文章目录
- 概述
- 工作窃取算法
- 工作窃取算法的优缺点
- 使用 ForkJoinPool 进行分叉和合并
- ForkJoinPool使用
- RecursiveAction
- RecursiveTask
- Fork/Join 案例Demo
概述
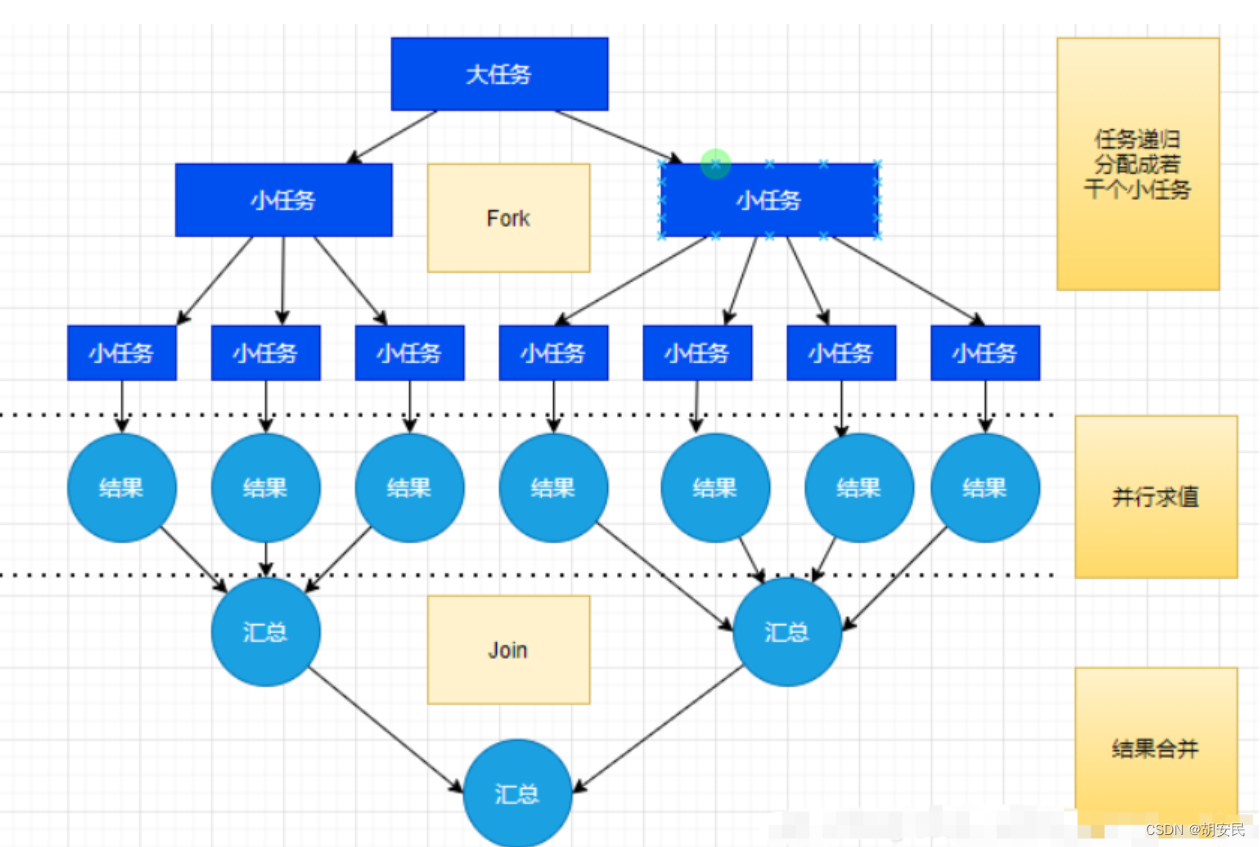
Fork 就是把一个大任务切分为若干个子任务并行地执行,Join 就是合并这些子任务的执行结果,最后得到这个大任务的结果。Fork/Join 框架使用的是工作窃取算法。
工作窃取算法
工作窃取算法是指某个线程从其他队列里窃取任务来执行。对于一个比较大的任务,可以把它分割为若干个互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。但是,有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务需要处理,于是它就去其他线程的队列里窃取一个任务来执行。由于此时它们访问同一个队列,为了减小竞争,通常会使用双端队列。被窃取任务的线程永远从双端队列的头部获取任务,窃取任务的线程永远从双端队列的尾部获取任务。
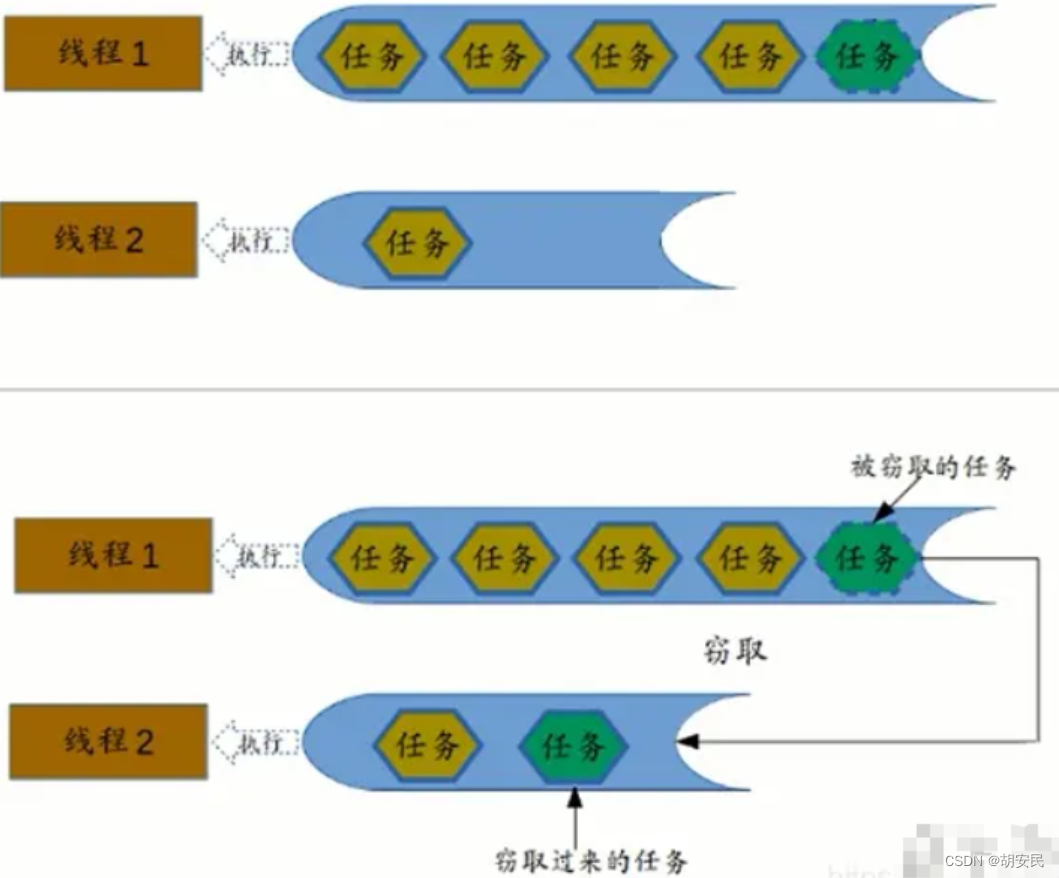
工作窃取算法的优缺点
优点:充分利用线程进行并行计算,减少了线程间的竞争。
缺点:双端队列只存在一个任务时会导致竞争,会消耗更多的系统资源,因为需要创建多个线程和多个双端队列。
使用 ForkJoinPool 进行分叉和合并
ForkJoinPool 在 Java 7 中被引入。它和 ExecutorService 很相似,除了一点不同。ForkJoinPool 让我们可以很方便地把任务分裂成几个更小的任务,这些分裂出来的任务也将会提交给 ForkJoinPool。任务可以继续分割成更小的子任务,只要它还能分割。可能听起来有些抽象,因此本节中我们将会解释 ForkJoinPool 是如何工作的,还有任务分割是如何进行的。
分叉和合并解释
在我们开始看 ForkJoinPool 之前我们先来简要解释一下分叉和合并的原理。
分叉和合并原理包含两个递归进行的步骤。两个步骤分别是分叉步骤和合并步骤。
分叉
一个使用了分叉和合并原理的任务可以将自己分叉(分割)为更小的子任务,这些子任务可以被并发执行。如下图所示:
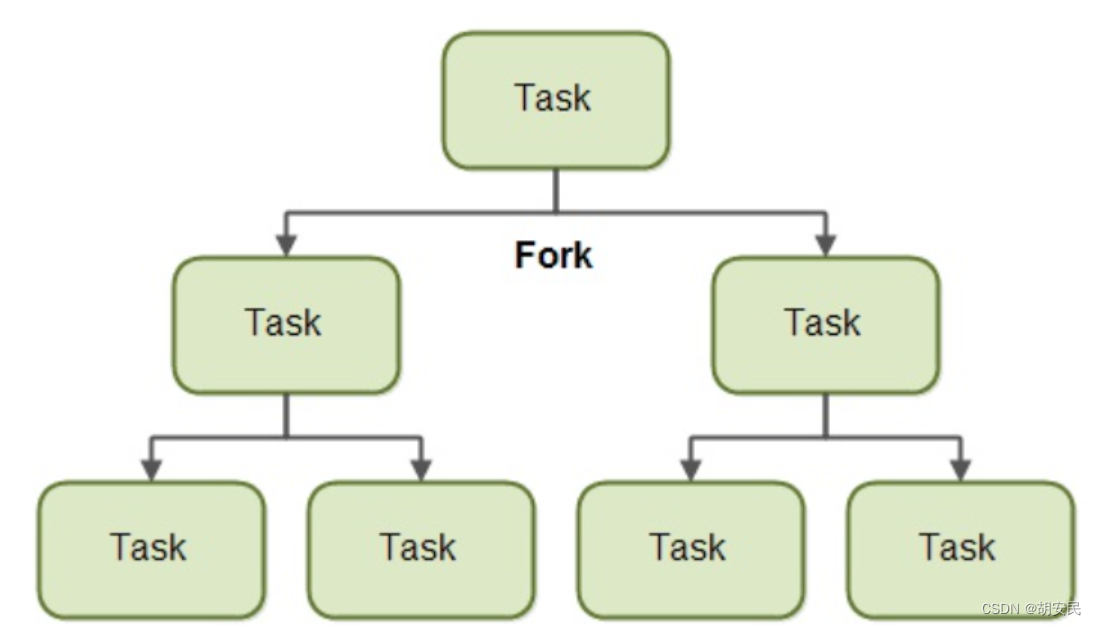
通过把自己分割成多个子任务,每个子任务可以由不同的 CPU 并行执行,或者被同一个 CPU 上的不同线程执行。
只有当给的任务过大,把它分割成几个子任务才有意义。把任务分割成子任务有一定开销,因此对于小型任务,这个分割的消耗可能比每个子任务并发执行的消耗还要大。
什么时候把一个任务分割成子任务是有意义的,这个界限也称作一个阀值。这要看每个任务对有意义阀值的决定。很大程度上取决于它要做的工作的种类。
合并
当一个任务将自己分割成若干子任务之后,该任务将进入等待所有子任务的结束之中。一旦子任务执行结束,该任务可以把所有结果合并到同一个结果。图示如下:
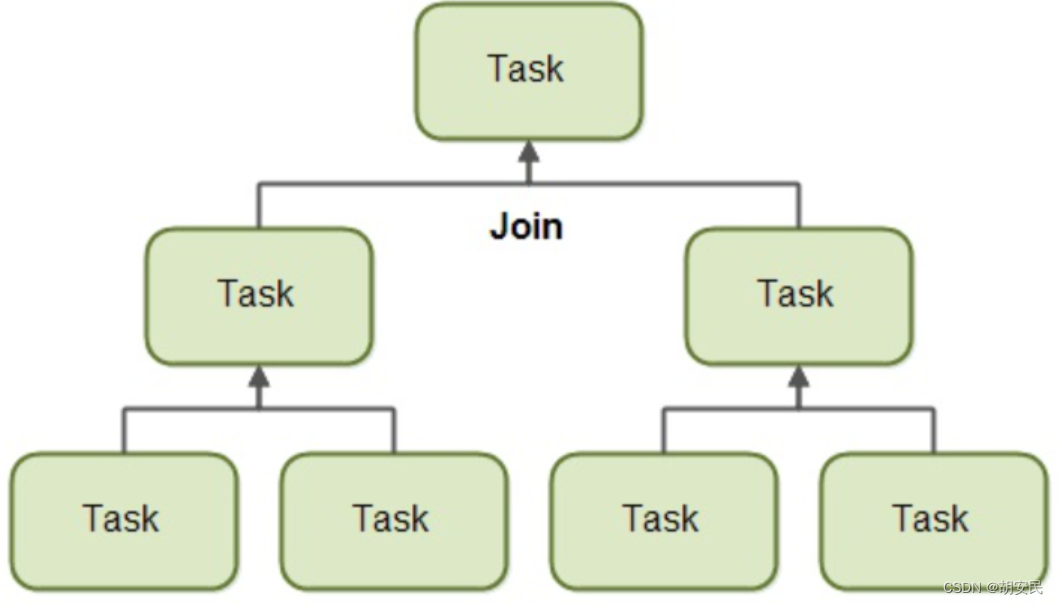
当然,并非所有类型的任务都会返回一个结果。如果这个任务并不返回一个结果,它只需等待所有子任务执行完毕。也就不需要结果的合并啦。
ForkJoinPool使用
ForkJoinPool 是一个特殊的线程池,它的设计是为了更好的配合 分叉-和-合并 任务分割的工作。ForkJoinPool 也在 java.util.concurrent 包中,其完整类名为 java.util.concurrent.ForkJoinPool。
创建一个 ForkJoinPool
你可以通过其构造子创建一个 ForkJoinPool。作为传递给 ForkJoinPool 构造子的一个参数,你可以定义你期望的并行级别。并行级别表示你想要传递给 ForkJoinPool 的任务所需的线程或 CPU 数量。以下是一个 ForkJoinPool 示例:
ForkJoinPool forkJoinPool = new ForkJoinPool(4);
提交任务到 ForkJoinPool
就像提交任务到 ExecutorService 那样,把任务提交到 ForkJoinPool。你可以提交两种类型的任务。一种是没有任何返回值的(一个 “行动”),另一种是有返回值的(一个"任务")。这两种类型分别由 RecursiveAction 和 RecursiveTask 表示。接下来介绍如何使用这两种类型的任务,以及如何对它们进行提交。
RecursiveAction
RecursiveAction 是一种没有任何返回值的任务。它只是做一些工作,比如写数据到磁盘,然后就退出了。一个 RecursiveAction 可以把自己的工作分割成更小的几块,这样它们可以由独立的线程或者 CPU 执行。
你可以通过继承来实现一个 RecursiveAction。示例如下:
package com;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
public class MyRecursiveAction extends RecursiveAction {
private long workLoad = 0;
public MyRecursiveAction(long workLoad) {
this.workLoad = workLoad;
}
@Override
protected void compute() {
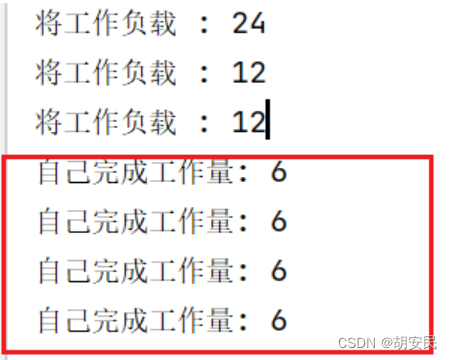
if(this.workLoad > 10) {
System.out.println("将工作负载 : " + this.workLoad);
List<MyRecursiveAction> subtasks =
new ArrayList<MyRecursiveAction>();
subtasks.addAll(createSubtasks());
for(RecursiveAction subtask : subtasks){
subtask.fork();
}
} else {
System.out.println("自己完成工作量: " + this.workLoad);
}
}
private List<MyRecursiveAction> createSubtasks() {
List<MyRecursiveAction> subtasks = new ArrayList<MyRecursiveAction>();
MyRecursiveAction subtask1 = new MyRecursiveAction(this.workLoad / 2);
MyRecursiveAction subtask2 = new MyRecursiveAction(this.workLoad / 2);
subtasks.add(subtask1);
subtasks.add(subtask2);
return subtasks;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool(4);
MyRecursiveAction myRecursiveAction = new MyRecursiveAction(24);
forkJoinPool.invoke(myRecursiveAction);
}
}
RecursiveTask
RecursiveTask 是一种会返回结果的任务。它可以将自己的工作分割为若干更小任务,并将这些子任务的执行结果合并到一个集体结果。用法和RecursiveAction一样唯一不同的就是可以返回值
以下是一个 RecursiveTask 示例:
package com;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class MyRecursiveTask extends RecursiveTask<Long> {
private long workLoad = 0;
public MyRecursiveTask (long workLoad) {
this.workLoad = workLoad;
}
@Override
protected Long compute() {
if(this.workLoad > 10) {
System.out.println("将工作负载 : " + this.workLoad);
List<MyRecursiveTask > subtasks = new ArrayList<MyRecursiveTask >();
subtasks.addAll(createSubtasks());
for(RecursiveTask subtask : subtasks){
subtask.fork();
}
long result = 0;
for(MyRecursiveTask subtask : subtasks) {
result += subtask.join();
}
return result;
} else {
System.out.println("自己完成工作量: " + this.workLoad);
return 1L ;
}
}
private List<MyRecursiveTask > createSubtasks() {
List<MyRecursiveTask > subtasks = new ArrayList<MyRecursiveTask >();
MyRecursiveTask subtask1 = new MyRecursiveTask (this.workLoad / 2);
MyRecursiveTask subtask2 = new MyRecursiveTask (this.workLoad / 2);
subtasks.add(subtask1);
subtasks.add(subtask2);
return subtasks;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool(4);
MyRecursiveTask myRecursiveAction = new MyRecursiveTask(24);
Long invoke = forkJoinPool.invoke(myRecursiveAction);
System.out.println("最终结果: " + invoke);
}
}

MyRecursiveTask 类继承自 RecursiveTask,这也就意味着它将返回一个 Long 类型的结果。MyRecursiveTask 示例也会将工作分割为子任务,并通过 fork() 方法对这些子任务计划执行。此外,本示例还通过调用每个子任务的 join() 方法收集它们返回的结果。子任务的结果随后被合并到一个更大的结果,并最终将其返回。对于不同级别的递归,这种子任务的结果合并可能会发生递归。
Fork/Join 案例Demo
需求:使用 Fork/Join 计算 1-10000的和,当一个任务的计算数量大于3000时拆分任务,数量小于3000时计算。
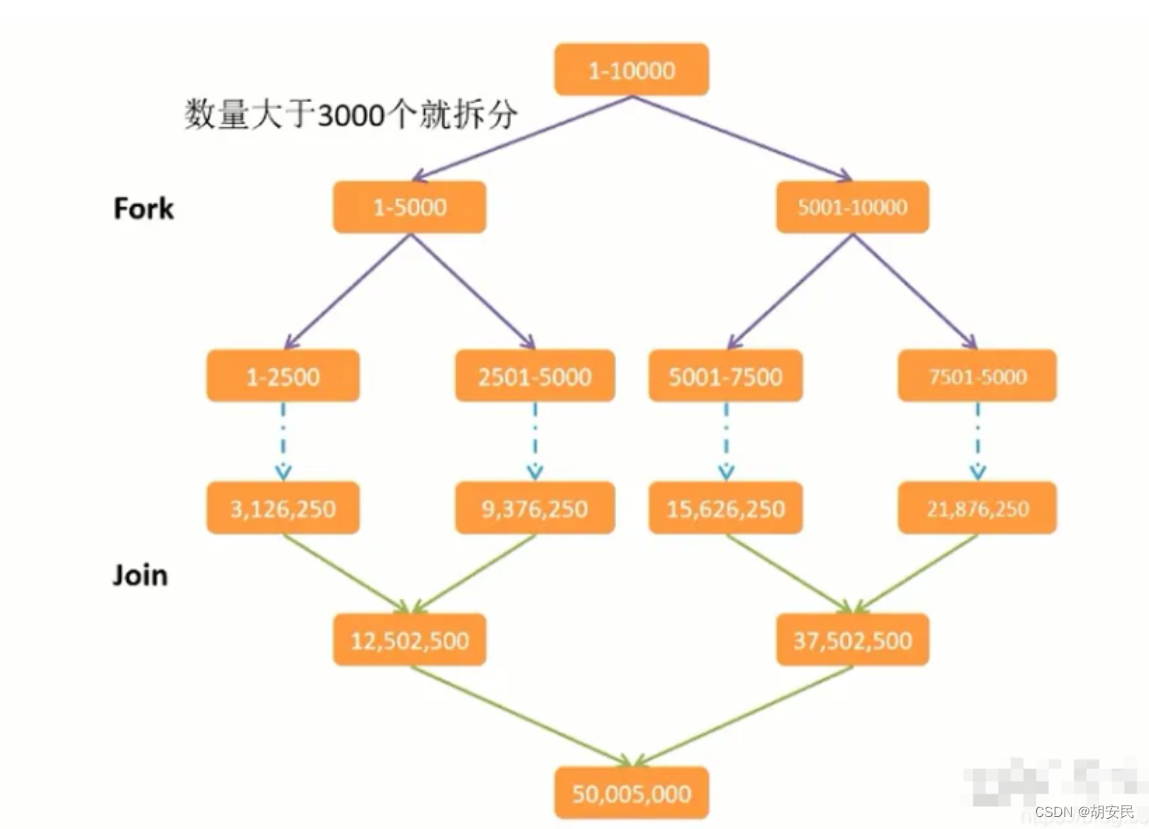
因为1~10000求和,耗时较少。下面我们将数据调大,求和1 ~ 59999999999(599亿),然后来对比一下使用 Fork/Join求和 和 普通求和之间的效率差异。
普通求和
public static void main(String[] args) {
Long start = System.currentTimeMillis();
long sum = 0l;
for (long i = 1; i <= 59999999999L; i++) {
sum+=i;
}
System.out.println(sum);
Long end = System.currentTimeMillis();
System.out.println("消耗时间:"+(end-start));
}
Fork/Join求和
package com;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class SumRecursiveTask extends RecursiveTask<Long> {
private static final long THRESHOLD = 3000L;
private final long start;
private final long end;
public SumRecursiveTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long length = end - start;
if(length < THRESHOLD){
long sum = 0;
for (long i = start; i <= end; i++) {
sum +=i;
}
return sum;
}else{
long middle = (start + end) /2;
SumRecursiveTask left = new SumRecursiveTask(start,middle);
left.fork();
SumRecursiveTask right = new SumRecursiveTask(middle+1,end);
right.fork();
return left.join() +right.join();
}
}
public static void main(String[] args) {
Long start = System.currentTimeMillis();
ForkJoinPool pool = new ForkJoinPool();
SumRecursiveTask task = new SumRecursiveTask(1, 59999999999L);
Long result = pool.invoke(task);
System.out.println("result="+result);
Long end = System.currentTimeMillis();
System.out.println("消耗时间:"+(end-start));
}
}
总结: 可以发现使用工作窃取算法能大大的提高我们计算的速度,理论上只要你电脑足够快这个提升是没有上限的 ,前提是任务是可拆分的

点赞 -收藏-关注-便于以后复习和收到最新内容
有其他问题在评论区讨论-或者私信我-收到会在第一时间回复
在本博客学习的技术不得以任何方式直接或者间接的从事违反中华人民共和国法律,内容仅供学习、交流与参考
免责声明:本文部分素材来源于网络,版权归原创者所有,如存在文章/图片/音视频等使用不当的情况,请随时私信联系我、以迅速采取适当措施,避免给双方造成不必要的经济损失。
感谢,配合,希望我的努力对你有帮助^_^
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)