任务逻辑
当有个新的AGX主机到手上后,主机是启动的是eMMC,大约30G存储
这个安装了系统后到后面随便弄一下就不够存储了,所以我是想要在主机上安装一个SSD,然后将系统直接放到SSD上,这种操作就需要刷机完成后进行开机引导,即为rootOnNVMe
个人的理解
当完成了rootOnNVMe的流程后,可以从SSD启动后,相对应的rootfs指向已经写好到了eMMC中,那么到后面就可以直接换SSD,可以使用更换SSD的方式来更换系统内部的配置与工程文件。
如果你恰巧财力雄厚,有多个AGX的主机,便可以直接备份SSD,然后更换烧录好的SSD,从而让多台主机都是相同配置的系统设置,节省了很多时间。
进行刷机流程
先将新的主机进行刷机
首先运行ubuntu的虚拟机或者双系统
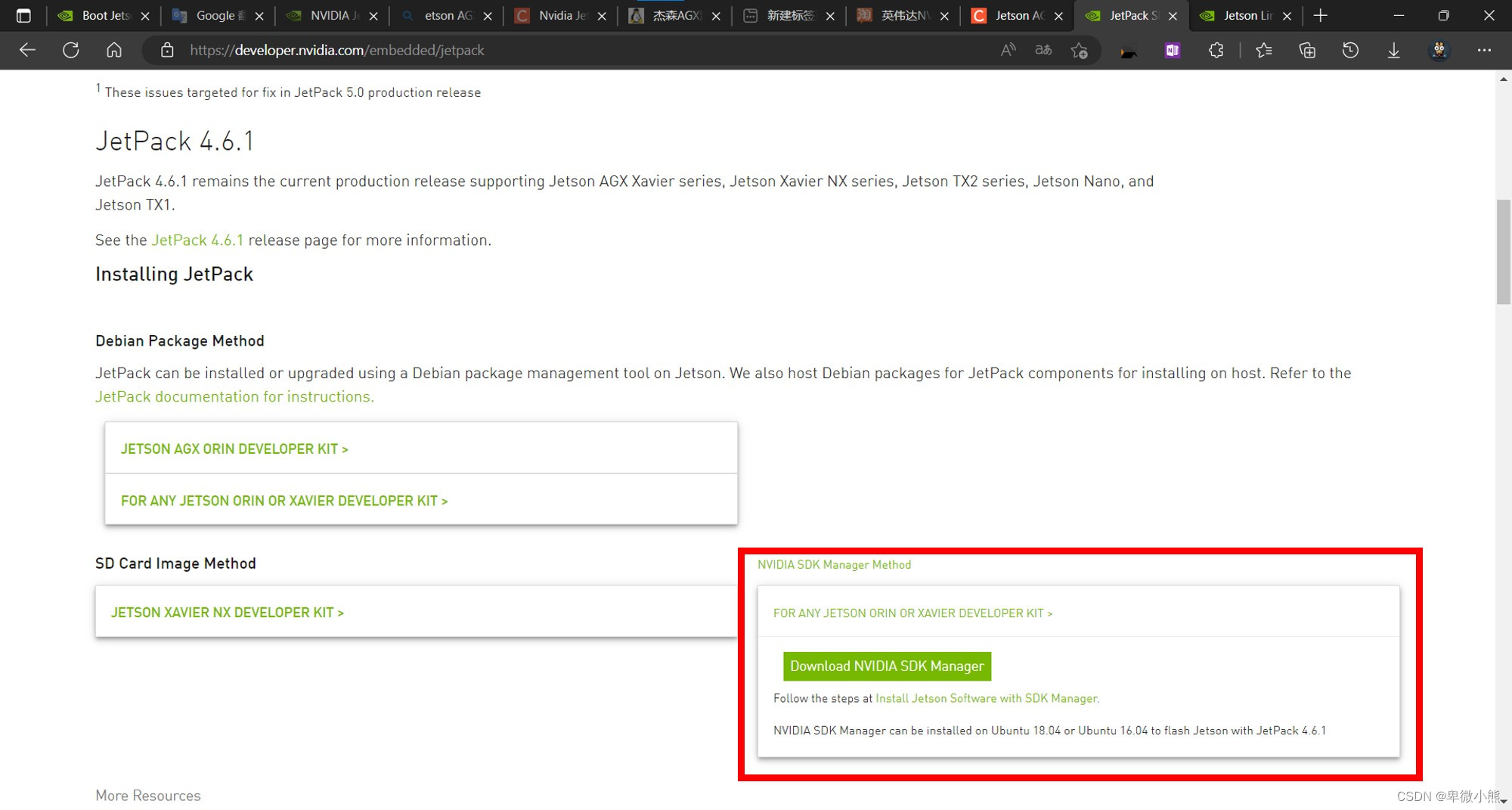
然后去到官方的下载网址将刷机程序NVIDIA SDK Manager安装到ubuntu
也就是图片红色的区域
由于我的虚拟机网络卡的很,所以我从Win10下载后截切达虚拟机中
进行安装,可能部分安装包的名字不一样,更改就行
sudo apt install ./sdkmanager_1.8.0-10363_amd64.deb
完成后运行
sdkmanager
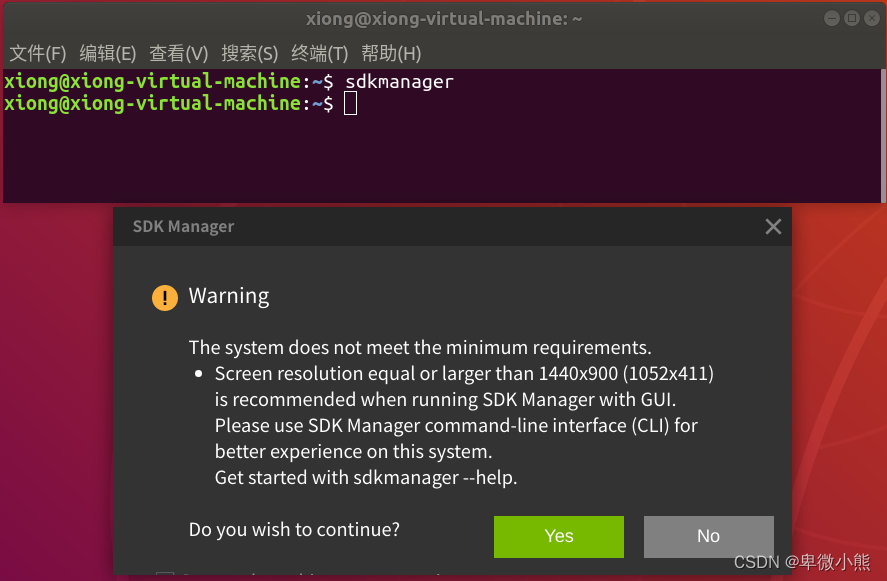
在我运行后有一个警告,说是屏幕的分辨率的问题,不用理会直接yes
然后要进行登录,我是直接使用微信登录
然后有个隐私声明,看个人情况选择
完成后就等他的进度条走完,然后跳出了选择设备信息

然后我使用了一个数据线连接了主机与电脑的虚拟机内

这里要求的是要用有指示灯的Typc-C接口,并且使用购买时自带的数据线
在程序中能够看到了已经识别到了主机
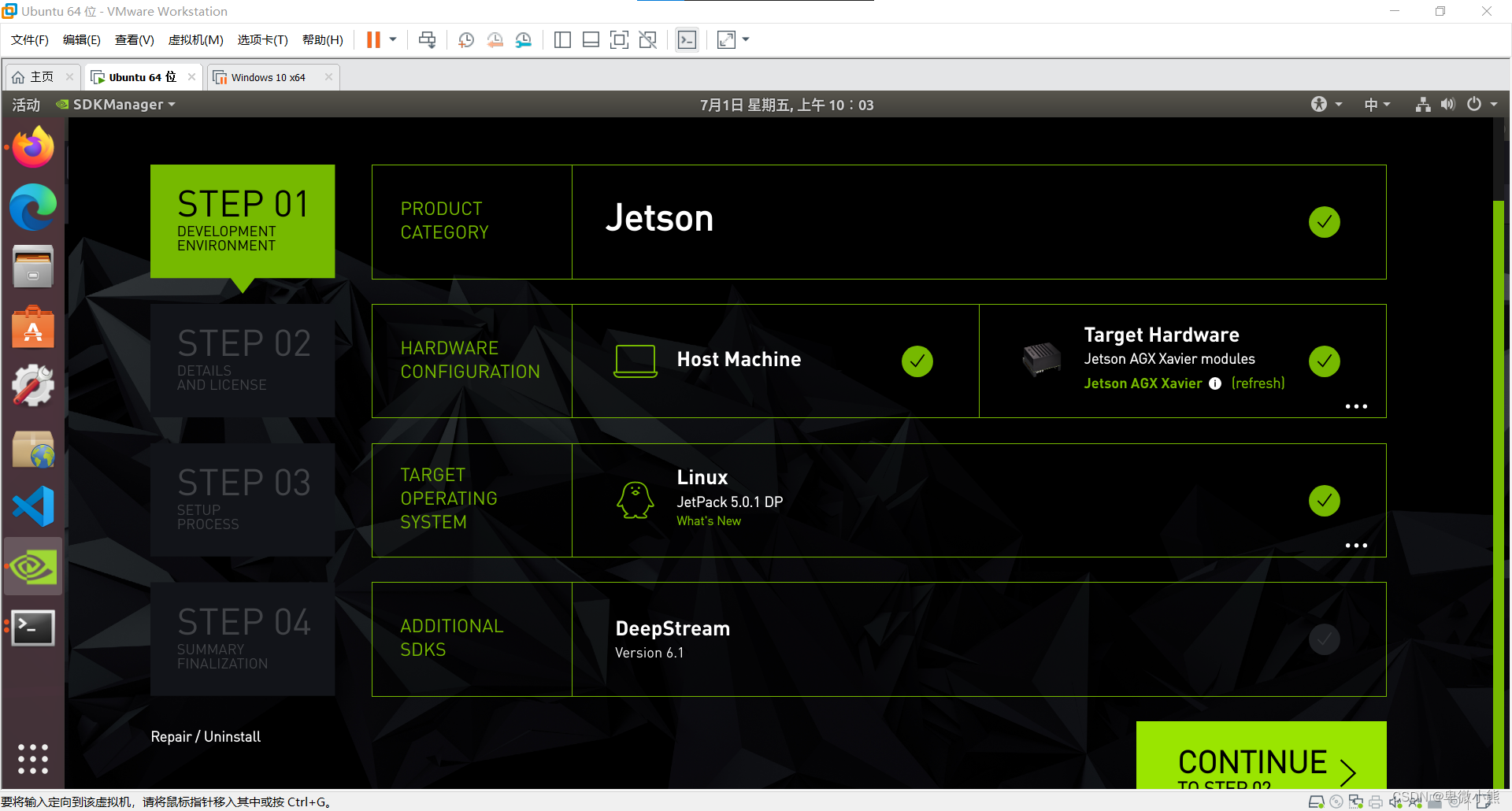
然后我这里选择了4.5.1的版本

完成后点击continue,下一步
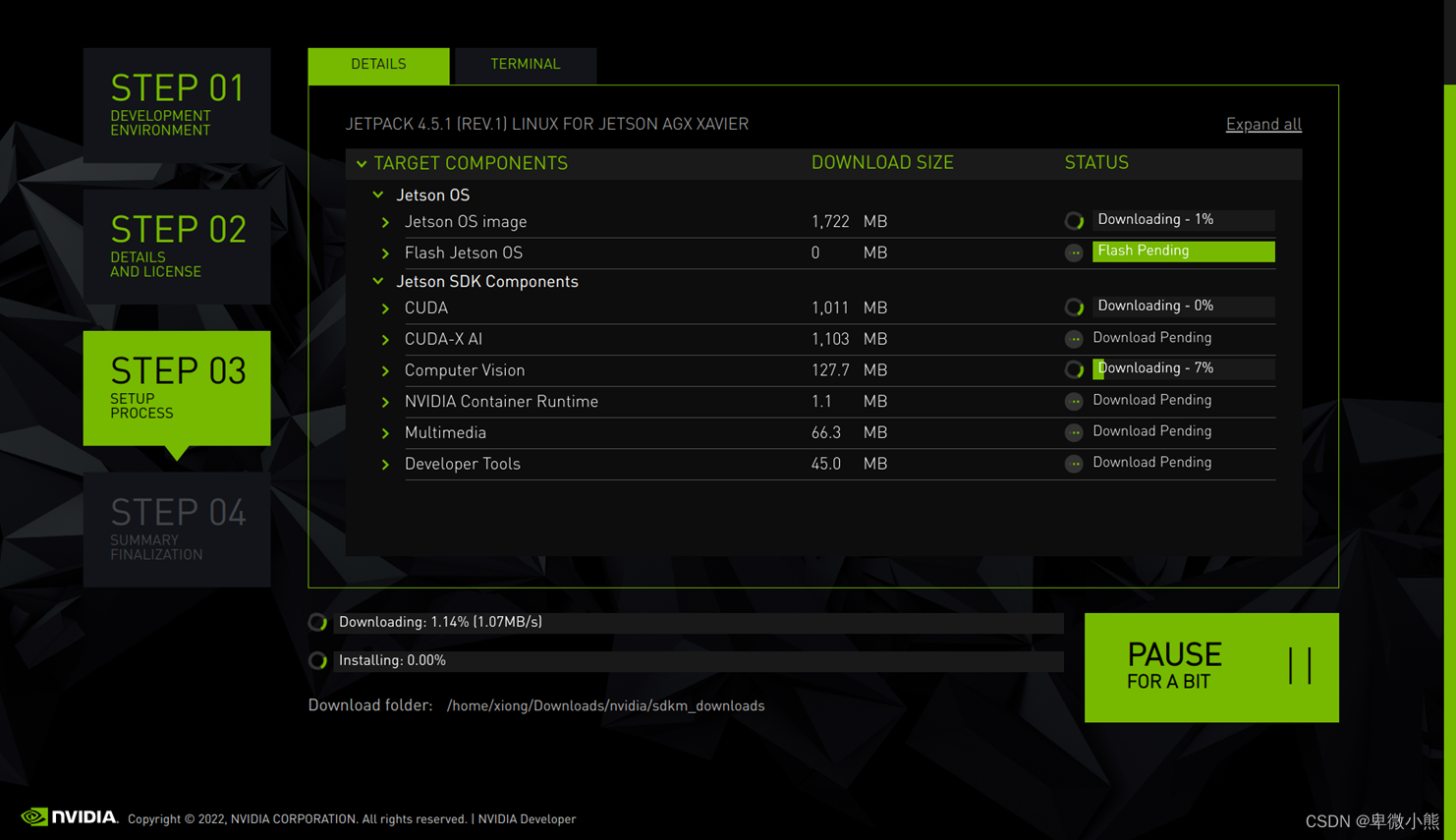
然后可以看到它即将安装的各个组件
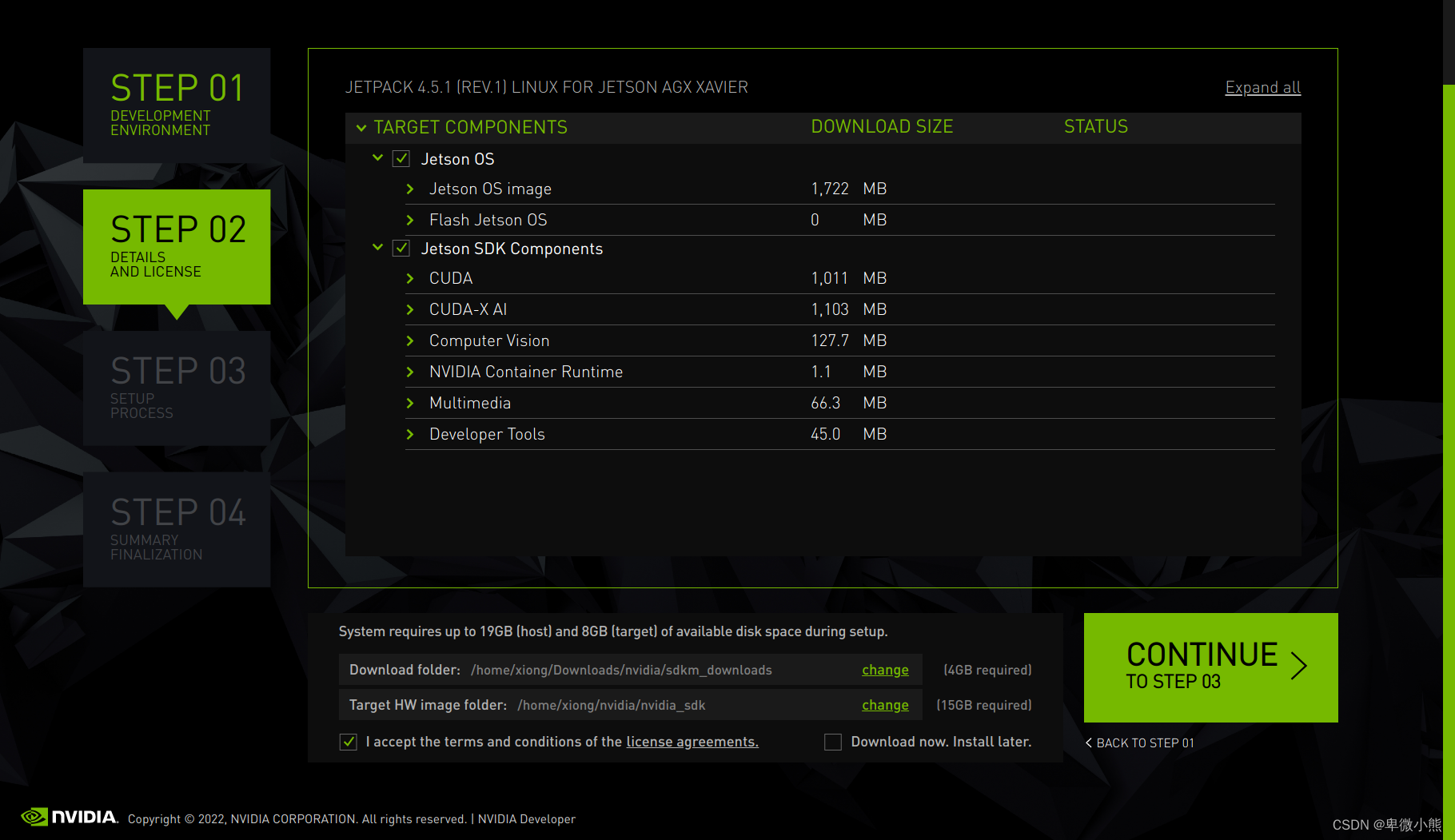
安装的位置我这里直接默认路径
然后创建文件目录
然后就是密码
出了个验证信息,稍微等等
然后开始下载
等待一会后,程序会跳出一个新的窗口,这里选择【Manual Setup】也就是手动模式
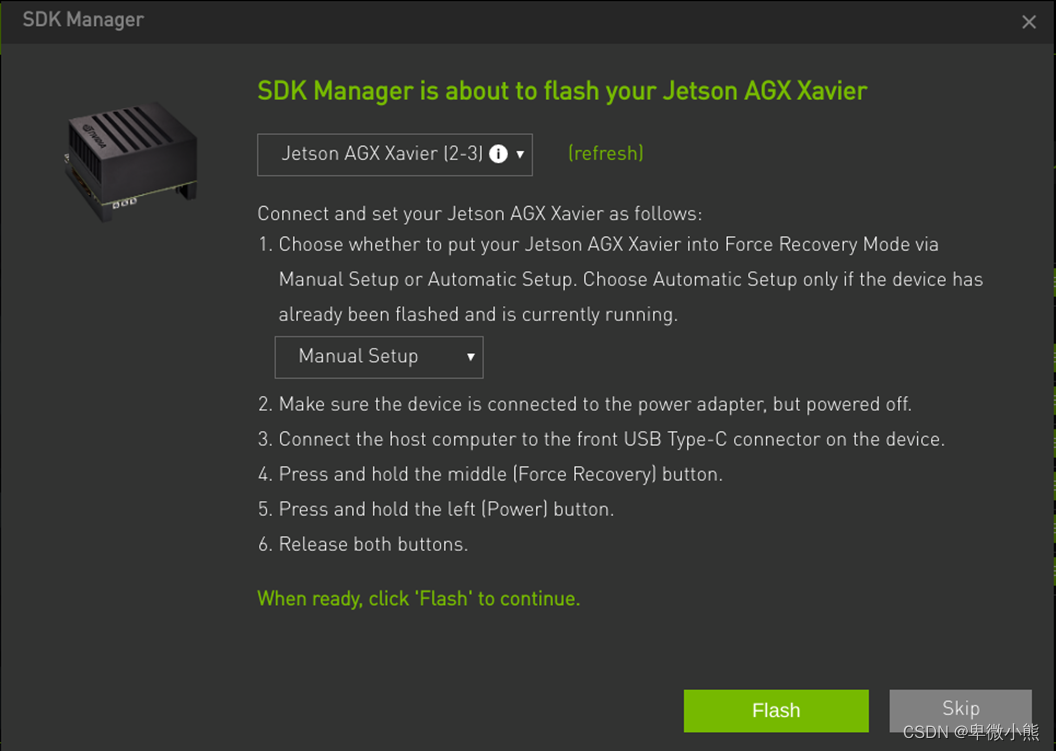
根据程序提示的步骤如下操作:
使用Type-C转USB数据线将 Xavier 与宿主电脑连接
将 Xavier 插上电源,并处于关机状态
点击Flash,准备刷机
按下并保持 Xavier 上的【Recovery】键(中间的键)
按下并保持【Power】键(最左边的键),持续1s,然后同时松开这两个键,进入刷机模式。
当让主机变成刷机模式后,可以使用命令查看,如果看到 NVidia Corp 则说明 xavier 与host端,也就是两者连接成功
lsusb
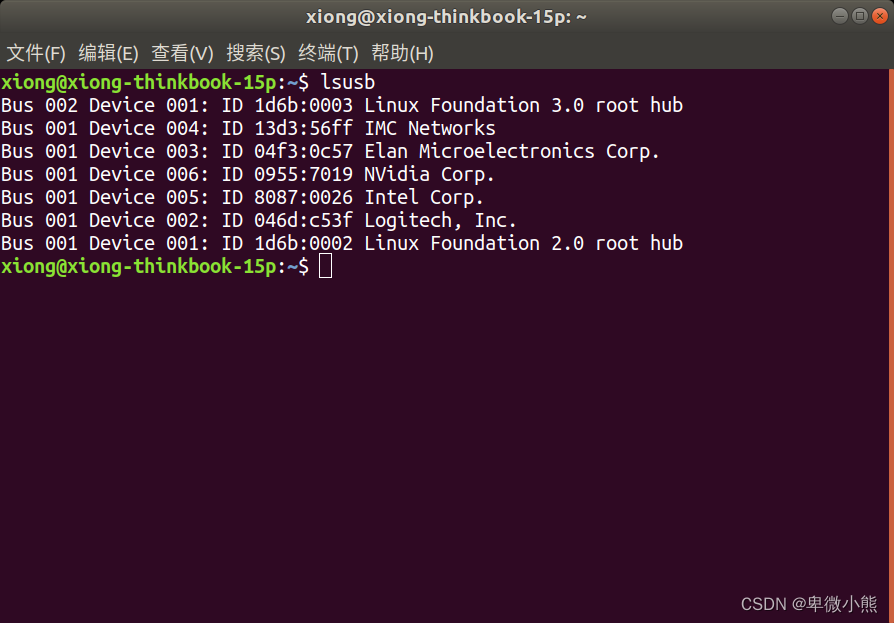
大概会在进度条一半的时候,AGX会自己启动,这时候就可以正常的进行系统的初始化,然后就设置主机,用户名密码,区域与语言等等
到这里我们要给AGX重新设置并更新源
首先备份sources.list文件
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
打开sources.list文件
sudo gedit /etc/apt/sources.list
删除原内容,添加下列内容
#中科大源
deb http://mirrors.ustc.edu.cn/ubuntu-ports/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu-ports/ bionic-updates main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu-ports/ bionic-security main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu-ports/ bionic-security main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu-ports/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.ustc.edu.cn/ubuntu-ports/ bionic-backports main restricted universe multiverse
deb http://mirrors.ustc.edu.cn/ubuntu-ports/ bionic main universe restricted
deb-src http://mirrors.ustc.edu.cn/ubuntu-ports/ bionic main universe restricted
保存sources.list文件后需要更新apt-get
sudo apt-get update
当烧录完镜像后,
输入刚才在 xavier 上设置的用户名和密码
确保主机和 xavier 连接在同一个局域网中,最好的方法是使用网线将两个设别连接到同一个路由器中
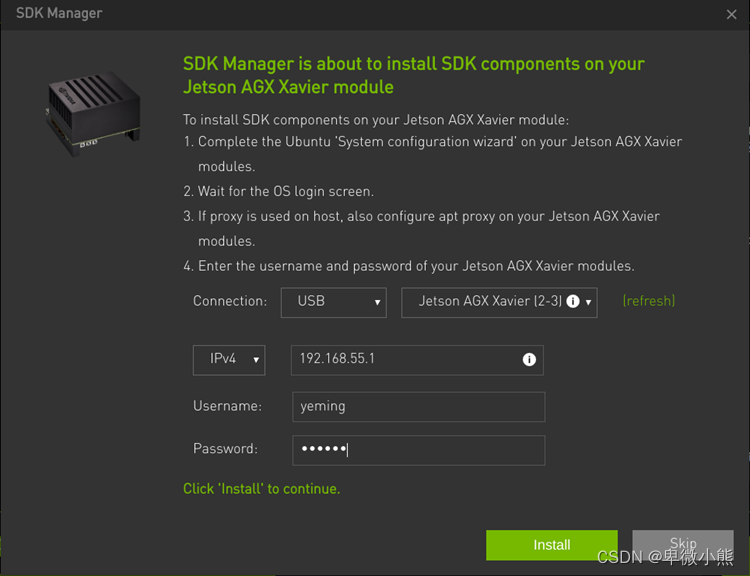
然后就是漫长的等待,最终完成
SSD的安装
到这里就可以重新启动AGX,AGX内部也就是一个完整的系统了
但是现在整个主机的存储是eMMC,大约30G,完全不够用,所以安装SSD
首先将所有的连接到AGX的线束断开
将整个主句背面朝上,然后将图片中这四个螺丝拆下

然后根据图片的箭头一边左右晃,一边拔出主板

拔出主板的时候要注意,有一个应该是给到散热风扇的供电线,不要给拔断了

主板翻过来后就可以看到空着的M.2 NVMe接口
然后将新买的SSD安装上去,这里我选择的是128G的SSD

完成后根据安装的位置重新盖回去

完成后就可以启动了,但是启动的是在eMMC上
所以需要进行rootOnNVMe的流程,以将 rootfs 指向安装在 /dev/nvme0(M.2 Key M 插槽)上的 SSD
rootOnNVMe
跟着流程走就行
然后要注意啊,原本的eMMC,就不用管它了,不然可能会发生以下的情况
对于Xavier ,仍然需要安装SD卡才能启动。Jetson Xavier 的默认配置不允许从 NVMe 直接引导。这个有在rootOnNVMe的流程中提到
当rootOnNVMe的流程走完后,重新启动应该就可以从SSD使用了
那么【NVIDIA Jetson AGX Xavier主机刷机与SSD安装】大致流程就是这样
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)