文章目录
- 二、Scikit-Learn简介
- (一)Scikit-Learn的数据表示
-
- (二)Scikit-Learn的评估器API
- 1. API基础知识
- 2. 有监督学习示例:简单线性回归
- 3. 有监督学习示例:鸢尾花数据分类
- 4. 无监督学习示例:鸢尾花数据降维
- 5. 无监督学习示例:鸢尾花数据聚类
- (三)应用:手写数字探索
- 1. 加载并可视化手写数字
- 2. 无监督学习:降维
- 3. 数字分类
[ sklearn version: 0.23.0 ]
二、Scikit-Learn简介
Scikit-Learn为各种常用机器学习算法提供了高效版本。
(一)Scikit-Learn的数据表示
机器学习是从数据创建模型的学问,因此首先需要了解怎样表示数据爱你让计算机理解。Scikit-Learn认为数据表示(data representation)最好的方法就是用数据表的形式。
1. 数据表
基本的数据表就是二维网格数据,其中的每一行表示数据集中的每个样本(samples),而列表示构成每个样本的相关特征(features)。
import pandas as pd
iris = pd.read_csv('./seaborn-data-master/iris.csv')
iris.head()
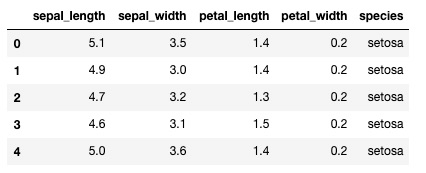
- 每行数据表示每朵被观察的鸢尾花,行数表示数据集中记录的鸢尾花总述。一般会将这个矩阵的行称为样本,行数记为 n_samples,每列数据表示每个样本某个特征的量化值,列数记为 n_features
- 数据集: mwaskom/seaborn-data - GitHub
2. 特征矩阵
这个表格布局通过二维数组或矩阵的形式将信息清晰地表达出来,通常把这类矩阵称为特征矩阵(features matrix)。
特征矩阵通常被简记为变量X。它是维度为[n_samples, n_features]的二维矩阵,通常可以用NumPy数组或Pandas的DataFrame来表示,不过Scikit-Learn也支持SciPy的稀疏矩阵。
样本(每一行)通常是指数据集中的每个对象(任何可以通过一组量化方法进行测量的实体)。
特征(每一列)通常是指每个样本都具有的某种量化观测值。一般情况下,特征都是实数,但有时也可能是布尔类型或离散值。
3. 目标数组
除了特征矩阵 X 之外,还需要一个标签或目标数组,通常简记为y。
目标数组一般是一维数组,其长度就是样本总数n_samples,通常都用一维的NumPy数组或Pandas的Series表示。
目标数组可以是连续的数值类型,也可以是离散的类型/标签。
有些Scikit-Learn的评估器可以处理具有多目标值的二维[n_samples, n_targets]目标数组,文中基本上只涉及常见一维目标数组问题。
如何区分目标数组的特征与特征矩阵中的特征列,一直是个问题。目标数组的特征通常是我们希望从数据中预测的量化结果,借用统计学的术语,y就是因变量。
- 以鸢尾花数据集为例,我们需要通过其他测量值来建立模型,预测花的品种(species),species列就可以看成是目标数组
%matplotlib inline
import seaborn as sns
sns.set()
sns.pairplot(iris, hue='species', height=1.5)
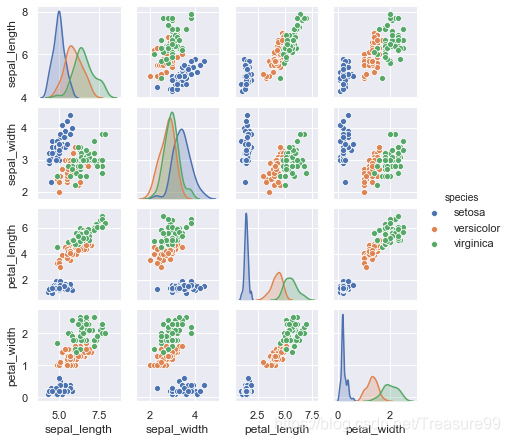
抽取特殊矩阵和目标数组
X_iris = iris.drop('species', axis=1)
X_iris.shape
X_iris
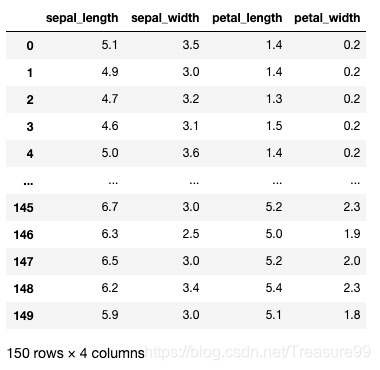
y_iris = iris['species']
y_iris.shape
y_iris

(二)Scikit-Learn的评估器API
Scikit-Learn API主要遵照以下设计原则:
- 统一性:所有对象使用共同接口连接一组方法和统一的文档
- 内省:所有参数值都是公共属性
- 限制对象层级:只有算法可以用Python类表示。数据集都用标准数据类型(NumPy数组、Pandas DataFrame、SciPy稀疏矩阵)表示,参数名称用标准的Python字符串
- 函数组合:许多机器学习任务都可以用一串基本算法实现,Scikit-Learn尽力支持这种可能
- 明智的默认值:当模型需要用户设置参数时,Scikit-Learn预先定义适当的默认值
Scikit-Learn中的所有机器学习算法都是通过评估器API实现的,它为各种机器学习应用提供了统一的接口
1. API基础知识
Scikit-Learn评估器API的常用步骤如下:
- 通过从Scikit-Learn中导入适当的评估器类,选择模型类
- 用合适的数值对模型类进行实例化,配置模型超参数(hyperparameter)
- 整理数据,获取特征矩阵和目标数组
- 调用模型实例的
fit()方法对数据进行拟合 - 对新数据应用模型:
– 在有监督学习模型中,通常使用predict()方法预测新数据的标签
– 在无监督学习模型中,通常使用transform()或predict()方法转换或推断数据的性质
2. 有监督学习示例:简单线性回归
演示一个简单线性回归的建模步骤:最常见的任务就是为散点数据集
(
x
,
y
)
(x,y)
(x,y)拟合一条直线
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
rng = np.random.RandomState(42)
x = 10 * rng.rand(50)
y = 2 * x - 1 + rng.randn(50)
plt.scatter(x, y)
(1) 选择模型类
在Scikit-Learn中,每个模型类都是一个Python类。
from sklearn.linear_model import LinearRegression
- 更多线性模型:sklearn.linear_model - scikit-learn 0.23.0 documentation
(2) 选择模型超参数
注意:模型类与模型实例不同
当我们选择模型类之后,还有许多参数需要配置。根据不同模型的不同情况,你可能需要回答一下问题:
- 我们想要拟合偏移量(即直线的截距)吗?
- 我们需要对模型进行归一化处理吗?
- 我们需要对特征进行预处理以提高模型灵活性吗?
- 我们打算在模型中使用哪种正则化类型?
- 我们打算使用多少模型组件(model component)?
有一些重要的参数必须在选择模型类时确定好。这些参数通常被称为超参数,即在模型拟合数据之前必须被确定的参数。
在Scikit-Learn中,通常在模型初始化阶段选择超参数。
model = LinearRegression(fit_intercept=True)
model
注意:对模型进行实例化仅仅是存储了超参数的值。我们还没有将模型应用到数据上:Scikit-Learn的API对选择模型和将模型应用到数据区别得很清晰。
(3) 将数据整理成特征矩阵和目标数组
Scikit-Learn的数据表示方法(需要二维特征矩阵和一维目标数组)。
虽然我们的目标数组已经有了y(长度为n_samples的数组),但还需要将数据x整理成[n_samples, n_features]的形式。
X = x[:, np.newaxis]
X.shape
(4) 用模型拟合数据
现在就可以将模型应用到数据上了,这一步通过模型的fit()方法即可完成。
fit()命令会在模型内部大量运算,运算结果将存储在模型属性中,供用户使用。
model.fit(X, y)
在Scikit-Learn中,所有通过fit()方法获得的模型参数都带一条下划线。
model.coef_
model.intercept_
model.coef_和model.intercept_两个参数分别表示对样本数据拟合直线的斜率和截距- 与前面样本数据的定义(斜率2,截距-1)进行比对,发现拟合结果与样本非常接近
模型参数的不确定性是机器学习经常遇到的问题。一般情况下,Scikit-Learn不会为用户提供直接从模型参数获得结论的工具,与其将模型桉树解释为机器学习问题,不如说它更像统计建模问题。机器学习的重点并不是模型的预见性。
(5) 预测新数据的标签
模型预测出来后,有监督机器学习的主要任务就变成了对不属于训练集的新数据进行预测。
在Scikit-Learn中,用predict()方法进行预测
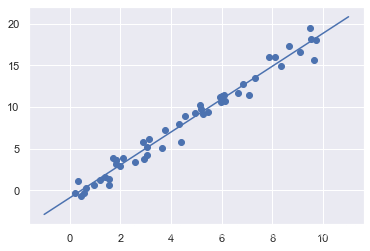
xfit = np.linspace(-1, 11)
Xfit = xfit[:, np.newaxis]
yfit = model.predict(Xfit)
plt.scatter(x, y)
plt.plot(xfit, yfit)
3. 有监督学习示例:鸢尾花数据分类
示例问题:如何为鸢尾花数据集建立模型,先用一部分数据进行㜕,再用模型预测出其他样本的标签?
我们将使用高斯朴素贝叶斯(Gaussian naive Bayes)方法完成。
这个方法假设每个特征中属于每一类的观测值都符合高斯分布。因为高斯朴素贝叶斯分类高斯朴素贝叶斯方法速度很快,而且不需要选择超参数,所以通常很适合作为初步分类手段,在借助更复杂的模型进行优化之前使用。
由于需要用模型之前没有接触过的数据评估它的训练效果,因此得现将数据分割成训练集(training set)和测试集(testing set)。使用train_test_split函数
from sklearn.model_selection import train_test_split
Xtrain, Xtest, ytrain, ytest = train_test_split(X_iris, y_iris, random_state=1)
整理好数据后,用模型预测标签
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(Xtrain, ytrain)
y_model = model.predict(Xtest)
最后用accuracy_score工具验证模型预测结果的准确率(预测的所有结果中,正确结果占总预测样本数的比例)
from sklearn.metrics import accuracy_score
accuracy_score(ytest, y_model)
- 准确率高达97%,表明即使是简单的分类算法也可以有效学习这个数据集
4. 无监督学习示例:鸢尾花数据降维
无监督学习问题:对鸢尾花数据集进行降维,以便能更方便地对数据进行可视化。(鸢尾花数据集由四个维度构成,即每个样本都有四个维度。)
降维的任务是要找到一个可以保留数据本质特征的低维矩阵来表示高维数据。降维通常用于辅助数据可视化的工作(用二维数据画图比用四维甚至更高维的数据画图更方便)
以下将使用主成分分析(principle component analysis, PCA)方法,是一种快速线性降维技术。将用模型返回两个主成分,也就是用二维数据表示鸢尾花的四维数据。
from sklearn.decomposition import PCA
model = PCA(n_components=2)
model.fit(X_iris)
X_2D = model.transform(X_iris)
可视化结果:快速处理方法就是先将二维数据插入到鸢尾花的DataFrame中,然后用Seaborn的lmplot方法画图
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
sns.lmplot('PCA1', 'PCA2', hue='species', data=iris, fit_reg=False)
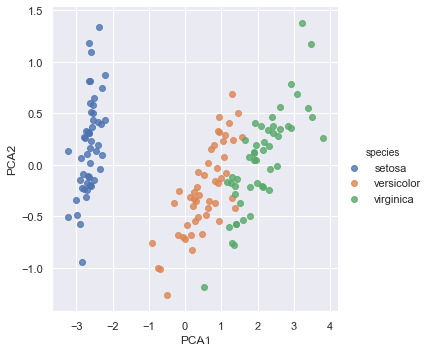
- 从二维数据表示图可以看出,虽然PCA算法不知道花的种类标签,但不同种类的花被很清晰区分开,这表明用一种比较简单的分类方法就能有效学习这份数据集
5. 无监督学习示例:鸢尾花数据聚类
聚类算法是要对没有任何标签的数据集进行分组。
此处使用聚类方法之高斯混合模型(Gaussian mixture model, GMM),GMM模型试图将数据构造成若干服从高斯分布的概率密度函数簇。
拟合高斯混合模型:
from sklearn.mixture import GaussianMixture
model = GaussianMixture(n_components=3,
covariance_type='full')
model.fit(X_iris)
y_gmm = model.predict(X_iris)
将簇标签添加到鸢尾花的DataFrame中,并用Seaborn画出结果
iris['cluster'] = y_gmm
sns.lmplot('PCA1', 'PCA2', data=iris, hue='species',
col='cluster', fit_reg=False)
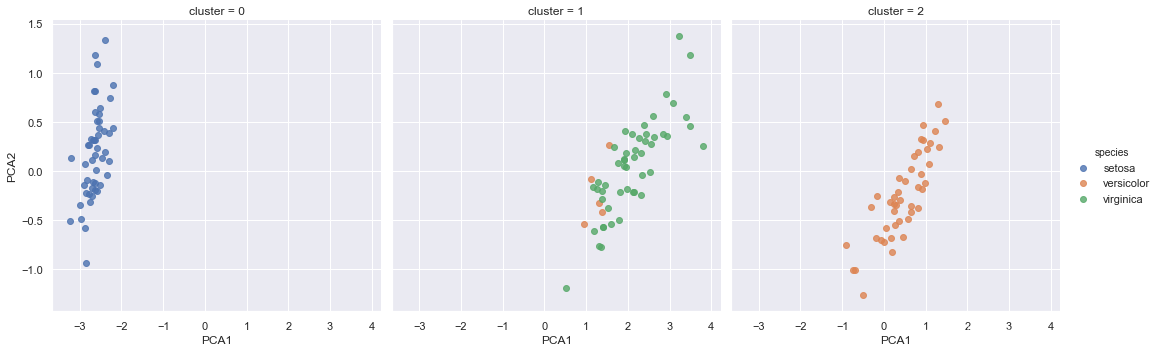
- 根据簇数量对数据进行分割,就会清洗地看出GMM算法的训练效果:setosa(山鸢尾花)类的花在簇0中被完美地区分出来,唯一的遗憾是第三幅图中versicolor(变色鸢尾花)和virginical(维吉尼亚鸢尾花)还有一点混淆。这就说明,由于每种花的特征差异很大,我们也可以通过简单的聚类算法自动识别出不同种类的花。
- 这种算法还可以探索观察样本之间的关联性
(三)应用:手写数字探索
挑战一个光学字符识别问题:手写数字识别。这个问题包括图像中字符的定位和识别两部分。
1. 加载并可视化手写数字
用Scikit-Learn的数据获取接口加载数据并简单统计:
from sklearn.datasets import load_digits
digits = load_digits()
digits.images.shape
import matplotlib.pyplot as plt
fig, axes = plt.subplots(10, 10, figsize=(8, 8),
subplot_kw={'xticks': [], 'yticks': []},
gridspec_kw=dict(hspace=0.2, wspace=0.1))
for i, ax in enumerate(axes.flat):
ax.imshow(digits.images[i], cmap='binary', interpolation='nearest')
ax.text(0.05, 0.05, str(digits.target[i]),
transform=ax.transAxes, color='green')
为了在Scikit-Learn中使用数据,需要一个维度为[n_samples, n_features]的二维特征矩阵,可以将每个样本图像的所有像素都作为特征,也就是将每个数字的8像素*8像素平铺成长度为64的一维数组。另外还需要一个目标数组,用来表示每个数字的真实值(标签)。
X = digits.data
X.shape
y = digits.target
y.shape
2. 无监督学习:降维
需要借助无监督学习方法将维度降到二维,通过流形学习算法中的Isomap算法对数据进行降维:
from sklearn.manifold import Isomap
iso = Isomap(n_components=2)
iso.fit(digits.data)
data_projected = iso.transform(digits.data)
data_projected.shape
plt.scatter(data_projected[:, 0], data_projected[:, 1], c=digits.target,
edgecolor='none', alpha=0.5,
cmap=plt.cm.get_cmap('nipy_spectral', 10))
plt.colorbar(label='digit label', ticks=range(10))
plt.clim(-0.5, 9.5)
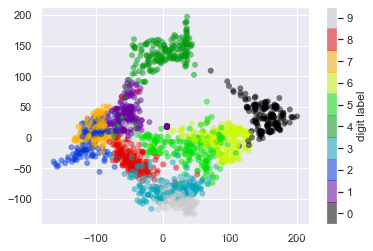
- 图像呈现了很直观的效果,可以看出数字在64维空间中的分离(可识别)程度。
- 如,在参数空间中,数字0(黑色)和1(紫色)基本不会重叠。
- 从图中发现,数字1、4、7有点混淆
3. 数字分类
需要找到一个分类算法,对手写数字进行分类。
Xtrain, Xtest, ytrain, ytest = train_test_split(X, y, random_state=0)
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(Xtrain, ytrain)
y_model = model.predict(Xtest)
from sklearn.metrics import accuracy_score
accuracy_score(ytest, y_model)
- 可以看出,通过一个简单的模型,数字识别率就可以高达80%,但仅依靠这个指标,无法知道模型哪里做得不够好,解决这个问题的办法就是用混淆矩阵(confusion matrix)
# 用Scikit-Learn计算混淆矩阵,并用Seaborn可视化
from sklearn.metrics import confusion_matrix
mat = confusion_matrix(ytest, y_model)
sns.heatmap(mat, square=True, annot=True, cbar=True)
plt.xlabel('predicted value')
plt.ylabel('true value')
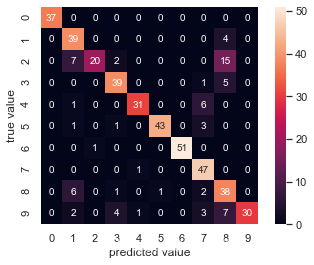
- 从图中可以看出,误判的主要原因在于许多数字2被误判成数字1或8。
另一种显示模型特征的直观方式是将样本画出来,然后把预测标签放在左下角,用绿色表示预测正确,红色表示预测错误
fig, axes = plt.subplots(10, 10, figsize=(8, 8),
subplot_kw={'xticks':[], 'yticks':[]},
gridspec_kw=dict(hspace=0.1, wspace=0.1))
test_images = Xtest.reshape(-1, 8, 8)
for i, ax in enumerate(axes.flat):
ax.imshow(test_images[i], cmap='binary', interpolation='nearest')
ax.text(0.05, 0.05, str(y_model[i]),
transform=ax.transAxes,
color='green' if (ytest[i] == y_model[i]) else 'red')

- 通过观察这部分样本数据,能知道模型哪里的学习不够好。
- 如果希望分类准确率达到80%以上,可能需要借助更加复杂的算法,如支持向量机、随机森林或其他分类算法。
机器学习相关阅读:
[Python3] 机器学习 ——(一)机器学习简介
总结自《Python数据科学手册》
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)