目录
解析 DES 加密算法(C语言):
DES 简介:
DES 算法整体流程:
DES 解密:
C 语言代码实现加密解密逻辑:
解析 DES 加密算法(C语言):
内容修改自博客:
DES加密算法解析与实现 - luogi - 博客园
DES 简介:
DES 全称为 Data Encryption Standard,即数据加密标准,是一种使用密钥加密的块算法。
DES 算法就是一个把 8 字节 64 位的明文输入块变为 64 位密文输出块的算法,它所使用的密钥也是 64 位(其实只使用到了 56 位,其余 8 位为奇偶校验位)
算法特点:分组比较短、密钥太短、密码生命周期短、运算速度较慢。
DES 算法的入口参数有三个:Key、Data、Mode
> Key(密钥):为 7 个字节共 56 位,是 DES 算法的工作密钥(若说密钥为 64 位,其指的也是 56 位的秘钥加上 8 位奇偶校验位,奇偶校验位为第 8,16,24,32,40,48,56,64 位)
> Data(数据):为 8 个字节 64 位,是要被加密或被解密的数据
> Mode(模式): 为 DES 的工作方式,有两种:加密或解密。
DES 算法整体流程:

转换成文字就是:
1:一开始输入 64 位的明文数据;
2:然后进行初始置换(IP);
3:初始置换之后,将生成的 64 位数据分为左右两部分,每部分为 32 位,命名为 L0(Left0)、R0(Right0);
4:然后这两部分在密钥 k 的参与下,根据函数 f 进行 16 轮逻辑相同但参数不同的运算,我们称为 16 轮迭代运算,每运算一次,左右两部分的命名就改变一次,比如第一轮运算后,L0、R0 就变为 L1、R1,直到 16 轮运算完成,L0 变为 L16,R0 变为 R16;(注意这里 L1 = R0,R1 = L0 ^ f(R0,K1))
5:在 16 轮运算完成之后,将 L16 和 R16 交换,并且合并为 64 位;再经过末置换(初始置换的逆置换/终止置换),输出密文。
IP置换(初始置换):
初始置换的原理其实很简单,根据一个初始置换表,对照表中的数值,将明文数据相应位置的数据移动到该数据所在的位置即可。
初始置换表如下:

置换举例:(实际操作是位操作,但是这里为了直观我们以单个字母为一个位)
由于二进制数据不容易看到置换后的改变,我们这里展示初始置换的流程时,不使用实际加密中的二进制数据,而是用字母代替。
用的字母如下:"abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789+="

a 就是加密的 64 位数据中的第一位,b 就是第二位,依次类推,那么,初始置换之后就应该是这样的:
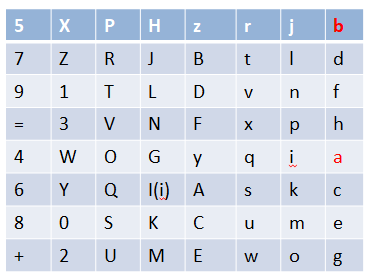
至此我们便得到了初始置换之后的数据:
Data=“5XPHzrjb7ZRJBtld91TLDvnf=3VNFxph4WOGyqia6YQI(i)Askc80SKCume+2UMEwog”
从前面任务中 DES 加密算法的整体流程知道,初始置换完成之后,就需要将置换后的数据分为 L0、R0:
L0 = “5XPHzrjb7ZRJBtld91TLDvnf=3VNFxph”
R0 = “4WOGyqia6YQI(i)Askc80SKCume+2UMEwog”
函数 f 的大致流程:

从上图我们可以知道,函数 f 主要对数据的右半部分 R 进行了操作:
1. 先对其进行扩展置换,使其变为 48 位的数据,
2. 然后生成的数据再与子密钥进行异或运算,得到一组新的 48 位数据
3. 再以异或运算后的 48 位数据进行 S 盒代替,将 48 位的数据,转换为 32 位的数据,
4. 再进行 P 盒置换,生成 32 位的数据
5. 最后将 P 盒置换生成的数据与本轮运算时输入的 L 进行异或运算,生成新的 R。
6. 而新的 L 是直接由本轮的 R 进行替换
扩展置换 E:
扩展置换的作用对象是我们在初始置换后,将数据拆分为两部分(L,R)中的右半部分 R。
扩展置换表如下:
将数据 R(32位),按照每 4 位一组,拆分成 8 个组,如图,左右两侧黑色的两列是扩展时添加的数据,中间的就是分组后的数据 R,表中的数字代表数据 R 中的位置。

分成 8 组后,遵循这样的一个规则:
1. 每一组的头部添加本组数据上一组的尾部,
2. 每一组的尾部添加本组数据下一组的头部。
即第一组数据,前面添加的是最后一组的最后一位数据,后面添加的是第二组的第一位数据…以此类推,
继续上面的例子,拿我们上面得到的 R0 进行扩展置换:
先分组:
R0 = “4WOGyqia6YQI(i)Askc80SKCume+2UMEwog”

然后进行扩展:

之后我们便得到了扩展到 48 位的 R0:
R0=“g4WOGYGYqia6a6YQI(i)AI(i)Askc8c80SKCKCume+e+2UMEMEwog4”
扩展置换 E 结束之后,我们要进行的就是 K1 与 R0 的异或运算,由于我们这里不是采用的真正的二进制数据,所以我们不做此步骤的详细解释,毕竟只是一个异或运算,很简单。
子秘钥 K:
子秘钥 K 的生成过程中,又有两次置换,称为压缩置换 1 和压缩置换 2,大致流程图如下:

从流程图我们可以清楚的知道:
1. 初始密钥在经过第一次压缩置换之后,生成 56 位数据,
2. 再将这 56 位数据从中间拆分开来,命名为 C0,D0,都是 28 位数据
3. 然后根据正在运算的轮数,将数据左移相应的位数,来得到 C1 和 D1,
4. 最后,压缩置换 1 未完成,将 C1,D1 合并为 56 位的数据,
5. 经过压缩置换 2 之后,生成子密钥 K1,即生成了第一轮运算时使用的子密钥。而且每一轮运算中的子密钥 K 都是由上一轮生成的子密钥经过这两次压缩置换得到的。
压缩置换 1:
我们将 64 位数据分成 8 组,每一组的最后一位数据,是奇偶校验位,虽然也属于密钥,但是不参与加密运算,也就是去掉这些标红的数据,剩下的 56 位数据就是需要参与到压缩置换 1 的数据。
如下图:

跟之前讲过的初始置换一样,将字母换到对应的位置上就可以了(为了方便我们在初始秘钥的表格后面标注了每行最后一个参与置换的字母的位置,比如 g 是第 7 位,o 是第 15 位)。
置换完成后:

压缩置换 1 接下来的是拆分:
K0 = “4WOGyqia5XPHzrjb6YQI(i)Askc7ZRJ+2UMEwog91TLDvnf80SKCumeBtld”
C0 = “4WOGyqia5XPHzrjb6YQI(i)Askc7ZRJ”
D0 = “+2UMEwog91TLDvnf80SKCumeBtld”
循环左移表:
由于每一轮运算中的子密钥 K 都是由上一轮生成的子密钥经过这两次压缩置换得到的,压缩置换表是相同的,但是循环左移的位数,在每一轮中都是不同的。C1、D1 是由 C0、D0 移位得到,C2、D2 是由 C1、D1 移位得到……..以此类推。

应用举例:(承接上面的压缩置换 1 后的例子,注意这里是用可视化的单个字母代替了一个位)
我们根据 “轮数与左移位数” 的对应表,得知,我们现在要求的是 C1、D1,也就是第一轮运算,那么循环左移的位数就是 1 位,就可以得到:
C1 = “WOGyqia5XPHzrjb6YQI(i)Askc7ZRJ4”
D1 = “2UMEwog91TLDvnf80SKCumeBtld+”
如左移的同时还要保持位数不变,所以最前面(左侧)移动的数据又补充到后面。然后将 C1D1 合并:
C1D1 = “WOGyqia5XPHzrjb6YQI(i)Askc7ZRJ42UMEwog91TLDvnf80SKCumeBtld+”
放在表格中(黑色表格中的是每一行最后一位的位数):

压缩置换 2:
要得到子秘钥 K1,还需要进行压缩置换 2,经过压缩置换 2 之后 56 位的 C1D1 被压缩成 48 位的 K1:
压缩置换 2 遵循的规则表如下:

得到 K1:

至此我们便得到了第一轮真正的子密钥:K1
> K1 = “jYH7WqG4bisPcI(i)zyR56aJArOvBM1KdUDe0wC8uL+otSnm92E”
S 盒代替:
S 盒代替的作用,就是将我们上一步,R0 与 K1 异或后得到的 48 位数据压缩为 32 位数据。
S 盒一共有 8 个,每一个都是一个 4 行 16 列的数组,具体如下:




用文字描述一下 S 盒代替的过程:
1. 我们前面扩展置换后得到的 R0 是 48 位的数据,我们的 S 盒有 8 个,那么我们就需要将得到的 R0 平均分为 8 组,每组对应一个 S 盒。
2. 每一组的数据长度为 6 位,假设第一组的二进制数据为:“100110”
3. 那么,我们取第一位与最后一位,组成十进制行数:“10”=2
4. 然后取中间四位,组成十进制列数:“0011”=3
5. 那么,在对应的 S1 盒中,取 2 行 3 列的数据(第 3 行第 4 列):8
6. 再将取得的数字转换为 2 进制:“1000”
7. 将这个得到的4位二进制数据,代替原来第一组的 6 位数据,这样一来,等 8 个S盒全部代替完毕,我们就得到 32 位的数据。
P 盒置换:
S 盒置换完成之后,要进行的就是 P 盒置换了,输入 32 位的数据,得到 32 位的输出。
置换表以及置换举例如下:

至此我们便得到了 f(R0,K1),只要再与 L0 进行异或运算,就得到了第一轮运算最终的 R1,然后再将 R0 的值赋给 L1,就完成了第一轮的运算,得到了 L1,R1。
末置换(也称初始置换的逆置换/终止置换):
经过 16 次的运算,我们在函数 f 的最后,会得到 “L16、R16”,这正是我们需要的,然后将 L16 与 R16 合并,但是与之前的步骤中的合并不同,此次合并需要先交换二者的位置,也就是应该是 R16L16。
合并之后我们就得到了长度为 64 位的数据,在用这 64 位数据进行终止置换,最终得到的数据就是加密后的数据。
终止置换表如下(我们不再举例,反正都一样):

DES 解密:
解密就是加密的反过程,执行上述步骤,只不过在那 16 轮迭代中,调转左右子秘钥的位置而已。
C 语言代码实现加密解密逻辑:
代码出自:C语言实现DES加解密算法_P1umH0的博客-CSDN博客_c语言des加解密
一:准备对应表
1.初始置换表–IP
const static ubyte IP[] = {
58, 50, 42, 34, 26, 18, 10, 2,
60, 52, 44, 36, 28, 20, 12, 4,
62, 54, 46, 38, 30, 22, 14, 6,
64, 56, 48, 40, 32, 24, 16, 8,
57, 49, 41, 33, 25, 17, 9, 1,
59, 51, 43, 35, 27, 19, 11, 3,
61, 53, 45, 37, 29, 21, 13, 5,
63, 55, 47, 39, 31, 23, 15, 7
};
2.扩展置换表–E
const static ubyte E[] = {
32, 1, 2, 3, 4, 5,
4, 5, 6, 7, 8, 9,
8, 9, 10, 11, 12, 13,
12, 13, 14, 15, 16, 17,
16, 17, 18, 19, 20, 21,
20, 21, 22, 23, 24, 25,
24, 25, 26, 27, 28, 29,
28, 29, 30, 31, 32, 1
};
3.S盒(共8个):
const static ubyte S[][64] = {
{
14, 4, 13, 1, 2, 15, 11, 8, 3, 10, 6, 12, 5, 9, 0, 7,
0, 15, 7, 4, 14, 2, 13, 1, 10, 6, 12, 11, 9, 5, 3, 8,
4, 1, 14, 8, 13, 6, 2, 11, 15, 12, 9, 7, 3, 10, 5, 0,
15, 12, 8, 2, 4, 9, 1, 7, 5, 11, 3, 14, 10, 0, 6, 13
},
{
15, 1, 8, 14, 6, 11, 3, 4, 9, 7, 2, 13, 12, 0, 5, 10,
3, 13, 4, 7, 15, 2, 8, 14, 12, 0, 1, 10, 6, 9, 11, 5,
0, 14, 7, 11, 10, 4, 13, 1, 5, 8, 12, 6, 9, 3, 2, 15,
13, 8, 10, 1, 3, 15, 4, 2, 11, 6, 7, 12, 0, 5, 14, 9
},
{
10, 0, 9, 14, 6, 3, 15, 5, 1, 13, 12, 7, 11, 4, 2, 8,
13, 7, 0, 9, 3, 4, 6, 10, 2, 8, 5, 14, 12, 11, 15, 1,
13, 6, 4, 9, 8, 15, 3, 0, 11, 1, 2, 12, 5, 10, 14, 7,
1, 10, 13, 0, 6, 9, 8, 7, 4, 15, 14, 3, 11, 5, 2, 12
},
{
7, 13, 14, 3, 0, 6, 9, 10, 1, 2, 8, 5, 11, 12, 4, 15,
13, 8, 11, 5, 6, 15, 0, 3, 4, 7, 2, 12, 1, 10, 14, 9,
10, 6, 9, 0, 12, 11, 7, 13, 15, 1, 3, 14, 5, 2, 8, 4,
3, 15, 0, 6, 10, 1, 13, 8, 9, 4, 5, 11, 12, 7, 2, 14
},
{
2, 12, 4, 1, 7, 10, 11, 6, 8, 5, 3, 15, 13, 0, 14, 9,
14, 11, 2, 12, 4, 7, 13, 1, 5, 0, 15, 10, 3, 9, 8, 6,
4, 2, 1, 11, 10, 13, 7, 8, 15, 9, 12, 5, 6, 3, 0, 14,
11, 8, 12, 7, 1, 14, 2, 13, 6, 15, 0, 9, 10, 4, 5, 3
},
{
12, 1, 10, 15, 9, 2, 6, 8, 0, 13, 3, 4, 14, 7, 5, 11,
10, 15, 4, 2, 7, 12, 9, 5, 6, 1, 13, 14, 0, 11, 3, 8,
9, 14, 15, 5, 2, 8, 12, 3, 7, 0, 4, 10, 1, 13, 11, 6,
4, 3, 2, 12, 9, 5, 15, 10, 11, 14, 1, 7, 6, 0, 8, 13
},
{
4, 11, 2, 14, 15, 0, 8, 13, 3, 12, 9, 7, 5, 10, 6, 1,
13, 0, 11, 7, 4, 9, 1, 10, 14, 3, 5, 12, 2, 15, 8, 6,
1, 4, 11, 13, 12, 3, 7, 14, 10, 15, 6, 8, 0, 5, 9, 2,
6, 11, 13, 8, 1, 4, 10, 7, 9, 5, 0, 15, 14, 2, 3, 12
},
{
13, 2, 8, 4, 6, 15, 11, 1, 10, 9, 3, 14, 5, 0, 12, 7,
1, 15, 13, 8, 10, 3, 7, 4, 12, 5, 6, 11, 0, 14, 9, 2,
7, 11, 4, 1, 9, 12, 14, 2, 0, 6, 10, 13, 15, 3, 5, 8,
2, 1, 14, 7, 4, 10, 8, 13, 15, 12, 9, 0, 3, 5, 6, 11
}
};
4.P置换表
const static ubyte P[] = {
16, 7, 20, 21,
29, 12, 28, 17,
1, 15, 23, 26,
5, 18, 31, 10,
2, 8, 24, 14,
32, 27, 3, 9,
19, 13, 30, 6,
22, 11, 4, 25
};
6.子密钥 KEY 生成的循环左移 SHIFTS 关系表:
const static ubyte SHIFTS[] = { 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1};
7.子密钥 KEY 生成的压缩置换 PC_1 表:
const static ubyte PC1[] = {
57, 49, 41, 33, 25, 17, 9,
1, 58, 50, 42, 34, 26, 18,
10, 2, 59, 51, 43, 35, 27,
19, 11, 3, 60, 52, 44, 36,
63, 55, 47, 39, 31, 23, 15,
7, 62, 54, 46, 38, 30, 22,
14, 6, 61, 53, 45, 37, 29,
21, 13, 5, 28, 20, 12, 4
};
8.子密钥 KEY 生成的压缩置换 PC_2 表:
const static ubyte PC2[] = {
14, 17, 11, 24, 1, 5,
3, 28, 15, 6, 21, 10,
23, 19, 12, 4, 26, 8,
16, 7, 27, 20, 13, 2,
41, 52, 31, 37, 47, 55,
30, 40, 51, 45, 33, 48,
44, 49, 39, 56, 34, 53,
46, 42, 50, 36, 29, 32
};
9.逆初始置换表–IP2
const static ubyte IP2[] = {
40, 8, 48, 16, 56, 24, 64, 32,
39, 7, 47, 15, 55, 23, 63, 31,
38, 6, 46, 14, 54, 22, 62, 30,
37, 5, 45, 13, 53, 21, 61, 29,
36, 4, 44, 12, 52, 20, 60, 28,
35, 3, 43, 11, 51, 19, 59, 27,
34, 2, 42, 10, 50, 18, 58, 26,
33, 1, 41, 9, 49, 17, 57, 25
};
二:准备逻辑代码:
typedef unsigned char ubyte;
#define KEY_LEN 8
typedef ubyte key_t[KEY_LEN];
typedef struct {
ubyte *data;
int len;
} String;
*将单个半字节转换为十六进制字符
*参数 in:a 值 < 0x10
*返回:表示半字节的字符
static char toHex(ubyte in) {
if (0x00 <= in && in < 0x0A) {
return '0' + in;
}
if (0x0A <= in && in <= 0x0F) {
return 'A' + in - 0x0A;
}
return 0;
}
*将字节数组转换为字符串
*参数 ptr:字节数组
*参数 len:字节数
*参数 out:调用者分配的缓冲区,有足够的空间容纳 2*len+1 个字符,因为半字节一个十六进制字符
static void printBytes(const ubyte *ptr, int len, char *out) {
while (len-- > 0) {
*out++ = toHex(*ptr >> 4);
*out++ = toHex(*ptr & 0x0F);
ptr++;
}
*out = 0;
}
*获取字节数组中位的值
*参数 src:要索引的字节数组
*参数 index:用于测试值的所需位
*返回:数组中指定位置的位
static int peekBit(const ubyte *src, int index) {
int cell = index / 8;
int bit = 7 - index % 8;
return (src[cell] & (1 << bit)) != 0;
}
*设置字节数组中位的值
*参数 dst:要设置位的位数组
*参数 index:要设置的位的位置
*参数 value:要设置的位的值
static void pokeBit(ubyte *dst, int index, int value) {
int cell = index / 8;
int bit = 7 - index % 8;
if (value == 0) {
dst[cell] &= ~(1 << bit);
}
else {
dst[cell] |= (1 << bit);
}
}
poke*通过将位移位到指定的位置数来转换一个字节数组
*参数 src:要从中移位位的数组
*参数 len:src 数组的长度
*参数 times:位应移位的位置数
*参数 dst:调用者分配用于存储移位值的字节数组
static void shiftLeft(const ubyte *src, int len, int times, ubyte *dst) {
int i, t;
for (i = 0; i <= len; ++i) {
pokeBit(dst, i, peekBit(src, i));
}
for (t = 1; t <= times; ++t) {
int temp = peekBit(dst, 0);
for (i = 1; i <= len; ++i) {
pokeBit(dst, i - 1, peekBit(dst, i));
}
pokeBit(dst, len - 1, temp);
}
}
*计算处理消息时要使用的子密钥
*参数 key:表示密钥的字节数组
*参数 ks:调用者分配的子键
typedef ubyte subkey_t[17][6]; /* 17 sets of 48 bits */
static void getSubKeys(const key_t key, subkey_t ks) {
ubyte c[17][7]; /* 56 bits */
ubyte d[17][4]; /* 28 bits */
ubyte kp[7];
int i, j;
/* intialize */
memset(c, 0, sizeof(c));
memset(d, 0, sizeof(d));
memset(ks, 0, sizeof(subkey_t));
/* permute 'key' using table PC1 */
for (i = 0; i < 56; ++i) {
pokeBit(kp, i, peekBit(key, PC1[i] - 1));
}
/* split 'kp' in half and process the resulting series of 'c' and 'd' */
for (i = 0; i < 28; ++i) {
pokeBit(c[0], i, peekBit(kp, i));
pokeBit(d[0], i, peekBit(kp, i + 28));
}
/* shift the components of c and d */
for (i = 1; i < 17; ++i) {
shiftLeft(c[i - 1], 28, SHIFTS[i - 1], c[i]);
shiftLeft(d[i - 1], 28, SHIFTS[i - 1], d[i]);
}
/* merge 'd' into 'c' */
for (i = 1; i < 17; ++i) {
for (j = 28; j < 56; ++j) {
pokeBit(c[i], j, peekBit(d[i], j - 28));
}
}
/* form the sub-keys and store them in 'ks'
* permute 'c' using table PC2 */
for (i = 1; i < 17; ++i) {
for (j = 0; j < 48; ++j) {
pokeBit(ks[i], j, peekBit(c[i], PC2[j] - 1));
}
}
}
*用于处理消息的函数
*参数 r:要处理的字节数组
*参数 ks:用于处理的子键之一
*参数 sp:处理的输出
static void f(ubyte *r, ubyte *ks, ubyte *sp) {
ubyte er[6]; /* 48 bits */
ubyte sr[4]; /* 32 bits */
int i;
/* initialize */
memset(er, 0, sizeof(er));
memset(sr, 0, sizeof(sr));
/* permute 'r' using table E */
for (i = 0; i < 48; ++i) {
pokeBit(er, i, peekBit(r, E[i] - 1));
}
/* xor 'er' with 'ks' and store back into 'er' */
for (i = 0; i < 6; ++i) {
er[i] ^= ks[i];
}
/* process 'er' six bits at a time and store resulting four bits in 'sr' */
for (i = 0; i < 8; ++i) {
int j = i * 6;
int b[6];
int k, row, col, m, n;
for (k = 0; k < 6; ++k) {
b[k] = peekBit(er, j + k) != 0 ? 1 : 0;
}
row = 2 * b[0] + b[5];
col = 8 * b[1] + 4 * b[2] + 2 * b[3] + b[4];
m = S[i][row * 16 + col]; /* apply table s */
n = 1;
while (m > 0) { //这里是获取到 S 盒的值后转成 bit 搭配 pokeBit 按位赋值到 sr bit 数组中
int p = m % 2;
pokeBit(sr, (i + 1) * 4 - n, p == 1);
m /= 2;
n++;
}
}
/* permute sr using table P */
for (i = 0; i < 32; ++i) {
pokeBit(sp, i, peekBit(sr, P[i] - 1));
}
}
*消息块的处理
*参数 message:来自消息的 8 字节块
*参数 ks:要在处理中使用的子密钥
*参数 ep:调用者分配的编码 8 字节块的空间
static void processMessage(const ubyte *message, subkey_t ks, ubyte *ep) {
ubyte left[17][4]; /* 32 bits */
ubyte right[17][4]; /* 32 bits */
ubyte mp[8]; /* 64 bits */
ubyte e[8]; /* 64 bits */
int i, j;
/* permute 'message' using table IP */
for (i = 0; i < 64; ++i) {
pokeBit(mp, i, peekBit(message, IP[i] - 1));
}
/* split 'mp' in half and process the resulting series of 'l' and 'r */
for (i = 0; i < 32; ++i) {
pokeBit(left[0], i, peekBit(mp, i));
pokeBit(right[0], i, peekBit(mp, i + 32));
}
for (i = 1; i < 17; ++i) {
ubyte fs[4]; /* 32 bits */
//R0 给了 L1,L0 的 ^= 最后给了 R1,只是绕了一点而已
memcpy(left[i], right[i - 1], 4);
f(right[i - 1], ks[i], fs);
for (j = 0; j < 4; ++j) {
left[i - 1][j] ^= fs[j];
}
memcpy(right[i], left[i - 1], 4);
}
/* amalgamate r[16] and l[16] (in that order) into 'e' */
for (i = 0; i < 32; ++i) {
pokeBit(e, i, peekBit(right[16], i));
}
for (i = 32; i < 64; ++i) {
pokeBit(e, i, peekBit(left[16], i - 32));
}
/* permute 'e' using table IP2 ad return result as a hex string */
for (i = 0; i < 64; ++i) {
pokeBit(ep, i, peekBit(e, IP2[i] - 1));
}
}
*使用 DES 加密消息
*参数 key:用于加密消息的密钥
*参数 message:要加密的消息
*参数 len:消息的长度
*返回:为编码消息动态分配的内存的一对,以及编码消息的长度,调用方需要在使用后释放内存。
String encrypt(const key_t key, const ubyte *message, int len) {
String result = { 0, 0 };
subkey_t ks;
ubyte padByte;
int i;
getSubKeys(key, ks);
padByte = 8 - len % 8;
result.len = len + padByte;
result.data = (ubyte*)malloc(result.len);
memcpy(result.data, message, len);
memset(&result.data[len], padByte, padByte);
for (i = 0; i < result.len; i += 8) {
processMessage(&result.data[i], ks, &result.data[i]);
}
return result;
}
*使用 DES 解密消息
*参数 key:用于解密消息的密钥
*参数 message:要解密的消息
*参数 len:消息的长度
*返回:解码消息的动态分配内存的配对,以及解码消息的长度,调用方需要在使用后释放内存。
String decrypt(const key_t key, const ubyte *message, int len) {
String result = { 0, 0 };
subkey_t ks;
int i, j;
ubyte padByte;
getSubKeys(key, ks);
/* reverse the subkeys */
for (i = 1; i < 9; ++i) {
for (j = 0; j < 6; ++j) {
ubyte temp = ks[i][j];
ks[i][j] = ks[17 - i][j];
ks[17 - i][j] = temp;
}
}
result.data = (ubyte*)malloc(len);
memcpy(result.data, message, len);
result.len = len;
for (i = 0; i < result.len; i += 8) {
processMessage(&result.data[i], ks, &result.data[i]);
}
padByte = result.data[len - 1];
result.len -= padByte;
return result;
}
void driver(const key_t key, const ubyte *message, int len) {
String encoded, decoded;
char buffer[128];
printBytes(key, KEY_LEN, buffer);
printf("Key : %s\n", buffer);
printBytes(message, len, buffer);
printf("Message : %s\n", buffer);
encoded = encrypt(key, message, len);
printBytes(encoded.data, encoded.len, buffer);
printf("Encoded : %s\n", buffer);
decoded = decrypt(key, encoded.data, encoded.len);
printBytes(decoded.data, decoded.len, buffer);
printf("Decoded : %s\n\n", buffer);
/* release allocated memory */
if (encoded.len > 0) {
free(encoded.data);
encoded.data = 0;
}
if (decoded.len > 0) {
free(decoded.data);
decoded.data = 0;
}
}
void main()
{
String decoded;
int len;
//密钥
const key_t key = { 97, 98, 99, 100, 101, 102, 103, 104 };
//密文
const ubyte data[] = { 18, 160, 16, 191, 146, 60, 89, 222, 238, 164, 90, 7, 250, 217, 139, 223 };
//密文长度
len = sizeof(data) / sizeof(ubyte);
decoded = decrypt(key, data, len);
printf("Decoded:%s\n", decoded.data);
//释放内存
if (decoded.len > 0) {
free(decoded.data);
decoded.data = 0;
}
return;
}
三:完整代码:(代码出自:P1umH0的博客-CSDN博客_c语言des加解密)
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/*--------------------------------------------------------------------------------------------------------------*/
typedef unsigned char ubyte;
/*--------------------------------------------------------------------------------------------------------------*/
#define KEY_LEN 8
typedef ubyte key_t[KEY_LEN];
/*--------------------------------------------------------------------------------------------------------------*/
const static ubyte PC1[] = {
57, 49, 41, 33, 25, 17, 9,
1, 58, 50, 42, 34, 26, 18,
10, 2, 59, 51, 43, 35, 27,
19, 11, 3, 60, 52, 44, 36,
63, 55, 47, 39, 31, 23, 15,
7, 62, 54, 46, 38, 30, 22,
14, 6, 61, 53, 45, 37, 29,
21, 13, 5, 28, 20, 12, 4
};
/*--------------------------------------------------------------------------------------------------------------*/
const static ubyte PC2[] = {
14, 17, 11, 24, 1, 5,
3, 28, 15, 6, 21, 10,
23, 19, 12, 4, 26, 8,
16, 7, 27, 20, 13, 2,
41, 52, 31, 37, 47, 55,
30, 40, 51, 45, 33, 48,
44, 49, 39, 56, 34, 53,
46, 42, 50, 36, 29, 32
};
/*--------------------------------------------------------------------------------------------------------------*/
const static ubyte IP[] = {
58, 50, 42, 34, 26, 18, 10, 2,
60, 52, 44, 36, 28, 20, 12, 4,
62, 54, 46, 38, 30, 22, 14, 6,
64, 56, 48, 40, 32, 24, 16, 8,
57, 49, 41, 33, 25, 17, 9, 1,
59, 51, 43, 35, 27, 19, 11, 3,
61, 53, 45, 37, 29, 21, 13, 5,
63, 55, 47, 39, 31, 23, 15, 7
};
/*--------------------------------------------------------------------------------------------------------------*/
const static ubyte E[] = {
32, 1, 2, 3, 4, 5,
4, 5, 6, 7, 8, 9,
8, 9, 10, 11, 12, 13,
12, 13, 14, 15, 16, 17,
16, 17, 18, 19, 20, 21,
20, 21, 22, 23, 24, 25,
24, 25, 26, 27, 28, 29,
28, 29, 30, 31, 32, 1
};
/*--------------------------------------------------------------------------------------------------------------*/
const static ubyte S[][64] = {
{
14, 4, 13, 1, 2, 15, 11, 8, 3, 10, 6, 12, 5, 9, 0, 7,
0, 15, 7, 4, 14, 2, 13, 1, 10, 6, 12, 11, 9, 5, 3, 8,
4, 1, 14, 8, 13, 6, 2, 11, 15, 12, 9, 7, 3, 10, 5, 0,
15, 12, 8, 2, 4, 9, 1, 7, 5, 11, 3, 14, 10, 0, 6, 13
},
{
15, 1, 8, 14, 6, 11, 3, 4, 9, 7, 2, 13, 12, 0, 5, 10,
3, 13, 4, 7, 15, 2, 8, 14, 12, 0, 1, 10, 6, 9, 11, 5,
0, 14, 7, 11, 10, 4, 13, 1, 5, 8, 12, 6, 9, 3, 2, 15,
13, 8, 10, 1, 3, 15, 4, 2, 11, 6, 7, 12, 0, 5, 14, 9
},
{
10, 0, 9, 14, 6, 3, 15, 5, 1, 13, 12, 7, 11, 4, 2, 8,
13, 7, 0, 9, 3, 4, 6, 10, 2, 8, 5, 14, 12, 11, 15, 1,
13, 6, 4, 9, 8, 15, 3, 0, 11, 1, 2, 12, 5, 10, 14, 7,
1, 10, 13, 0, 6, 9, 8, 7, 4, 15, 14, 3, 11, 5, 2, 12
},
{
7, 13, 14, 3, 0, 6, 9, 10, 1, 2, 8, 5, 11, 12, 4, 15,
13, 8, 11, 5, 6, 15, 0, 3, 4, 7, 2, 12, 1, 10, 14, 9,
10, 6, 9, 0, 12, 11, 7, 13, 15, 1, 3, 14, 5, 2, 8, 4,
3, 15, 0, 6, 10, 1, 13, 8, 9, 4, 5, 11, 12, 7, 2, 14
},
{
2, 12, 4, 1, 7, 10, 11, 6, 8, 5, 3, 15, 13, 0, 14, 9,
14, 11, 2, 12, 4, 7, 13, 1, 5, 0, 15, 10, 3, 9, 8, 6,
4, 2, 1, 11, 10, 13, 7, 8, 15, 9, 12, 5, 6, 3, 0, 14,
11, 8, 12, 7, 1, 14, 2, 13, 6, 15, 0, 9, 10, 4, 5, 3
},
{
12, 1, 10, 15, 9, 2, 6, 8, 0, 13, 3, 4, 14, 7, 5, 11,
10, 15, 4, 2, 7, 12, 9, 5, 6, 1, 13, 14, 0, 11, 3, 8,
9, 14, 15, 5, 2, 8, 12, 3, 7, 0, 4, 10, 1, 13, 11, 6,
4, 3, 2, 12, 9, 5, 15, 10, 11, 14, 1, 7, 6, 0, 8, 13
},
{
4, 11, 2, 14, 15, 0, 8, 13, 3, 12, 9, 7, 5, 10, 6, 1,
13, 0, 11, 7, 4, 9, 1, 10, 14, 3, 5, 12, 2, 15, 8, 6,
1, 4, 11, 13, 12, 3, 7, 14, 10, 15, 6, 8, 0, 5, 9, 2,
6, 11, 13, 8, 1, 4, 10, 7, 9, 5, 0, 15, 14, 2, 3, 12
},
{
13, 2, 8, 4, 6, 15, 11, 1, 10, 9, 3, 14, 5, 0, 12, 7,
1, 15, 13, 8, 10, 3, 7, 4, 12, 5, 6, 11, 0, 14, 9, 2,
7, 11, 4, 1, 9, 12, 14, 2, 0, 6, 10, 13, 15, 3, 5, 8,
2, 1, 14, 7, 4, 10, 8, 13, 15, 12, 9, 0, 3, 5, 6, 11
}
};
/*--------------------------------------------------------------------------------------------------------------*/
const static ubyte P[] = {
16, 7, 20, 21,
29, 12, 28, 17,
1, 15, 23, 26,
5, 18, 31, 10,
2, 8, 24, 14,
32, 27, 3, 9,
19, 13, 30, 6,
22, 11, 4, 25
};
/*--------------------------------------------------------------------------------------------------------------*/
const static ubyte IP2[] = {
40, 8, 48, 16, 56, 24, 64, 32,
39, 7, 47, 15, 55, 23, 63, 31,
38, 6, 46, 14, 54, 22, 62, 30,
37, 5, 45, 13, 53, 21, 61, 29,
36, 4, 44, 12, 52, 20, 60, 28,
35, 3, 43, 11, 51, 19, 59, 27,
34, 2, 42, 10, 50, 18, 58, 26,
33, 1, 41, 9, 49, 17, 57, 25
};
/*--------------------------------------------------------------------------------------------------------------*/
const static ubyte SHIFTS[] = {
1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 1
};
/*--------------------------------------------------------------------------------------------------------------*/
typedef struct {
ubyte *data;
int len;
} String;
/*--------------------------------------------------------------------------------------------------------------*/
/*
* Transform a single nibble into a hex character
*
* in: a value < 0x10
*
* returns: the character that represents the nibble
*/
static char toHex(ubyte in) {
if (0x00 <= in && in < 0x0A) {
return '0' + in;
}
if (0x0A <= in && in <= 0x0F) {
return 'A' + in - 0x0A;
}
return 0;
}
/*--------------------------------------------------------------------------------------------------------------*/
/*
* Convert an array of bytes into a string
*
* ptr: the array of bytes
* len: the number of bytes
* out: a buffer allocated by the caller with enough space for 2*len+1 characters
*/
static void printBytes(const ubyte *ptr, int len, char *out) {
while (len-- > 0) {
*out++ = toHex(*ptr >> 4);
*out++ = toHex(*ptr & 0x0F);
ptr++;
}
*out = 0;
}
/*--------------------------------------------------------------------------------------------------------------*/
/*
* Gets the value of a bit in an array of bytes
*
* src: the array of bytes to index
* index: the desired bit to test the value of
*
* returns: the bit at the specified position in the array
*/
static int peekBit(const ubyte *src, int index) {
int cell = index / 8;
int bit = 7 - index % 8;
return (src[cell] & (1 << bit)) != 0;
}
/*--------------------------------------------------------------------------------------------------------------*/
/*
* Sets the value of a bit in an array of bytes
*
* dst: the array of bits to set a bit in
* index: the position of the bit to set
* value: the value for the bit to set
*/
static void pokeBit(ubyte *dst, int index, int value) {
int cell = index / 8;
int bit = 7 - index % 8;
if (value == 0) {
dst[cell] &= ~(1 << bit);
}
else {
dst[cell] |= (1 << bit);
}
}
/*--------------------------------------------------------------------------------------------------------------*/
/*
* Transforms one array of bytes by shifting the bits the specified number of positions
*
* src: the array to shift bits from
* len: the length of the src array
* times: the number of positions that the bits should be shifted
* dst: a bytes array allocated by the caller to store the shifted values
*/
static void shiftLeft(const ubyte *src, int len, int times, ubyte *dst) {
int i, t;
for (i = 0; i <= len; ++i) {
pokeBit(dst, i, peekBit(src, i));
}
for (t = 1; t <= times; ++t) {
int temp = peekBit(dst, 0);
for (i = 1; i <= len; ++i) {
pokeBit(dst, i - 1, peekBit(dst, i));
}
pokeBit(dst, len - 1, temp);
}
}
/*--------------------------------------------------------------------------------------------------------------*/
/*
* Calculates the sub keys to be used in processing the messages
*
* key: the array of bytes representing the key
* ks: the subkeys that have been allocated by the caller
*/
typedef ubyte subkey_t[17][6]; /* 17 sets of 48 bits */
static void getSubKeys(const key_t key, subkey_t ks) {
ubyte c[17][7]; /* 56 bits */
ubyte d[17][4]; /* 28 bits */
ubyte kp[7];
int i, j;
/* intialize */
memset(c, 0, sizeof(c));
memset(d, 0, sizeof(d));
memset(ks, 0, sizeof(subkey_t));
/* permute 'key' using table PC1 */
for (i = 0; i < 56; ++i) {
pokeBit(kp, i, peekBit(key, PC1[i] - 1));
}
/* split 'kp' in half and process the resulting series of 'c' and 'd' */
for (i = 0; i < 28; ++i) {
pokeBit(c[0], i, peekBit(kp, i));
pokeBit(d[0], i, peekBit(kp, i + 28));
}
/* shift the components of c and d */
for (i = 1; i < 17; ++i) {
shiftLeft(c[i - 1], 28, SHIFTS[i - 1], c[i]);
shiftLeft(d[i - 1], 28, SHIFTS[i - 1], d[i]);
}
/* merge 'd' into 'c' */
for (i = 1; i < 17; ++i) {
for (j = 28; j < 56; ++j) {
pokeBit(c[i], j, peekBit(d[i], j - 28));
}
}
/* form the sub-keys and store them in 'ks'
* permute 'c' using table PC2 */
for (i = 1; i < 17; ++i) {
for (j = 0; j < 48; ++j) {
pokeBit(ks[i], j, peekBit(c[i], PC2[j] - 1));
}
}
}
/*--------------------------------------------------------------------------------------------------------------*/
/*
* Function used in processing the messages
*
* r: an array of bytes to be processed
* ks: one of the subkeys to be used for processing
* sp: output from the processing
*/
static void f(ubyte *r, ubyte *ks, ubyte *sp) {
ubyte er[6]; /* 48 bits */
ubyte sr[4]; /* 32 bits */
int i;
/* initialize */
memset(er, 0, sizeof(er));
memset(sr, 0, sizeof(sr));
/* permute 'r' using table E */
for (i = 0; i < 48; ++i) {
pokeBit(er, i, peekBit(r, E[i] - 1));
}
/* xor 'er' with 'ks' and store back into 'er' */
for (i = 0; i < 6; ++i) {
er[i] ^= ks[i];
}
/* process 'er' six bits at a time and store resulting four bits in 'sr' */
for (i = 0; i < 8; ++i) {
int j = i * 6;
int b[6];
int k, row, col, m, n;
for (k = 0; k < 6; ++k) {
b[k] = peekBit(er, j + k) != 0 ? 1 : 0;
}
row = 2 * b[0] + b[5];
col = 8 * b[1] + 4 * b[2] + 2 * b[3] + b[4];
m = S[i][row * 16 + col]; /* apply table s */
n = 1;
while (m > 0) {
int p = m % 2;
pokeBit(sr, (i + 1) * 4 - n, p == 1);
m /= 2;
n++;
}
}
/* permute sr using table P */
for (i = 0; i < 32; ++i) {
pokeBit(sp, i, peekBit(sr, P[i] - 1));
}
}
/*--------------------------------------------------------------------------------------------------------------*/
/*
* Processing of block of the message
*
* message: an 8 byte block from the message
* ks: the subkeys to use in processing
* ep: space for an encoded 8 byte block allocated by the caller
*/
static void processMessage(const ubyte *message, subkey_t ks, ubyte *ep) {
ubyte left[17][4]; /* 32 bits */
ubyte right[17][4]; /* 32 bits */
ubyte mp[8]; /* 64 bits */
ubyte e[8]; /* 64 bits */
int i, j;
/* permute 'message' using table IP */
for (i = 0; i < 64; ++i) {
pokeBit(mp, i, peekBit(message, IP[i] - 1));
}
/* split 'mp' in half and process the resulting series of 'l' and 'r */
for (i = 0; i < 32; ++i) {
pokeBit(left[0], i, peekBit(mp, i));
pokeBit(right[0], i, peekBit(mp, i + 32));
}
for (i = 1; i < 17; ++i) {
ubyte fs[4]; /* 32 bits */
memcpy(left[i], right[i - 1], 4);
f(right[i - 1], ks[i], fs);
for (j = 0; j < 4; ++j) {
left[i - 1][j] ^= fs[j];
}
memcpy(right[i], left[i - 1], 4);
}
/* amalgamate r[16] and l[16] (in that order) into 'e' */
for (i = 0; i < 32; ++i) {
pokeBit(e, i, peekBit(right[16], i));
}
for (i = 32; i < 64; ++i) {
pokeBit(e, i, peekBit(left[16], i - 32));
}
/* permute 'e' using table IP2 ad return result as a hex string */
for (i = 0; i < 64; ++i) {
pokeBit(ep, i, peekBit(e, IP2[i] - 1));
}
}
/*--------------------------------------------------------------------------------------------------------------*/
/*
* Encrypts a message using DES
*
* key: the key to use to encrypt the message
* message: the message to be encrypted
* len: the length of the message
*
* returns: a paring of dynamically allocated memory for the encoded message,
* and the length of the encoded message.
* the caller will need to free the memory after use.
*/
String encrypt(const key_t key, const ubyte *message, int len) {
String result = { 0, 0 };
subkey_t ks;
ubyte padByte;
int i;
getSubKeys(key, ks);
padByte = 8 - len % 8;
result.len = len + padByte;
result.data = (ubyte*)malloc(result.len);
memcpy(result.data, message, len);
memset(&result.data[len], padByte, padByte);
for (i = 0; i < result.len; i += 8) {
processMessage(&result.data[i], ks, &result.data[i]);
}
return result;
}
/*--------------------------------------------------------------------------------------------------------------*/
/*
* Decrypts a message using DES
*
* key: the key to use to decrypt the message
* message: the message to be decrypted
* len: the length of the message
*
* returns: a paring of dynamically allocated memory for the decoded message,
* and the length of the decoded message.
* the caller will need to free the memory after use.
*/
String decrypt(const key_t key, const ubyte *message, int len) {
String result = { 0, 0 };
subkey_t ks;
int i, j;
ubyte padByte;
getSubKeys(key, ks);
/* reverse the subkeys */
for (i = 1; i < 9; ++i) {
for (j = 0; j < 6; ++j) {
ubyte temp = ks[i][j];
ks[i][j] = ks[17 - i][j];
ks[17 - i][j] = temp;
}
}
result.data = (ubyte*)malloc(len);
memcpy(result.data, message, len);
result.len = len;
for (i = 0; i < result.len; i += 8) {
processMessage(&result.data[i], ks, &result.data[i]);
}
padByte = result.data[len - 1];
result.len -= padByte;
return result;
}
/*--------------------------------------------------------------------------------------------------------------*/
/*
* Convienience method for showing the round trip processing of a message
*/
void driver(const key_t key, const ubyte *message, int len) {
String encoded, decoded;
char buffer[128];
printBytes(key, KEY_LEN, buffer);
printf("Key : %s\n", buffer);
printBytes(message, len, buffer);
printf("Message : %s\n", buffer);
encoded = encrypt(key, message, len);
printBytes(encoded.data, encoded.len, buffer);
printf("Encoded : %s\n", buffer);
decoded = decrypt(key, encoded.data, encoded.len);
printBytes(decoded.data, decoded.len, buffer);
printf("Decoded : %s\n\n", buffer);
/* release allocated memory */
if (encoded.len > 0) {
free(encoded.data);
encoded.data = 0;
}
if (decoded.len > 0) {
free(decoded.data);
decoded.data = 0;
}
}
/*--------------------------------------------------------------------------------------------------------------*/
void main()
{
String decoded;
int len;
//密钥
const key_t key = { 97, 98, 99, 100, 101, 102, 103, 104 };
//密文
const ubyte data[] = { 18, 160, 16, 191, 146, 60, 89, 222, 238, 164, 90, 7, 250, 217, 139, 223 };
//密文长度
len = sizeof(data) / sizeof(ubyte);
decoded = decrypt(key, data, len);
printf("Decoded:%s\n", decoded.data);
//释放内存
if (decoded.len > 0) {
free(decoded.data);
decoded.data = 0;
}
return;
}
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)