博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业
毕业设计
项目实战6年之久,选择我们就是选择放心、选择安心毕业✌感兴趣的可以先收藏起来,点赞、关注不迷路✌
毕业设计:2023-2024年计算机毕业设计1000套(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕业设计选题汇总
1、项目介绍
技术栈:
Python语言、Django框架、协同过滤推荐算法、Echarts可视化、HTML
2、项目界面
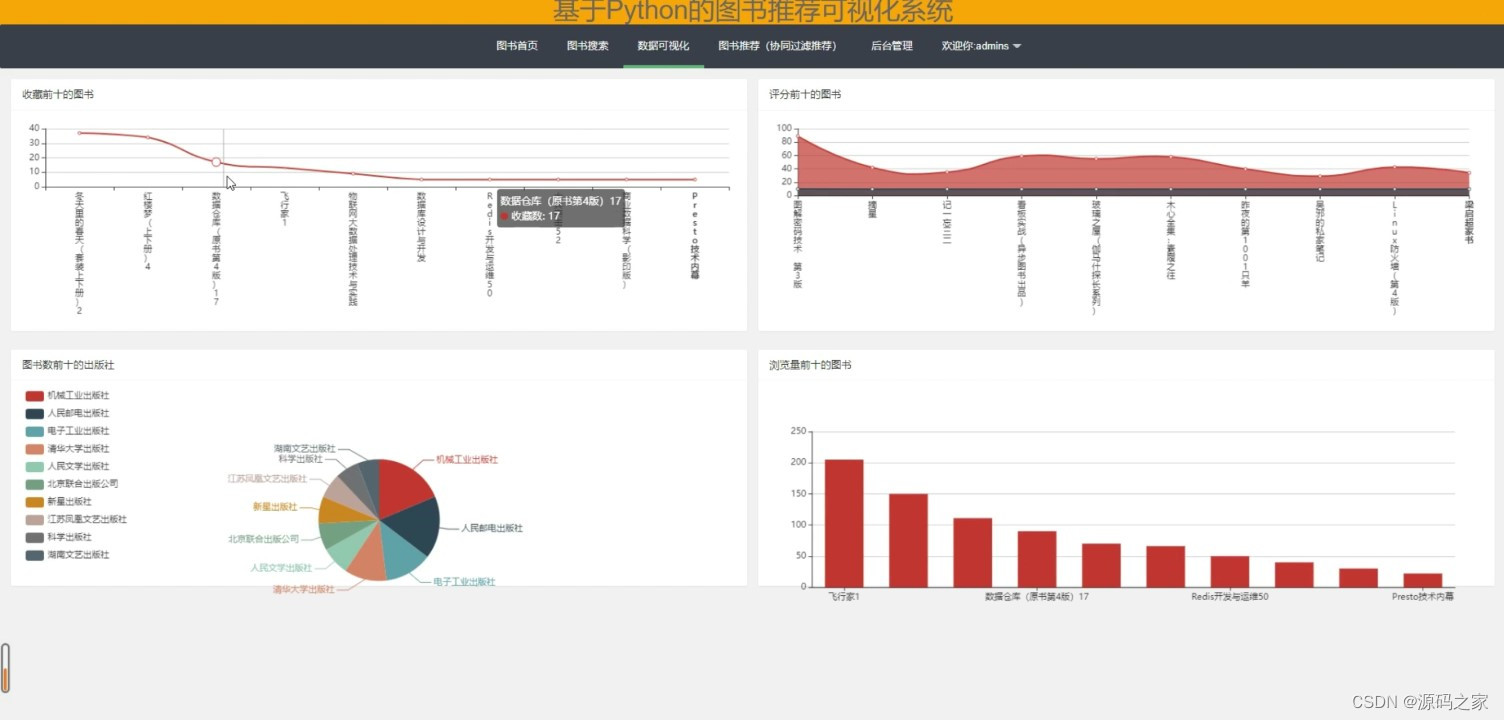
(1)图书数据可视化
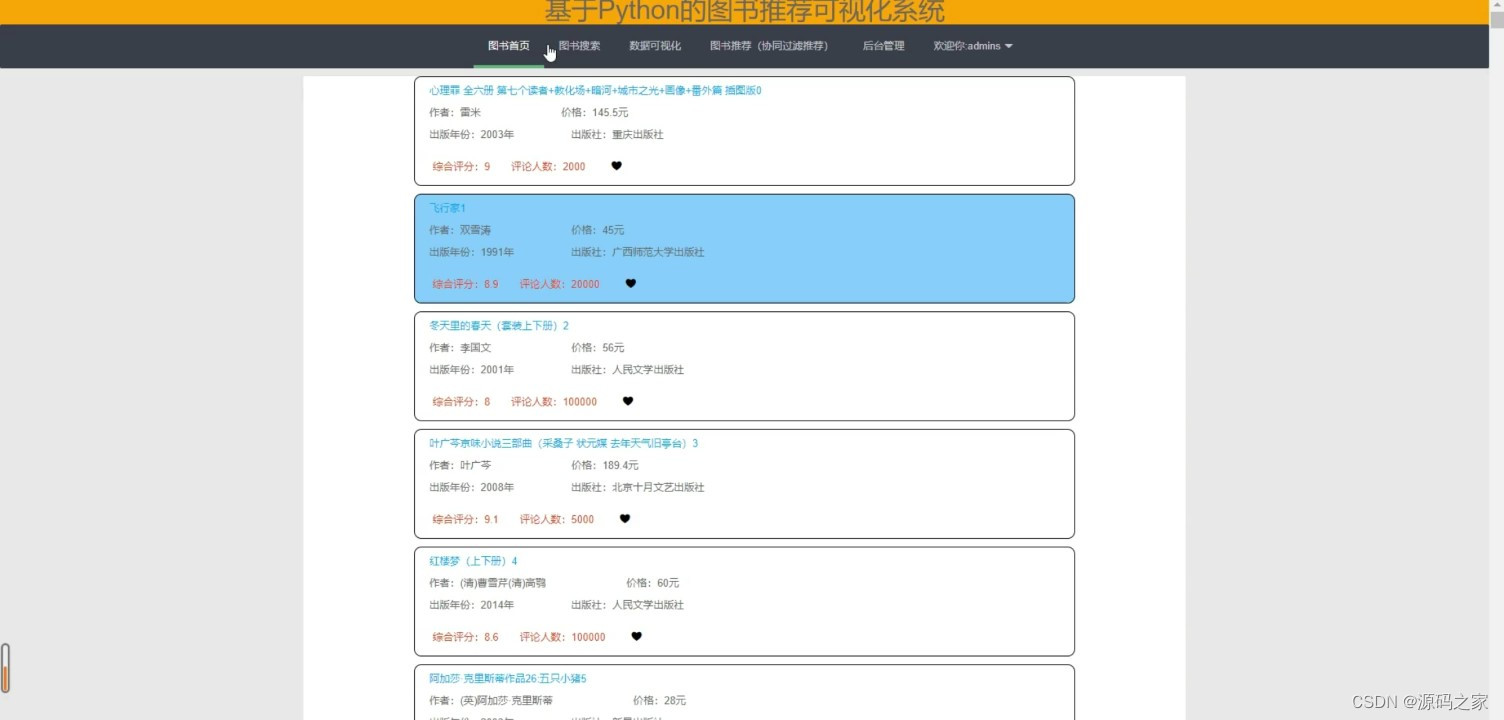
(2)图书信息
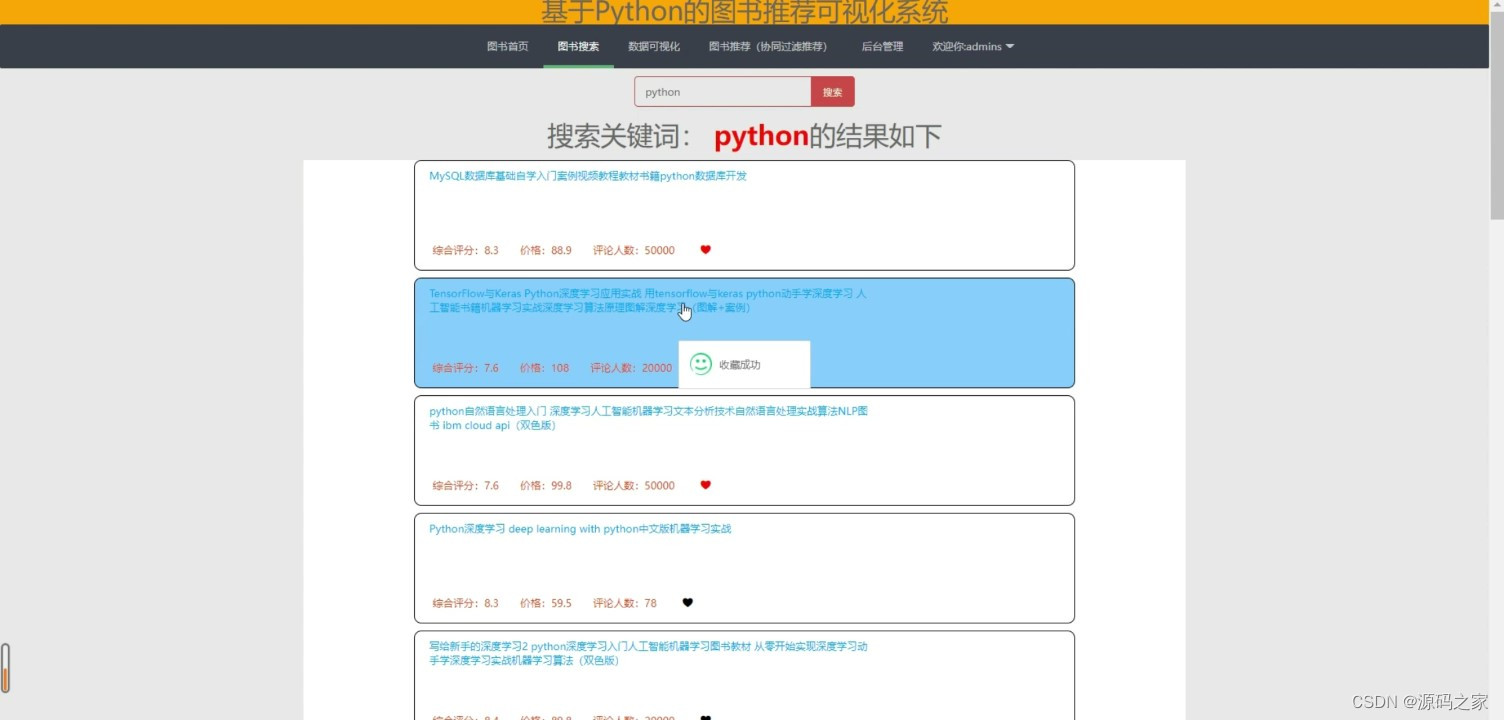
(3)数据搜索
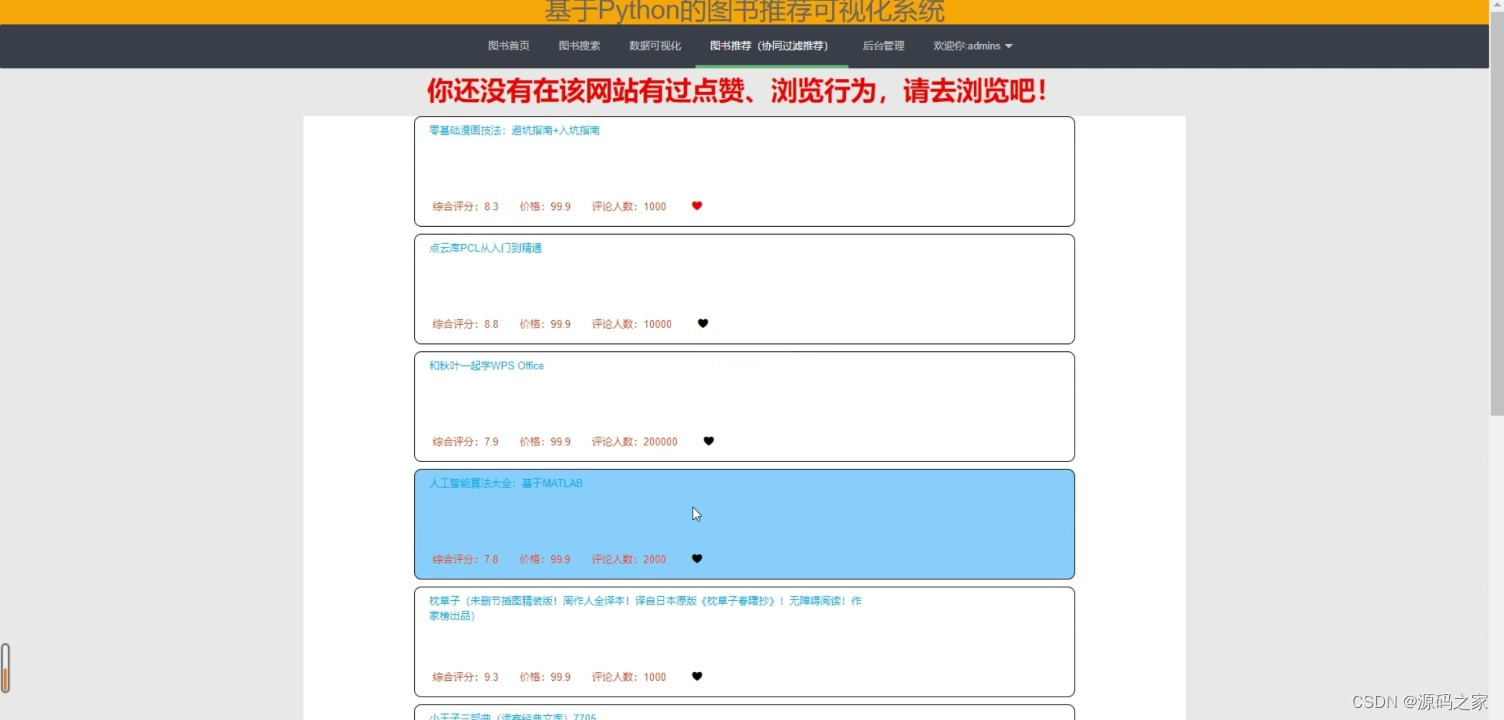
(4)图书推荐
(5)后台管理
3、项目说明
图书推荐可视化系统是基于Python语言和Django框架开发的,主要利用协同过滤推荐算法和Echarts可视化技术实现的一种图书推荐系统。
该系统的核心功能是根据用户的阅读历史和兴趣偏好,为用户推荐可能感兴趣的图书。系统通过收集用户的阅读记录和评分数据,利用协同过滤推荐算法分析用户与其他用户的相似度,从而找到与用户兴趣相似的其他用户,并将这些用户喜欢的图书推荐给用户。
为了更直观地展示推荐结果和用户兴趣分布情况,系统利用Echarts可视化技术将数据以图表的形式呈现出来。用户可以通过系统界面浏览推荐结果和了解自己的兴趣偏好。
系统的前端界面采用HTML编写,通过Django框架与后端进行交互,实现用户注册、登录、图书搜索、推荐结果展示等功能。用户可以通过系统界面进行图书搜索、评分、收藏等操作,以便系统更准确地了解用户的兴趣和需求。
总的来说,图书推荐可视化系统利用Python语言、Django框架、协同过滤推荐算法、Echarts可视化和HTML等技术,为用户提供个性化的图书推荐服务,并通过可视化展示方式帮助用户更好地了解自己的兴趣偏好。
4、核心代码
#!/usr/bin/env python
#-*-coding:utf-8-*-
import math
import pdb
class ItemBasedCF:
def __init__(self,train):
self.train = train
# def readData(self):
# #读取文件,并生成用户-物品的评分表和测试集
# self.train = dict()
# #用户-物品的评分表
# for line in open(self.train_file):
# user,score,item = line.strip().split(",")
# self.train.setdefault(user,{})
# self.train[user][item] = int(float(score))
def ItemSimilarity(self):
#建立物品-物品的共现矩阵
cooccur = dict() #物品-物品的共现矩阵
buy = dict() #物品被多少个不同用户购买N
for user,items in self.train.items():
for i in items.keys():
buy.setdefault(i,0)
buy[i] += 1
cooccur.setdefault(i,{})
for j in items.keys():
if i == j : continue
cooccur[i].setdefault(j,0)
cooccur[i][j] += 1
#计算相似度矩阵
self.similar = dict()
for i,related_items in cooccur.items():
self.similar.setdefault(i,{})
for j,cij in related_items.items():
self.similar[i][j] = cij / (math.sqrt(buy[i] * buy[j]))
return self.similar
#给用户user推荐,前K个相关用户,前N个物品
def Recommend(self,user,K=10,N=10):
rank = dict()
action_item = self.train[user]
#用户user产生过行为的item和评分
for item,score in action_item.items():
sortedItems = sorted(self.similar[item].items(),key=lambda x:x[1],reverse=True)[0:K]
for j,wj in sortedItems:
if j in action_item.keys():
continue
rank.setdefault(j,0)
rank[j] += score * wj
return dict(sorted(rank.items(),key=lambda x:x[1],reverse=True)[0:N])
# #声明一个ItemBasedCF的对象
# item = ItemBasedCF("item_book.txt")
# item.ItemSimilarity()
# recommedDict = item.Recommend("Li Si")
# for k,v in recommedDict.items():
# print(k,"\t",v)
????✌
感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!
????✌
5、源码获取方式
????
由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。
????
点赞、收藏、关注,不迷路,
下方查看
????????
获取联系方式
????????