论文名称:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
论文下载:https://arxiv.org/abs/1807.11164
论文年份:2018
论文被引:2162(2022/05/12)
Abstract
Currently, the neural network architecture design is mostly guided by the indirect metric of computation complexity, i.e., FLOPs. However, the direct metric, e.g., speed, also depends on the other factors such as memory access cost and platform characterics. Thus, this work proposes to evaluate the direct metric on the target platform, beyond only considering FLOPs. Based on a series of controlled experiments, this work derives several practical guidelines for efficient network design. Accordingly, a new architecture is presented, called ShuffleNet V2. Comprehensive ablation experiments verify that our model is the stateof-the-art in terms of speed and accuracy tradeoff.
目前,神经网络架构设计主要由计算复杂度的间接度量,即 FLOPs 指导。但是,直接指标(例如速度)还取决于其他因素,例如内存访问成本和平台特性。因此,这项工作建议评估目标平台上的直接指标,而不仅仅是考虑 FLOP。基于一系列受控实验,这项工作得出了几个有效网络设计的实用指南。因此,提出了一种新的架构,称为 ShuffleNet V2。全面的消融实验验证了我们的模型在速度和准确率的权衡方面是最先进的。
1 Introduction
深度卷积中性网络 (CNN) 的架构已经发展了多年,变得更加准确和快速。自从 AlexNet [1] 的里程碑式工作以来,ImageNet 的分类精度已经通过新的结构得到显着提高,包括 VGG [2]、GoogLeNet [3]、ResNet [4,5]、DenseNet [6]、ResNeXt [7]、 SE-Net [8] 和自动中性架构搜索 [9,10,11] 等等。
除了准确性之外,计算复杂性是另一个重要的考虑因素。现实世界的任务通常旨在在有限的计算预算下获得最佳精度,由目标平台(例如,硬件)和应用场景(例如,自动驾驶需要低延迟)给出。这激发了一系列针对轻量级架构设计和更好的速度-准确性权衡的工作,包括 Xception [12]、MobileNet [13]、MobileNet V2 [14]、ShuffleNet [15] 和 CondenseNet [16] 等等。分组卷积和深度卷积在这些工作中至关重要。
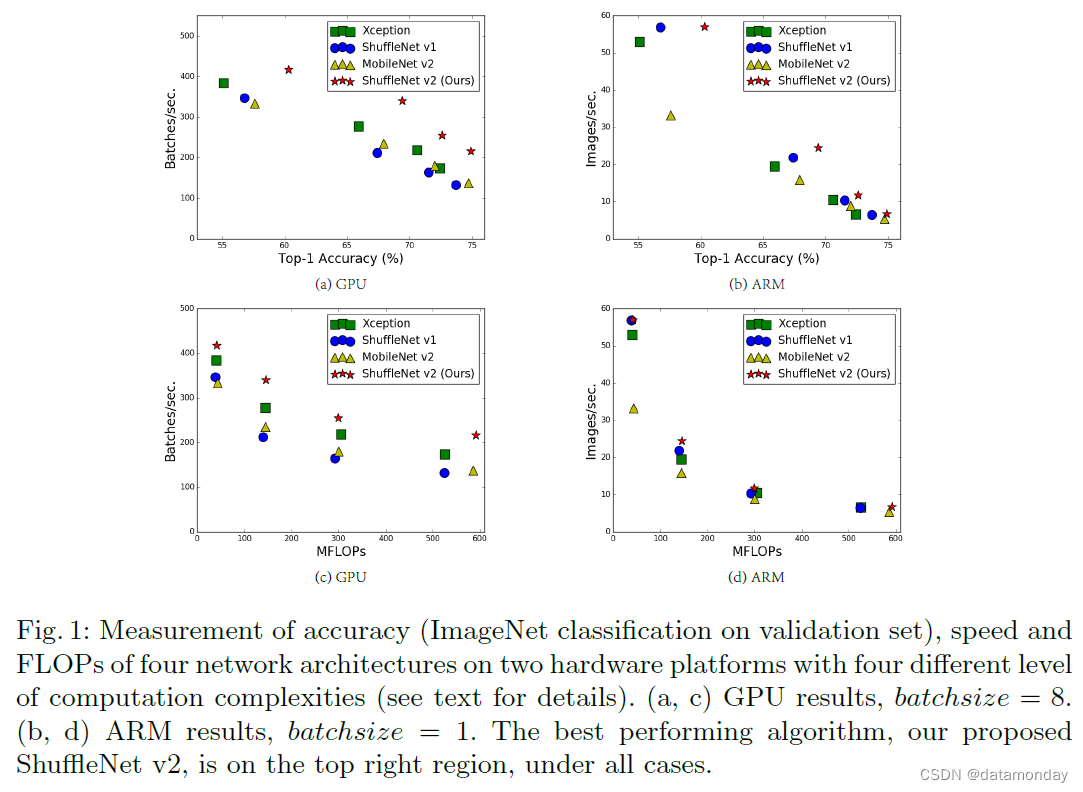
为了衡量计算复杂性,一个广泛使用的指标是浮点运算的数量,或FLOPs。但是,FLOPs是一个间接指标。这是一个近似值,但通常不等同于我们真正关心的直接指标,如速度或延迟。这种差异在以前的著作中已经注意到 [17,18,14,19]。例如,MobileNet v2 [14] 比 NASNET-A [9] 快得多,但它们的FLOPs相当。这种现象在图 1 © (d) 中得到进一步说明,图中显示了具有相似FLOPs的网络具有不同的速度。因此,使用FLOPs作为计算复杂度的唯一度量是不够的,并且可能导致次优设计。
间接(FLOPs)和直接(速度)指标之间的差异可归因于两个主要原因。首先,FLOP 没有考虑对速度有相当大影响的几个重要因素。其中一个因素是内存访问成本 (memory access cost, MAC)。在某些操作(如组卷积)中,这种成本占运行时间的很大一部分。它可能是具有强大计算能力的设备(例如 GPU)的瓶颈。在网络架构设计期间不应简单地忽略此成本。另一个是并行度。在相同的 FLOP 下,具有高度并行性的模型可能比另一个具有低并行度的模型快得多。
其次,具有相同 FLOP 的操作可能具有不同的运行时间,具体取决于平台。例如,张量分解在早期的工作中被广泛使用 [20,21,22] 来加速矩阵乘法。然而,最近的工作 [19] 发现 [22] 中的分解在 GPU 上甚至更慢,尽管它减少了 75% 的 FLOP。我们调查了这个问题,发现这是因为最新的 CUDNN [23] 库专门针对 3 × 3 conv 进行了优化。我们当然不能认为 3 × 3 conv 比 1 × 1 conv 慢 9 倍。
有了这些观察,我们建议应该考虑两个原则来进行有效的网络架构设计。首先,应该使用直接指标(例如速度)而不是间接指标(例如 FLOPs)。其次,应在目标平台上评估此类指标。
在这项工作中,我们遵循这两个原则,并提出了一种更有效的网络架构。在第 2 节中,我们首先分析了两个具有代表性的最先进网络的运行时性能 [15,14]。然后,我们得出了高效网络设计的四个准则,这些准则不仅仅考虑了 FLOP。虽然这些指南与平台无关,但我们执行了一系列受控实验,以在两个不同的平台(GPU 和 ARM)上通过专门的代码优化对其进行验证,确保我们的结论是最先进的。
在第 3 节中,根据指南,我们设计了一个新的网络结构。由于它受到 ShuffleNet [15] 的启发,因此被称为 ShuffleNet V2。通过第 4 节中的综合验证实验,证明了它比两个平台上的先前网络更快、更准确。图 1(a)(b) 给出了比较的概述。例如,给定 40M FLOPs 的计算复杂度预算,ShuffleNet v2 分别比 ShuffleNet v1 和 MobileNet v2 高 3.5% 和 3.7%。
2 Practical Guidelines for Efficient Network Design
我们的研究是在两个广泛采用的硬件上进行的,并对 CNN 库进行了行业级优化。我们注意到我们的 CNN 库比大多数开源库更高效。因此,我们确保我们的观察和结论是可靠的,并且对工业实践具有重要意义。
其他设置包括:打开完整的优化选项(例如张量融合,用于减少小型操作的开销)。输入图像大小为 224 × 224。每个网络随机初始化并评估 100 次。使用平均运行时间。
为了开始我们的研究,我们分析了两个最先进的网络 ShuffleNet v1 [15] 和 MobileNet v2 [14] 的运行时性能。它们在 ImageNet 分类任务上既高效又准确。它们都广泛用于移动设备等低端设备。虽然我们只分析这两个网络,但我们注意到它们代表了当前的趋势。它们的核心是分组卷积和深度卷积,它们也是其他最先进网络的关键组件,例如 ResNeXt [7]、Xception [12]、MobileNet [13] 和 CondenseNet [16]。
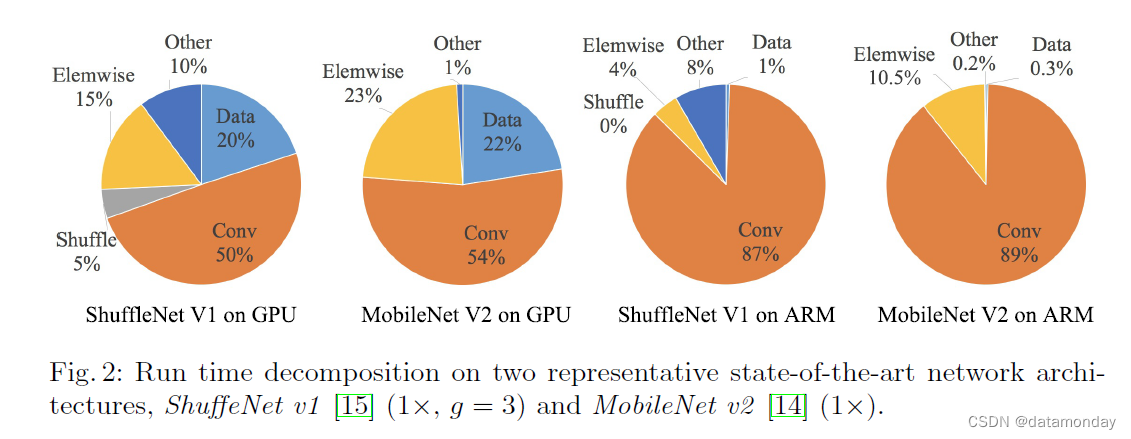
整个运行时间被分解为不同的操作,如图 2 所示。我们注意到 FLOPs 指标仅考虑卷积部分。虽然这部分消耗的时间最多,但其他操作包括数据 I/O、数据 shuffle 和元素操作(AddTensor、ReLU 等)也占用了大量时间。因此,FLOPs 对实际运行时间的估计不够准确。
基于这一观察,我们从几个不同方面对运行时间(或速度)进行了详细分析,并得出了一些有效的网络架构设计的实用指南。
G1) 相等的通道宽度将内存访问成本 (MAC) 降至最低。现代网络通常采用深度可分离卷积[12,13,15,14],其中点卷积(即1×1卷积)占了大部分复杂度[15]。我们研究了 1×1 卷积的核形状。形状由两个参数指定:输入通道 c1 和输出通道 c2 的数量。设 h 和 w 为特征图的空间大小,1×1 卷积的 FLOPs 为 B = hwc1c2。
为简单起见,我们假设计算设备中的缓存足够大,可以存储整个特征图和参数。因此,内存访问成本 (MAC) 或内存访问操作数为 MAC = hw(c1+c2)+c1c2。请注意,这两个术语分别对应于输入/输出特征图和内核权重的内存访问。
从均值不等式,我们有
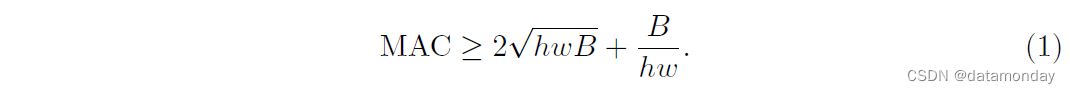
因此,MAC 具有由 FLOPs 给出的下限。当输入和输出通道数相等时,它达到下限。
结论是理论上的。实际上,许多设备上的缓存都不够大。此外,现代计算库通常采用复杂的阻塞策略来充分利用缓存机制[24]。因此,实际 MAC 可能会偏离理论值。为了验证上述结论,进行如下实验。通过重复堆叠 10 个构建块来构建基准网络。每个块包含两个卷积层。第一个包含 c1 输入通道和 c2 输出通道,第二个则包含。
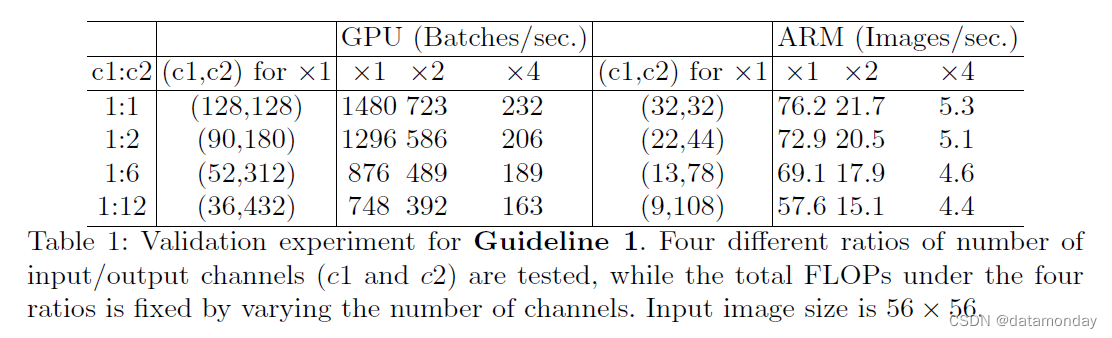
表 1 通过改变比率 c1 : c2 来报告运行速度,同时固定总 FLOPs。很明显,当 c1 : c2 接近 1 : 1 时,MAC 变小,网络评估速度更快。
G2) 过多的分组卷积会增加 MAC。分组卷积是现代网络架构的核心 [7,15,25,26,27,28]。它通过将所有通道之间的密集卷积更改为稀疏(仅在通道组内)来降低计算复杂度(FLOP)。一方面,它允许在给定固定 FLOP 的情况下使用更多通道并增加网络容量(从而提高准确性)。然而,另一方面,增加的通道数量会导致更多的 MAC。形式上,遵循 G1 和 Eq 1 中的符号,1×1 组卷积的 MAC 和 FLOPs 之间的关系是
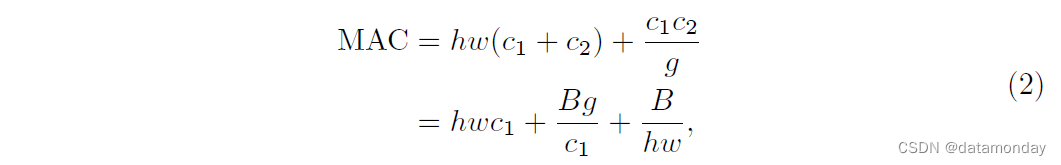
其中 g 是组数,B = hwc1c2/g 是 FLOP。很容易看出,给定固定的输入形状 c1 × h × w 和计算成本 B,MAC 随着 g 的增长而增加。为了在实践中研究这种影响,通过堆叠 10 个逐点组卷积层来构建基准网络。
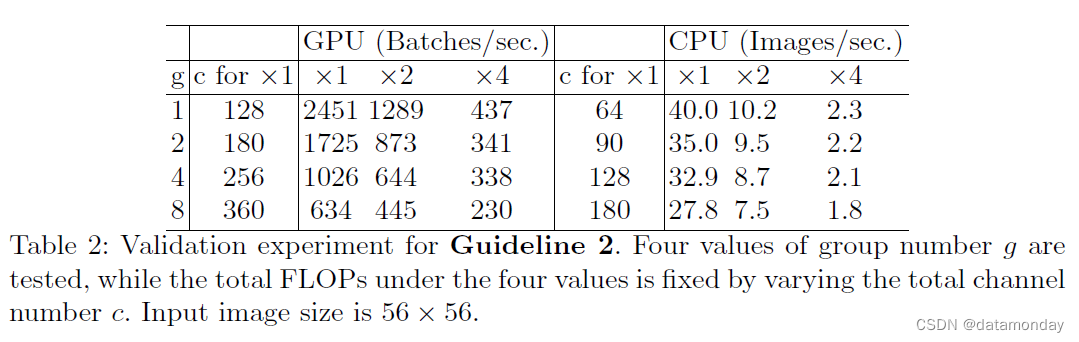
表 2 报告了在固定总 FLOP 时使用不同组号的运行速度。很明显,使用较大的组数会显着降低运行速度。例如,在 GPU 上使用 8 组比使用 1 组(标准密集卷积)慢两倍以上,在 ARM 上慢达 30%。这主要是由于 MAC 增加所致。我们注意到我们的实现已经过特别优化,并且比逐组计算卷积要快得多。
因此,我们建议应根据目标平台和任务谨慎选择分组数量。仅仅因为使用更多通道而使用较大的组数是不明智的,因为快速增加的计算成本很容易超过准确性提高的好处。
G3) 网络碎片(fragmentation)降低了并行度。在 GoogLeNet 系列 [29,30,3,31] 和自动生成的架构 [9,11,10])中,每个网络块都广泛采用“多路径”结构。使用了很多小的算子(这里称为“碎片算子”)而不是几个大的算子。例如,在 NASNET-A [9] 中,碎片化算子的数量(即一个构建块中的单个卷积或池化操作的数量)是 13。相比之下,在像 ResNet [4] 这样的常规结构中,这个数字是 2 或 3。
虽然这种碎片化的结构已被证明有利于准确性,但它可能会降低效率,因为它对 GPU 等具有强大并行计算能力的设备不友好。它还引入了额外的开销,例如内核启动和同步。
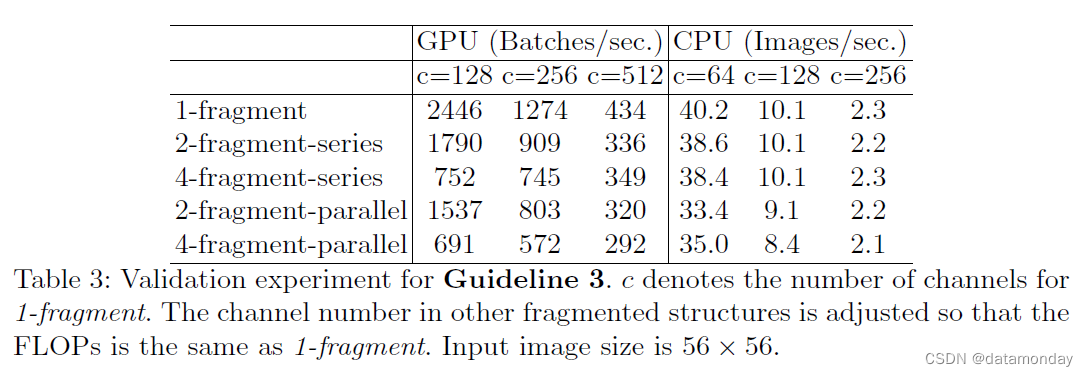
为了量化网络碎片如何影响效率,我们评估了一系列具有不同碎片程度的网络块。具体来说,每个构建块由 1 到 4 个 1×1 卷积组成,这些卷积按顺序或平行排列。块结构在附录中说明。每个块重复堆叠 10 次。表 3 中的结果表明,碎片会显着降低 GPU 上的速度,例如 4 片段结构比 1 片段慢 3 倍。在 ARM 上,速度降低相对较小。
G4) 逐元素操作是不可忽略的。如图 2 所示,在像 [15,14] 这样的轻量级模型中,逐元素操作会占用大量时间,尤其是在 GPU 上。这里,element-wise 算子包括 ReLU、AddTensor、AddBias 等。它们的 FLOP 较小,但 MAC 相对较重。特别是,我们还考虑将深度卷积 [12,13,14,15] 作为元素级算子,因为它还具有较高的 MAC/FLOPs 比率。
为了验证,我们在 ResNet [4] 中尝试了“瓶颈”单元(1 × 1 conv,然后是 3 × 3 conv,然后是 1 × 1 conv,带有 ReLU 和快捷连接)。 ReLU 和快捷操作被分别删除。表 4 中报告了不同变体的运行时间。我们观察到,在移除 ReLU 和快捷方式后,GPU 和 ARM 都获得了大约 20% 的加速。

结论与讨论 基于上述指导方针和实证研究,我们得出结论,一个有效的网络架构应该
- 1)使用“平衡”卷积(相等的通道宽度)
- 2)注意使用组卷积的成本
- 3)降低碎片化程度
- 4)减少元素操作
这些理想的属性取决于超出理论 FLOP 的平台特性(例如内存操作和代码优化)。在实际的网络设计中应考虑到它们。
轻量级神经网络架构 [15,13,14,9,11,10,12] 的最新进展主要基于 FLOP 的度量,并没有考虑上述这些属性。例如,ShuffleNet v1 [15] 严重依赖组卷积(针对 G2)和类似瓶颈的构建块(针对 G1)。 MobileNet v2 [14] 使用了违反 G1 的倒置瓶颈结构。它在“厚”特征图上使用深度卷积和 ReLU。这违反了 G4。自动生成的结构 [9,11,10] 高度分散并违反 G3。
3 ShuffleNet V2: an Efficient Architecture
回顾 ShuffleNet v1 [15]。 ShuffleNet 是一种最先进的网络架构。它广泛用于手机等低端设备。它启发了我们的工作。因此,首先对其进行回顾和分析。
根据 [15],轻量级网络的主要挑战是在给定的计算预算(FLOPs)下只有有限数量的特征通道是负担得起的。为了在不显着增加 FLOP 的情况下增加通道数量,[15] 中采用了两种技术:逐点组卷积和类似瓶颈的结构。然后引入**“通道混洗”操作以实现不同通道组之间的信息通信并提高准确性**。构建块如图 3(a)(b) 所示。
如第 2 节所述,逐点组卷积和瓶颈结构都会增加 MAC(G1 和 G2)。这个成本是不可忽略的,特别是对于轻量级模型。此外,使用太多组违反了 G3。快捷连接中的元素方式"Add"操作也是不可取的(G4)。因此,为了实现高模型容量和效率,关键问题是如何在既不密集卷积又不太多组的情况下保持大量且等宽的通道。
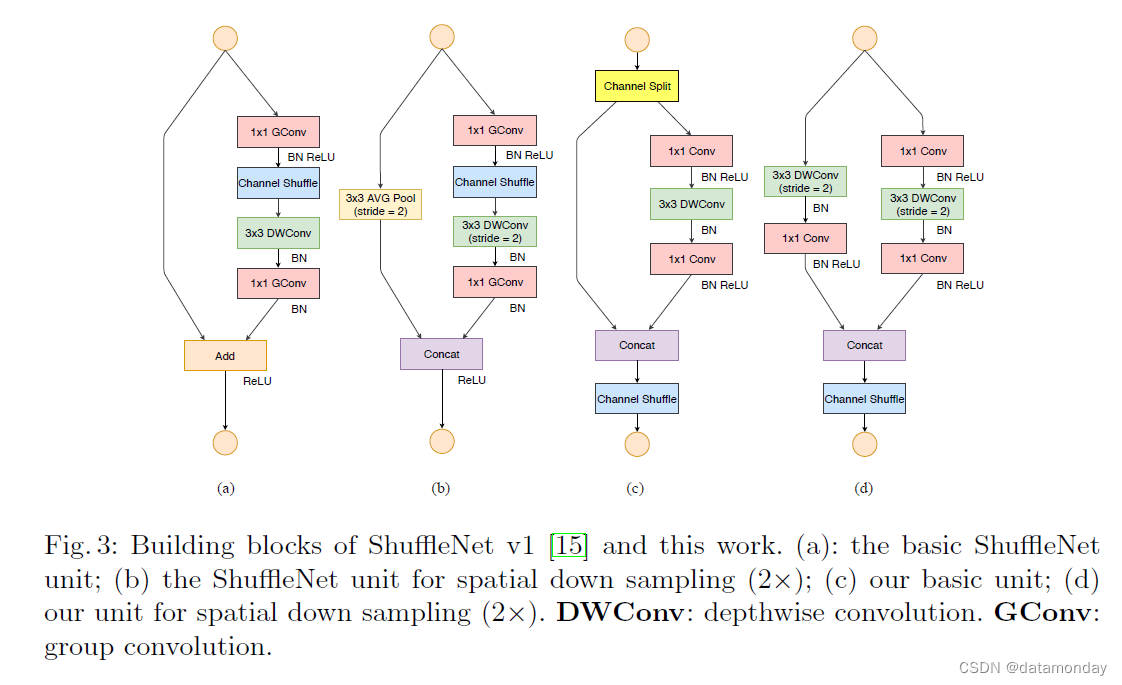
Channel Split 和 ShuffleNet V2 为实现上述目的,我们引入了一个简单的算子,称为 channel split。如图 3© 所示。在每个单元的开始,c 个特征通道的输入被分成两个分支,分别具有 c-c’ 和 c’ 通道。在 G3 之后,一个分支仍然作为身份。另一个分支由三个具有相同输入和输出通道的卷积组成,以满足 G1。与 [15] 不同,这两个 1 × 1 卷积不再是分组的。这部分是遵循 G2,部分是因为拆分操作已经产生了两个组。
卷积之后,将两个分支连接起来。因此,通道数保持不变(G1)。然后使用与 [15] 中相同的“通道混洗”操作来实现两个分支之间的信息通信。
混洗后,下一个单元开始。请注意,ShuffleNet v1 [15] 中的"Add"操作不再存在。像 ReLU 和深度卷积这样的元素操作只存在于一个分支中。此外,三个连续的元素操作,“Concat”、“Channel Shuffle”和“Channel Split”,被合并为一个单独的元素操作。根据 G4,这些变化是有益的。
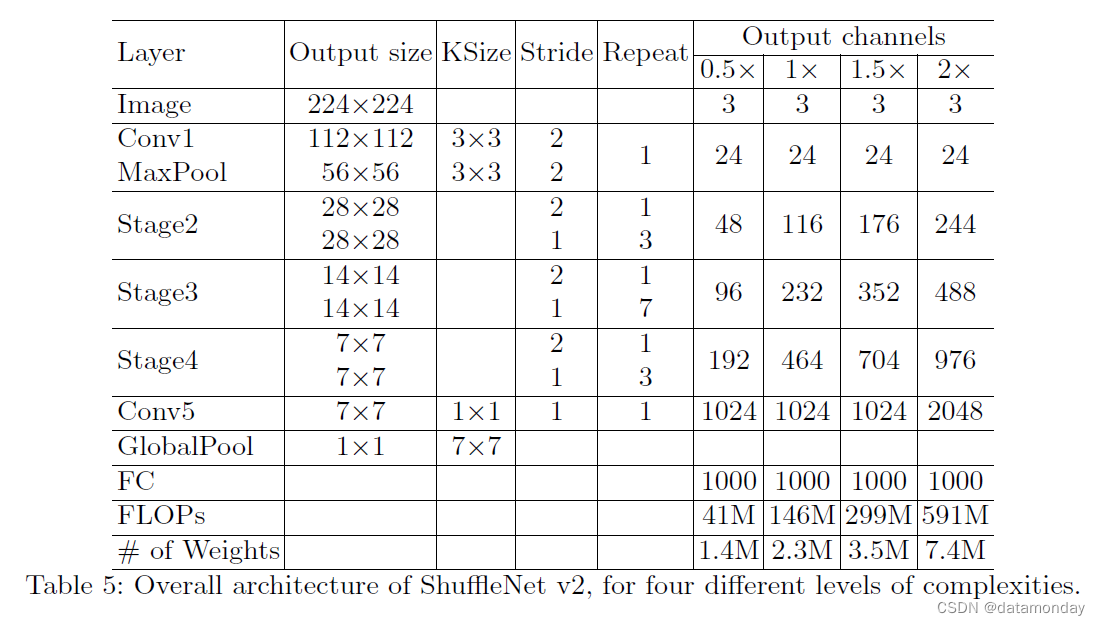
对于空间下采样,该单元稍作修改,如图 3(d) 所示。删除了通道拆分运算符。因此,输出通道的数量增加了一倍。提议的构建块 ©(d) 以及由此产生的网络称为 ShuffleNet V2。基于上述分析,我们得出结论,这种架构设计非常高效,因为它遵循了所有准则。构建块被反复堆叠以构建整个网络。为简单起见,我们设置 c’ = c/2。整个网络结构类似于 ShuffleNet v1 [15],总结在表 5 中。只有一个区别:在全局平均池化之前添加了一个额外的 1×1 卷积层来混合特征,这在 ShuffleNet v1 中是不存在的。与[15]类似,每个块中的通道数被缩放以生成不同复杂度的网络,标记为0.5×、1×等。
网络准确率分析 ShuffleNet v2 不仅高效,而且准确。有两个主要原因。首先,每个构建块的高效率可以使用更多的特征通道和更大的网络容量。
其次,在每个块中,有一半的特征通道(当 c0 = c/2 时)直接通过该块并加入下一个块。这可以看作是一种特征重用,与 DenseNet [6] 和 CondenseNet [16] 的精神相似。
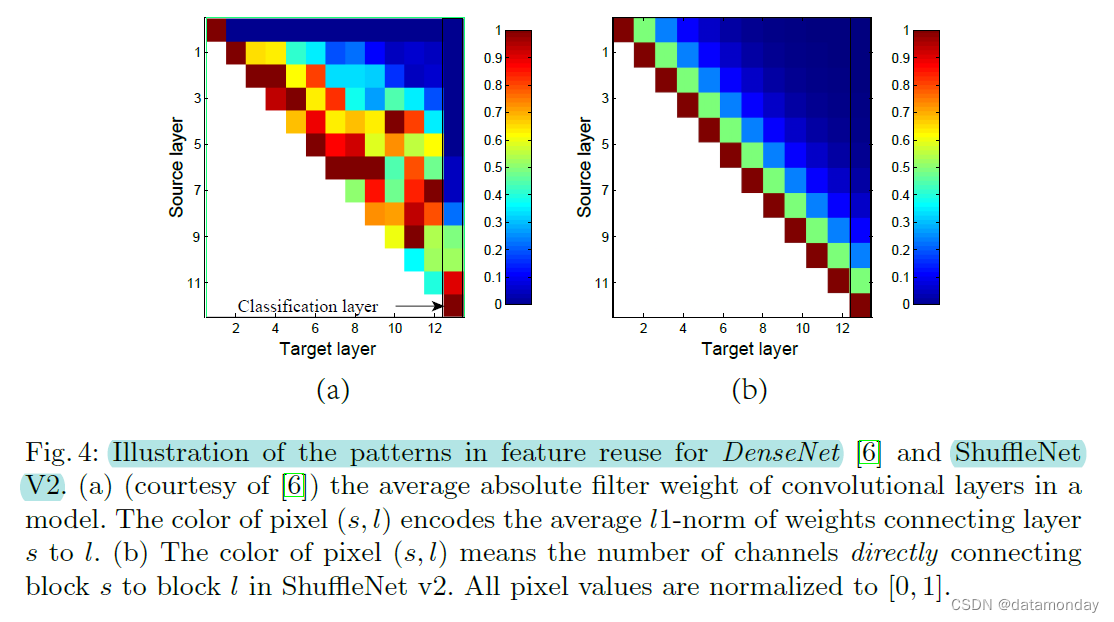
在 DenseNet[6] 中,为了分析特征重用模式,绘制了层间权重的 l1-范数,如图 4(a) 所示。很明显,相邻层之间的连接比其他层更强。这意味着所有层之间的密集连接可能会引入冗余。最近的 CondenseNet [16] 也支持这一观点。
在 ShuffleNet V2 中,很容易证明第
i
i
i 个和第
(
i
+
j
)
(i+j)
(i+j) 个构建块之间“直接连接”的通道数是
r
j
c
r^jc
rjc,其中
r
=
(
1
−
c
′
)
/
c
r = (1−c')/c
r=(1−c′)/c。换句话说,特征重用的数量随着两个块之间的距离呈指数衰减。在遥远的块之间,特征重用变得更弱。图 4(b) 绘制了与 (a) 中相似的可视化,其中 r = 0.5。请注意,(b)中的模式与(a)相似。
因此,ShuffleNet V2 的结构通过设计实现了这种类型的特征重用模式。它与 DenseNet [6] 具有相似的特征重用以实现高精度的好处,但正如前面分析的那样,它的效率要高得多。这在实验中得到验证,表 8。
4 Experiment
我们的消融实验是在 ImageNet 2012 分类数据集 [32,33] 上进行的。按照惯例 [15,13,14],所有比较起来的网络都有四个级别的计算复杂度,即大约 40、140、300 和 500+ MFLOPs。这种复杂性对于移动场景来说是典型的。其他超参数和协议与 ShuffleNet v1 [15] 完全相同。我们与以下网络架构进行比较 [12,14,6,15]:
- ShuffleNet v1 [15]。在[15]中,比较了一系列组数g。建议g = 3在精度和速度之间有更好的权衡。这也与我们的观察一致。在这项工作中,我们主要使用 g = 3。
- MobileNet v2 [14]。它优于 MobileNet v1 [13]。为了进行全面比较,我们报告了原始论文 [14] 和我们重新实现的准确性,因为 [14] 中的某些结果不可用。
- Xception [12]。原始的 Xception 模型 [12] 非常大(FLOPs >2G),超出了我们的比较范围。最近的工作 [34] 提出了一种改进的轻量级 Xception 结构,该结构在准确性和效率之间表现出更好的权衡。因此,我们与此变体进行比较。
- DenseNet [6]。原始工作 [6] 仅报告大型模型(FLOPs >2G)的结果。为了直接比较,我们按照表 5 中的架构设置重新实现它,其中第 2-4 阶段的构建块由 DenseNet 块组成。我们调整通道的数量以满足不同的目标复杂性。
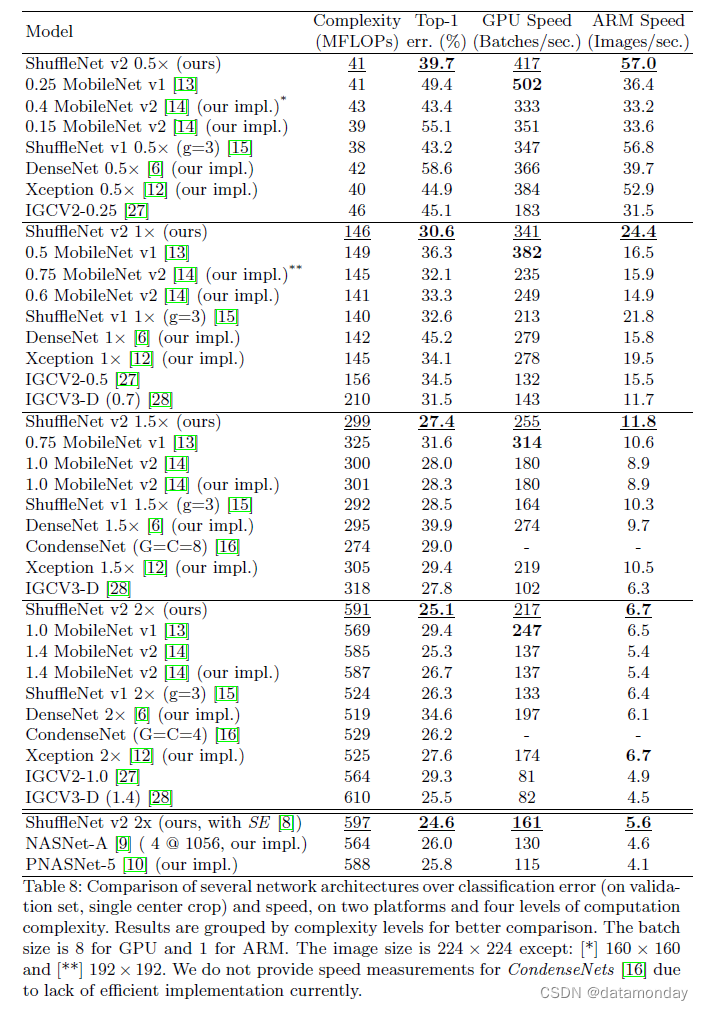
表 8 总结了所有结果。我们从不同方面分析这些结果。
准确性与 FLOPs。很明显,所提出的 ShuffleNet v2 模型在很大程度上优于所有其他网络,尤其是在较小的计算预算下。此外,我们注意到 MobileNet v2 以 40 MFLOPs 级别执行池化,图像大小为 224 × 224。这可能是由于通道太少造成的。相比之下,我们的模型没有这个缺点,因为我们的高效设计允许使用更多通道。此外,虽然我们的模型和 DenseNet [6] 都重用了特征,但我们的模型效率更高,如第 3 节所述。
表 8 还将我们的模型与其他最先进的网络进行了比较,包括 CondenseNet [16]、IGCV2 [27] 和 IGCV3 [28]。我们的模型在各种复杂性级别上始终表现得更好。
推理速度与 FLOPs/准确性。对于准确率较高的四种架构,ShuffleNet v2、MobileNet v2、ShuffleNet v1 和 Xception,我们比较了它们的实际速度与 FLOP,如图 1©(d) 所示。附录表 1 提供了关于不同分辨率的更多结果。
ShuffleNet v2 显然比其他三个网络更快,尤其是在 GPU 上。例如,在 500MFLOPs 时,ShuffleNet v2 比 MobileNet v2 快 58%,比 ShuffleNet v1 快 63%,比 Xception 快 25%。在 ARM 上,ShuffleNet v1、Xception 和 ShuffleNet v2 的速度相当;但是,MobileNet v2 慢得多,尤其是在较小的 FLOP 上。我们认为这是因为 MobileNet v2 具有更高的 MAC(参见第 2 节中的 G1 和 G4),这在移动设备上非常重要。
与 MobileNet v1 [13]、IGCV2 [27] 和 IGCV3 [28] 相比,我们有两个观察结果。首先,虽然 MobileNet v1 的准确率没有那么好,但它在 GPU 上的速度比所有同行都快,包括 ShuffleNet v2。我们认为这是因为它的结构满足了大多数提出的准则(例如,对于 G3,MobileNet v1 的片段甚至比 ShuffleNet v2 还要少)。其次,IGCV2 和 IGCV3 速度慢。这是由于使用了太多的卷积组([27,28] 中的 4 或 8 个)。这两个观察结果都与我们提出的指导方针一致。
最近,自动模型搜索 [9,10,11,35,36,37] 已成为 CNN 架构设计的一个有前途的趋势。表 8 的底部评估了一些自动生成的模型。我们发现它们的速度相对较慢。我们认为这主要是由于使用了太多的碎片(见 G3)。尽管如此,这个研究方向还是很有希望的。例如,如果将模型搜索算法与我们提出的指南相结合,并在目标平台上评估直接度量(速度),则可以获得更好的模型。
最后,图 1(a)(b) 总结了准确度与速度的结果,这是直接衡量标准。我们得出结论,ShuffeNet v2 在 GPU 和 ARM 上都是最好的。
与其他方法的兼容性。 ShuffeNet v2 可以与其他技术结合以进一步提高性能。当配备 Squeezeand-excitation (SE) 模块 [8] 时,ShuffleNet v2 的分类精度提高了 0.5%,但代价是一定的速度损失。块结构如附录图 2(b) 所示。结果示于表8(底部)。
泛化到大型模型。尽管我们的主要消融是针对轻量级场景执行的,但 ShuffleNet v2 可用于大型模型(例如,FLOPs ≥ 2G)。表 6 比较了 50 层的 ShuffleNet v2(详见附录)与 ShuffleNet v1 [15] 和 ResNet-50 [4] 的对应物。 ShuffleNet v2 在 2.3GFLOPs 上仍优于 ShuffleNet v1,并以 40% 的 FLOPs 减少超过 ResNet-50。

对于非常深的 ShuffleNet v2(例如超过 100 层),为了使训练更快地收敛,我们通过添加残差路径对基本的 ShuffleNet v2 单元稍作修改(详见附录)。表 6 展示了一个 164 层的 ShuffleNet v2 模型,配备了 SE [8] 组件(详见附录)。与以前的最先进模型 [8] 相比,它以更少的 FLOP 获得了更高的准确性。
目标检测 为了评估泛化能力,我们还测试了 COCO 对象检测 [38] 任务。我们使用最先进的轻量级检测器——Light-Head RCNN [34]——作为我们的框架,并遵循相同的训练和测试协议。只有骨干网被我们的取代。模型在 ImageNet 上进行预训练,然后在检测任务上进行微调。对于训练,我们使用 COCO 中的 train+val 集,除了来自 minival 集的 5000 张图像,并使用 minival 集进行测试。准确度指标是 COCO 标准 mmAP,即 box IoU 阈值从 0.5 到 0.95 处的平均 mAP。
ShuffleNet v2 与其他三个轻量级模型:Xception [12,34]、ShuffleNet v1 [15] 和 MobileNet v2 [14] 在四个复杂度级别上进行了比较。表 7 中的结果显示 ShuffleNet v2 表现最好。
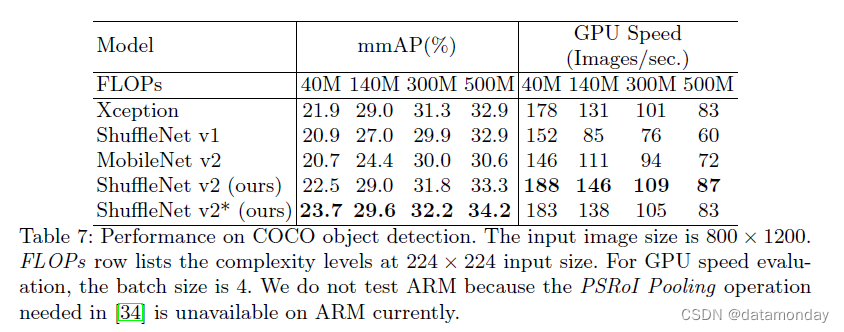
将检测结果(表 7)与分类结果(表 8)进行比较,有趣的是,分类时准确度排名为 ShuffleNet v2 ≥ MobileNet v2 > ShuffeNet v1 > Xception,而检测时排名变为 ShuffleNet v2 > Xception ≥ ShuffleNet v1 ≥ MobileNet v2。这表明 Xception 擅长检测任务。这可能是由于 Xception 构建块的感受野比其他对应物更大(7 比 3)。受此启发,我们还通过在每个构建块中的第一个逐点卷积之前引入额外的 3 × 3 深度卷积来扩大 ShuffleNet v2 的感受野。此变体表示为 ShuffleNet v2*。只需几个额外的 FLOP,它就可以进一步提高准确性。
我们还对 GPU 上的运行时间进行了基准测试。为了公平比较,批量大小设置为 4 以确保充分利用 GPU。由于数据复制(分辨率高达 800 × 1200)和其他检测特定操作(如 PSRoI Pooling [34])的开销,不同模型之间的速度差距小于分类的速度差距。尽管如此,ShuffleNet v2 还是优于其他的,例如比 ShuffleNet v1 快 40% 左右,比 MobileNet v2 快 16%。
此外,变体 ShuffleNet v2* 具有最佳精度,并且仍然比其他方法更快。这引发了一个实际问题:如何增加感受野的大小?这对于高分辨率图像中的目标检测至关重要 [39]。我们将在未来研究这个主题。
5 Conclusion
我们建议网络架构设计应考虑速度等直接指标,而不是 FLOP 等间接指标。我们提出了实用的指导方针和一种新颖的架构,ShuffleNet v2。综合实验验证了我们新模型的有效性。我们希望这项工作可以启发未来的网络架构设计工作,即平台感知和更实用。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)