文章下载地址:https://arxiv.org/pdf/2002.11949.pdf
代码地址:GitHub - KaihuaTang/Scene-Graph-Benchmark.pytorch
发表地点:CVPR 2020
1 内容概述
现有的场景图生成方法因为training loss的存在,也就是数据集中关系分布存在长尾分布,存在关系检测并不准确的问题。
本文提出了一种基于TDE的因果推理的场景图生成方法,保留biased traing的过滤结果作用,同时去除图像内容上下文干扰带来的关系检测不准确这一副作用。
通过这样一种训练方式的改善,可以看见场景图生成效果的提升。
2 研究背景和创新点
背景:场景图生成任务本是为下游任务例如captioning,VQA提供一个全面的视觉场景表征。现有的方法往往会抛弃掉模糊的视觉关系,将所有的内容抽象成一张graph,图中具有稀疏的object分布以及一些binary的links.
问题:因为严重的training bias,现有的生成模型更像是一堆object词汇的堆积。
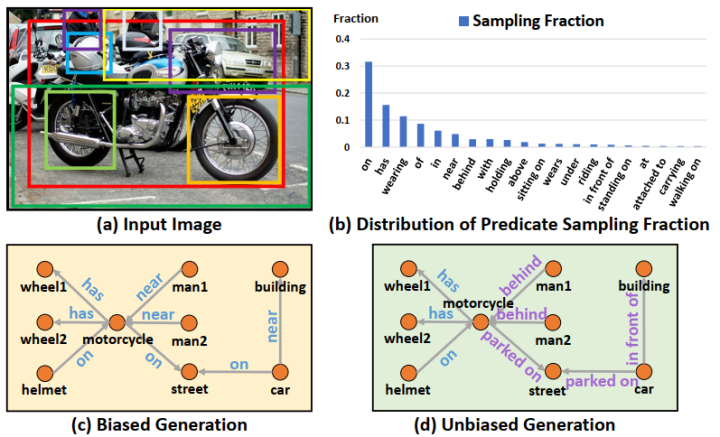
例如b所示,因为训练集合中各类关系的长尾分布,很容易在后续场景图生成的过程中用near等常见关系来替代behind/in front of等不常见关系。所以如何更好地分辨细粒度的视觉关系呢?
bias也可以分成两类:好的contextual prior,可以帮助过滤不合理的关系对,例如apple不可能park on table;坏的long-tailed bias,就如上面所述。
如何留下好的,去掉坏的bias,找出一种unbiased的训练方式就是研究的重点了。
创新点:决策往往是针对内容content和上下文context一起确定的,人类不会因为环境的bias做出不恰当的决定作者认为是因为人类可以进行因果推理。
因此文章的创新点就是将likelihood-based的推理变成causality-based的推理,重点就是分辨训练数据带来的main effect以及side effect。
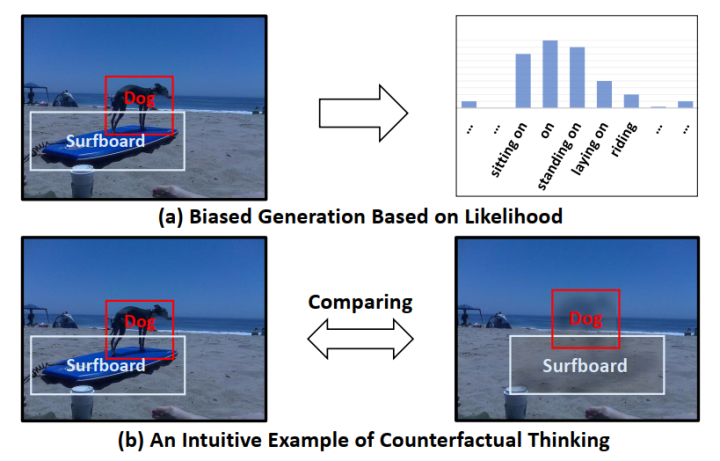
如果可以将常见的biased推理结果以及反事实的推理结果相比较,如上图b所示,是否就可以留下好的bias的过滤效果并且去掉上下文对谓词预测结果的影响呢?基于此,作者提出了一种基于total direct effect的unbiased场景图生成方法。
3 方法介绍
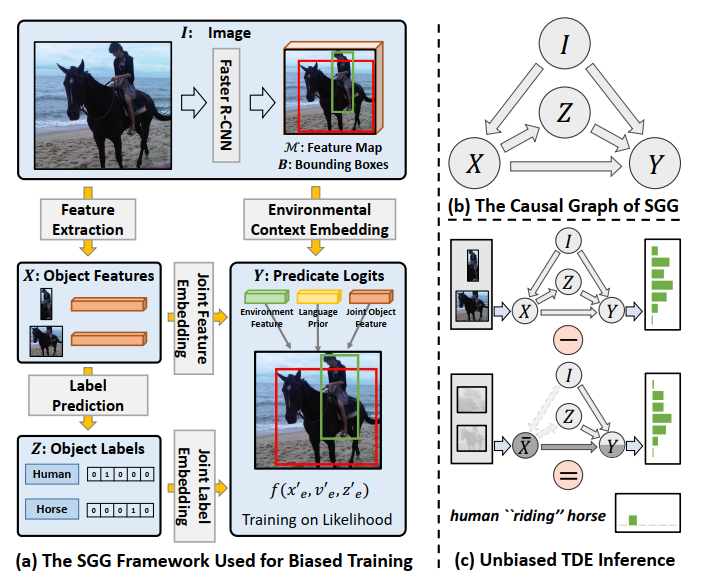
下方讲述将用因果图的角度来分析场景图生成这一任务
3.1 节点关系介绍
在上图(b)中,
节点I表示图像输入,嵌入预训练的Faster R-CNN模型,输出bounding box以及feature map;
关系I->X表示object feature extractor,可以对object进行特征嵌入;
节点X表示经过嵌入后的object feature;
关系X->Z表示object分类过程,将X输入后得到object的对应类别;
节点Z表示object的类别;
关系X->Y表示对场景图生成的object feature输入;
关系Z->Y表示对场景图生成的object class输入;
关系I->Y表示对场景图生成的视觉上下文输入;
节点Y表示predicate classification,谓词预测,也就是将三部分输入融合在一起后得到的预测结果;
训练损失就是常见的cross-entropy loss.
3.2 内容介绍

如(a)中在学习到好的contextual prior之后,进行因果推理过程中的干预。
图(b),就是将I->X的边切断,给X随便赋值,忽略掉object特征对推理结果的干扰,尽量避免视觉内容对推理结果的干扰。
图(c)就是反事实推理,不改变Z,只是改变X的结果,只依赖上下文得到的推理结果。
(c)中的结果不针对object内容,只是由上下文带来的bias,也是我们想去除的。
在因果推理中,最后的预测结果也就是total direct effect(TDE),计算方法如下所示
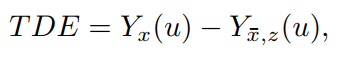
最后的预测结果也是两个预测logits的相减。
4 实验结果
作者在Visual Genome数据集上做了场景图生成的实验,在COCO以及VG上完成图文检索的实验。
作者通过relationship retrieval,zero-shot relationship retrieval以及sentence-to-graph retrieval等方面来判断场景图生成的好坏与否。发现通过TDE这样的一种计算方式,实验结果有了明显的提升。

实验的可视化结果也展现了通过TDE这样一种谓词预测方式后生成结果的改善。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)