K-Means是一种聚类(Clustering)算法,使用它可以为数据分类。K代表你要把数据分为几个组,前文实现的K-Nearest Neighbor算法也有一个K,实际上,它们有一个相似之处:K-Means也使用欧拉距离公式。
- K-Means:https://en.wikipedia.org/wiki/K-means_clustering
- scikit-learn中的聚类算法:http://scikit-learn.org/stable/modules/clustering.html
- scikit-learn K-Means文档:http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
K-Means算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。
为了更好的理解这个K-Means,本帖使用Python实现K-Means算法。
K-Means简单图示(sklearn)
import numpy as np
from sklearn.cluster import KMeans
from matplotlib import pyplot
# 要分类的数据点
x = np.array([ [1,2],[1.5,1.8],[5,8],[8,8],[1,0.6],[9,11] ])
# pyplot.scatter(x[:,0], x[:,1])
# 把上面数据点分为两组(非监督学习)
clf = KMeans(n_clusters=2)
clf.fit(x) # 分组
centers = clf.cluster_centers_ # 两组数据点的中心点
labels = clf.labels_ # 每个数据点所属分组
print(centers)
print(labels)
for i in range(len(labels)):
pyplot.scatter(x[i][0], x[i][1], c=('r' if labels[i] == 0 else 'b'))
pyplot.scatter(centers[:,0],centers[:,1],marker='*', s=100)
# 预测
predict = [[2,1], [6,9]]
label = clf.predict(predict)
for i in range(len(label)):
pyplot.scatter(predict[i][0], predict[i][1], c=('r' if label[i] == 0 else 'b'), marker='x')
pyplot.show()
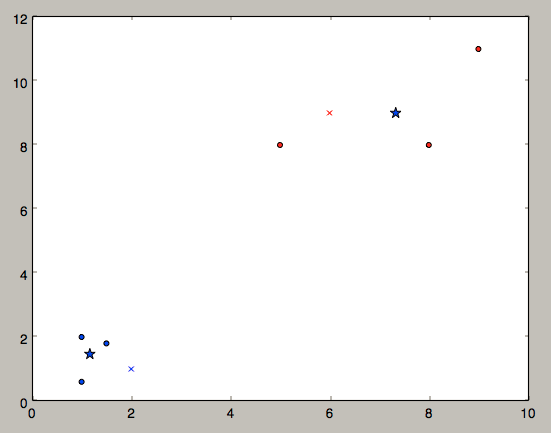
*是两组数据的”中心点”;x是预测点分组。上面使用的是二维数据,方便可视化。
使用Python实现K-Means算法
K-Means聚类算法主要分为三个步骤:
- 第一步是为待聚类的点随机寻找聚类中心
- 第二步是计算每个点到聚类中心的距离,将各个点归类到离该点最近的聚类中去
- 第三步是计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心,反复执行(2)、(3),直到聚类中心不再进行大范围移动或者聚类次数达到要求为止
Python代码:
# -*- coding:utf-8 -*-
import numpy as np
from matplotlib import pyplot
class K_Means(object):
# k是分组数;tolerance‘中心点误差’;max_iter是迭代次数
def __init__(self, k=2, tolerance=0.0001, max_iter=300):
self.k_ = k
self.tolerance_ = tolerance
self.max_iter_ = max_iter
def fit(self, data):
self.centers_ = {}
for i in range(self.k_):
self.centers_[i] = data[i]
for i in range(self.max_iter_):
self.clf_ = {}
for i in range(self.k_):
self.clf_[i] = []
# print("质点:",self.centers_)
for feature in data:
# distances = [np.linalg.norm(feature-self.centers[center]) for center in self.centers]
distances = []
for center in self.centers_:
# 欧拉距离
# np.sqrt(np.sum((features-self.centers_[center])**2))
distances.append(np.linalg.norm(feature - self.centers_[center]))
classification = distances.index(min(distances))
self.clf_[classification].append(feature)
# print("分组情况:",self.clf_)
prev_centers = dict(self.centers_)
for c in self.clf_:
self.centers_[c] = np.average(self.clf_[c], axis=0)
# '中心点'是否在误差范围
optimized = True
for center in self.centers_:
org_centers = prev_centers[center]
cur_centers = self.centers_[center]
if np.sum((cur_centers - org_centers) / org_centers * 100.0) > self.tolerance_:
optimized = False
if optimized:
break
def predict(self, p_data):
distances = [np.linalg.norm(p_data - self.centers_[center]) for center in self.centers_]
index = distances.index(min(distances))
return index
if __name__ == '__main__':
x = np.array([[1, 2], [1.5, 1.8], [5, 8], [8, 8], [1, 0.6], [9, 11]])
k_means = K_Means(k=2)
k_means.fit(x)
print(k_means.centers_)
for center in k_means.centers_:
pyplot.scatter(k_means.centers_[center][0], k_means.centers_[center][1], marker='*', s=150)
for cat in k_means.clf_:
for point in k_means.clf_[cat]:
pyplot.scatter(point[0], point[1], c=('r' if cat == 0 else 'b'))
predict = [[2, 1], [6, 9]]
for feature in predict:
cat = k_means.predict(predict)
pyplot.scatter(feature[0], feature[1], c=('r' if cat == 0 else 'b'), marker='x')
pyplot.show()
执行结果:
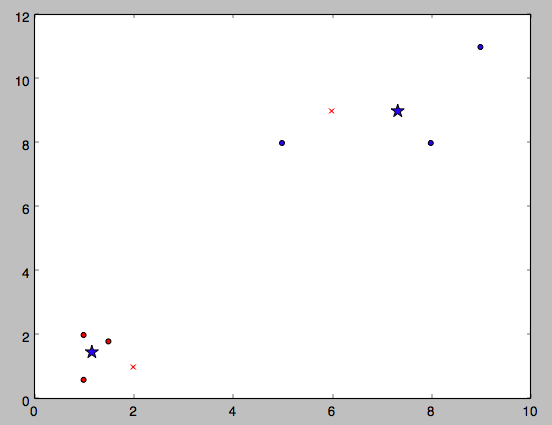
K-Means算法需要你指定K值,也就是需要人为指定数据应该分为几组。下一帖我会实现Mean Shift算法,它也是一种聚类算法(Hierarchical),和K-Means(Flat)不同的是它可以自动判断数据集应该分为几组。
在实际数据上应用K-Means算法
# -*- coding:utf-8 -*-
import numpy as np
from sklearn.cluster import KMeans
from sklearn import preprocessing
import pandas as pd
'''
数据集:titanic.xls(泰坦尼克号遇难者/幸存者名单)
<http://blog.topspeedsnail.com/wp-content/uploads/2016/11/titanic.xls>
***字段***
pclass: 社会阶层(1,精英;2,中产;3,船员/劳苦大众)
survived: 是否幸存
name: 名字
sex: 性别
age: 年龄
sibsp: 哥哥姐姐个数
parch: 父母儿女个数
ticket: 船票号
fare: 船票价钱
cabin: 船舱
embarked
boat
body: 尸体
home.dest
******
目的:使用除survived字段外的数据进行k-means分组(分成两组:生/死),然后和survived字段对比,看看分组效果。
'''
# 加载数据
df = pd.read_excel('titanic.xls')
# print(df.shape) (1309, 14)
# print(df.head())
# print(df.tail())
"""
pclass survived name sex \
0 1 1 Allen, Miss. Elisabeth Walton female
1 1 1 Allison, Master. Hudson Trevor male
2 1 0 Allison, Miss. Helen Loraine female
3 1 0 Allison, Mr. Hudson Joshua Creighton male
4 1 0 Allison, Mrs. Hudson J C (Bessie Waldo Daniels) female
age sibsp parch ticket fare cabin embarked boat body \
0 29.0000 0 0 24160 211.3375 B5 S 2 NaN
1 0.9167 1 2 113781 151.5500 C22 C26 S 11 NaN
2 2.0000 1 2 113781 151.5500 C22 C26 S NaN NaN
3 30.0000 1 2 113781 151.5500 C22 C26 S NaN 135.0
4 25.0000 1 2 113781 151.5500 C22 C26 S NaN NaN
home.dest
0 St Louis, MO
1 Montreal, PQ / Chesterville, ON
2 Montreal, PQ / Chesterville, ON
3 Montreal, PQ / Chesterville, ON
4 Montreal, PQ / Chesterville, ON
"""
# 去掉无用字段
df.drop(['body', 'name', 'ticket'], 1, inplace=True)
# print(df.info())#可以查看数据类型
df.convert_objects(convert_numeric=True)#将object格式转float64格式
df.fillna(0, inplace=True) # 把NaN替换为0
# 把字符串映射为数字,例如{female:1, male:0}
df_map = {} # 保存映射关系
cols = df.columns.values
print('cols:',cols)
for col in cols:
if df[col].dtype != np.int64 and df[col].dtype != np.float64:
temp = {}
x = 0
for ele in set(df[col].values.tolist()):
if ele not in temp:
temp[ele] = x
x += 1
df_map[df[col].name] = temp
df[col] = list(map(lambda val: temp[val], df[col]))
for key, value in df_map.items():
print(key,value)
# print(df.head())
# 由于是非监督学习,不使用label
x = np.array(df.drop(['survived'], 1).astype(float))
# 将每一列特征标准化为标准正太分布,注意,标准化是针对每一列而言的
x = preprocessing.scale(x)
clf = KMeans(n_clusters=2)
clf.fit(x)
# 上面已把数据分成两组
# 下面计算分组准确率是多少
y = np.array(df['survived'])
correct = 0
for i in range(len(x)):
predict_data = np.array(x[i].astype(float))
predict_data = predict_data.reshape(-1, len(predict_data))
predict = clf.predict(predict_data)
# print(predict[0], y[i])
if predict[0] == y[i]:
correct += 1
print(correct * 1.0 / len(x))
执行结果:
$ python sk_kmeans.py
0.692131398014 # 泰坦尼克号的幸存者和遇难者并不是随机分布的,在很大程度上取决于年龄、性别和社会地位
$ python sk_kmeans.py
0.307868601986 # 结果出现很大波动,原因是它随机分配组(生:0,死:1)(生:1,死:0)
# 1-0.307868601986是实际值
$ python sk_kmeans.py
0.692131398014
来源:http://blog.topspeedsnail.com/archives/10349
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)