第一次安装的时候真的是纯小白,各种概念都不懂,只知道使用GPU跑代码需要安装CUDA。弯路走了不少,前前后后被虐了一周,安装的非常艰辛,且混乱;
第二次安装是在同学电脑上,又绕了些弯路,不过这次只花了半天时间,当时非常自豪来着。
这次是第三次安装,有了第二次的经验,安装的非常非常顺利,可谓一气呵成。现在把过程发过来,是我的第一篇CSDN。有点点激动。
步骤简述:
1.确认有Nvidia GPU
2.升级驱动程序
3.安装CUDA
4.安装GPU版Pytorch
关键:版本一定要对应,各个地方版本都要对应。最好经常查看与确认版本。
详细过程:
1.确认有GPU
在任务管理器-性能中,看GPU1中的型号。(GPU1是独显,GPU0是集显)

2.升级驱动程序:
官网下载,教程可参考:(51条消息) Windows更新NVIDIA显卡驱动_nvidia安装选显卡驱动还是图形驱动_振华OPPO的博客-CSDN博客
之后检查版本号。在NVIDIA控制面板,这里的版本显示472.84.

3.安装CUDA。
查看对应CUDA版本:
看这张表即可。(下图的表中能找到就行,可以不看原网址:CUDA 12.0 Release Notes — cuda-toolkit-release-notes 12.0 documentation (nvidia.com))

如刚刚版本472.84,在表中对应一下,发现>=452.39,可以安装CUDA11.8x。
官网下载对应CUDA:CUDA Toolkit Archive | NVIDIA Developer
注意点击与刚刚匹配的版本。这里是CUDA11.8。


下载完双击安装即可。
检查是否安装成功:
搜索栏输入cmd回车(进入cmd),输入nvidia-smi
即可得到如图所示。这里显示的CUDA是11.8,即安装成功。

4.安装GPU版torch。注意一定要下载对应版本!
确认CUDA型号与python版本,在下面的网址下载GPU版torch。(我之前官网下的有问题,推荐从这个网址下)
(另外,在这一步想查看torch版本的,可以在python中pip下载torch,然后终端print版本,如x.xx.x+cpu,则说明是cpu版本的torch。安装好GPU版torch后,再重复这个步骤会显示x.xx.x+cu118)
去网址 https://download.pytorch.org/whl/torch/ 下载gpu版本。在里面仔细找一下,名称中cu118代表cuda11.8,cp39代表python3.9.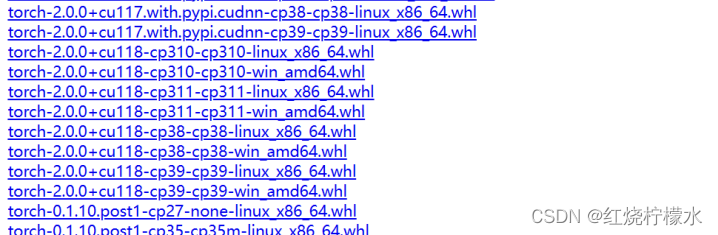 (另外:上面链接只有torch,需要torchvision或者torchaudio的可以在这里找:https://download.pytorch.org/whl/torch_stable.html)
(另外:上面链接只有torch,需要torchvision或者torchaudio的可以在这里找:https://download.pytorch.org/whl/torch_stable.html)
下载完gpu版torch后,在python中pip安装
pip install .\torch-1.13.0+cu116-cp39-cp39-win_amd64.whl (注意,名称要换成刚刚下载的版本)
安装好后,可以在终端pip list 在列表中找寻并查看torch安装的版本。
最后,在终端
import torch,print(torch.__version__),print(torch.version.cuda),print(torch.cuda.is_available())
显示true则大功告成~
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)