限流算法,顾名思义,就是指对流量进行控制的算法,因此也常被称为流控算法。
我们在日常生活中,就有很多限流的例子,比如地铁站在早高峰的时候,会利用围栏让乘客们有序排队,限制队伍行进的速度,避免大家一拥而上;再比如在疫情期间,很多景点会按时段限制售卖的门票数量,避免同一时间在景区的游客太多等等。
对于 Server 服务而言,单位时间内能承载的请求也是存在容量上限的,我们也需要通过一些策略,控制请求数量多少,实现对流量的控制,虽然,限流为了保证一部分的请求流量可以得到正常的响应,一定会导致部分请求响应速度下降或者直接被拒绝,但是相比于全部的请求都不能得到响应,系统直接崩溃的情况,限流还是要好得多。
本篇内容主要介绍:业务中的限流场景、限流算法、限流值的确认、不仅仅限流
文章目录
- 一、业务中的限流场景
- 1、限流算法介绍
- 2、突发流量
- 3、恶意流量
- 4、业务本身需要
- 二、限流算法
- 1、固定窗口计数器
- 2、滑动窗口计数器
- 3、Leaky Bucket 漏桶 - As a Meter Version
- 4、Leaky Bucket 漏桶 - As a Queue Version
- 5、Token Bucket 令牌桶
- 三、限流相关问题
-
一、业务中的限流场景
1、限流算法介绍
限流算法,顾名思义,就是指对流量进行控制的算法,因此也常被称为流控算法。
我们在日常生活中,就有很多限流的例子,比如地铁站在早高峰的时候,会利用围栏让乘客们有序排队,限制队伍行进的速度,避免大家一拥而上;再比如在疫情期间,很多景点会按时段限制售卖的门票数量,避免同一时间在景区的游客太多等等。
对于 Server 服务而言,单位时间内能承载的请求也是存在容量上限的,我们也需要通过一些策略,控制请求数量多少,实现对流量的控制,虽然,限流为了保证一部分的请求流量可以得到正常的响应,一定会导致部分请求响应速度下降或者直接被拒绝,但是相比于全部的请求都不能得到响应,系统直接崩溃的情况,限流还是要好得多。
限流与熔断经常被人弄混,博主认为它们最大的区别在于限流主要在 Server 实现,而熔断主要在 Client 实现,当然了,一个服务既可以充当 Server 也可以充当 Client,这也是让限流与熔断同时存在一个服务中,这两个概念才容易被混淆。
业务中的典型的限流场景主要分为三种:
2、突发流量
突发流量是我们需要限流的主要场景之一。当我们后端服务处理能力有限,面对业务流量突然激增,即突发流量时,很容易出现服务器被打垮的情况。
如我们常见的双十一,京东 618 这些整点秒杀的业务,12306 这些都会出现某段时间面临着大量的流量流入的情况。
在这些情况下,除了提供更好的弹性伸缩的能力,以及在已经能预测的前提下提前准备更多的资源,我们还能做的一件事就是利用限流来保护服务,即使拒绝了一部分请求,至少也让剩下的请求可以正常被响应。
3、恶意流量
除了突发流量,限流有的时候也是出于安全性的考虑。网络世界有其凶险的地方,所有暴露出去的API都有可能面对非正常业务的请求。
比如我们常见的各种各样的网络爬虫,或者恶意的流量攻击网站等等,都会产生大量的恶意流量。面对我们服务对外暴露接口的大规模疯狂调用,很有可能也会可能导致服务崩溃,在很多时候也会导致我们需要的计算成本飙升,比如云计算的场景下。
4、业务本身需要
还有一种业务本身需要的场景,这种场景也十分常见,比如云服务平台根据不同套餐等级,需要对不同服务流量限制时,也是需要采取限流算法的。
二、限流算法
终于到了正题,我们这里将介绍 4 种限流算法:分别是 固定窗口计数器、滑动窗口计数器、Leaky Bucket 漏桶、Token Bucket令牌桶
1、固定窗口计数器
规定我们单位时间处理的请求数量。比如我们规定我们的一个接口一分钟只能访问10次的话。使用固定窗口计数器算法的话可以这样实现:给定一个变量counter来记录处理的请求数量,当1分钟之内处理一个请求之后counter+1,1分钟之内的如果counter=100的话,后续的请求就会被全部拒绝。等到 1分钟结束后,将counter回归成0,重新开始计数(ps:只要过了一个周期就讲counter回归成0)。

这种限流算法无法保证限流速率,因而无法保证突然激增的流量。比如我们限制一个接口一分钟只能访问10次的话,前半分钟一个请求没有接收,后半分钟接收了10个请求。
# 具体实现
package com.lizhengi.limiter;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
public class FixedWindowCounterLimiter {
private final int limit;
private final AtomicInteger count;
public FixedWindowCounterLimiter(int windowSize, int limit) {
this.limit = limit;
count = new AtomicInteger(0);
ExecutorService threadPool = new ThreadPoolExecutor(1, 1, 1L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy());
threadPool.execute(() -> {
while (true) {
try {
Thread.sleep(windowSize * 1000L);
} catch (InterruptedException e) {
System.out.println("Happen Exception: " + e.getMessage());
}
count.set(0);
}
});
}
public boolean tryAcquire() {
int num = count.incrementAndGet();
return num <= limit;
}
}
# 测试代码
package com.lizhengi.limiter;
import org.junit.Test;
public class FixedWindowCounterLimiterTest {
@Test
public void test() throws InterruptedException {
int allNum, passNum = 0, blockNum = 0;
FixedWindowCounterLimiter rateLimiter = new FixedWindowCounterLimiter(2, 5);
allNum = 3;
for (int i = 0; i < allNum; i++) {
if (rateLimiter.tryAcquire()) {
passNum++;
} else {
blockNum++;
}
}
System.out.println("请求总数: " + allNum + ", 通过数: " + passNum + ", 被限流数: " + blockNum);
Thread.sleep(5000);
allNum = 14;
passNum = blockNum = 0;
for (int i = 0; i < allNum; i++) {
if (rateLimiter.tryAcquire()) {
passNum++;
} else {
blockNum++;
}
}
System.out.println("请求总数: " + allNum + ", 通过数: " + passNum + ", 被限流数: " + blockNum);
}
}
# 测试结果
请求总数: 3, 通过数: 3, 被限流数: 0
请求总数: 14, 通过数: 5, 被限流数: 9
2、滑动窗口计数器
算的上是固定窗口计数器算法的升级版。滑动窗口计数器算法相比于固定窗口计数器算法的优化在于:它把时间以一定比例分片。例如我们的借口限流每分钟处理60个请求,我们可以把 1 分钟分为60个窗口。每隔1秒移动一次,每个窗口一秒只能处理 不大于 60(请求数)/60(窗口数) 的请求, 如果当前窗口的请求计数总和超过了限制的数量的话就不再处理其他请求。
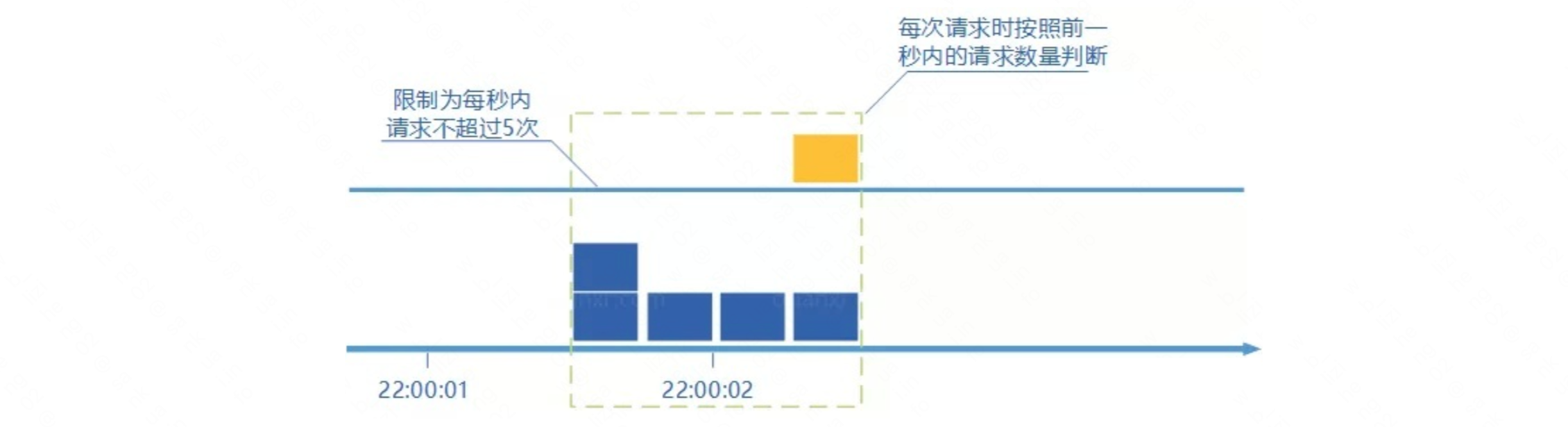
很显然:当滑动窗口的格子划分的越多,滑动窗口的滚动就越平滑,限流的统计就会越精确。
# 具体实现
package com.lizhengi.limiter;
import java.util.Arrays;
public class SlidingWindowCounterLimiter {
private final int slotNum;
private final int slotTime;
private final int limit;
private final int[] counters;
private long lastTime;
public SlidingWindowCounterLimiter(int windowSize, int limit) {
this(windowSize, limit, 10);
}
public SlidingWindowCounterLimiter(int windowSize, int limit, int slotNum) {
this.limit = limit;
this.slotNum = slotNum;
this.counters = new int[slotNum];
this.slotTime = windowSize * 1000 / slotNum;
this.lastTime = System.currentTimeMillis();
}
public synchronized boolean tryAcquire() {
long currentTime = System.currentTimeMillis();
int slideNum = (int) Math.floor((currentTime - lastTime) * 1.0 / slotTime);
slideWindow(slideNum);
int sum = Arrays.stream(counters).sum();
if (sum > limit) {
return false;
} else {
counters[slotNum - 1]++;
return true;
}
}
private void slideWindow(int num) {
if (num == 0) {
return;
}
if (num >= slotNum) {
Arrays.fill(counters, 0);
} else {
for (int index = num; index < slotNum; index++) {
int newIndex = index - num;
counters[newIndex] = counters[index];
counters[index] = 0;
}
}
lastTime = lastTime + (long) num * slotTime;
}
}
# 测试代码
package com.lizhengi.limiter;
import org.junit.Test;
public class SlidingWindowCounterLimiterTest {
@Test
public void test() throws InterruptedException {
int allNum, passNum = 0, blockNum = 0;
SlidingWindowCounterLimiter rateLimiter = new SlidingWindowCounterLimiter(2, 5);
allNum = 3;
for (int i = 0; i < allNum; i++) {
if (rateLimiter.tryAcquire()) {
passNum++;
} else {
blockNum++;
}
}
System.out.println("请求总数: " + allNum + ", 通过数: " + passNum + ", 被限流数: " + blockNum);
Thread.sleep(5000);
allNum = 14;
passNum = blockNum = 0;
for (int i = 0; i < allNum; i++) {
if (rateLimiter.tryAcquire()) {
passNum++;
} else {
blockNum++;
}
}
System.out.println("请求总数: " + allNum + ", 通过数: " + passNum + ", 被限流数: " + blockNum);
}
}
# 测试结果
请求总数: 3, 通过数: 3, 被限流数: 0
请求总数: 14, 通过数: 6, 被限流数: 8
3、Leaky Bucket 漏桶 - As a Meter Version
我们可以把发请求的动作比作成注水到桶中,我们处理请求的过程可以比喻为漏桶漏水。我们往桶中以任意速率流入水,以一定速率流出水。当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。如果想要实现这个算法的话也很简单,准备一个队列用来保存请求,然后我们定期从队列中拿请求来执行就好了。
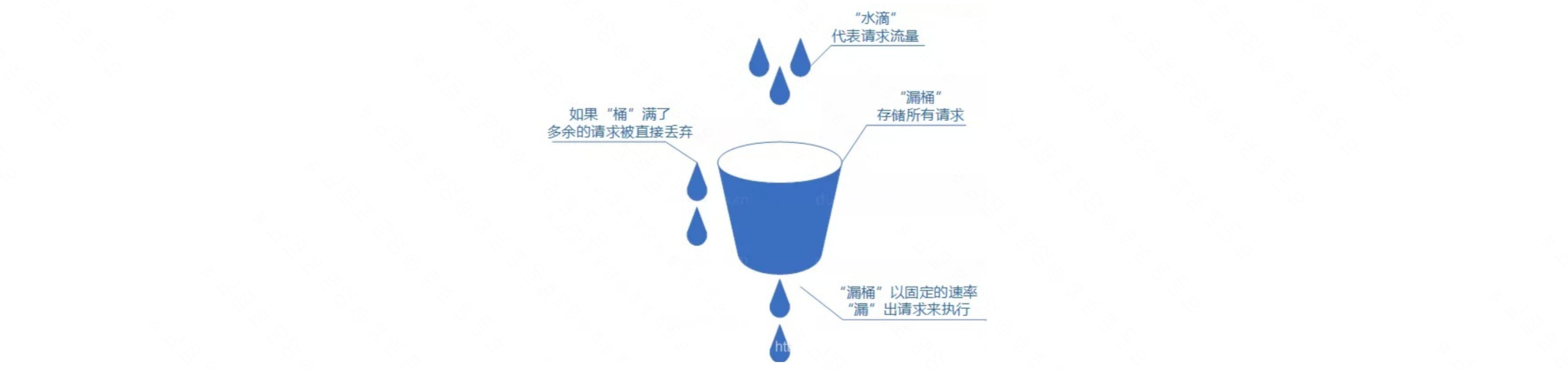
# 具体实现
package com.lizhengi.limiter;
public class LeakyBucketLimiter1 {
private final long capacity;
private final long rate;
private long water;
private long lastTime;
public LeakyBucketLimiter1(long capacity, long rate) {
this.capacity = capacity;
this.rate = rate;
this.water = 0;
this.lastTime = System.currentTimeMillis();
}
public synchronized boolean tryAcquire() {
long currentTime = System.currentTimeMillis();
long outWater = (currentTime - lastTime) / 1000 * rate;
water = Math.max(0, water - outWater);
lastTime = currentTime;
if (water < capacity) {
water++;
return true;
} else {
return false;
}
}
}
# 测试代码
package com.lizhengi.limiter;
import org.junit.Test;
public class LeakyBucketLimiter1Test {
@Test
public void test() throws InterruptedException {
int allNum, passNum = 0, blockNum = 0;
LeakyBucketLimiter1 rateLimiter = new LeakyBucketLimiter1(5, 1);
allNum = 3;
for (int i = 0; i < allNum; i++) {
if (rateLimiter.tryAcquire()) {
passNum++;
} else {
blockNum++;
}
}
System.out.println("请求总数: " + allNum + ", 通过数: " + passNum + ", 被限流数: " + blockNum);
Thread.sleep(5000);
allNum = 14;
passNum = blockNum = 0;
for (int i = 0; i < allNum; i++) {
if (rateLimiter.tryAcquire()) {
passNum++;
} else {
blockNum++;
}
}
System.out.println("请求总数: " + allNum + ", 通过数: " + passNum + ", 被限流数: " + blockNum);
}
}
# 测试结果
请求总数: 3, 通过数: 3, 被限流数: 0
请求总数: 14, 通过数: 5, 被限流数: 9
4、Leaky Bucket 漏桶 - As a Queue Version
在 As a Meter Version 版本的漏桶中,当桶中水未满,请求即会直接被放行。而在漏桶的另外一个版本 As a Queue Version 中,如果桶中水未满,则该请求将会被暂时存储在桶中。然后以漏桶固定的出水速率对桶中存储的请求依次放行。对比两个版本的漏桶算法不难看出,As a Meter Version 版本的漏桶算法可以应对、处理突发流量,只要桶中尚有足够空余即可立即放行请求;而对于 As a Queue Version 版本的漏桶,其只会以固定速率放行请求,无法充分利用后续系统的处理能力。
# 具体实现
package com.lizhengi.limiter;
import lombok.AllArgsConstructor;
import org.apache.commons.lang3.concurrent.BasicThreadFactory;
import java.time.LocalTime;
import java.time.format.DateTimeFormatter;
import java.util.concurrent.*;
public class LeakyBucketLimiter2 {
private final ArrayBlockingQueue<UserRequest> queue;
public LeakyBucketLimiter2(int capacity, long rate) {
queue = new ArrayBlockingQueue<>(capacity);
ScheduledExecutorService threadPool = new ScheduledThreadPoolExecutor(1, new BasicThreadFactory.
Builder().namingPattern("example-schedule-pool-%d").daemon(true).build());
long period = 1000 / rate;
threadPool.scheduleAtFixedRate(getTask(), 0, period, TimeUnit.MILLISECONDS);
}
public boolean tryAcquire(UserRequest userRequest) {
return queue.offer(userRequest);
}
private Runnable getTask() {
return () -> {
UserRequest userRequest = queue.poll();
if (userRequest != null) {
userRequest.handle();
}
};
}
@AllArgsConstructor
public static class UserRequest {
private static final DateTimeFormatter FORMATTER = DateTimeFormatter.ofPattern("HH:mm:ss.SSS");
private String name;
public void handle() {
String timeStr = FORMATTER.format(LocalTime.now());
String msg = "<" + timeStr + "> " + name + " 开始处理";
System.out.println(msg);
}
}
}
# 代码测试
package com.lizhengi.limiter;
import org.junit.Test;
public class LeakyBucketLimiter2Test {
@Test
public void test() throws InterruptedException {
int allNum, passNum = 0, blockNum = 0;
LeakyBucketLimiter2 rateLimiter = new LeakyBucketLimiter2(5, 2);
allNum = 7;
for(int i=1; i<=allNum; i++) {
String name = "用户请求:" + i;
LeakyBucketLimiter2.UserRequest userRequest = new LeakyBucketLimiter2.UserRequest(name);
if( rateLimiter.tryAcquire( userRequest ) ) {
passNum++;
}else{
blockNum++;
}
}
System.out.println("请求总数: "+allNum+", 通过数: "+passNum+", 被限流数: "+blockNum);
Thread.sleep(120*1000);
}
}
# 测试结果
请求总数: 7, 通过数: 5, 被限流数: 2
<15:48:21.542> 用户请求:1 开始处理
<15:48:22.032> 用户请求:2 开始处理
<15:48:22.532> 用户请求:3 开始处理
<15:48:23.032> 用户请求:4 开始处理
<15:48:23.533> 用户请求:5 开始处理
5、Token Bucket 令牌桶
令牌桶算法也比较简单。和漏桶算法算法一样,我们的主角还是桶(这限流算法和桶过不去啊)。不过现在桶里装的是令牌了,请求在被处理之前需要拿到一个令牌,请求处理完毕之后将这个令牌丢弃(删除)。我们根据限流大小,按照一定的速率往桶里添加令牌。
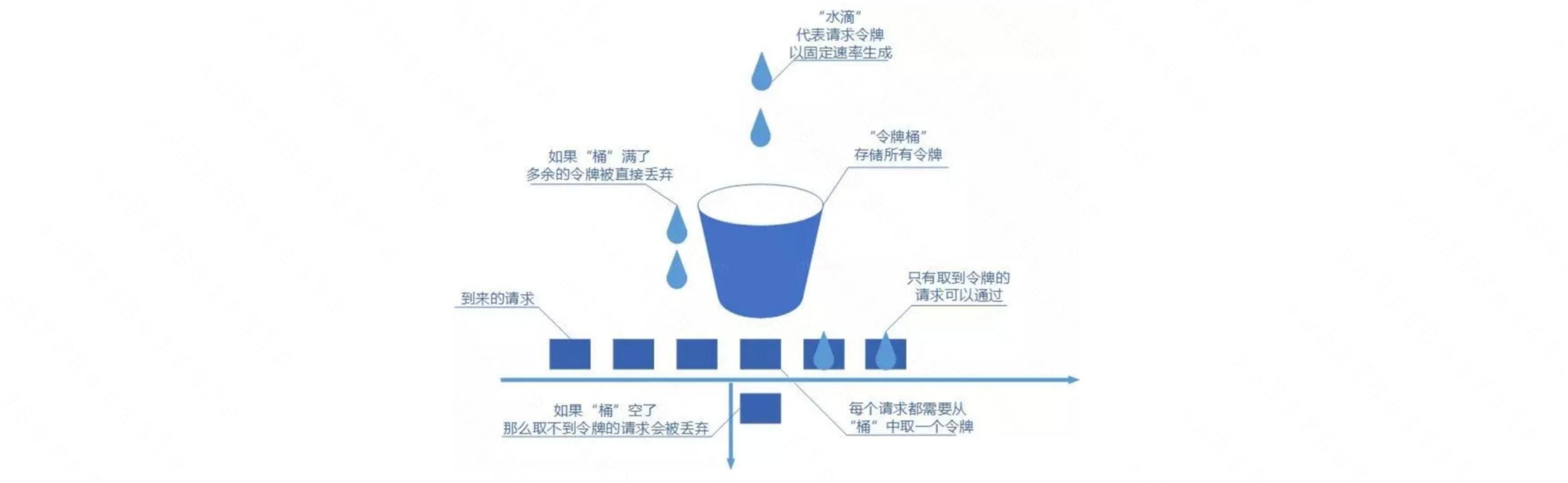 # 具体实现
# 具体实现
package com.lizhengi.limiter;
public class TokenBucketLimiter {
private final long capacity;
private final long rate;
private long tokens;
private long lastTime;
public TokenBucketLimiter(long capacity, long rate) {
this.capacity = capacity;
this.rate = rate;
this.tokens = capacity;
this.lastTime = System.currentTimeMillis();
}
public synchronized boolean tryAcquire() {
long currentTime = System.currentTimeMillis();
long newTokenNum = (currentTime - lastTime) / 1000 * rate;
tokens = Math.min(capacity, tokens + newTokenNum);
lastTime = currentTime;
if (tokens > 0) {
tokens--;
return true;
} else {
return false;
}
}
}
# 测试代码
package com.lizhengi.limiter;
import org.junit.Test;
public class TokenBucketLimiterTest {
@Test
public void test() throws InterruptedException {
int allNum, passNum = 0, blockNum = 0;
TokenBucketLimiter rateLimiter = new TokenBucketLimiter(5, 1);
allNum = 3;
for (int i = 0; i < allNum; i++) {
if (rateLimiter.tryAcquire()) {
passNum++;
} else {
blockNum++;
}
}
System.out.println("请求总数: " + allNum + ", 通过数: " + passNum + ", 被限流数: " + blockNum);
Thread.sleep(5000);
allNum = 14;
passNum = blockNum = 0;
for (int i = 0; i < allNum; i++) {
if (rateLimiter.tryAcquire()) {
passNum++;
} else {
blockNum++;
}
}
System.out.println("请求总数: " + allNum + ", 通过数: " + passNum + ", 被限流数: " + blockNum);
}
}
# 测试结果
请求总数: 3, 通过数: 3, 被限流数: 0
请求总数: 14, 通过数: 5, 被限流数: 9
三、限流相关问题
1、限流值的确认
正确的值,才能起到效果;限流多了等于没限,少了则会影响服务利用效率
对于核心服务限流的值可以通过以下方法来设置合理的值
- 观察评估:通过CAT大盘,可以观察到服务的平时调用量,QPS和各个调用方。
- 压测摸底:通过quake平台,可以压测核心服务的支持的最大QPS。
- 场景分析:通过分析各业务调用场景,评估一个合理的值。
2、不仅仅限流
限流作为系统稳定性保障的有效措施之一,常常与重试、降级、熔断等作为组合方法一起使用。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)