merge和join都是将不同的dataframe进行合并,区别在于merge是通过key将frame合并,而join通过index进行合并。
merge: 两个frame必须要有同一种属性可以作为键值,如下的id属性
import pandas as pd
df1 = pd.DataFrame({'id':['A', 'A', 'C', 'B', 'C']})
df2 = pd.DataFrame({'id':['A', 'B', 'C'], 'count':[1, 2, 3]})
df3 = pd.merge(df1, df2, how='left')
df3
>>> id count
0 A 1
1 A 1
2 C 3
3 B 2
4 C 3
join: 一般两个frame没有重叠的属性,是通过index作为键值来合并
import pandas as pd
df1 = pd.DataFrame({'A':[22, 11, 33, 44]})
df2 = pd.DataFrame({'B':[13, 22, 44, 45], 'C':[1, 3, 2, 4]})
df1
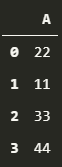
df2

以df1的index为参考(how=left)合并df2
df = df1.join(df2, how='left')

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)