python使用request+xpath爬取豆瓣电影
背景
由于毕设需要用到电影相关的数据,在网上想查找一个可以爬电影的教程,但是基本上所有的教程都是爬的豆瓣top250,并没有找到别的相关的教程,所以学习了一下使用python的request结合xpath爬取电影的相关信息。
话不多说上代码
我所爬取的url是:https://movie.douban.com/subject/25845392/,这个界面上的信息

如何获取到这个界面呢,我们首先来分析一下这个页面
豆瓣电影列表
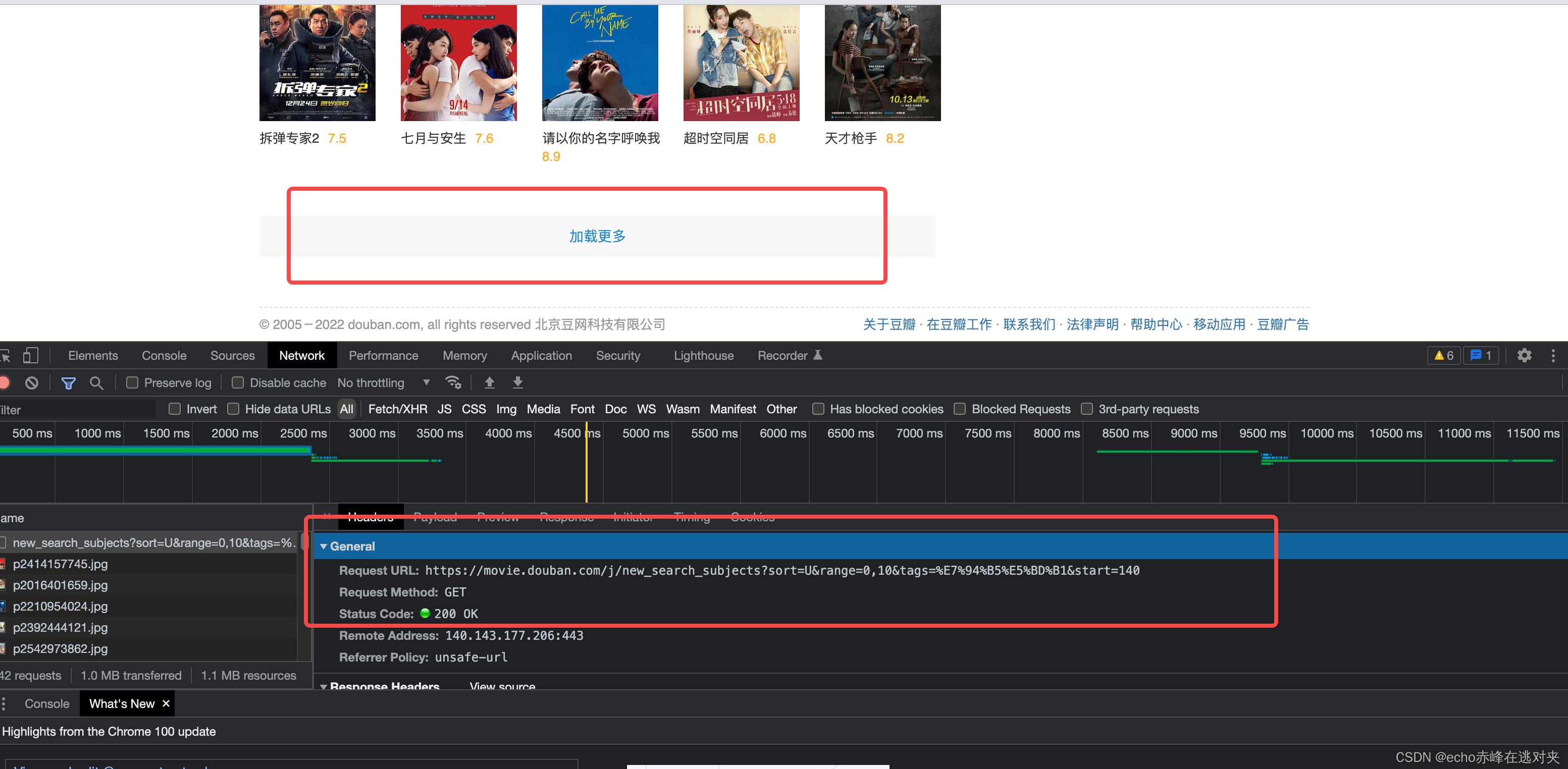
通过查看url的参数发现,可能是使用了分页的功能,所以要想查看所有的电影需要看看这些参数都是什么,打开开发者工具查看network,发现每次点击加载更多的时候都会有新的请求,这个请求后面携带的参数start=140应该就是每次分页所请求到的数据,因此我们就获取到了电影展示列表的url和参数都是什么,每次的参数都是增加20
网页分析完了我们开始写代码
import requests
from lxml import html
import json
import time
import random
import csv
import re
class douban:
def __init__(self):
self.URL = 'https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=%E7%94%B5%E5%BD%B1'
self.start_num = []
self.movie_url = []
for start_num in range(0, 20, 20):
self.start_num.append(start_num)
self.header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'}
好了准备工作结束了,我们来写通过xpath获取到页面的内容
def get_top250(self):
for start in self.start_num:
start = str(start)
response = requests.get(self.URL, params={'start':start}, headers=self.header)
page_content = response.content.decode()
json_data = json.loads(page_content)
movieList = []
for key in range(len(json_data['data'])):
movieDict = {}
movie_url = json_data['data'][key]['url']
rex = re.compile(r'subject/(\d+)')
mo = rex.search(movie_url)
movie_id = mo.group(1)
page_response = requests.get(movie_url, headers=self.header)
page_result = page_response.content.decode()
page_html = html.etree.HTML(page_result)
movie_name = page_html.xpath('//*[@id="content"]/h1/span[1]/text()')
director = page_html.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')
yanyuan = page_html.xpath('//*[@id="info"]/span[3]/span[2]')
for yanyuanList in yanyuan:
yanyuanData = yanyuanList.xpath('././a/text()')
juqing = page_html.xpath('//*[@id="info"]/span[@property="v:genre"]/text()')
country = page_html.xpath(u'//*[@id="info"]/span[contains(./text(), "制片国家/地区:")]/following::text()[1]')
language = page_html.xpath('//*[@id="info"]/span[contains(./text(), "语言:")]/following::text()[1]')
push_time = page_html.xpath('//*[@id="info"]/span[11]/text()')
movie_long = page_html.xpath('//*[@id="info"]/span[13]/text()')
pingfen = page_html.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()')
conver_img = page_html.xpath('//*[@id="mainpic"]/a/img/@src')
describe = page_html.xpath('normalize-space(//*[@id="link-report"]/span/text())')
下面我来讲一下如何通过xpath获取到标签的内容,非常简单只需要打开网页的开发者工具,然后找到所需要的信息的标签,例如制片国家
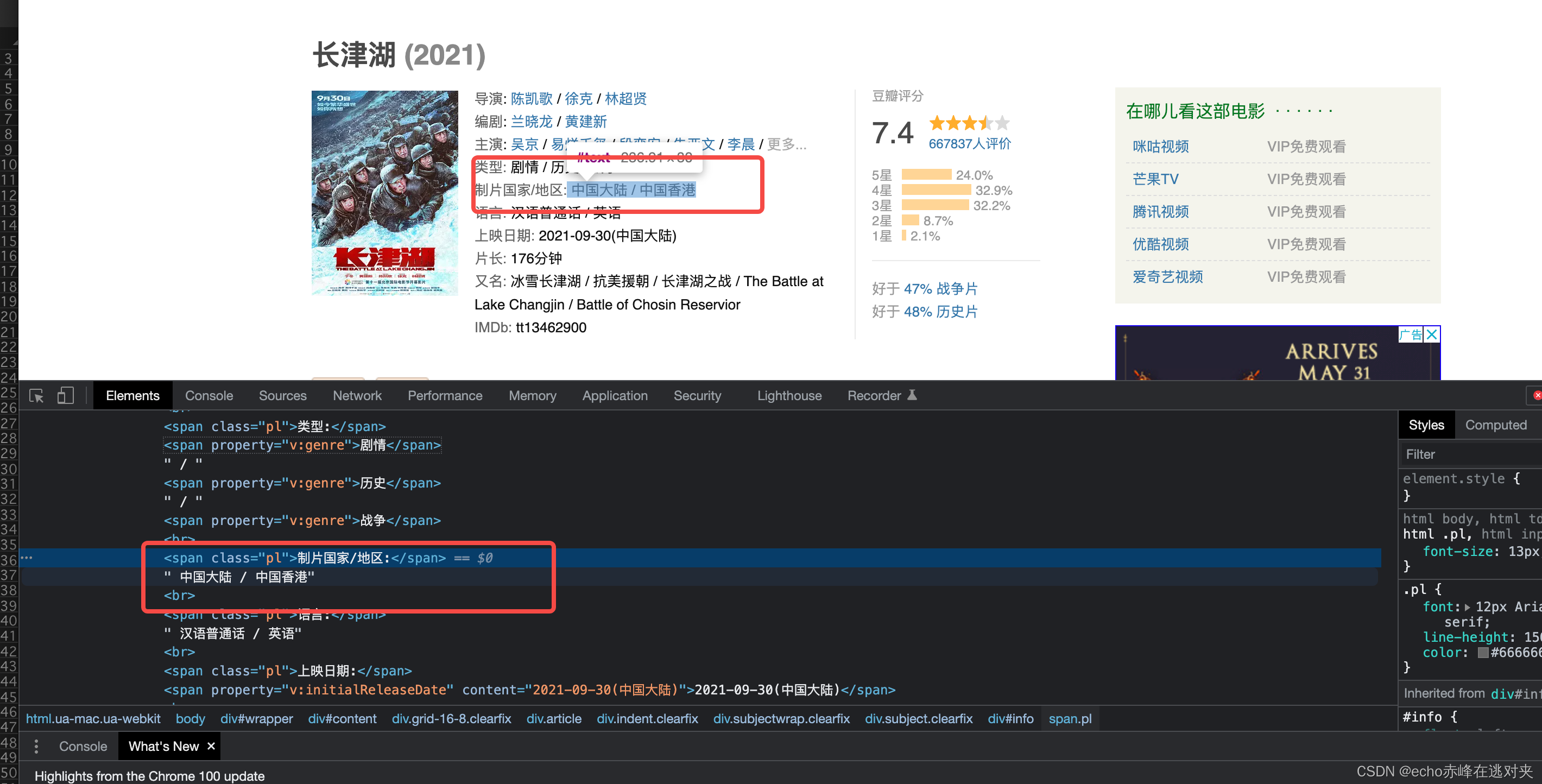
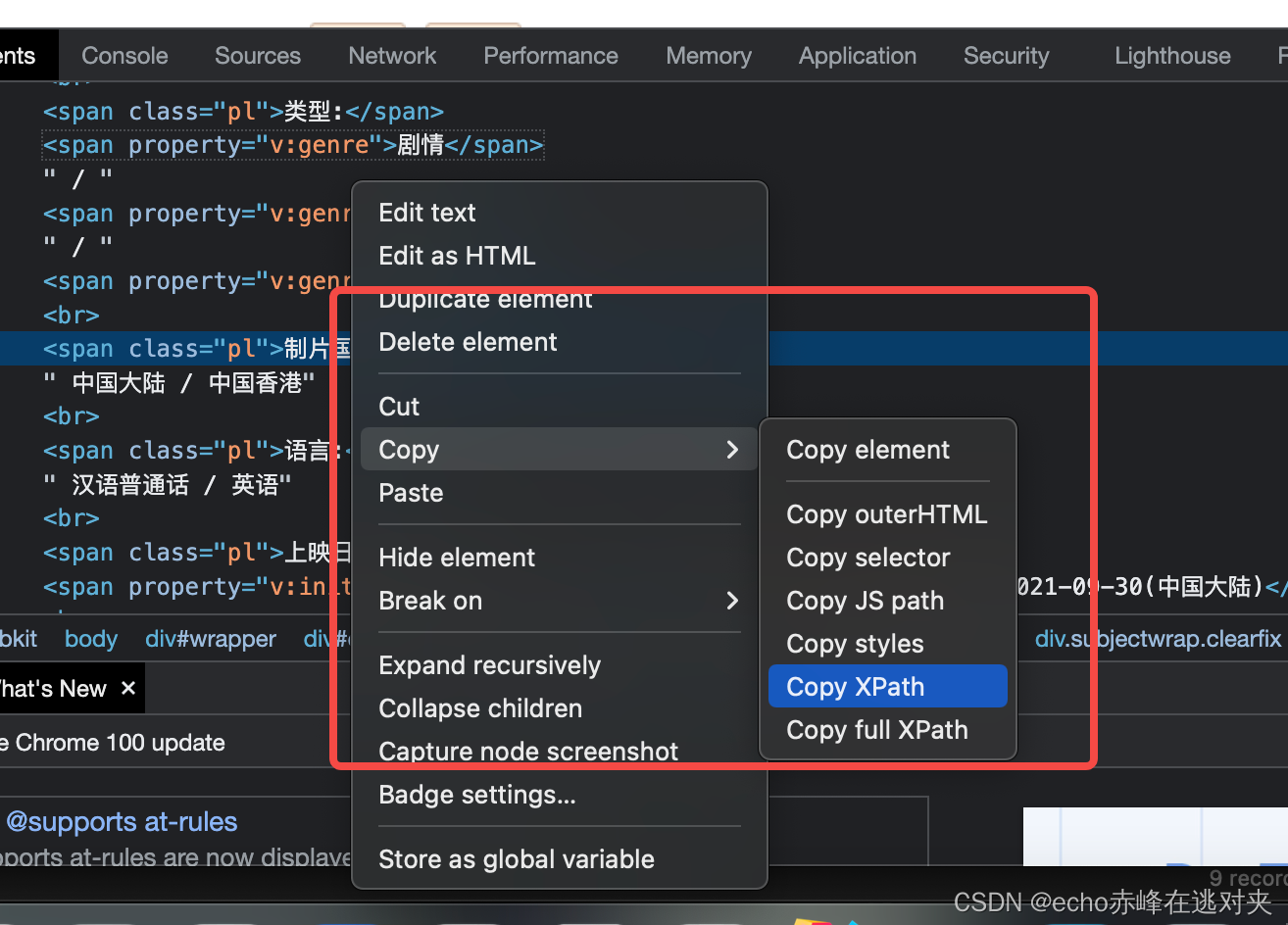
我们通过右键,copyxpath就能获取到这个标签所在的位置,但是我们会发现,我们要的数据并不是在span标签里的数据,而是在span标签后,这应该怎么办呢,
#我们可以通过contains来标记span包含什么信息的span标签,然后通过/following::text()[1]来获取不在标签中的信息
u'//*[@id="info"]/span[contains(./text(), "制片国家/地区:")]/following::text()[1]'
这样我们就能获取到了页面标签中的信息,下面就是如何存储的问题,详细看如下的完整代码吧,我保存的是csv格式的数据,非常简单直接定义好了就能存储。
完整代码如下:
import requests
from lxml import html
import json
import time
import random
import csv
import re
class Douban:
def __init__(self):
self.URL = 'https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=%E7%94%B5%E5%BD%B1'
self.start_num = []
self.movie_url = []
for start_num in range(0, 20, 20):
self.start_num.append(start_num)
self.header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'}
def get_top250(self):
for start in self.start_num:
start = str(start)
response = requests.get(self.URL, params={'start':start}, headers=self.header)
page_content = response.content.decode()
json_data = json.loads(page_content)
movieList = []
for key in range(len(json_data['data'])):
movieDict = {}
movie_url = json_data['data'][key]['url']
rex = re.compile(r'subject/(\d+)')
mo = rex.search(movie_url)
movie_id = mo.group(1)
page_response = requests.get(movie_url, headers=self.header)
page_result = page_response.content.decode()
page_html = html.etree.HTML(page_result)
movie_name = page_html.xpath('//*[@id="content"]/h1/span[1]/text()')
director = page_html.xpath('//*[@id="info"]/span[1]/span[2]/a/text()')
yanyuan = page_html.xpath('//*[@id="info"]/span[3]/span[2]')
for yanyuanList in yanyuan:
yanyuanData = yanyuanList.xpath('././a/text()')
juqing = page_html.xpath('//*[@id="info"]/span[@property="v:genre"]/text()')
country = page_html.xpath(u'//*[@id="info"]/span[contains(./text(), "制片国家/地区:")]/following::text()[1]')
language = page_html.xpath('//*[@id="info"]/span[contains(./text(), "语言:")]/following::text()[1]')
push_time = page_html.xpath('//*[@id="info"]/span[11]/text()')
movie_long = page_html.xpath('//*[@id="info"]/span[13]/text()')
pingfen = page_html.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()')
conver_img = page_html.xpath('//*[@id="mainpic"]/a/img/@src')
describe = page_html.xpath('normalize-space(//*[@id="link-report"]/span/text())')
movieDict['movie_id'] = movie_id
movieDict['movie_name'] = movie_name
movieDict['director'] = director
movieDict['yanyuanData'] = yanyuanData
movieDict['juqing'] = juqing
movieDict['country'] = country
movieDict['language'] = language
movieDict['push_time'] = push_time
movieDict['movie_long'] = movie_long
movieDict['pingfen'] = pingfen
movieDict['conver_img'] = conver_img
movieDict['describe'] = describe
movieList.append(movieDict)
print("正在执行中---", movie_url)
self.random_sleep(1, 0.4)
return movieList
def random_sleep(self, mu, sigma):
'''正态分布随机睡眠
:param mu: 平均值
:param sigma: 标准差,决定波动范围
'''
secs = random.normalvariate(mu, sigma)
if secs <= 0:
secs = mu
print("休眠中。。。")
time.sleep(secs)
def writeData(self, movieList):
with open('douban.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, fieldnames=['movie_id', 'movie_name', 'director', 'yanyuanData', 'juqing',
'country', 'language', 'push_time', 'movie_long', 'pingfen',
'conver_img', 'describe'])
writer.writeheader()
for each in movieList:
writer.writerow(each)
if __name__ == '__main__':
movieList = []
cls = Douban()
movieList = cls.get_top250()
cls.writeData(movieList)
···········
第一次写博客,可能写的不够好,如果文章有不懂的地方或者有疑问的地方可以留言或者加我qq:19686862360,我们一起学习进步
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)