文章目录
- Abstract
- Introduction
-
- Faster R-CNN
- 整体流程
- Conv layers
- RPN
- cls
- reg
- anchor
- Translation-Invariant Anchors
- Muti-Scale Anchors as Regression References
-
- Loss Function
- 训练
- 特征
目标检测的四个基本步骤:
- 候选区域生成;
- 特征提取;
- 分类
- 位置精修
Fast R-CNN = Selective Search + Fast R-CNN
Faster R-CNN = RPN + Fast R-CNN

将四个基本步骤统一到一个深度网络框架之中,所以计算没有重复,完全在GPU中完成,大大提升运行速度。
Abstract
目前,目标检测网络普遍采用region proposal算法来假定对象的位置。
SPPnet和Fast R-CNN也正是在region proposal上受到局限。
因此,该论文提出了一种新的region proposal算法——RPN。
RPN是一个卷积网络,可以同时预测每个位置的对象边界与分数。
Introduction
目标检测模型的组成部分:region proposal methods(候选框生成方法) & R-CNNs(对象检测网络)。
缘由
目前采用的SS算法对比检测网络,运行时间慢了一个数量级,大概是后面所有时间的十倍以上。
这样的时间计算是基于CNN采用GPU,SS采用CPU,是不公平的。但是倘若用GPU实现SS算法,会忽略对象检测网络,错过了共享计算的机会。因此,采用了RPN。
RPN——与最先进的对象检测网络贡献卷积层的区域提议网络。
RPN
对象检测网络(Fast R-CNN)使用的卷积特征图也可以用于生成候选框。在这些特征之上,通过添加一些额外的卷积层就可以构建RPN。这些额外的卷积层对规则网格进行回归位置边界与回归目标性评分(即判断这块位置是目标的可能性有多大)。
类似于RNN中的attention的作用,把区域缩得比较小,不是单纯地选取2000个比较相似的区域。
RPN的目的是为了预测具有各种比例和横纵比的区域。
被认为是a pyramid of regression references。
有效避免了枚举多个尺度或横纵比的图像或过滤器。
训练方案
如何共享参数?
4-Step Alternating Training
该方案在region proposal任务与object detection任务之间交替。
Faster CNN的训练,是在已经训练好的model(VGG_CNN_M_1024,VGG,ZF)上进行训练的,具体分为六个步骤:
- 在已经训练好的model上训练RPN网络;
- 利用训练好的RPN网络,收集proposals;
- 第一次训练Fast RCNN网络;(截止目前为止,参数尚未共享)
- 第二次训练RPN网络;(此时,我们固定共享的卷积层,只对部分层微调,下一步同理)
- 收集proposals;
- 第二次训练Fast RCNN网络。
类似于一种迭代的过程,仅训练两次,这是基于实验所得的。
结合训练,减少训练时间。
Faster R-CNN
由两个模块组成:
- a deep fully convolutional network that proposes regions;
- Faster R-CNN detector that uses the proposed regions.

整体流程

- Conv layers。作为一种CNN网络目标检测方法,首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享于后续的RPN层和全连接层;
- RPN。RPN网络用于生成region proposals。该层通过softmax判断anchors属于foreground或者background,再利用bounding box regression修正anchors,从而获得精确的proposals;
- Roi Pooling。该层收集输入的feature maps 和 proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别;
- Classification。利用proposal feature maps 计算proposal的类别,同时在此bounding box regression获得检测框最终的精确位置。
Conv layers
采用的是VGG网络。
包含13个conv层+13个relu层+4个pooling层;
conv层:kernel_size = 4 ,pad = 1
pooling层:kernel_size = 2 ,stride = 1
则一个M x N大小的矩阵经过处理后,变为了
M
16
∗
N
16
\frac{M}{16}*\frac{N}{16}
16M∗16N大小的矩阵。
RPN
RPN网络中的卷积层是与FRCNN共享的,为了提出候选区域,在最后的共享卷积层输出的卷积特征图上滑动一个小网格,
- 向窗口输入特征图的
n
∗
n
n*n
n∗n大小的空间窗口(论文中,
n
=
3
n=3
n=3);
- 映射到低位特征;
- 输入到两个兄弟全连接层(回归层reg与分类层cls)
从整体来看,该部分已经对其做了一个初步的预测与定位。
具体流程如下图所示,上方为cls,下方为reg。

cls
通过softmax分类anchors获得foreground(object)和background(not object),其中foreground是我们的检测目标。
reg
计算该anchor对应的bounding box的偏移量,获得proposal。
最后Proposal层综合了foreground anchors 和bounding box regression偏移量获取proposals。
同时,剔除了太小和超出边界的proposals。
到此处,就已经基本完成目标定位的功能。
anchor

anchor是滑动窗口的中心。
anchor box本质上是一系列生成的矩形。
在每一个滑动窗口的位置上有k个候选anchor boxes。
2k是因为在cls层,这k个anchors都有两个类别的概率输出;
4k是因为在reg层,这k个anchors输出一个四元组。
在该论文中,锚框包含3个比例与3个横纵比,因此k=9。
对于一个大小为
W
∗
H
W*H
W∗H的卷积特征图,共有
W
∗
H
∗
k
W*H*k
W∗H∗k个锚框。
Translation-Invariant Anchors
该方法的重要特性是平移不变性。

Muti-Scale Anchors as Regression References
多尺度预测
法一:
1)图像金字塔:
- 将图像进行不同尺度的缩放,得到图像金字塔;
- 对每层图片提取不同的尺寸特征,得到特征图;
- 对每个尺度的特征进行单独预测。
2)特征金字塔:
先提特征,后缩放。
特点:不同尺度的特征可以包含很丰富的语义信息,精度高,速度慢。
法二:
在特征图上使用多个尺度的滑动窗口。
RPN的方法:
基于锚点的多尺度设计。
构建anchors金字塔;参考多个尺度的anchor box对边界框进行分类和回归。
特点:只依赖单一尺度的图像和特征图;使用单一尺度的过滤器(滑动窗口)。
Loss Function
我们为两种锚框分配正标签:
- 具有最高IoU;
-
I
o
U
>
0.7
IoU \gt 0.7
IoU>0.7
也就是说一个样本会有多个正标签;如果舍弃第一种情况的话,可能会出现无正标签的情况,从而导致非正非负标签的出现,这是对训练目标没有贡献的。
基于以上考量,得到如下损失函数:
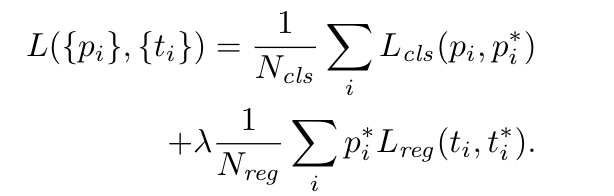
训练
可以进行端到端的学习方式。
传统的图像识别问题将母问题分解为若干简单的子问题,并分步解决。
尽管在子问题上可以得到最优解,但是不意味着全局问题的最优解。
端到端的学习对母问题统一进行处理,将一系列操作看作一个整体的函数,通过最终的损失函数进行最优化。总的来说,端到端的学习不做额外的处理,从原始数据输入到最后任务结果输出,整个训练和预测过程都是在模型里完成的。
关于训练,采用的是固定一方、训练另一方的方式,在训练方案部分已经详细介绍。
特征
- 取代了SS算法;
- 共享卷积层;
- 引入计算量小,耗时少;
- 可以端到端训练;
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)