sites[0])
for i in yy.queue:
print(i)
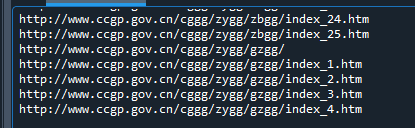
可以看到,翻页后的链接的确已经生成成功了,然后,在翻页链接被采集后,有一句获得该链接对应的列表页解析节点的代码
node = element.getparent().findall('./regex/match')[0]
#self.parse(node,html,next_url)
根据这个节点,继续解析采集到的内容。。。不过为了减少运行时间,我暂时给他注释掉了,没有解析翻页后的列表页
而每个列表页的第一页,则进入到了
if tag.lower() == 'match':
这个代码片段,我在这个实现里,仅仅获取了列表页的 li 标签,并将其打印出来了

那么,到此为止,我们基本上可以对任意站点进行老顾这样的xml定义,进行不限制的采集了。
还是那句话,本文主要是针对已有的采集项,在转型到python时,用老顾定义的 Ajax类来实现转型的,而不是强制使用 scrapy 来从新定义的。
如果有同学有自己的采集池也要转型,可以私信老顾,咱们一起探讨一下怎么迁移哦。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)