对抗样本攻击
Github:https://github.com/Gary11111/03-GAN
研究背景
尽管深度学习在很多计算机视觉领域的任务上表现出色,Szegedy第一次发现了深度神经网络在图像分类领域存在有意思的弱点。他们证明尽管有很高的正确率,现代深度网络是非常容易受到对抗样本的攻击的。这些对抗样本仅有很轻微的扰动,以至于人类视觉系统无法察觉这种扰动(图片看起来几乎一样)。这样的攻击会导致神经网络完全改变它对图片的分类。此外,同样的图片扰动可以欺骗好多网络分类器。
对抗样本涉及到的评估标准
使用一个具体的例子来说明三个指标
假如某个班级有男生 80 人, 女生20人, 共计 100 人. 目标是找出所有女生. 现在某人挑选出 50 个人, 其中 20 是女生, 另外还错误的把 30 个男生也当作女生挑选出来了. 作为评估者的你需要来评估(evaluation)下他的工作
-
准确率(accuracy)
对于给定的策树数据集,分类器正确分类样本与总样本数之比。在开头的场景中,这个人把20个女生分类正确,50个男生分类正确所以
a
c
c
=
(
20
+
50
)
/
100
=
70
acc = (20+50)/100 = 70%
acc=(20+50)/100=70
如果只关注准确率会带来一个问题:假设我把所有人全部看作男生,这样我的准确率可以高达80%,然而这个算法显然是不合理的,因此需要引出recall和precision。
-
TP, FN, FP, TN
| 相关 正类 | 无关 负类 |
|---|
| 被检索到 | TP: 正类判定为正类(50个女生中的20个女生) | FP:负类判定为正类 (抽取的50个人中的30个男生) |
| 未被检索到 | FN: 正类判定为负类(假设有女生没被采样到,她被判定成了男生) | TN 负类判定为负类 (未被抽样的50个男生) |
-
召回率(recall)
R
=
T
P
T
P
+
F
N
R = \frac{TP}{TP+FN}
R=TP+FNTP 计算的是:所有被检索到的正确结果占所有正类的比例。
-
精确率(precision)
P
=
T
P
T
P
+
F
P
P = \frac{TP}{TP+FP}
P=TP+FPTP 计算的是:被检索到的正确结果占所有被检索到的结果的比例。
对抗攻击的方式
下面介绍的两种分类方式,是在实际运用中测试防御模型效果较为常用的攻击模式。按照攻击者是否能掌握机器学习算法分为白盒和黑盒攻击。按照攻击目标(对抗最终所属分类的情况)分为有目标攻击和无目标攻击。其中,黑盒攻击和白盒攻击的概念将会在防御算法的论文中被反复提及。一般提出的新算法,都需经受黑盒攻击和白盒攻击两种攻击模式的测定。
- 白盒攻击:攻击者能够获知机器学习所使用的算法,以及算法所使用的参数。攻击者在产生对抗性攻击数据的过程中能够与机器学习的系统有所交互。
- 黑盒攻击:攻击者并不知道机器学习所使用的算法和参数,但攻击者仍能与机器学习的系统有所交互,比如可以通过传入任意输入观察输出,判断输出。
- 有目标攻击:对于一张图片,生成一个对抗样本,使得标注系统在其上的标注与原标注无关,即只要攻击成功就好,对抗样本的最终属于哪一类不做限制。
- 无目标攻击:对于一张图片和一个目标标注句子,生成一个对抗样本,使得标注系统在其上的标注与目标标注完全一致,即不仅要求攻击成功,还要求生成的对抗样本属于特定的类。
对抗防御方式
-
对抗训练:对抗训练旨在从随机初始化的权重中训练一个鲁棒的模型,其训练集由真实数据集和加入了对抗扰动的数据集组成,因此叫做对抗训练。
-
梯度掩码:由于当前的许多对抗样本生成方法都是基于梯度去生成的,所以如果将模型的原始梯度隐藏起来,就可以达到抵御对抗样本攻击的效果。
-
随机化:向原始模型引入随机层或者随机变量。使模型具有一定随机性,全面提高模型的鲁棒性,使其对噪声的容忍度变高。
-
去噪:在输入模型进行判定之前,先对当前对抗样本进行去噪,剔除其中造成扰动的信息,使其不能对模型造成攻击。
任务

-
椒盐噪声

def noise(img, SNR=0.7):
img_ = img.transpose(2, 1, 0)
c, h, w = img_.shape
mask = np.random.choice((0, 1, 2), size=(1, h, w), p=[SNR, (1 - SNR) / 2., (1 - SNR) / 2.])
mask = np.repeat(mask, c, axis=0)
img_[mask == 1] = 255
img_[mask == 2] = 0
return img_.transpose(2, 1, 0)
- Success rate of this attack is 0.98
- Noise norm of this attack is 20.688474655151367
-
模糊化
使用cv2自带的blur函数
img = cv2.blur(img, kernel = (1, 1)) # kernel越大图像越模糊

- Success rate of this attack is 1.0
- Noise norm of this attack is 12.38012695312
-
三种效果叠加

-
产生target的对抗样本
随机指定一个class要使样本被分类器判定为这个class(可能需要改变损失函数)。
本次实验选取 truck 类别作为目标,希望将所有样本都转化成 truck 这个类别。但在实验中发现,实验成功的概率只有 0.3 左右,但是所有的样本均偏离了原来的标签,也即:成功的欺骗了神经网络。在实验中,我使用了两套方案来比较结果:
lr0.01+epoch500

lr0.005+epoch2000
原谅我不想重新跑图像了 偷个懒
实验效果如下: 在实验中发现了一个神奇的现象,尽管 target 攻击的样本成功率为 50%左右,但仍有将近 48% 的对抗样本会被 vgg16 分类为另一种标签,具体结果可以见图3.10。以一次攻击为例,我指定的攻击目标为类别 9, truck。但是攻击后有 40%+ 的分布在类型 2 automobile。笔者猜想这种结果可能是因为加入了噪声后,使得图片有些特征使 vgg 网络变得不稳定而无法区分,且 truck 和 automobile 本身也是两类十分近似的类别,所以可以得出这样的假设: target 攻击成功了,但是因为样本扰动过大,导致 vgg 在分类的时候,在两类相近的标签 automobile 和 truck 之间摇摆不定,出现概率分布大致相同的现象。
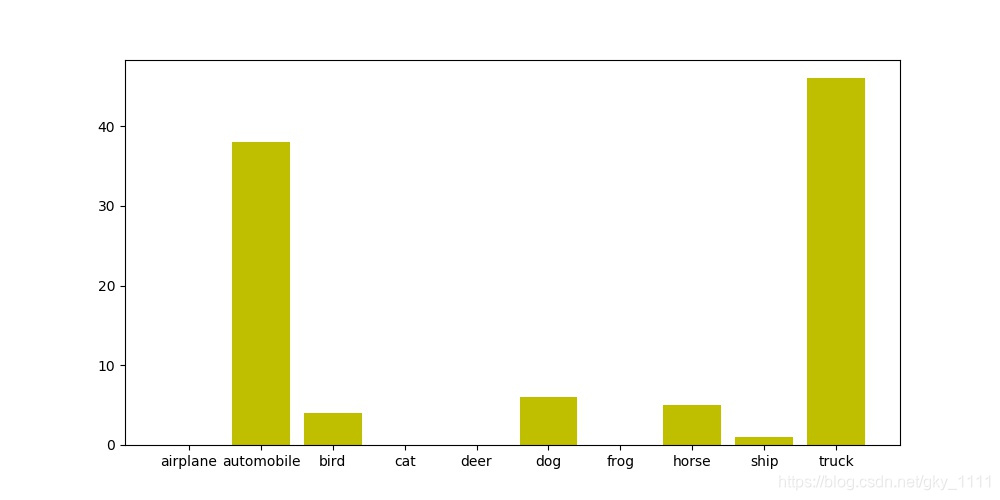
分近似的类别,所以可以得出这样的假设: target 攻击成功了,但是因为样本扰动过大,导致 vgg 在分类的时候,在两类相近的标签 automobile 和 truck 之间摇摆不定,出现概率分布大致相同的现象。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)



