本篇是多年前的存篇,出处不详。旧酒换新瓶,温故知新,有了新的理解。
一、什么是
TLV
格式
几乎所有的通信都有协议,而几乎所有的需要在卡片和终端之间传送的数据(结构)都是
**TLV**
格式的.
TLV
是
tag
,
length
和
value
的缩写.一个基本的数据元就包括上面三个域. Tag唯一标识该数据元,
length
是
value
域的长度.
value
就是数据本身了.
举个例子, 下面是一个tlv格式的AID(应用标识符)字节串
9F0607A0000000031010
, 其中
9F06
是
tag
,
07
是长度,
A0000000031010
就是AID本身的值了.
二、
TLV
格式编码解析
对于程序编写人员来说,如果有类似上面这样的一串TLV编码的字节串从卡片传过来, 怎么样从中提取我们想要的数据. 这就牵扯出TLV解码的问题了.
解析方法:
-
1.读取type 转换为ntohl、ntohs转换为主机字节序得到类型;指针偏移+2或4
-
2.读取lenght,转换为ntohl、ntohs转换为主机字节序得到长度;指针偏移+2或4
-
3.根据得到的长度读取value,指针偏移+Length;
-
-
…
-
-
继续处理后面的tlv;
TLV编码
就是指先对
Tag
编码,再对
Length
编码,最后对
Value
编码。BER编码的长度确定的编码方式就是这样的。
2.1
BER-TLV
编码 : 长度确定与长度不确定的编码方式
BER编码
有两种方式:
-
一种是
长度确定的编码方式
。这由3部分组成
Identifier octets
、
Length octets
和
Contents octets
(可以和TLV对应)。
-
另一种是
长度不确定的编码方式
。这由4部分组成
Identifier octets
、
Length octets
、
Contents octets
、
End-of-contents octets
。其中
Length octets
为0x80,End-of-contents octets为0x00 00。每种类型都能够编码成长度确定的编码方式,但是有的类型不能够编码成长度不确定的编码方式。
2.2
DER-TLV
编码 : 只能使用长度确定的编码方式
-
Identifier octets
由3部分组成
Class
、
P/C
和
Tag number
。
Identifier octets
的第一个字节的高2位为
Class
,接下来一位为
P/C
,其他位表示
Tag number
。
Class
有4中类型
Universal(00)
、
Application(01)
、
Context-specific(10)
和
Private(11)
。
-
P/C
位如果为
1
则表示是
Constructed
的,为
0
表示是
Primitive
。
-
如果
0<=Tag number<=30
,则整个
Identifieroctets
只有一个字节,否则第一个字节的后5位前为1,接下来找第一个最高位为
0
的字节,该字节就是
Identifier octets
的最后一个字节。从第二个字节到最后一个字节去掉最高位的值拼起来就是
Tagnumber
的值。
2.3 长度确定的编码方式
长度确定的编码方式的
Length octets
有两种方法编码长度:
-
一种是只用一个字节表示长度,其最高位为0,后7位表示长度值,显然这样
只能表示0-127
。
-
另一种是第一个字节的最高位为1,其他位表示后面还有多少个字节属于
Length octets
(这种方式在我们讲解的secs协议中就有用到
《半导体:Gem/Secs基本协议库的开发(1)》
)。后面的那些字节组成的就是
长度值
。长度值表示的是
Contents octets
所占的字节数。
-
DER
要求如果长度为0-127则要使用第一种方式,如果大于127则使用后一种方式。**
其中
BER-TLV
编码是
ISO
定义一种规范,然后到了
PBOC/EMV
里被简化了, 哪里被简化了呢?
举一个例子,
tag
域在
ISO
里可以有
多个字节
, 而
PBOC/EMV
里规定
只用前两个字节
.
下面要讲的TLV解码就是基于
PBOC/EMV
的简化版本.
2.4 tag域编码规则
首先看一下
tag
域是怎样编码的.
Tag
域占最多占两个字节. 编码规则如下面两幅图:
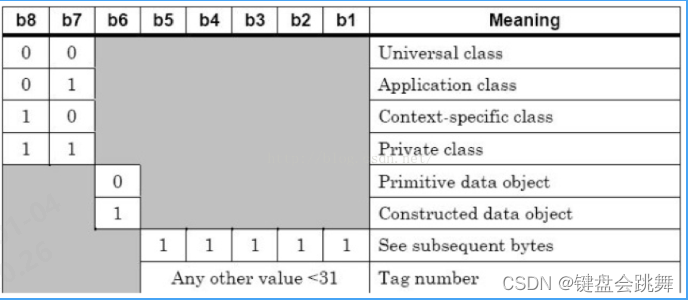
这两幅图. 第一个图是第一个字节的编码规则.
-
b8
和
b7
两位标识
tag
所属类别. 这个可以暂时不用理.
-
b6
决定当前的
TLV
数据是一个单一的数据和复合结构的数据. 复合的
TLV
是指
value
域里也包含一个或多个
TLV
, 类似嵌套的编码格式.(嵌套编码也是很常见的格式,譬如在SIM中的
klarf
协议格式,就是典型的嵌套格式)
-
b5~b1
如果全为1,则说明这个
tag
下面还有一个子字节.占两个字节, 否则
tag
占一个字节.
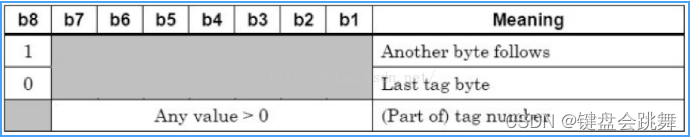
第二幅图:
-
如果
tag
占用两个字节, 第二个字节的编码格式. B8决定tag是否还有后绪的字节存在,因为前面说过,
PBOC/EMV
里的
tag
最多占两个字节,所以该位保持为0.
2.5 tag域的解析
清楚了上面tag编码格式,可很容易写出tag域解码的代码了. 假设,终端接收到一人字节串,这个字节串保存在tlvData的字节数组里, 伪代码如下:
if ((tlvData[i]&0x20) != 0x20)//单一结构
{
if ((tlvData[i]&0x1f) == 0x1f)//tag两字节
{
tagIndex++;
//解析length域
//解析value域
}
else//tag单字节
{
//解析length域
//解析value域
}
}
else//复合结构
{
//复合结构可以考虑用递归的方法来实现.
}
2.6
length域
的解析
Length域
的编码比较简单,最多有四个字节, 如果第一个字节的最高位b8为0, b7~b1的值就是value域的长度. 如果b8为1, b7~b1的值指示了下面有几个子字节. 下面子字节的值就是value域的长度.
2.7
value域
的解析
已知·
value域
的长度,那么解析自然也手到擒来的事情了,不详细赘述~