PC-DARTS: Partial Channel Connections for Memory-Efficient Differentiable Architecture Search
Abstract
可微体系结构搜索(DARTS)在寻找有效的网络体系结构方面提供了一种快速的解决方案,但在联合训练超级网络和寻找最优体系结构方面却存在较大的内存和计算开销。在本文中,我们提出了一种新的方法,即部分连接DARTS,通过采样一小部分超级网络来减少网络空间的冗余,从而在不影响性能的情况下执行更有效的搜索。特别是,我们在通道子集中执行操作搜索,并保持保留部分不变。这种策略可能会因不同通道的采样而导致超网边缘选择不一致。我们通过引入边缘规范化来解决这一问题,在搜索过程中加入一组新的边缘级超参数以减少搜索的不确定性。由于降低了内存成本,PC-DART可以以更大的批量进行训练,因此,它既具有更快的速度,又具有更高的训练稳定性。实验结果证明了该方法的有效性。具体来说,对于架构搜索,我们仅在0.1 GPU天内就在CIFAR10上实现了2.57%的错误率,对于搜索,我们在ImageNet(在移动设置下)上实现了24.2%的一流错误率(在3.8 GPU天内)。我们提供了代码https://github.com/yuhuixu1993/PC-DARTS。
1 Introduction
神经结构搜索(NAS)作为自动机器学习(AutoML)的一个重要分支,正受到学术界和工业界的广泛关注。NAS的关键方法是在特定的训练数据和约束条件(如网络规模和延迟)的组合下,建立一个大的网络结构空间,采用一种高效的算法来探索空间,并发现最优的结构。与早期需要大量计算的方法[34,35,24]不同,最近的one-shot方法[23,19]将搜索成本降低了几个数量级,这使其在许多实际问题中得到了应用。具体来说,DARTS[19]模型将操作选择转换为一组固定操作的加权组合。这使得整个框架可微到体系结构的超参数,因此搜索过程可以以端到端的方式完成。尽管DARTS的设计非常复杂,但它仍然受制于一个庞大而冗余的网络体系结构空间,因此会带来大量的内存和计算开销。这可以阻止搜索过程使用更大的批处理大小来加速或提高稳定性。先前的工作[6]提出减少搜索空间,这导致一个可能牺牲所发现体系结构的最优性的近似。
本文提出了一种简单而有效的部分连接DARTS(PCDARTS)方法来减少内存和计算量。其核心思想是直观的:我们不把所有的通道都加入到操作选择块中,而是随机抽取其中的一个子集进行操作选择,同时直接绕过其余的通道。我们假设这个子集上的计算是一个近似代理(surrogate approximating),近似于所有通道上的计算。除了极大地降低了内存和计算成本之外,采样带来了另一个好处,即操作搜索是正则化的,不太可能陷入局部最优。然而,PC-DART也带来了一个副作用,即当在迭代过程中对不同的通道子集进行采样时,网络连接的选择将变得不稳定。因此,我们引入边缘规范化,通过显式学习额外的一组边缘选择超参数来稳定网络连通性搜索。通过在整个训练过程中共享这些超参数,学习的网络架构不易在迭代中采样通道,因此更加稳定。
##########################################
补充参考博客:PC-DARTS:使用部分通道改进DARTS
我们的PC-DARTS可以减少内存和计算量。想法是:不把全部通道送入运算选择中,而是随机采样通道子集进行运算,其他的直接通过。前提假设是通道子集可以作为全集的近似。但是带来的问题是,由于采样的随机性,网络连接的选择可能是不稳定的。因此引入边标准化(edge normalization)进行稳定,做法是添加一个额外的边选择超参数集合。
###########################################
得益于部分连接策略,我们能够相应地增加批大小。在实际应用中,我们为每个操作选择随机抽取1/K个通道,这样可以将存储成本降低近K倍。这允许我们在搜索过程中使用Kx批处理大小,这不仅加快了K倍的搜索速度,而且还稳定了搜索,特别是对于大型数据集。在基准数据集上的实验很好地证明了PC-DART的有效性。具体来说,我们在单个GPU上的错误率为2.57%,小于0.1 GPU天(约1.5小时),超过了DART报告的2.76%,后者需要1 GPU天。此外,PC-DART允许在ImageNet上直接搜索(而DART由于稳定性低而失败),并在8 GPU上仅用3.8 GPU天(11.5小时)进行搜索,实现24.2%(在移动设置下)的最新top-1错误率。
本文的其余部分安排如下。第2节回顾了相关工作,第3节描述了我们的方法。在第4节展示了实验之后,我们在第5节总结。
2 Related Works
由于深度学习的迅速发展,计算机视觉问题在性能上有了很大的提高,其中大部分是由人工设计的网络体系结构引起的[16,26,11,13]。近年来,一个新的研究领域神经架构搜索(NAS)引起了越来越多的关注。其目的是寻找自动设计神经结构的方法,以取代传统的手工构造。根据探索大型体系结构空间的启发式方法,现有的NAS方法大致可分为三类,即基于进化的方法、基于强化学习的方法和one-shot方法。
第一类架构搜索方法[18、29、25、9、24、22]采用了进化算法,该算法假设应用遗传操作来强制单个架构或家族朝着更好的性能进化的可能性。其中,刘等人。[18] 介绍了一种描述网络体系结构的层次表示法,谢等人。[29]将每个结构分解成一个“基因”的表示。Real等人。[24]提出了aging进化,改进了standard tournament选择,并超越了自那时以来最好的手工设计架构。另一种启发式方法转向强化学习(RL)[34,1,35,32,17],它训练一个元控制器来指导在巨大的体系结构空间中的搜索过程。佐夫等人。[34]首先提出了一种基于控制器的递归神经网络来生成神经网络的超参数。为了降低计算成本,研究人员开始搜索块或单元[32,35]而不是整个网络,因此,[35]设法将总体计算成本降低了7倍。其他类型的近似,如贪婪搜索[17],也被应用于进一步加速搜索。然而,基于进化或RL的这些方法的计算成本仍然无法接受。
为了在短时间内完成架构搜索,研究人员考虑降低评估每个搜索候选对象的成本。早期的工作包括在搜索到的网络和新生成的网络之间共享权重[3],后来这些方法被推广到一个更优雅的框架中,称为one-shot架构搜索[2,4,19,23,30]。在这些方法中,覆盖所有候选操作的over-parameterized network 或super network 只训练一次,并从该超级网络中抽样得到最终的结构。
其中,Brock等人。[2] 用超网训练过参数化网络(over-parameterized network)[10],Pham等。[23]建议在子模型之间共享参数,以避免从头开始对每个候选人进行再培训。本文以DARTS[18]为基础,引入了一个可微框架,从而将搜索和评估阶段合并为一个阶段。尽管它很简单,但研究人员发现了它的一些缺点,这导致了一些改进的方法超越了DARTS[4,30,6]。
3 The Proposed Approach
3.1 Preliminaries: Differentiable Architecture Search (DARTS)
我们首先回顾一下baseline DARTS[19],并为后面的讨论定义符号。形式上,DARTS将搜索到的网络分解成若干(L)个单元。每个单元被组织为一个有N个节点的有向无环图(DAG),其中每个节点定义一个网络层。有一个预定义的操作空间,用O表示,对于Od 每一个元素,
o
(
⋅
)
o(\cdot)
o(⋅) 是一个固定的操作(如恒等连接,和3x3卷积)在网络层执行。在一个单元中,目标是从O中选择一个操作来连接每一对节点。设一对节点为(i,j),其中
0
≤
i
<
j
≤
N
−
1
0\le i<j\le N-1
0≤i<j≤N−1,DART的核心思想是将从i到j传播的信息表示为| O |运算的加权和,也就是;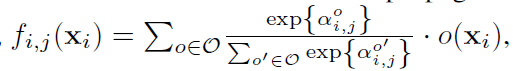
其中
x
i
x_i
xi是第i个节点的输出,
α
i
,
j
o
\alpha^o_{i,j}
αi,jo 是加权操作
o
(
x
i
)
o(x_i)
o(xi)的超参数。节点的输出是所有输入流的和,例如,
x
j
=
Σ
i
<
j
f
i
,
j
(
x
i
)
x_j=\Sigma_{i<j}f_{i,j}(x_i)
xj=Σi<jfi,j(xi),整个单元(cells)的输出是由节点
x
2
−
x
N
−
1
x_2-x_{N-1}
x2−xN−1的输出concatenating,例如
c
o
n
c
a
t
(
x
2
,
x
3
,
.
.
.
,
x
N
−
1
)
concat(x_2,x_3,...,x_{N-1})
concat(x2,x3,...,xN−1)。注意,前两个节点(
x
0
x_0
x0和
x
1
x_1
x1)是单元的输入节点,它们在架构搜索期间是固定的。
这种设计使得整个框架对层权重和超参数
α
i
,
j
o
\alpha^o_{i,j}
αi,jo 都是可微的,以便能够以端到端方式执行架构搜索。搜索过程结束后,对每条边(i,j),
α
i
,
j
o
\alpha^o_{i,j}
αi,jo 的值最大的对应的操作o被保留,and each node j is connected to two precedents i < j with the largest
α
i
,
j
o
\alpha^o_{i,j}
αi,jo preserved.
3.2 Partial Channel Connections
DARTS的一个缺点在于它的内存效率低下。为了适应|O|个operations,在搜索架构的主要部分,|O|个候选操作及其输出的副本需要存储在每个节点上(即,每个网络层),导致|O|倍的内存使用。为了适应GPU,必须在搜索过程中减少批量大小,这不可避免地降低了搜索速度,并且可能会降低搜索的稳定性和准确性。
另外,另一种内存效率解决方案是图1所示的部分通道连接。

图1:提议的方法的图解,部分连接的DARTS(PC-DARTS)。作为一个示例,我们将研究如何将信息传播到node#3,i.e.,j=3。搜索过程中有两组超参数,即
{
α
i
,
j
o
}
\{\alpha^o_{i,j}\}
{αi,jo}和
{
β
i
,
j
}
\{\beta_{i,j}\}
{βi,j},其中
0
≤
i
<
j
0\le i<j
0≤i<j 且
o
∈
O
o\in O
o∈O。为了确定
{
α
i
,
j
o
}
\{\alpha^o_{i,j}\}
{αi,jo} 我们只对通道的一个1/K子集进行采样,并将它们连接到下一个阶段,所以内存消耗减少了K倍。为了最小化采样带来的不确定性,我们添加
{
β
i
,
j
}
\{\beta_{i,j}\}
{βi,j} 作为额外的边缘级参数。
以
x
i
x_i
xi 到
x
j
x_j
xj 为例,这涉及到定义一个通道采样掩码
S
i
,
j
S_{i,j}
Si,j ,将1分配给选定的通道,0分配给屏蔽通道。所选通道被发送到| O |操作的混合计算中,而屏蔽通道绕过这些操作,即它们被直接复制到输出端,
f
i
,
j
P
C
(
x
i
;
S
i
,
j
)
=
Σ
o
∈
O
e
x
p
{
α
i
,
j
o
}
Σ
o
′
∈
O
e
x
p
{
α
i
,
j
0
′
}
⋅
o
(
S
i
,
j
∗
x
i
)
+
(
1
−
S
i
,
j
)
∗
x
i
f_{i,j}^{PC}(x_i;S_{i,j})=\Sigma_{o\in O}\frac{exp\{\alpha_{i,j}^o\}}{\Sigma_{o^{'}\in O}exp\{\alpha^{0'}_{i,j}\}}\cdot o(S_{i,j}*x_i)+(1-S_{i,j})*x_i
fi,jPC(xi;Si,j)=Σo∈OΣo′∈Oexp{αi,j0′}exp{αi,jo}⋅o(Si,j∗xi)+(1−Si,j)∗xi (1)
其中
S
i
,
j
∗
x
i
S_{i,j}*x_i
Si,j∗xi和
(
1
−
S
i
,
j
)
∗
x
i
(1-S_{i,j})*x_i
(1−Si,j)∗xi分别表示所选通道和掩码通道。在实践中,我们通过将K作为超参数,将所选通道的比例设置为1/K。通过改变K,我们可以在架构搜索精度(较小的K)和效率(较大的K)之间进行权衡,以达到平衡(有关更多详细信息,请参阅第4.4.1节)。
K带来的直接好处是计算
f
i
,
j
P
C
(
x
i
;
S
i
,
j
)
f_{i,j}^{PC}(x_i;S_{i,j})
fi,jPC(xi;Si,j)的内存开销被减少了K倍。这允许我们使用更大的批处理大小来进行架构搜索。这样做有两个好处。首先,计算成本也可以减少K倍。此外,较大的批处理大小意味着在每次迭代期间可以采样更多的训练数据,这对于架构搜索尤其重要。在大多数情况下,一个操作相对于另一个操作的优势并不显著,除非在一个小批量中涉及更多的训练数据,以减少更新网络权值和体系结构参数时的不确定性。
3.3 Edge Normalization
让我们来看看采样通道对神经结构搜索的影响。既有积极的影响,也有消极的影响。另一方面,通过为操作混合提供一小部分通道同时保持剩余部分不变,我们可以减少选择操作时的偏差(we make it less biased in selecting operations)。换句话说,对于边
e
d
g
e
(
i
,
j
)
edge(i,j)
edge(i,j), 给定一个输入
x
i
x_i
xi,由于只有一小部分(1/K)输入通道通过操作混合,而其余通道保持不变,因此使用两组超参数
{
α
i
,
j
o
}
\{\alpha^o_{i,j}\}
{αi,jo}和
{
α
i
,
j
o
′
}
\{\alpha^{o^{'}}_{i,j}\}
{αi,jo′}的差别大大减小。这削弱了O中无权重操作(例如,skip-connect、max-pooling等)相对于有权重操作(例如,各种卷积)的优势。在早期阶段,搜索算法通常更倾向于无权重操作,因为它们没有训练的权重,因此产生更一致的输出,即
O
(
x
i
)
O(x_i)
O(xi)。与之相反,在权重优化之前,需要权重的那些操作会在迭代中传播不一致的信息。这样无权重的运算会的权重将会很大,后续有权重的运算优化的很好也无法超过他们。当代理数据集(在其上执行体系结构搜索)很困难时,这种现象尤其重要,这使得dart无法在ImageNet上执行令人满意的体系结构搜索。在实验中,我们将证明PC-DART具有部分通道连接,在ImageNet上产生更稳定和更优越的性能。
不利的地方是,在cell中,每一个节点
x
j
x_j
xj 的输出需要从
{
x
0
,
x
1
,
.
.
.
,
x
j
−
1
}
\{x_0,x1,...,x_{j-1}\}
{x0,x1,...,xj−1}中选取两个输入节点,权重分别为:
m
a
x
o
α
0
,
j
o
,
m
a
x
o
α
1
,
j
o
,
…
,
m
a
x
o
α
j
−
1
,
j
o
max_o \alpha ^ o _ {0, j}, max_o \alpha ^ o _ {1, j}, \dots, max_o \alpha ^ o _ {j-1, j}
maxoα0,jo,maxoα1,jo,…,maxoαj−1,jo 。然而,这些架构参数是通过迭代过程中随机采样的通道优化的,因此当采样通道随时间变化时,由它们确定的最佳连接性可能是不稳定的。这可能会导致生成的网络体系结构出现意外的波动。为了缓解这个问题,我们引入了边规范化,它显式地对每个边(i,j)进行加权,用
β
i
,
j
\beta_{i,j}
βi,j表示,这样
x
j
x_j
xj的计算变成:
x
j
P
C
=
Σ
i
<
j
e
x
p
{
β
i
,
j
}
Σ
i
′
<
j
e
x
p
{
β
i
′
,
j
}
⋅
f
i
,
j
(
x
j
)
\mathbf{x}_{j}^{PC}=\Sigma_{i<j}\frac{exp\{\beta_{i,j}\}}{\Sigma_{i^{'}<j}exp\{\beta_{i^{'},j}\}}\cdot f_{i,j}(\mathbf{x}_j)
xjPC=Σi<jΣi′<jexp{βi′,j}exp{βi,j}⋅fi,j(xj)
具体来说,架构搜索完成后,edge(i,j)的连接性由
{
α
i
,
j
o
}
\{\alpha^o_{i,j}\}
{αi,jo}和
{
β
i
,
j
}
\{\beta_{i,j}\}
{βi,j},为此我们将归一化系数相乘,即
e
x
p
{
β
i
,
j
}
Σ
i
′
<
j
e
x
p
{
β
i
′
,
j
}
\frac{exp\{\beta_{i,j}\}}{\Sigma_{i^{'}<j}exp\{\beta_{i^{'},j}\}}
Σi′<jexp{βi′,j}exp{βi,j}与
e
x
p
{
α
i
,
j
o
}
Σ
o
′
∈
O
e
x
p
{
α
i
,
j
o
′
}
\frac{exp\{\alpha^o_{i,j}\}}{\Sigma_{o^{'}\in O}exp\{\alpha_{i,j}^{o^{'}}\}}
Σo′∈Oexp{αi,jo′}exp{αi,jo}相乘。然后通过找到大的边权值来选择边,就像在DARTS中一样。由于
β
i
,
j
\beta_{i,j}
βi,j 是整个训练过程共享的,因此学习的网络体系结构不太容易在迭代过程中使用采样通道,从而使体系结构搜索更加稳定。(Since
β
i
,
j
\beta_{i,j}
βi,j are shared through the training process, the learned network architecture is less prone to the sampled channels across iterations, making the architecture search more stable.)
4 Experiments
4.1 Datasets and Implementation Details
我们在CIFAR10和ImageNet上进行了实验,这两个最流行的数据集用于评估神经架构搜索。CIFAR10[15]由60K个图像组成,所有图像的空间分辨率均为32 x 32。这些图片平均分布在10个班级,有5万张训练和10万张测试图片。ImageNet[7]包含1000个对象类别,130万个训练图像和50K个验证图像,所有这些图像都是高分辨率的,在所有类中大致均匀分布。按照惯例[35,19],我们应用mobile setting,其中输入图像大小固定为224x 224,并且在测试阶段multi-add操作的数量不超过600M。
遵循DARTS[19]和传统的架构搜索方法,我们使用一个单独的阶段进行架构搜索,在获得最佳架构之后,我们从头开始执行另一个训练过程。在搜索阶段,目标是确定最佳的超参数集,即每条边
(
i
,
j
)
(i,j)
(i,j)的
{
α
i
,
j
o
}
\{\alpha^o_{i,j}\}
{αi,jo}和
{
β
i
,
j
}
\{\beta_{i,j}\}
{βi,j}。为此,将训练集分成两部分,第一部分用于优化网络参数,例如卷积权重,第二部分用于优化超参数。整个搜索阶段是以端到端的方式完成的。为了公平比较,操作空间O与约定相同,它包含8个选择,即3x3和5x5separable convolution、3x3和5x5dilated separable
convolution、3x3最大池化、3x3平均池化、skip-connect (identity)和zero (none)。
我们为部分通道连接提出了一种可选的、更有效的实现方法。对于边(i,j),我们不再每次计算
o
(
x
i
)
o(\mathbf{x_i})
o(xi)时执行通道采样,而是直接选择
x
i
\mathbf{x}_i
xi的第一个1/K通道用于操作混合。为了进行补偿,在得到
x
j
\mathbf{x}_j
xj之后,我们对它的通道进行洗牌,然后再使用它进行进一步的计算。这与ShuffleNet[31]中使用的实现相同,后者对GPU更友好,因此运行速度更快。
4.2 Results on CIFAR10
在搜索场景中over-parameterized network由8个单元(6个正常单元和2个缩减(reduction)单元)叠加而成,每个单元由N=6个节点组成。我们对网络进行50个阶段的训练,最初的通道数是16个。CIFAR10的50K训练集被分成两个大小相等的子集,其中一个子集用于训练网络权值,另一个子集用于架构超参数。


我们为CIFAR10设置了K=4,即每边只采样1/4个特征,使得搜索时的批处理大小增加到256。此外,following[6],我们冻结了网络超参数,只允许在前15个阶段调整网络参数。这是为网络参数提供预热,从而减轻参数化操作的缺点。总内存成本小于12GB,因此我们可以在大多数现代GPU上对其进行训练。采用动量SGD优化网络权值,初始学习率为0.1(按照余弦规律不重启退火为零),权值衰减为
3
×
1
0
−
4
3\times10^{-4}
3×10−4,动量为0.9。我们使用Adam优化器[14]来处理超参数
(
i
,
j
)
(i,j)
(i,j)的
{
α
i
,
j
o
}
\{\alpha^o_{i,j}\}
{αi,jo}和
{
β
i
,
j
}
\{\beta_{i,j}\}
{βi,j} ,用一个固定学习率
6
×
1
0
−
4
6\times10^{-4}
6×10−4,动量为 (0.5; 0.999),权重衰减为
1
0
−
3
10^{-3}
10−3。
由于批量的增加,整个搜索过程只需要3个小时在一个NVIDIA GTX 1080Ti GPU上,或1.5个小时在一个Tesla V100 GPU上,这几乎是4倍的速度比原来的一阶DARTS。
评估阶段简单地跟DARTS一样。该网络由20个cells(18个正常cells和2个reduction cells)组成,每种cells结构相同。初始信道数为36。整个50K训练集被使用,网络是从零开始训练600个epoch,使用128的批量大小。我们使用的SGD优化器的初始学习率为0.025(按照余弦计划退火到零而不重新启动),动量为0.9,权重衰减为
3
×
1
0
−
4
3\times10^{-4}
3×10−4,范数梯度剪裁为5。速率为0.3的Drop-path以及cutout[8]也用于正则化。我们在图2的左侧看到搜索到的正常cells和reduction cells。

表1总结了结果并与最近的方法进行了比较。在仅仅0.1gpu-days的时间里,PC-DARTS的错误率达到了2.57%,搜索时间和准确率都大大超过了baseline DARTS。据我们所知,我们的方法是最快的方法,其错误率小于3%。我们的数字在最近的架构搜索结果中排名第一。ProxylessNAS使用了一个不同的协议来实现2.08%的错误率,并且报告了一个更长的架构搜索时间。P-DARTS[6]通过搜索更深层次的体系结构,稍微优于我们的方法,我们强调我们的方法可以与之结合。
4.3 Results on ImageNet
我们稍微修改了CIFAR10上使用的网络架构以适应ImageNet。 overparameterized network以步长2的三个卷积层开始,以将输入图像分辨率从224x 224降低到28x 28。8个单元格(6个正常单元格和2个缩减单元格)堆叠在该点之外,每个单元格由N=6个节点组成。为了减少搜索时间,我们从ImageNet的1.3M训练集中随机抽取两个子集,分别抽取10%和2.5%的图像,前者用于训练网络权值,后者用于更新超参数。
ImageNet比CIFAR10困难得多。为了保留更多信息,我们使用1/2的子采样率,这是CIFAR10中使用的子采样率的两倍。尽管如此,总共有50个时代被训练,在前35个时代中,架构超参数被冻结。对于网络权值,我们使用初始学习率为0.5的动量SGD(按照余弦时间表不重新启动而退火为零)、动量为0.9和权值衰减为
3
×
1
0
−
5
3\times10^{-5}
3×10−5。对于超参数,我们使用Adam优化器[14],它的固定学习率为
6
×
1
0
−
3
6\times10^{-3}
6×10−3,动量(0.5;0.999)和权重衰减为
1
0
−
3
10^{-3}
10−3。我们使用8台特斯拉V100 gpu进行搜索,总批量大小为1024。整个搜索过程大约需要11.5个小时。我们在图2的右侧将搜索到的正常cells和reduction cells可视化。
评估阶段遵循DARTS的步骤,也从三个stride为2的卷积层开始,这三个卷积层将输入图像的分辨率从224x 224降低到28x 28。14个cells(12个正常cells和2个reduction cells)堆叠在该点之后,初始通道数为48。该网络是从零开始训练的250个epoch使用批量大小为1024。我们使用的SGD优化器的动量为0.9,初始学习率为0.5(线性衰减为零),权重衰减为
3
×
1
0
−
5
3\times 10^{-5}
3×10−5。在训练期间,还采用了其他增强功能,包括标签平滑和an auxiliary loss tower。前5个阶段采用学习率warm-up。
结果汇总在表2中。请注意,在CIFAR10上搜索的架构和ImageNet本身都是经过评估的。对于前者,它报告了25.1%/7.8%的top-1/5 error,这明显优于DARTS报告的26.7%/8.7%。这是令人印象深刻的,因为我们的搜索时间要短得多。对于后者,我们达到了24.2%/7.3%的top-1/5 accuracy,这是迄今为止最著名的性能。相比之下,ProxylessNAS[4],另一种直接在ImageNet上搜索的方法,使用了几乎两倍的时间来产生24.9%/7.5%,这证明我们减少内存消耗的策略更有效。

4.4 Ablation Study
4.4.1 Effectiveness of Channel Proportion 1=K
我们首先计算控制信道采样率的超参数K。注意,存在一个折衷:增加采样率(即使用smaller K)允许传播更精确的信息,而采样较小部分的信道会产生更重的正则化,并可能缓解过度拟合。为了研究其影响,我们评估了四种采样率(即1/1、1/2、1/4和1/8)对CIFAR10的性能,并将结果绘制成图3中的搜索时间和准确性图表。我们可以观察到,1/4的采样率在时间和累积性方面都优于1/2和1/1。使用1/8,虽然可以进一步减少搜索时间,但会导致显著的准确性下降。
4.4.2 Contributions of Different Components of PC-DARTS
率在时间和累积性方面都优于1/2和1/1。使用1/8,虽然可以进一步减少搜索时间,但会导致显著的准确性下降。
4.4.2 Contributions of Different Components of PC-DARTS
接下来,我们评估PC-DART的两个组件所做的贡献,即部分通道连接和边缘规范化。结果汇总在表3中。很明显,即使在通道完全连通的情况下,边缘归一化也会带来正则化的效果。作为一个额外成本很少的组件,它可以自由地应用于涉及边缘选择的各种方法。此外,边缘规范化与部分信道连接很好地配合,以提供进一步的改进。在没有边缘规范化的情况下,该方法在网络参数个数和精度上都有较低的稳定性。在CIFAR10上,我们多次运行无边缘归一化的搜索,测试误差在2.54%~3.01%之间。另一方面,在边缘归一化的情况下,五次运行之间的最大差异不超过0.15%。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)