目录
一、Logstash 架构介绍
1.1 为什么需要 Logstash
1.2 什么是 Logstash
1.3 Logstash 架构介绍
1.4 安装 Logstash
二、Logstash Input 插件
2.1 stdin 插件
2.2 file 插件
三、Logstash Filter 插件
3.1 Grok 插件
3.1.1 grok 如何出现的?
3.1.2 grok 解决什么问题
3.1.3 grok 语法示意图
3.1.4 grok 语法示例
3.2 geoip 插件
3.2.1 geoip 示例
3.2.3 fields 字段
3.3 Date 插件
3.3.1 date 示例
3.4 useragent 插件
3.4.1 useragent 示例
3.5 mutate 插件
3.5.1 remove field
3.5.2 split
3.5.3 add field
3.5.4 convert
一、Logstash 架构介绍
1.1 为什么需要 Logstash
对于部分生产上的日志无法像 Nginx 那样,可以直接将输出的日志转为 json 格式,但是可以借助 Logstash 来将我们的“非结构化数据”,转为“结构化数据”。
1.2 什么是 Logstash
Logstash 是开源的数据处理管道,能够同时从多个源采集数据,转换数据,然后输出数据。
Logstash 官网传送门:Logstash:收集、解析和转换日志 | Elastic
1.3 Logstash 架构介绍
Logstash 的基础架构类似于 pipeline 流水线,如下所示:
-
Input:数据采集 (常用插件:stdin、file、kafka、beat、http)
-
Filter:数据解析/转换 (常用插件:grok、date、geoip、mutate、 useragent)
-
output: 数据输出 (常用插件:Elasticsearch 等)
1.4 安装 Logstash
Logstash 7.8.1 下载地址:Logstash 7.8.1 | Elastic

注意:需要提前安装 java 环境:Linux 部署 JDK+MySQL+Tomcat 详细过程_移植mysql+tomcat_Stars.Sky的博客-CSDN博客
[root@es-node1 ~]# rpm -ivh logstash-7.8.1.rpm
[root@es-node1 ~]# vim /etc/logstash/logstash.yml
node.name: logstash-node1 # 指定了当前 Logstash 节点的名称为 logstash-node1
path.data: /var/lib/logstash # 指定了Logstash 数据存储的路径为 /var/lib/logstash
pipeline.workers: 2 # 指定了 Logstash 使用的工作线程数量为 2
pipeline.batch.size: 1000 # 指定了每个批次处理的事件数量为 1000
pipeline.ordered: auto # 指定了事件的处理顺序。auto 表示 Logstash 自动选择顺序,一般情况下不需要手动设置。
path.logs: /var/log/logstash # 指定了 Logstash 日志存储的路径为 /var/log/logstash
[root@es-node1 ~]# ln -s /usr/share/logstash/bin/logstash /usr/local/bin/logstash
二、Logstash Input 插件
input 插件用于指定输入源,一个 pipeline 可以有多个 input 插件,我们主要围绕下面几个 input 插件进行介绍:
-
stdin
-
file
-
beat
-
kafka
-
http
2.1 stdin 插件
从标准输入读取数据,从标准输出中输出内容:
[root@es-node1 ~]# vim /etc/logstash/conf.d/test1.conf
input {
stdin {
type => "stdin" # 自定义事件类型,可用于后续判断
tags => "stdin_type" # 自定义事件 tag,可用于后续判断
}
}
output {
stdout {
codec => "rubydebug"
}
}
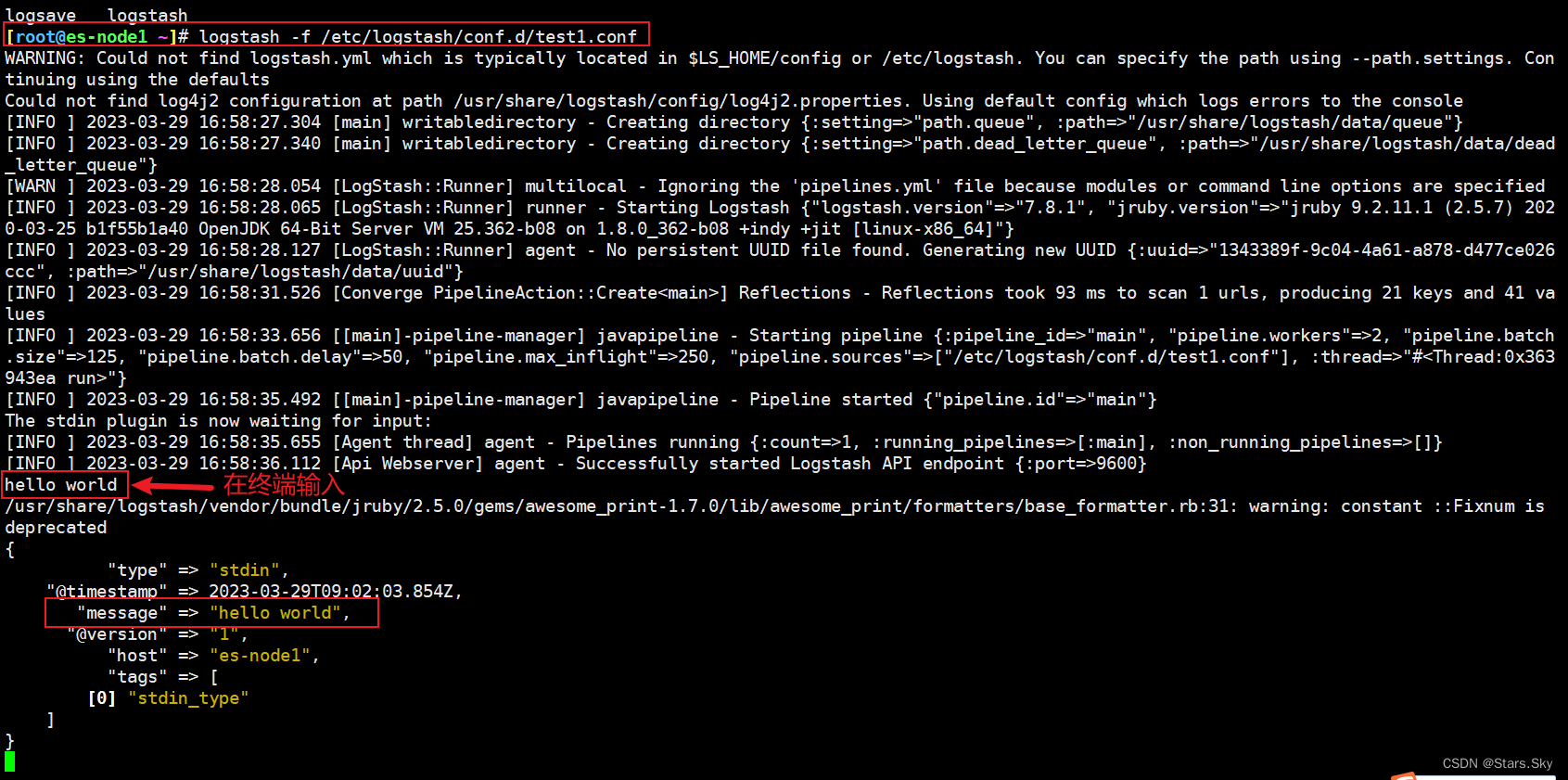
执行测试:
[root@es-node1 ~]# logstash -f /etc/logstash/conf.d/test1.conf
hello world
2.2 file 插件
从 file 文件中读取数据,然后输入至标准输入:
[root@es-node1 ~]# vim /etc/logstash/conf.d/test2.conf
input {
file {
path => "/var/log/test2.log"
type => syslog
exclude => "*.gz"
start_position => "beginning"
stat_interval => "3"
}
}
output {
stdout {
codec => "rubydebug"
}
}
[root@es-node1 ~]# echo 123 >> /var/log/test2.log
具体地说,这个配置文件的含义如下:
- 输入配置(input):使用 file 插件读取指定路径的文件 /var/log/test2.log,设置输入数据的类型为 syslog,并指定不读取以 .gz 结尾的文件。start_position 参数指定从文件的开头开始读取数据,而 stat_interval 参数则指定每 3 秒重新扫描文件以读取新的数据。
- 输出配置(output):使用 stdout 插件将处理后的数据输出到标准输出,使用 codec 参数指定使用 Ruby 格式进行输出调试信息。
该配置文件的作用是将指定路径下的文件数据以 syslog 格式读取,然后输出到标准输出并格式化为 Ruby 调试信息,方便用户查看和分析处理结果。
# 执行测试
[root@es-node1 ~]# logstash -f /etc/logstash/conf.d/test2.conf
# 再另一个终端写入数据
[root@es-node1 ~]# echo 567 >> /var/log/test2.log

三、Logstash Filter 插件
数据从源传输到存储的过程中,Logstash 的 filter 过滤器能够解析各个事件,识别已命名的字段结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。

3.1 Grok 插件
3.1.1 grok 如何出现的?
我们希望将如下 nginx 日志非结构化的数据解析成 json 结构化数据格式:
120.27.74.166 - - [30/Dec/2022:11:59:18 +0800] "GET / HTTP/1.1" 302 154 "_" "Mozi1a/5.0 (Macintosh; Inte Mac os X 10_14_1) chrome/79.0.3945.88 Safari/537.36"
需要使用非常复杂的正则表达式
\[([^]]+)]\s\[(\w+)]\s([^:]+:\s\w+\s\w+\s[^:]+:\S+\s[^:]+:
\S+\s\s+).*\[([^]]+)]\S\[(\w+)]\s([^:]+:\s\w+\s\w+\s[^:]+:
\S+\s[^:]+:\s+\s\s+).*\[([^]]+)]\S\[(\w+)]\s([^:]+:\s\w+
\s\w+\s[:]+: S+ s[^:]+: S+ s S+).*
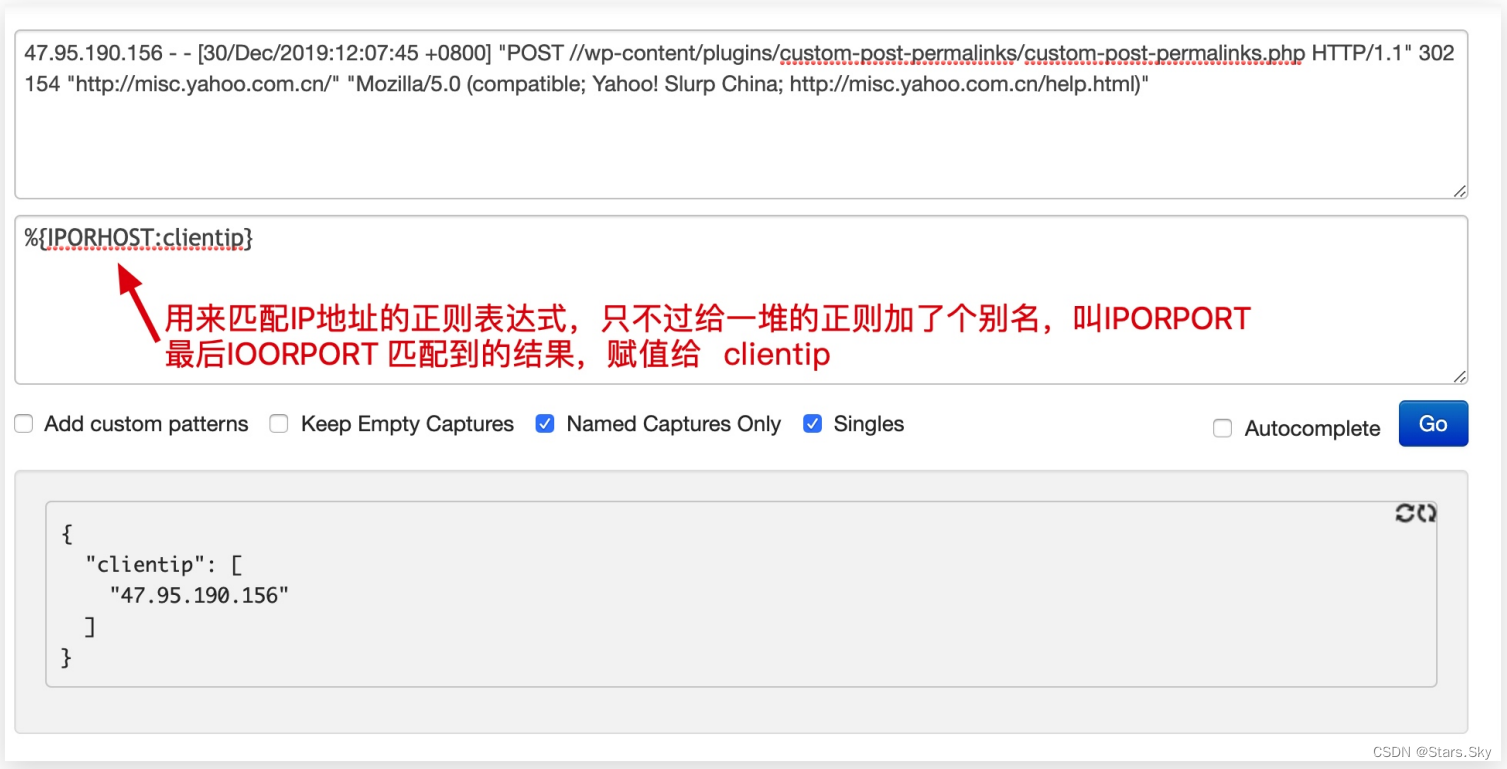
3.1.2 grok 解决什么问题
grok 其实是带有名字的正则表达式集合。grok 内置了很多 pattern 可以直接使用:
grok 在线语法生成器:Grok Debugger
3.1.3 grok 语法示意图
 3.1.4 grok 语法示例
3.1.4 grok 语法示例
使用 grok pattern 将 Nginx 日志格式化为 json 格式:
input {
file {
path => "/var/log/test2.log"
type => syslog
exclude => "*.gz"
start_position => "beginning"
stat_interval => "3"
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
}
}
output {
stdout {
codec => "rubydebug"
}
}
[root@es-node1 ~]# logstash -f /etc/logstash/conf.d/test3.conf -r
在另一个终端执行:
[root@es-node1 ~]# vim /var/log/test2.log
120.27.74.166 - - [30/Dec/2022:11:59:18 +0800] "GET / HTTP/1.1" 302 154 "_" "Mozi1a/5.0 (Macintosh; Inte Mac os X 10_14_1) chrome/79.0.3945.88 Safari/537.36"

3.2 geoip 插件
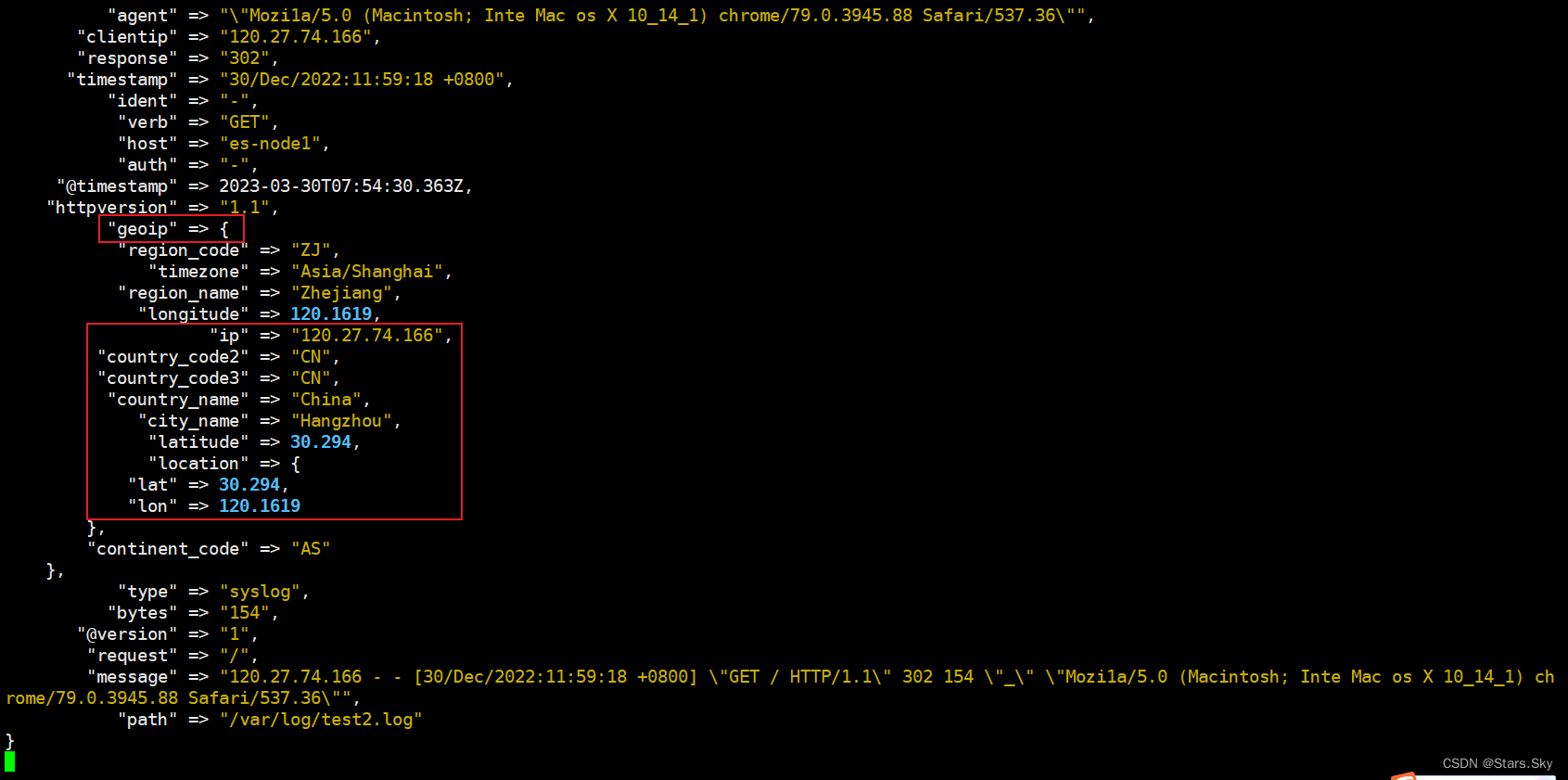
根据 ip 地址提供的对应地域信息,比如经纬度、城市名等、方便进行地理数据分析.
3.2.1 geoip 示例
通过 geoip 提取 Nginx 日志中 clientip 字段,并获取地域信息:
input {
file {
path => "/var/log/test2.log"
type => syslog
exclude => "*.gz"
start_position => "beginning"
stat_interval => "3"
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
}
geoip {
source => "clientip"
}
}
output {
stdout {
codec => "rubydebug"
}
}
测试结果:
3.2.3 fields 字段
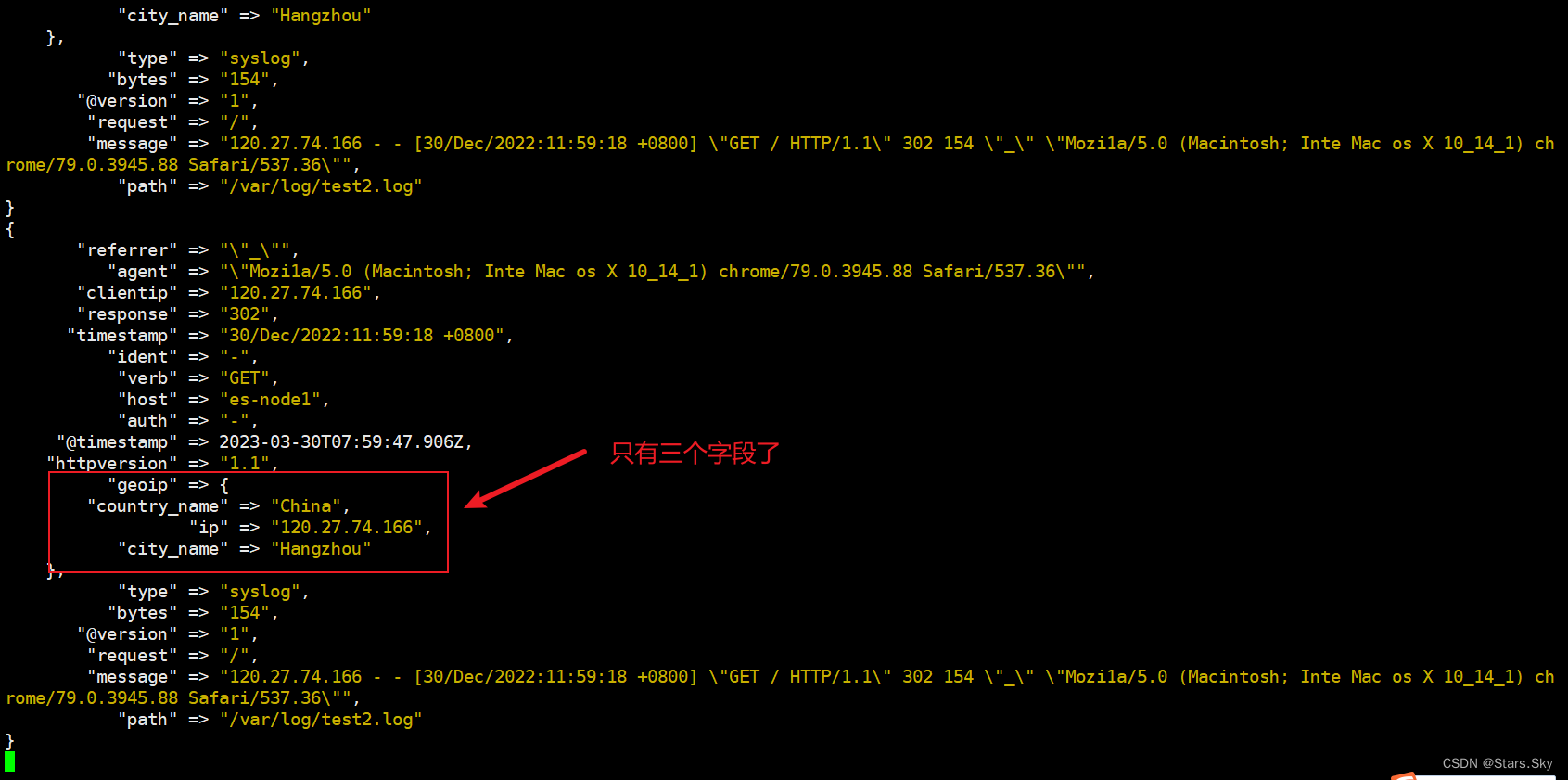
由于输出内容太多,可以通过 fileds 选项选择自己需要的信息:
input {
file {
path => "/var/log/test2.log"
type => syslog
exclude => "*.gz"
start_position => "beginning"
stat_interval => "3"
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
}
geoip {
source => "clientip"
fields => ["ip", "country_name", "city_name"] # 仅提取需要的字段信息
}
}
output {
stdout {
codec => "rubydebug"
}
}
测试结果:
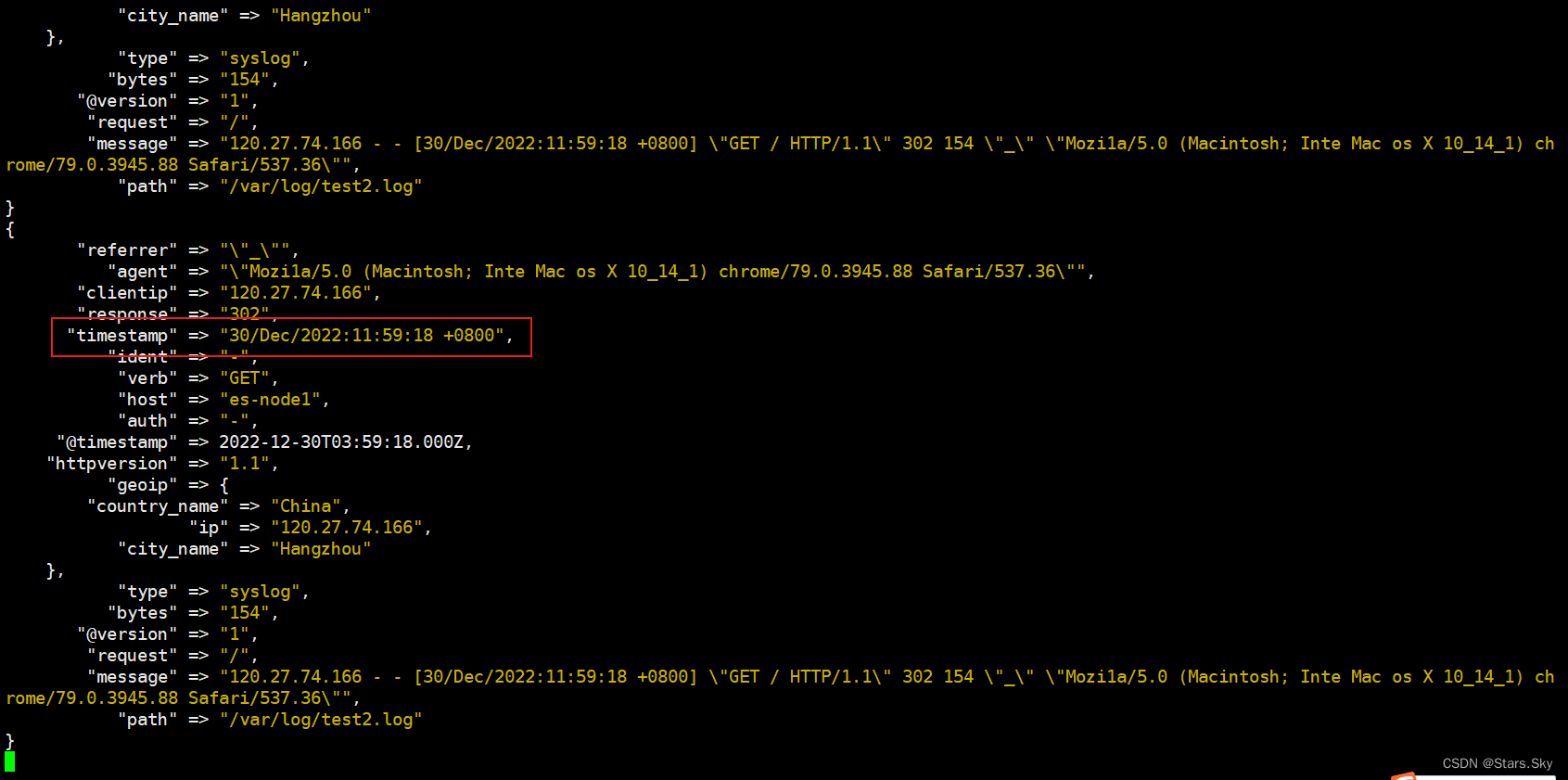
3.3 Date 插件
将日期字符串解析为日志类型,然后替换 @timestamp 字段或指定的其他字段。
官方文档:Date filter plugin | Logstash Reference [8.6] | Elastic
3.3.1 date 示例
将 nginx 请求中的 timestamp 日志进行解析:
input {
file {
path => "/var/log/test2.log"
type => syslog
exclude => "*.gz"
start_position => "beginning"
stat_interval => "3"
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
}
# geoip 插件,用来分析请求客户端来源归属地
geoip {
source => "clientip"
fields => ["ip", "country_name", "city_name"]
}
# date 处理时间,将timestamp 请求的时间覆盖写入时间 30/Dec/2022:11:59:18 +0800
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
}
output {
stdout {
codec => "rubydebug"
}
}
3.4 useragent 插件
根据请求中的 user-agent 字段解析出浏览器设备、操作系统等信息:
3.4.1 useragent 示例
input {
file {
path => "/var/log/test2.log"
type => syslog
exclude => "*.gz"
start_position => "beginning"
stat_interval => "3"
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
}
# geoip 插件,用来分析请求客户端来源归属地
geoip {
source => "clientip"
fields => ["ip", "country_name", "city_name"]
}
# date 处理时间,将timestamp 请求的时间覆盖写入时间 30/Dec/2022:11:59:18 +0800
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
# useragent 字段,用来解析用户请求社保、操作系统版本等信息
useragent {
source => "agent"
target => "agent"
}
}
output {
stdout {
codec => "rubydebug"
}
}

3.5 mutate 插件
mutate 主要是对字段进行、类型转换、删除、替换、更新等操作:
-
remove_field 删除字段
-
split 字符串切割(awk 取列)
-
add_field 添加字段
-
convert 类型转换
-
gsub 字符串替换
-
rename 字段重命名
3.5.1 remove field
mutate 删除无用字段,比如: headers、message、agent
input {
file {
path => "/var/log/test2.log"
type => syslog
exclude => "*.gz"
start_position => "beginning"
stat_interval => "3"
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}"
}
}
# geoip 插件,用来分析请求客户端来源归属地
geoip {
source => "clientip"
fields => ["ip", "country_name", "city_name"]
}
# date 处理时间,将timestamp 请求的时间覆盖写入时间 30/Dec/2022:11:59:18 +0800
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
# useragent 字段,用来解析用户请求社保、操作系统版本等信息
useragent {
source => "agent"
target => "agent"
}
# mutate 删除字段
mutate {
remove_field => ["message", "headers"]
}
}
output {
stdout {
codec => "rubydebug"
}
}
结果返回,整个数据返回的结果清爽了很多。
3.5.2 split
mutate 中的 split 字符切割,指定“|”为字段分隔符。
测试数据:5607|提交订单|2023-12-28 03:18:31
[root@es-node1 ~]# vim /etc/logstash/conf.d/test4.conf
input {
file {
path => "/var/log/test4.log"
type => syslog
exclude => "*.gz"
start_position => "beginning"
stat_interval => "3"
}
}
filter {
mutate {
split => { "message" => "|" }
}
}
output {
stdout {
codec => "rubydebug"
}
}
[root@es-node1 ~]# vim /var/log/test4.log
5607|提交订单|2023-12-28 03:18:31
[root@es-node1 ~]# logstash -f /etc/logstash/conf.d/test4.conf -r

3.5.3 add field
mutate 中 add_field,可以将分割后的数据创建出新的字段名称。便于以后的统计和分析:
[root@es-node1 ~]# vim /etc/logstash/conf.d/test4.conf
input {
file {
path => "/var/log/test4.log"
type => syslog
exclude => "*.gz"
start_position => "beginning"
stat_interval => "3"
}
}
filter {
mutate {
split => { "message" => "|" }
add_field => {
"UserID" => "%{[message][0]}"
"Action" => "%{[message][1]}"
"Date" => "%{[message][2]}"
}
remove_field => ["message", "headers"]
}
}
output {
stdout {
codec => "rubydebug"
}
}

3.5.4 convert
mutate 中的 convert 类型转换。支持转换 integer、float、string 等类型:
input {
file {
path => "/var/log/test4.log"
type => syslog
exclude => "*.gz"
start_position => "beginning"
stat_interval => "3"
}
}
filter {
mutate {
# 字段分隔符
split => { "message" => "|" }
# 将分割后的字段添加到指定的字段名称
add_field => {
"UserID" => "%{[message][0]}"
"Action" => "%{[message][1]}"
"Date" => "%{[message][2]}"
}
# 对新添加的字段进行格式转换
convert => {
"UserID" => "integer"
"Action" => "string"
"Date" => "string"
}
# 移除无用的字段
remove_field => ["message", "headers"]
}
}
output {
stdout {
codec => "rubydebug"
}
}

上一篇文章:【Elastic (ELK) Stack 实战教程】06、Filebeat 日志收集实践(下)_Stars.Sky的博客-CSDN博客下一篇文章:【Elastic (ELK) Stack 实战教程】08、Logstash 分析业务 APP、Nginx、Mysql 日志实践_Stars.Sky的博客-CSDN博客
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)