公司某个系统的微信端计划将开放给几百上千的人员登录查询,并且登录账号为同一账号多人使用。
后台服务能够支撑起多用户的并发操作以及成百上千人登录微信端对生产数据库或者登录查询的性能效率高成为交付可靠生产环境的必要条件。
因此,项目组决定提交测试,由测试人员通过自动化方式模拟并发场景,以验证程序的可靠性。
问题点描述
测试初期,随着时间的推移,Loadrunner客户端不断出现事务通过率下降的情况,或因为连接不上服务端,或因为连接超时:
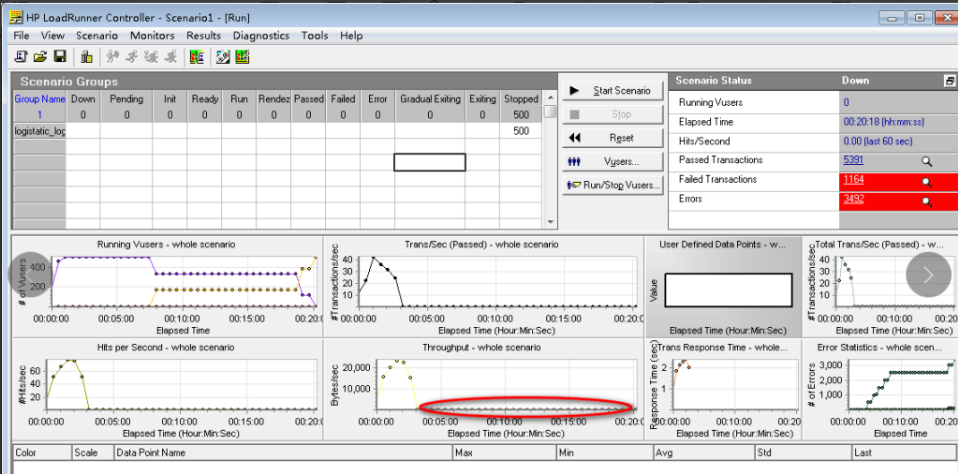
现象1:大用户并发一段时间后服务器吞吐率降到0,而后所有请求出现无法连接到服务器。
现象2:
根据目标1000个并发请求进行结果验证,吞吐量在运行一段时间后,有下降趋势,最后服务端支撑不起:若干请求 failed to connected to server ,若干请求connect timed out。
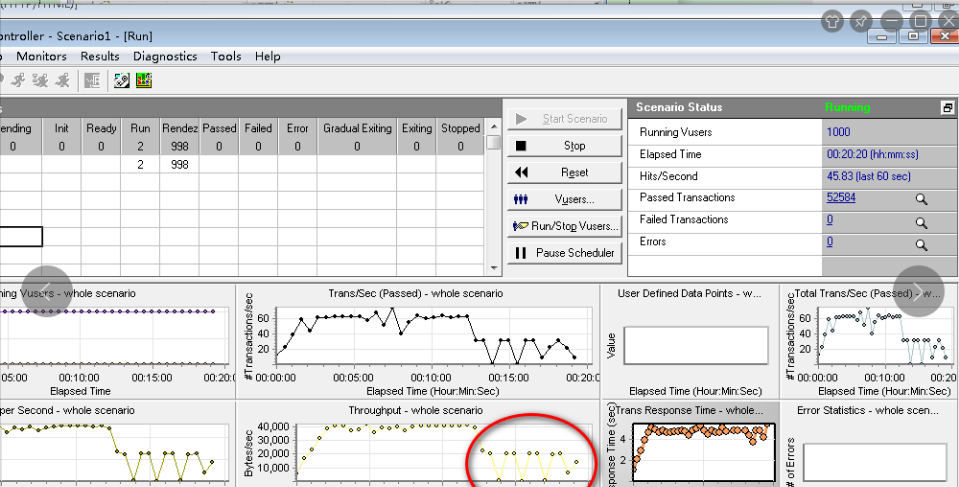

这些现象都直接说明了系统服务端暂无法支撑起大并发用户的访问。
思路和方法
我们需要进一步移位到服务端(Linux-tomcat服务器),通过性能分析手段来分析问题,并根据定位出的具体问题,来展开调优手段解决问题,主要的分析工具有:
1. Linux-top命令
一个用户程序的执行离不开管理它的操作系统,top命令是Linux操作系统下实时查看服务器资源情况的其中一种命令,它可以输出操作系统资源概况信息和进程信息。
2. Jstack工具
Jstack,这是一个在JDK5开始提供的内置工具,可以打印指定进程中线程运行的状态,包括线程数量、是否存在死锁、资源竞争情况和线程的状态等等。
以及,如netstat -anp|grep 端口号|wc -l 查询http连接数、查询数据库连接数,Ps -LF pid 查询线程情况,ps -eLo pid,stat|grep 20017|grep Sl|wc -l查询线程S1状态个数等等其他Linux命令了解当前当前服务器运行情况。
调优方案
01 现象1的性能分析过程及对应的调优手段
(一)分析过程:
使用top命令查询服务器资源结果:
CPU占用资源过大,内存、磁盘资源正常
根据top 1 占用cpu资源的排行,定位到占用资源率高的进程id(pid),进行进一步分析:
Tomcat对应的java进程程占用CPU资源率最高,记录下java进程号

top -hp 进程号 ,打印线程信息,记录下占用CPU资源异常的线程号(tid)
查看线程情况:其中某线程cpu占用率高,使用 printf "%x \n"<tid> 命令将异常线程id转成十六进制的值(thread-hex-id)
通过jstack工具输出当前的线程信息:jstack -l <pid> | grep <thread-hex-id> -A 10
thread dump文件显示出程序在执行org.apache.commons.collections.ReferenceMap..getEntry()方法时处于获取到锁资源的可运行状态;heap dump 中JVM堆中对象使用的情况正常。
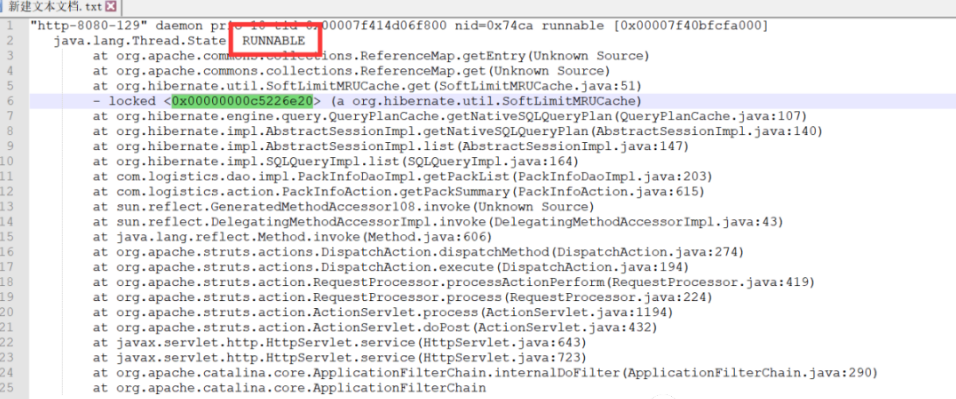
过5分钟后,再次通过通过jstack工具输出当前的线程信息:jstack -l <pid> | grep <thread-hex-id> -A 10
thread dump文件显示出程序在执行org.apache.commons.collections.ReferenceMap..getEntry()方法时处于获取锁资源的可运行状态;heap dump 中JVM堆中对象使用的情况正常。
对比前后两次的线程信息,进行分析:
两个线程在长达5分钟时间里,一直在执行org.apache.commons.collections.ReferenceMap.getEntry()方法,未能释放锁,进入了死循环。而其他多线程处于等待锁资源的状态,造成了blocked阻塞。
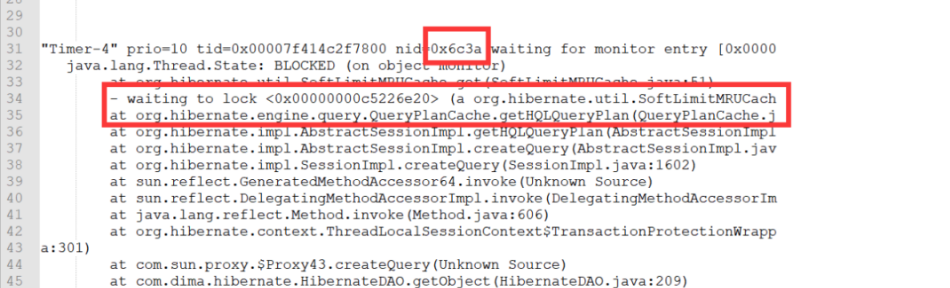
(二)对应的调优手段:
百度查询wait to lock
(org.hibernate.util.SoftLimitMRUCache)出此类似的问题为hibernate3.1,x的bug造成了线程不安全:hashMap等线程不安全的容器,用在多线程读/写的场合,导致hashmap的方法调用造成死循环,解决方法是更换hibernate版本。
02 现象2的性能分析过程及对应的调优手段
(一)分析过程:
当前配置下,逐渐增加服务器负载,根据tps 查找最佳线程数。
500用户并发时,tps出现拐点

使用500个用户并发运行一段时间
服务器吞吐率逐渐下载,而后开始产生一些连接超时的问题,最后出现connect timeout
分析tomcat配置:连接数、线程数以及队列长度
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="2000000" redirectPort="8443" minSpareThreads="100" maxSpareThreads="500" acceptCount="1000" />
从以上信息了解到服务端采用的是tomcat BIO模式,配置中未指定最大线程数,则默认为200;未指定连接数,则Bio下 connect max connections=max thread=200;
tomcat一开始可处理
acceptCount+maxConnections的请求,已进入acceptcount但无法处理的先出现connect timeout,最后无法进入acceptcount的出现connect refuse。
(二)对应的调优手段:
根据目标支撑数,调整tomcat配置:线程数和队列长度。
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="2000000" redirectPort="8443" maxThreads="1000" acceptCount="1000" />
修改后,500个用户并发运行30min,服务器吞吐率保持稳定

继续进行100-200-300 到1000个用户并发场景,结合Loadrunner和服务端资源验证结果
原先运行10min就开始报错,现在并发运行48min期间吞吐量稳定(48min后出错是现象1的问题);服务端内存占用率稳定,tomcat配置修改有效。

总结
Loadrunner工具是以客户的角度分析应用业务是否可用,服务体验是否满意,它不需要知道系统的业务流向和系统的架构设计,但系统瓶颈分析和调优时却需要这些知识。
面对日益复杂的系统负载,系统的性能也受许多因素的影响,如处理器速度、内存容量、网络、I/O、磁盘容量、中间件连接池配置等等。
因此,要求我们对计算机硬件、操作系统和应用有相当深入的了解,我们才能合理动用脑袋中的知识库以分析和解决问题。
在分析系统瓶颈和调优问题上,本人也没有搭建起完整的知识体系框架来,在此只能分享我浅薄的几点经验:
1.了解被测项目的架构:如是否用了缓存,用了集群、负载均衡,用了哪些应用以及对应配置、特性,如redis是内存数据库,特性是占用内存会大;对磁盘资源依赖少。如常见的关系型数据库对CPU、内存、磁盘都有比较高的要求;web应用如果对文件进行操作,那可先分析磁盘I/O、内存。
2. 运用抓包、日志等工具分段定位瓶颈位置:前端页面、后台服务端还是数据库。
3. 对于测试对象是web应用类型的,经常出问题的是它中间件的配置、程序代码和其依赖的服务器资源,一般出错时有后台服务端日志可以参考。
4. 对于web应用,要了解tcp工作原理,java应用了解进程、线程状态及工作情况。
5. 优先排查应用程序问题,一般应用程序和资源表现有关系,应用服务端关注:连接模式及配置、jvm内存:泄露、溢出、应用程序逻辑。
6. 操作系统关注:包含了操作系统的系统参数、内核参数、进程参数、文件系统、磁盘IO等
7. 数据库关注:连接池、sql语句、索引、死锁
系统分析的主要目标是识别出哪些工作负荷是影响当前吞吐量的瓶颈;总体来说有很多有用的信息分析工具可以用,且分析方法并不是唯一,本次实践在物流查询系统中出现的问题也只是性能问题里的冰山一角。
通过性能分析和对应的调优手段,我们提升了系统的响应能力,为用户带来更好的使用体验。在其他场景,我们通过架构、应用逻辑上的优化,还可以不需要对硬件系统进行扩容,用更少的硬件资源,支撑更大量的业务发展,从而达到节省硬件投资的目的,性能调优带来收益是巨大的。
在性能分析手段上,本人也还在努力学习,分享以上测试经验希望大家少走弯路,希望能够帮助初学者解决一些问题,共同进步。
总结:
感谢每一个认真阅读我文章的人!!!
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助

