本文主要用于解释一些在深度学习中常见的名词,重点参考了博客:
https://towardsdatascience.com/generalization-regularization-overfitting-bias-and-variance-in-machine-learning-aa942886b870#:~:text=Generalization%20is%20low%20if%20there,between%20training%20and%20validation%20loss.&text=Regularization%20is%20a%20method%20to,keep%20coefficients%20close%20to%20zero.
(31条消息) 深度学习常见名词概念:Sota、Benchmark、Baseline、端到端模型、迁移学习等的定义_HanZee的博客-CSDN博客_sota
感谢前辈!
Benchmark &Baseline:
Benchmark 和 Baseline 比较容易混淆,二者的目的都是为了和已经存在的project 进行比较,个人理解benchmark 是用于比较的指标,而baseline是对需要比较的已存在的业界项目进行复现的过程,也就是说baseline是你在某个时点某个环境中重新运行代码,成功运行后你会得到一些metrics(也就是AUC, Accuracy, loss等),然后这些metrics就是目前业界的benchmark,用于和改进后的代码进行比较,看看在某个参数上是提升了还是下降了。
SOTA
state of the arts 的简写,目前业界最顶尖的的,有best performance的Method或者model
End to End
端到端的,end to end deep learning is a process seeks to directly map the input to the output, 把整个系统(包括输入层和输出层)看作一个单独的整体的神经网络,训练的时候只需要在意输入端和输出口的结果,通过学习调节模型内部的参数。
Generalization
泛化, 如果training loss 的确在训练中衰减,那么我们可以引入validation loss来验证数据集的学习是否真的奏效了,这个时候我们需要用一个新的数据集输入到模型中,计算它是否也会随着迭代减少loss, 这个过程就是泛化(generalization)
Regulation
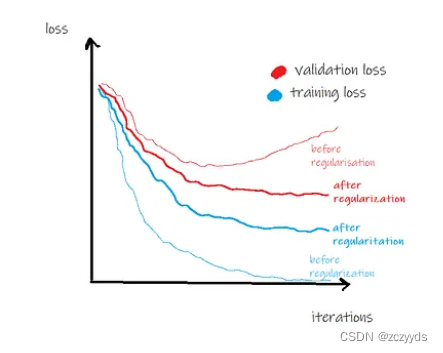
正则化是一种避免高方差(high variance)和过度拟合(overfitting)以及增加泛化(generalization)的方法。在不涉及细节的情况下,正则化的目的是使系数接近于零。直观地说,模型所代表的函数更简单,不那么不稳定。Regularization can be as simple as shrinking or penalizing large coefficients — often called weight decay
Supervised and Semi-Supervised Learning:
监督学习是机器学习的一种类型,在这种学习中,一个模型在标记的数据上被训练来进行预测和分类。该模型被提供给一组标记的数据点,其中每个都属于一个特定的类别。在训练过程中,模型能够学习数据的结构以及相关的标签和模式,以便准确地对未见过的数据做出预测.
Semi-supervised learning is a combination of supervised and unsupervised learning. It leverages both labeled(带有标签的数据) and unlabeled data(没有打上标签的数据) to train a model to make predictions。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)