文章地址:An Introduction to Deep Learning for the Physical Layer
github:
py-radio-autoencoder(第三方代码,非作者创作)
其余相关blog参考:
【文献学习】An Introduction to Deep Learning for the Physical Layer
An Introduction to Deep Learning for the PhysicalLayer
本文分为两个部分,第一部分是对论文关键内容的记录与分析,第二部分是对论文中模型的复现记录,因为coding之后感觉对一些理论理解的更透彻了,因此自我感觉part2 比 part1 要精彩不少
注意,本文一些主观的分析和看法可能是错误的,希望读者以批判性的眼光阅读
文章目录
- Part 1 论文阅读
- 1 概述
- 2 论文分段分析
- 2. 1 Abstract
- 2. 2 Inroduction
- 2.2.1 Potential of DL for the physical layer
- 2.2.2 Historical context and related work
- 2.3 DEEP LEARNING BASICS
- 2.4 EXAMPLES OF MACHINE LEARNING APPLICATIONS FOR THE PHYSICAL LAYER
- 2.4.1 Autoencoders for end-to-end communications systems
- 补充:线性分组码(n, k)
- 补充:汉明码
- 补充:Block Error Rate
- 2.4.2 Autoencoders for multiple transmitters and receivers
- 2.4.3 Radio transformer networks for augmented signal processing algorithms
- 2.4.4 CNNs for classification tasks
- 2.5 DISCUSSION AND OPEN RESEARCH CHALLENGES
- 2.5.1 Data sets and challenges
- 2.5.2 Data representation, loss functions, and training SNR
- 2.5.3 Complex-valued neural networks
- 2.5.4 ML-augmented signal processing
- 3 总结:AI在通信领域与其他领域的不同
- Part 2 代码复现
- 1 autoencoder
- 1.1 win10 无法安装 itpp
- 1.2 汉明码测试
- 1.3 autoencoder 源码训练
- 1.4 autoencoder 源码分析
- 1.5 自问自答: autoencoder到底是什么?
- 2 RTN
- 3 调制分类 CNN
-
- 感想
Part 1 论文阅读
1 概述
这是一篇关于深度学习方法在通信物理层方面应用的综述性文章
提出了三种网络模型,Autoencoder 、 RTN 以及 CNN for modulation classification
什么叫做物理层?
最后反过头来看这个问题,应该就是信道编解码等,可以理解为计算机网络OSI模型中的那个物理层,负责数据的传输,本质是管道
2 论文分段分析
2. 1 Abstract
(1)摘要中阐明了将深度学习引入通信系统的一大好处
we develop a fundamental new way to think about communications system design as an end-to-end reconstruction task that seeks to jointly optimize transmitter and receiver components in a single process
那就是将一个通信系统中原本需要独立设计的发射机、接收机、信道等看成整体。我们学通信原理时都是 分开学习,如果将深度学习引入通信系统,那就有可能将这些独立的过程合并为一个端到端的单一任务,这就大大简化了设计通信系统的过程。
这种思想不仅适用于单发射机与单接收机的通信系统,也适用于多发射机与多接收机的通信网络。
(2)同时,作者提出了一种新的概念叫 radio transformer networks(RTNs, 注意是复数),希望能够借此将专家领域知识(expert domain knowledge )整合入机器学习模型内
关于expert domain knowledge的理解,我理解的就是通信领域的专家系统,一个拥有且能通过人机交互解答通信领域专业知识的程序系统就是一个专家系统。“ incorporate expert domain knowledge in the machine learning (ML) model”,我理解为就是希望通过机器学习来解决通信领域的专业问题。
(3)最后,作者展示了一些CNN在原始智商样本(raw IQ samples)上的调制分类(modulation classification)应用,并且显示CNN方案相比传统方案,在精度上是有竞争力的
(学到了,精度没有超过可以说 competitve)
这里两个关键名词,一个是 raw IQ samples,一个是 modulation classification
IQ 是一种数字调试方式,可参考:【知识点】IQ调制 IQ数据 星座图
2. 2 Inroduction
点出了几个关键点
(1)1st-2nd段
机器学习算法要想应用于通信领域在性能上要通过很高的门槛,因为通信目前已经是一个非常成熟的领域,在很对子领域传统算法已经将性能提升的很高了,出现了性能上的瓶颈。
并且,通信领域与目前DL横行的CV和NLP领域有一个本质的区别,那就是CV和NLP领域很难用传统的方法来解决问题,比如手写数字识别,你没法用OpenCV写一个固定的算法来完成这个任务。但是通信领域的任务,比如编码、解码、检测等,都是有非常solid且久经考验的传统算法可以实现的。
对于“capture real effects” 不是很理解,怎样的效果算是 capture real effects? 逼近香农极限?
更新回答:相同信噪比下误码率更低或许就可以看作是捕获的real effects更多
(2)3rd段
作者点明自己这篇论文的贡献,并且阐述文章结构
其中第一点阐述了如何通过神经网络来得到一个包含“trainsmitter - channel - receiver” 的通信模型,那就是把 channel 设计为一个网络模型,然后用来训练得到 trainsmitter 和 receiver
2.2.1 Potential of DL for the physical layer
这一部分主要阐述为什么DL算法可能优于传统算法
(1)DL算法的非线性
传统算法与DL算法的本质差异在于线性与非线性。
传统算法通常都是易于处理的数学模型,是线性的,然而一个实际的通信系统并不是完美的,其有很多非线性的特征,那么传统算法对于这些非线性特征就只能近似的捕获,这就造成了误差。DL算法是非线性的,它可以更好的捕获实际通信系统的特征。
(2)DL算法提供了一个端到端的整体方案
传统算法将通信系统拆分为一个个模块,然后分别优化,但是各自优化之后再合并对于通信系统整体来说其性能并不一定达到了最优。
(3)DL算法的效率更高
神经网络可以看成是一个通用函数逼近器,可以完成很大范围内的任务。相对于手动编程的算法来说,通过神经网络学习得到的算法执行速度更快,功耗更低。并且由于GPU以及各种专用芯片的发展,神经网络能够实现很高的硬件资源利用率。
2.2.2 Historical context and related work
这一部分展示了 DL 在通信领域应用的一些相关工作
在CV大爆发之前,NN与通信领域的结合基本都是专注于receiver这单一部分。DL在CV爆发之后,通信DL这边也慢慢开始发展了,目前通信领域应用DL有两个主要的思路:(1)利用DL改进现有算法;(2)用DL完全取代现有算法
关于(1)和(2)提到的文献内容另外记录于其他blog中
(1):【文献笔记】【泛读】AI in physical layer:用DL改进现有算法的工作
(2):【文献笔记】【泛读】AI in phsical layer:用DL算法代替现有算法
2.3 DEEP LEARNING BASICS
介绍深度学习数学基础,没什么新知识
2.4 EXAMPLES OF MACHINE LEARNING APPLICATIONS FOR THE PHYSICAL LAYER
2.4.1 Autoencoders for end-to-end communications systems
描述了如何将一个传统的 “transmitter - channel - recerver” 通信系统 表示为一个端到端的 autoencoder 的过程。
信道可以用一个条件概率密度函数p(y|x)来表示,x是发送信号,y是接收信号
这一句话看不懂
Typically, the goal of an autoencoder is to find a low-dimensional representation of its input at some intermediate layer which allows reconstruction at the output with minimal error.
2021-8-15更新
现在看懂了,就是说设计 autoencoder 的目标是模型尽量窄,并且精度尽量高(loss尽量低)
autoencoder的示意图还是很好看懂的

以下是autoencoder与其他传统算法在误差率上的对比

补充:线性分组码(n, k)
关于(n, k),n channel uses 指的是一个编码的长度为n bit, 默认信道用一次发一个bit。
由编码器产生的n-k个添加到每个输入消息中的消息比特称为冗余比特 m, 因此必然 n>=k
communication rate R = k / n 在中文中叫码率,可以解释为每一个码比特所携带的平均信息比特数
参考: 移动通信中的信道编码基础
补充:汉明码
参考:汉明码(Hamming Code)原理及实现
记住汉明码本质是奇偶校验位的进化版
这张图非常好用

补充:Block Error Rate
盲猜是误码率,google 搜索 block error rate,弹出 block error rate and bit error rate,果然。
参考:BER vs BLER vs DBLER
注意,这里的block只是有效信息位,不包括码字,一帧包括block + 冗余位
接2.4.1, 作者给出了一个网络结构

网络结构本身很简单,但是要训练一个网络,知道网络结构本身是远远不够的,下面是我从论文以及源码中提炼的训练信息
(1) optimizer: SGD
(2) loss_function: BLER
(3) data_set:
(4) input:
(5) output:
其中,数据集,输入,输出具体是啥,或者说在代码中怎么表示并不清楚,在part2的源码分析会提到
经过对源码的分析,以上问题已经完成能够解释了
data_set 是随机生成的待传输的 blocks,也就是有效信息编码串
input是二维张量 [input_dimension, input_dimension],表示input_dimension个bit(一个bit被编码为input_dimension长度的one hot),也就表示一个block
output就是input编码再加噪解码后的输出,shape一模一样
2.4.2 Autoencoders for multiple transmitters and receivers

与single transmitter-receiver系统不同的是噪声的影响作用于receiver上了。
这一部分的公式推导着实看不懂
2.4.3 Radio transformer networks for augmented signal processing algorithms
这一部分主要阐述了一种优化参数估计的神经网络方法,叫RTN
传统参数估计方法一般只适用于特定几种情况,泛化性不好而且非常复杂。因此可以引入NN的方法来进行参数估计
论文中给出了一种在receiver端应用RTN以优化参数估计的模型

关于RTN的作用作者这么说
Importantly, the training process of such an RTN does not seek to directly improve the parameter
estimation itself but rather optimizes the way the parameters are estimated to obtain the best end-to-end performance
也就是说,RTN并不直接优化参数,而是通过改善autoencoder优化参数的效果来改善参数。
从这个角度看,RTN可以看作是一种 autoencoder 的 trick,是一种attention
通过以下这两个图可以看出在通信DL的训练中 Eb/Eo和epoch是等价的,非常inspiring

2.4.4 CNNs for classification tasks
物理层中的许多信号处理都可以看作是分类任务, 比如 modulation classification
传统方法一般通过 expert feature engineering 、analytic decision trees(决策树)、support vector machines(支持向量机)、随机森林、小规模前馈神经网络等来解决。但是并没有寻求在无线电领域中对原始时间序列数据使用特征学习的方法,而这正是CV领域的标准方法。
作者使用了如下网络进行 modulation classification

使用的数据集地址如下所示:http://radioml.com/datasets/radioml-2016-10-dataset/
CNN网络与传统方法对比如下:

2.5 DISCUSSION AND OPEN RESEARCH CHALLENGES
这整个大节都是在讨论物理层DL目前面临的不足和挑战。
2.5.1 Data sets and challenges
目前通信AI领域有如下不足之处
(1)没有一个公认的 benchmark 与 公开数据集,这与CV、NLP领域不能比。
(2)没有丰富的挑战赛,社区活跃度不够
2.5.2 Data representation, loss functions, and training SNR
目前关于通信DL最佳数据表示、损失函数以及训练策略(比如作为一个通信系统,应该在哪个信噪比SNR下训练?)都还不清楚。
这一部分提到了信噪比对于训练的影响
The authors of [58] have observed that starting off the training at high SNR and then gradually lowering it with each epoch led to significant performance improvements for their application
还提出了一些调参方法(batch size, learning rate…)
Examples include architecture search guided by hyper-gradients and differential hyper-parameters [59] as well as genetic algorithm or particle swarm style optimization [60].
2.5.3 Complex-valued neural networks
通信中通常运用复数计算,但是目前没有DL框架支持复数运算,一方面因为复数运算可以转换为两倍的实数运算;另一方面目前也没有针对复数的损失函数以及激活函数。
2.5.4 ML-augmented signal processing
用深度学习训练端到端通信系统的一大阻力就是数据的纬度太大,如果发送的信息有100bit,那就有2e100个数据要被训练,非常恐怖。
3 总结:AI在通信领域与其他领域的不同
(1)在通信领域,DL要打败传统算法在精度上有很高的门槛,在CV和NLP领域,DL算法的优势是从0到1,而在通信领域,DL算法的优势在于由繁化简
(2)在数据方面,通信领域与CV、NLP领域有很大不同。图像、语音等数据是自然数据,可以通过采集得到,而通信领域的数据基本是人造的。
Part 2 代码复现
除去文献 12 页纯英文论文着实看麻了,但是光看论文总感觉差点意思,很多文字都是似懂非懂的样子,gets your hands dirty,没有亲手coding过的知识都是脆弱的
part 2 主要是关于论文中提到的几个网络的复现,包括autoencoder、RTN、modulation classification等,还有一些通信算法的代码,比如汉明码通信全过程
1 autoencoder
论文作者说在文章 review 之后就将放出源码,但是2021年了,仍然没有看到源码(也可能被放出来后被删除了)
在 paper with code 网站上查到了第三方写的关于 autoencoder 的代码,遂fork了一份准备好好研读,github链接如下:
https://github.com/ndwuhuangwei/py-radio-autoencoder
准备的环境如下:
tensorflow-gpu1.15.0 + python3.6 (使用 anaconda 配置)
在跑代码的过程中遇到了一些问题,记录如下
1.1 win10 无法安装 itpp
源码在编写汉明码的时候使用了作者自己写的一个库 itpp(https://github.com/vidits-kth/py-itpp)
这是一个用于信号处理的库,从makefile中可以看出,这个库是为linux准备的,或许可以通过修改makefile来使代码适配win10,但是由于这段日子紧张,暂时没空探索,挖个坑先留着。
又仔细看了一下sh 和 makefile,看样子makefile是基于已经 apt-get install libitpp-dev的前提下,这个win10应该是彻底玩不转了
不能用itpp那怎么办呢,只能是用其他方式来实现源代码中itpp的功能了。
先看一看在 autoencoder 的源码中 itpp 都干了啥
itpp在 /src/hamming.py 中被调用
源码代码如下,注释已十分详尽
def block_error_ratio_hamming_awgn(snr_db, block_size):
"""
snr_db: 信噪比
block_size: 一个码字包含的有效信息bit数, 目前只能为4,可以修改mapping_k_m来增加可输入的block_size
"""
mapping_k_m = {4: 3}
m = mapping_k_m[block_size]
'''Hamming encoder and decoder instance'''
hamm = itpp.comm.Hamming_Code(m)
n = pow(2, m) - 1
rate = float(block_size)/float(n)
'''Generate random bits'''
nrof_bits = 10000 * block_size
source_bits = itpp.randb(nrof_bits)
'''Encode the bits'''
encoded_bits = hamm.encode(source_bits)
'''Modulate the bits'''
modulator_ = itpp.comm.modulator_2d()
constellation = itpp.cvec('-1+0i, 1+0i')
symbols = itpp.ivec('0, 1')
modulator_.set(constellation, symbols)
tx_signal = modulator_.modulate_bits(encoded_bits)
'''Add the effect of channel to the signal'''
noise_variance = 1.0 / (rate * pow(10, 0.1 * snr_db))
noise = itpp.randn_c(tx_signal.length())
noise *= itpp.math.sqrt(noise_variance)
rx_signal = tx_signal + noise
'''Demodulate the signal'''
demodulated_bits = modulator_.demodulate_bits(rx_signal)
'''Decode the received bits'''
decoded_bits = hamm.decode(demodulated_bits)
'''Calculate the block error ratio'''
blerc = itpp.comm.BLERC(block_size)
blerc.count(source_bits, decoded_bits)
return blerc.get_errorrate()
可见,itpp 在本代码中主要用于 编汉明码、解汉明码、算误码率、数学计算
itpp库的源码时C++,以我目前的功力还不足以看懂。。。再挖个坑,学通C++后单开一个blog来解读
关于汉明码的原理已在part 1中补充说明了。因为看不懂 itpp 库的过程,所以只能通过python代码来猜测了。
找到了另一个汉明码编码和解码可以使用的库,https://pypi.org/project/hamming-codec/,试了之后蚌埠住了,这也是只能linux用的
干脆直接上租的服务器装环境,一劳永逸
我用的矩池云(https://www.matpool.com/user/matbox?path=%2Finternship%2Fdata_set)(非广告),开一个最拉的卡
用远程服务器装itpp就贼顺,只不过记得 sh 文件中的sudo都要去掉,因为服务器默认root用户,另外装python那行也注释掉,当然,如果用的是自己的服务器,那就当普通linux用就行
裂开,itpp专门为python3.6写的,我开的服务器开的python3.5,不过没事,再用anaconda装一个python3.6的环境,成功import itpp
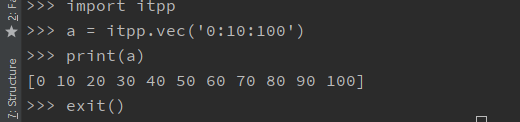
1.2 汉明码测试
至此,hamming.py可以完美工作了,小小测试一下信噪比对于误码率的影响
| 信噪比 | 误码率(%) |
|---|
| 10 | 0 |
| 5 | 1.64 |
| 2.5 | 9.48 |
| 1 | ·17.79 |
| 0 | 25.99 |
| -5 | 61.3 |
| -10 | 80.06 |
可以看出,信噪比影响还蛮大的,降到5以下误码率就开始迅速恶化
仅传一个码字来分析下汉明码通信全过程

要传输的四位数据为 [0 0 1 1]
按照汉明码编码规则,编码后1, 2, 4位为奇校验位,异或后为1
XX0X011
1234567
这编码后的数据必然不对啊。。。。,看起来itpp像是低三位插入校验位,而不是1,2,4
手动计算编码后数据
【位编号,从左到右001 -> 111(值)】
位1校验 001, 011(0),101(0), 111(1) 故位1为0
位2校验010, 011(0), 110(1), 111(1), 故位2为1
位4校验100, 101(0), 110(1), 111(1),故位4为1
所以编码后数据为 0101011, 着实不懂itpp怎么编的。。。。难道有另一种汉明码?
目前没搞明白,先这样把,反正怎么编码不重要,autoencoder才是重点,与autoencoder对比才重要
找到了一段Python代码,算出来与itpp算出来的一样,或许可以解答疑惑
def random_sources():
random_sources = random.randint(0, 16)
print('这个随机数是', random_sources)
return hanming(random_sources)
def hanming(code_0):
code1 = bin(int(code_0))
code = str(code1)[2:]
print('{0}变成二进制'.format(code_0), code)
while len(code) < 4:
code = '0' + code
code_list = list(code)
code_1 = int(code_list[0]) ^ int(code_list[2]) ^ int(code_list[3])
code_2 = int(code_list[0]) ^ int(code_list[1]) ^ int(code_list[2])
code_4 = int(code_list[1]) ^ int(code_list[2]) ^ int(code_list[3])
code_list.insert(0, str(code_1))
code_list.insert(1, str(code_2))
code_list.insert(2, str(code_4))
hanming_code = ''.join(code_list)
print('生成的(7,4)汉明码字:' + hanming_code)
return code_list
可以看出,检验位插入位置与异或的位都不对
改成自己理解的方式
def hanming(code_0):
code1 = bin(int(code_0))
code = str(code1)[2:]
print('{0}变成二进制'.format(code_0), code)
while len(code) < 4:
code = '0' + code
code_list = list(code)
code_1 = int(code_list[0]) ^ int(code_list[1]) ^ int(code_list[3]) ^ 1
code_2 = int(code_list[0]) ^ int(code_list[2]) ^ int(code_list[3]) ^ 1
code_4 = int(code_list[1]) ^ int(code_list[2]) ^ int(code_list[3]) ^ 1
code_list.insert(0, str(code_1))
code_list.insert(1, str(code_2))
code_list.insert(3, str(code_4))
hanming_code = ''.join(code_list)
print('生成的(7,4)汉明码字:' + hanming_code)
return code_list
结果就对了,看来真的有第二种汉明码编码方式?没搜到,而且这代码命名还是 code_1,code_2, code_4,着实整不会了。
1.3 autoencoder 源码训练
先运行源码看看
训练的时候可以看出来,对于卡的要求还是很低的

跑出来的结果

基本符合论文中给出的图
1.4 autoencoder 源码分析
以下是autoencoder训练的主要代码,代码分析见注释
u1s1,tensorflow1代的api是真的乱,但是没办法,还是得看
def block_error_ratio_autoencoder_awgn(snrs_db, block_size, channel_use, batch_size, nrof_steps):
print('block_size %d'%(block_size))
print('channel_use %d'%(channel_use))
rate = float(block_size)/float(channel_use)
print('rate %0.2f'%(rate))
'''The input is one-hot encoded vector for each codeword'''
alphabet_size = pow(2, block_size)
'''np.eye生成一个对角阵,以二维列表的形式呈现,见blog代码后解释,可以完美理解one hot'''
alphabet = np.eye(alphabet_size, dtype='float32')
'''Repeat the alphabet to create training and test datasets'''
'''np.transpose: 转置'''
'''np.tile: 将数组沿各个方向复制,默认向右拓展'''
'''先向右拓展再转置,等于是扩充列向量(每一个alphabet矩阵都是一串编码)'''
'''这个train_dataset拥有 batch_size串编码,仍然可以看成是一维的数据集'''
train_dataset = np.transpose(np.tile(alphabet, int(batch_size)))
test_dataset = np.transpose(np.tile(alphabet, int(batch_size * 1000)))
print('--Setting up autoencoder graph--')
input, output, noise_std_dev, h_norm = _implement_autoencoder(alphabet_size, channel_use)
print( '--Setting up training scheme--')
train_step = _implement_training(output, input)
print('--Setting up accuracy--')
accuracy = _implement_accuracy(output, input)
print('--Starting the tensorflow session--')
sess = _setup_interactive_tf_session()
_init_and_start_tf_session(sess)
print('--Training the autoencoder over awgn channel--')
_train(train_step, input, noise_std_dev, nrof_steps, train_dataset, snrs_db, rate, accuracy)
print('--Evaluating autoencoder performance--')
bler = _evaluate(input, noise_std_dev, test_dataset, snrs_db, rate, accuracy)
print('--Closing the session--')
_close_tf_session(sess)
return bler
特别注意数据集的生成
生成数据集过程中关键的 api 为 np.eye 与 np.tile
为什么源码说np.eye是用来生成one hot编码的?
做个实验看看
import numpy as np
block_size = 2
alphabet_size = pow(2, block_size)
alphabet = np.eye(alphabet_size, dtype='float32')
print(alphabet)
得到的结果为
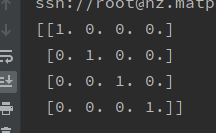
什么意思?
原本一串信息码为 1234
但是转换为one hot后
1变为 1000
2变为 0100
3变为 0010
4变为 0001
这就叫one hot编码,有几种分类就编为几位,并且每一位都代表一种分类
理解了np.eye之后就可以轻松理解为什么要利用np.tile扩充batch_size了
这样一个train_dataset中就有 batch_size串信息编码
_implement_autoencoder 中描述了网络结构,如下
具体代码分析加在注释里了,十分详细,看一遍下来就能理清了
def _implement_autoencoder(input_dimension, encoder_dimension):
'''为即将输入的张量插入占位符,[None, input_dimension]为输入张量的shape, None表示batch_size数量未知'''
input = tf.compat.v1.placeholder(tf.float32, [None, input_dimension])
'''Densely connected encoder layer'''
W_enc1 = _weight_variable([input_dimension, input_dimension])
b_enc1 = _bias_variable([input_dimension])
'''matuml是矩阵乘法'''
'''矩阵乘法前提,左列右行相等,结果为一个纬度为左行右列的矩阵'''
'''从tensor的角度看,这是两个二维tensor在相乘'''
'''h_enc1 的 shape 为[input_dimension, input_dimension]'''
h_enc1 = tf.nn.relu(tf.matmul(input, W_enc1) + b_enc1)
'''Densely connected encoder layer'''
'''这一层类比编码器'''
W_enc2 = _weight_variable([input_dimension, encoder_dimension])
b_enc2 = _bias_variable([encoder_dimension])
'''这里shape转变为[input_dimension, encoder_dimension]'''
h_enc2 = tf.matmul(h_enc1, W_enc2) + b_enc2
'''Normalization layer'''
'''tf.math.reciprocal用于计算倒数'''
'''tf.reduce_sum压缩求和,用于降纬, https://blog.csdn.net/arjick/article/details/78415675'''
'''tf.expand_dims 令tensor在指定轴上扩充纬度,参考 https://blog.csdn.net/TeFuirnever/article/details/88797810'''
'''一缩一扩,shape 保持在[input_dimension, encoder_dimension]'''
normalization_factor = tf.math.reciprocal(tf.sqrt(tf.reduce_sum(tf.square(h_enc2), 1))) * np.sqrt(encoder_dimension)
h_norm = tf.multiply(tf.tile(tf.expand_dims(normalization_factor, 1), [1, encoder_dimension]), h_enc2)
'''AWGN noise layer'''
noise_std_dev = tf.compat.v1.placeholder(tf.float32)
channel = tf.random.normal(tf.shape(h_norm), stddev=noise_std_dev)
h_noisy = tf.add(h_norm, channel)
'''Densely connected decoder layer'''
'''这一层类比解码器'''
'''shape 变回 [input_dimension, input_dimension]'''
W_dec1 = _weight_variable([encoder_dimension, input_dimension])
b_dec1 = _bias_variable([input_dimension])
h_dec1 = tf.nn.relu(tf.matmul(h_noisy, W_dec1) + b_dec1)
'''Output layer'''
W_out = _weight_variable([input_dimension, input_dimension])
b_out = _bias_variable([input_dimension])
output = tf.nn.softmax(tf.matmul(h_dec1, W_out) + b_out)
'''input 是一个二维tensor [input_dimension, input_dimension]'''
'''output 也是一个二维tensor,shape与input一摸一样 [input_dimension, input_dimension]'''
'''noise_std_dev是一个浮点数,表示噪声标准差'''
'''h_norm shape 为 [input_dimension, encoder_dimension]'''
return (input, output, noise_std_dev, h_norm)
为了搞明白输入输出tensor的shape变化,我们需要搞明白tf各个api的具体功能
参考:https://blog.csdn.net/UESTC_C2_403/article/details/72328296
用到的函数如下:
def _weight_variable(shape):
initial = tf.random.truncated_normal(shape, stddev=0.01)
return tf.Variable(initial)
def _bias_variable(shape):
initial = tf.constant(0.01, shape=shape)
return tf.Variable(initial)
tf.truncated_normal(shape, mean, stddev) :shape表示生成张量的维度,mean是均值,stddev是标准差。这个函数产生正太分布,均值和标准差自己设定。这是一个截断的产生正太分布的函数,就是说产生正太分布的值如果与均值的差值大于两倍的标准差,那就重新生成。和一般的正太分布的产生随机数据比起来,这个函数产生的随机数与均值的差距不会超过两倍的标准差,但是一般的别的函数是可能的。
可以看出此函数生成了随机的某一层的weights
tf.constant 顾名思义,生成常量
1.5 自问自答: autoencoder到底是什么?
就目前接收到的知识来说,autoencoder 起到了自动 “编码+解码”的功能,可以代替一个通信系统中的核心数字部分
它的数据集不要专门的标签,因为input就是标签,通过input和ouput的差距就能作反向传播更新权重
2 RTN
目前已有的代码只有 autoencoder,论文中其余的 RTN 以及 用于调制分类的 CNN的代码都没有,因此要完全自己写
论文中的RTN结构只有receiver,对标普通autoencoder的代码为
'''Densely connected decoder layer'''
'''这一层类比解码器'''
'''shape 变回 [input_dimension, input_dimension]'''
W_dec1 = _weight_variable([encoder_dimension, input_dimension])
b_dec1 = _bias_variable([input_dimension])
h_dec1 = tf.nn.relu(tf.matmul(h_noisy, W_dec1) + b_dec1)
'''Output layer'''
W_out = _weight_variable([input_dimension, input_dimension])
b_out = _bias_variable([input_dimension])
output = tf.nn.softmax(tf.matmul(h_dec1, W_out) + b_out)
也就是说 baseline只有两层
但是看RTN的概念图这两层需要扩充为4层以上
其中比较陌生的是 transformer layer 以及 linear activation,以前没用过
目前的激活函数基本都是非线性的,softmax, sigmoid ,tahn, ReLU啥的,线性激活我理解为就是不作激活处理。。。
google 搜索 “tensorflow transformer layer”,出来一个api 叫 tf.Transform,但是这个需要自己编写一个数据预处理函数,不像是在这种情况下使用的
先试下残差结构
将网络修改为
'''Densely connected decoder layer'''
'''这一层类比解码器'''
'''shape 变回 [input_dimension, input_dimension]'''
W_dec1 = _weight_variable([encoder_dimension, input_dimension])
b_dec1 = _bias_variable([input_dimension])
h_dec1 = tf.nn.relu(tf.matmul(h_noisy, W_dec1) + b_dec1)
W_dec2 = _weight_variable([input_dimension, input_dimension])
b_dec2 = _bias_variable([input_dimension])
h_dec2 = tf.nn.relu(tf.matmul(h_dec1, W_dec2) + b_dec2)
'''这就当作是transform layer了'''
h_dec3 = tf.add(h_noisy, h_dec2)
'''在softmax之前再经过两层'''
W_dec4 = _weight_variable([input_dimension, input_dimension])
b_dec4 = _bias_variable([input_dimension])
h_dec4 = tf.nn.relu(tf.matmul(h_dec3, W_dec4) + b_dec4)
W_dec5 = _weight_variable([input_dimension, input_dimension])
b_dec5 = _bias_variable([input_dimension])
h_dec5 = tf.nn.relu(tf.matmul(h_dec4, W_dec5) + b_dec5)
'''Output layer'''
W_out = _weight_variable([input_dimension, input_dimension])
b_out = _bias_variable([input_dimension])
output = tf.nn.softmax(tf.matmul(h_dec5, W_out) + b_out)
把修改后的网络命名为 _implement_autoencoder_RTN

这么改报错了,因为从 h_noisy 到 h_dec2 经历了 encoder_dimension 到 input_dimension的变化,shape不一致,不能相加
这是从一篇很经典的论文 Spatial transformer networks 中借鉴的结果,paers with code上有很多代码
https://paperswithcode.com/paper/spatial-transformer-networks#code
还有一篇论文题目就是 Radio Transformer Networks,发表于2016年,但是这篇综述没有引用,之后再看
Radio Transformer Networks: Attention Models for Learning to Synchronize in Wireless Systems
看完了更新
3 调制分类 CNN
3.1 调制分类数据集
解压 RML2016.10a.tar.bz2 后得到一个 pkl文件
tar -jxvf RML2016.10a.tar.bz2
pkl 文件如何打开?参考如何打开.pkl文件,查看.pkl文件里的内容(Python3.6)
数据集整个是一个字典,key是调制种类,是字符串,value是对应的码字,是三维数组
数据集官网说明
数据集github
官方使用例程
官方例程正好用的keras,可以无缝转接tf2
但是例程是python2的代码,因此需要改一些地方
比如,如果报错
TypeError: object of type ‘map’ has no len()
这是因为 python3中map不再是list对象,需要手动转换list(XXX)
导入数据集后shape与例程中一致

虽然 [2, 128]代表什么目前还不清楚,先把网络跑起来
3.2 网络结构与训练效果
微调了一下代码,将 in_shp 设为(1, 2,128),因为在例程中用的Conv2D

实验证明这么改不行,卷积的时候会出问题,因为kernel size都大于1,而以上shape接收conv的是(1, 2)
对照例程,左边开始第一位为 channels,也就是说扩充出来的那一个维度是用来作channels的,那么tf2中应该在最右边扩充维度,于是将输入shape改为(2, 128, 1),同理(128, 2, 1)对于conv2d来说都一样
建立的模型 tensor 流动是正常的
复习下输出特征图大小
valid:
O= |(I-K)/S+1 |
same:
O = I/S 如果是小数,向上取整

但是 shape 与论文对不上
从论文中看似乎(2, 128)中的2才是处于channels这一维度,然后 卷积核只作用于128这一纬度。

或许论文意思是128是矩阵边长?
将input shape改为(128, 128, 2)再试了一次(padding设为’valid’)

可以发现对上了,有一个纬度没对上是因为kernel_size我用的(2,8)和(1,16)
或许2*8的意思是两个8?
照此修改,成型
虽然tensor对上了,但是参数量不对,上面这个模型有600+万参数,论文中说只有30+万个
这个只能是conv1d了
改为conv1d后各参数都非常完美,网络参数量只比论文多了33个,这个应该是框架不同引起的

训练完后用tensorboard画出曲线

橙色是训练集,蓝色是测试集,虽然没画混淆矩阵,但是从训练曲线中已经可以明显地看出过拟合,论文中也没有提到关于这个网络的训练细节
感想
就这篇论文来看,这一领域至少在2017年还是一片蓝海,有很多可以做的东西。只是因为刚刚起步,可供参考的资料也很少,有利有弊。
因为面临的数据形式,要解决的任务都与CV、NLP等有很明显的区别,所以在通信领域做DL或许要创新不同于CNN、transformer等的网络结构
就目前为止coding的体验来看,要整明白关键还是在通信,AI只是工具,没有充足的通信基础知识支撑模型跑出来的效果都不知道怎么分析,之后还是得着重加强通信基础知识的学习。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)