最近在翻阅文本生成图像的相关工作,目前比较新的有突破性的工作是李飞飞工作团队18年cvpr发表的《Image Generation from Scene Graphs》 。
论文地址:https://arxiv.org/abs/1804.01622
源码地址: https://github.com/google/sg2im
这篇主要就是介绍该论文的工作,穿插对部分代码的理解和讲解。看完代码以后拜服Justin Johnson大神,真厉害!
一、相关工作
先前已经有了很多文本生成图像的方法,比较具有代表性的是StackGAN和StackGAN++(会在其它博客中给出介绍)。StackGAN存在的比较突出的问题是不能处理比较复杂的文本。比如句子为:A sheep by another sheep standing on the grass with sky above and a boat in the ocean by a tree behind the sheep.
结果如下图所示:


左图是StackGAN生成的结果,右图是李飞飞小组提出的新方法的结果。右边的效果明显更好。
二、基本思想
不同于先前的方法,李飞飞小组提出可以使用场景图作为中间媒介。即由原本的
文本----->图像(也就是RNN+GAN的直接搭配)
转化为
文本--→场景图--→图像。
首先的问题是:什么是场景图,场景图怎么得到?
场景图是一种可以用来表示文本或者图像结构的表述。如图二所示,即为图一所对应的文本的场景图。
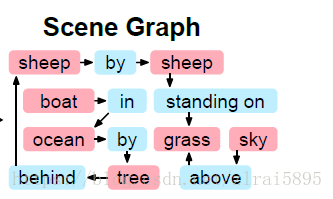
可以看到,场景图将场景表示为有向图,其中节点(红色)是对象,边(蓝色)给出对象之间的关系。
关于场景图的获取:一些数据集中提供了与图像配套的场景图,例如Visual Genome数据集。大部分场景图的工作都是基于此数据集的。第二种方法是使用句子或者图像直接生成场景图。从句子中生成的场景图的工作有:《Generating Semantically Precise Scene Graphs from Textual Descriptions for Improved Image Retrieval》。从图像中生成场景图的工作有:《Visual relationship detection with language priors》 、 《Pixels to graphs by associative embedding》 、《Scene graph generation by iterative message passing》、《On support relations and semantic scene graphs》。这里暂时不做详细的介绍。
获得场景图之后,后续的处理如下图所示:
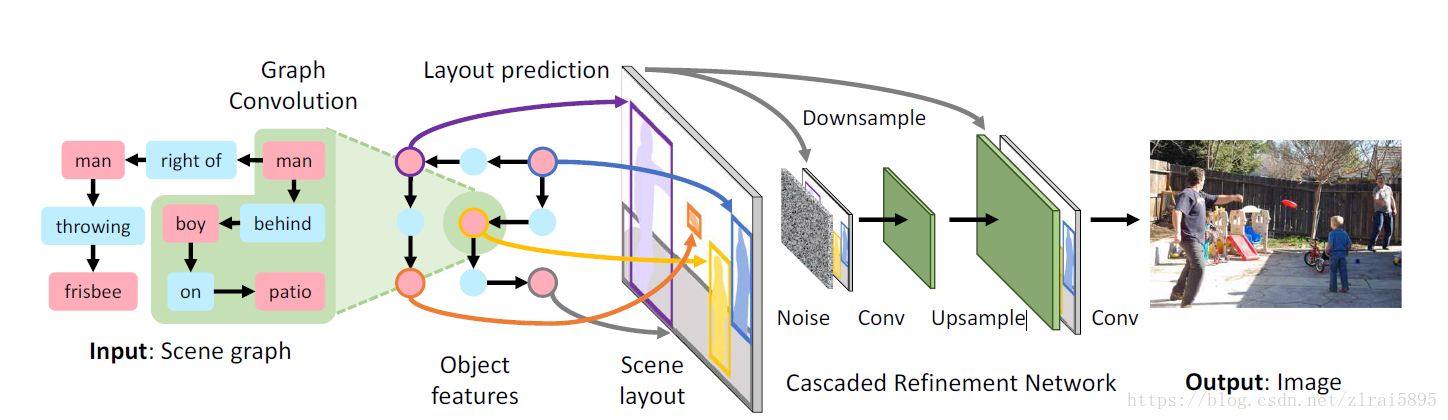
首先将场景图(Scene graph)输入图卷积网络(Graph Convolution)获得对象的嵌入向量(Object features)(嵌入向量是什么,后续有解释)。获得的嵌入向量输入对象布局网络。对象布局网络预测对象的bounding boxes和segmentation masks。得到scene layout(场景布局)。将其输入级联细化网络(Cascaded Refinement Network)得到最后的输出图像。
每个模块的具体实现会在后面配合代码进行介绍。这里给出嵌入向量的概念:我们使用不同的向量来表示不同的对象(词汇),最直接的做法是使用one-hot的形式,但是当词库特别大,词向量会十分冗长。而且两个关系很接近的词汇对应的向量(比如 “国王”和“王后”)之间的关系并不能通过one-hot的词向量表示出来。
所以引入嵌入向量(词嵌入)来表示不同对象。首先,它也是一个向量,但是长度比较短,而且是一个密集向量。其次,它可以表示关系相近的对象之间的关系(比如“国王”-“男人”+“女人”约等于“王后” ) 这种关系是通过距离表现出来的。比如“猫”和“狗”向量之间的距离比较近,但是“猫”和“天空”距离就比较远。
三、数据集介绍
在介绍具体的模型结构前,我们先介绍一下实验中用到的数据集。源码中可选的数据集有两个:Visual Genome数据集和COCO数据集。
- Visual Genome数据集
Visual Genome 数据集包括 7 个主要部分:
区域描述 --------对图像的不同区域进行描述。这些区域是由边框坐标限定的,区域之间允许有重复。数据集中平均对每一张图片有 42 种区域描述。每一个描述都是一个短语包含着从 1 到 16 单词长度,以描述这个区域。
对象---------------平均每张图片包含21个物体,每个物体周围有一个边框。
属性---------------平均每张图片有16个属性。一个物体可以有0个或是更多的属性。属性可以是颜色(比如yellow),状态(比如standing),等等。
关系----------------“关系”将两个物体关联到一起。
区域图-------------将从区域描述中提取的物体、属性、以及关系结合在一起。表述该区域
场景图-------------一整幅图片中所有的物体、属性、以及关系的表示
问答对-------------每张图片都有两类问答:基于整张图片的随意问答(freeform QAs),以及基于选定区域的区域问答(region-based QAs)。在本实验中用不到,所以不做过多解释。
此外,每一个对象、属性、关系在WordNet中都有自己规范化的ID。
- COCO数据集
COCO的数据标注信息包括:
- 类别标志
- 类别数量区分
- 像素级的分割
2014年版本的数据为例,一共有20G左右的图片和500M左右的标签文件。标签文件标记了每个segmentation+bounding box的精确坐标,其精度均为小数点后两位。一个目标的标签示意如下:
{"segmentation":[[392.87, 275.77, 402.24, 284.2, 382.54, 342.36, 375.99, 356.43, 372.23, 357.37, 372.23, 397.7, 383.48, 419.27,407.87, 439.91, 427.57, 389.25, 447.26, 346.11, 447.26, 328.29, 468.84, 290.77,472.59, 266.38], [429.44,465.23, 453.83, 473.67, 636.73, 474.61, 636.73, 392.07, 571.07, 364.88, 546.69,363.0]], "area": 28458.996150000003, "iscrowd": 0,"image_id": 503837, "bbox": [372.23, 266.38, 264.5,208.23], "category_id": 4, "id": 151109}
四、模型结构
依旧先上这张整体结构图。;另外,下文提到的向量具体数值均是为了便于理解,并不完全与代码运行后的实际数值相同。
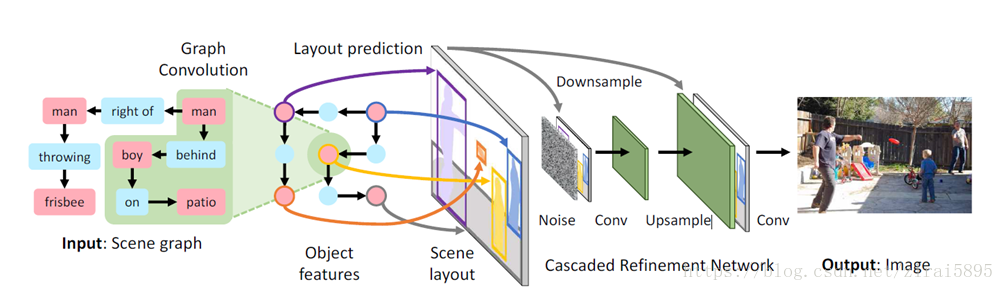
-
图卷积网络(GCN)
由Thomas Kpif于2017年在论文《Semi-supervised Classification with Graph Convolutional Networks》。Thomas Kpif的这篇论文属于谱卷积,即将卷积网络的滤波器与图信号同时搬移到傅里叶域以后进行处理。
原论文没看太懂,数学推导可以参https://blog.csdn.net/chensi1995/article/details/77232019值得注意的是,图嵌入(graph embedding)、网络嵌入(network embedding)、网络表示学习(network representation learning),这三个概念从原理上来说其实表达的是同一件事,核心思想就是“通过深度学习技术将图中的节点(或边)映射为向量空间中的点,进而可以对向量空间中的点进行聚类、分类等处理”。图卷积神经网络就属于图嵌入技术的一种。
也就是说,图卷积网络的目的是把对象(节点)、关系(边)映射为嵌入向量。
具体原理可以参考https://blog.csdn.net/tMb8Z9Vdm66wH68VX1/article/details/78705916。 为方便后续理解,这里给出部分内容的截图。

Hl 即为第l个隐含层,H0
即为第l个隐含层,H0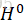 就是输入层。
就是输入层。

可以看到GCN可以有一到多层。
下面分析源码:
首先读取场景图,在代码中场景图的表示是一个由若干字典组成的列表。一幅图像可能有一到多个场景图表述。
字典有两个key: 'objects' 和'relationships' 。这里给出一个scene graph:{'objects': ['sky', 'grass', 'zebra'], 'relationships': [[0, 'above', 1], [2, 'standing on', 1]]}。对于拥有多个字典(场景图)的列表(图像),在列表中从前到后字典逐渐变复杂,对象数目和关系数目增多。在relationship的列表中,目标用索引表示。一幅图像中有N个目标,则在所有的字典中,目标的索引从0到N-1。
场景图的处理是encode_scene_graphs函数。函数输入是单个场景图的字典或者包含了多个字典的列表,输出是元组(objs, triples, obj_to_img)。之前讲到在VG数据集中,所有的对象、属性、关系都有规范化的索引,我们暂且称之为词库索引。objs, triples, obj_to_img都是 列表,objs表示所有所有场景图中出现的所有目标的词库索引,triples表示所有场景图中每一张场景图中目标之间的关系,obj_to_img与objs长度相同,用于标注哪些目标属于哪些场景图。比如:
objs:[11, 17, 130, 0, 11, 17, 129, 0] 最后用0来代表'__image__'
triples:[[0, 4, 1], [2, 19, 1], [0, 0, 3], [1, 0, 3], [2, 0, 3], [4, 4, 5]]
obj_to_img:[0, 0, 0, 0, 1, 1, 1, 1,…..N] 总共有N个场景图
相关代码:
def encode_scene_graphs(self, scene_graphs):
"""
Encode one or more scene graphs using this model's vocabulary. Inputs to
this method are scene graphs represented as dictionaries like the following:
{
"objects": ["cat", "dog", "sky"],
"relationships": [
[0, "next to", 1],
[0, "beneath", 2],
[2, "above", 1],
]
}
This scene graph has three relationshps: cat next to dog, cat beneath sky,
and sky above dog.
Inputs:
- scene_graphs: A dictionary giving a single scene graph, or a list of
dictionaries giving a sequence of scene graphs.
Returns a tuple of LongTensors (objs, triples, obj_to_img) that have the
same semantics as self.forward. The returned LongTensors will be on the
same device as the model parameters.
"""
if isinstance(scene_graphs, dict):
# We just got a single scene graph, so promote it to a list
scene_graphs = [scene_graphs]
objs, triples, obj_to_img = [], [], []
obj_offset = 0
for i, sg in enumerate(scene_graphs):#对于单幅图像 有好几个场景图 每次进一个场景图
# Insert dummy __image__ object and __in_image__ relationships
sg['objects'].append('__image__')
image_idx = len(sg['objects']) - 1
for j in range(image_idx):
sg['relationships'].append([j, '__in_image__', image_idx])
#首先是对场景图进行处理,除了原本的目标以外,加入新的目标 ,也就是总体的'__image__'
#加入了新的目标,就需要更新关系列表 也就是 之间的每一个目标 都'__in_image__'在图像里
#举例:sg['objects']:['sky', 'grass', 'sheep', '__image__']
#sg['relationships']: [[0, 'above', 1], [2, 'standing on', 1], [0, #'__in_image__', 3], [1, '__in_image__', 3], [2, '__in_image__', 3]]
#0 1 .....len(sg['objects']) - 2 分别是原图中目标的索引
#image_idx = len(sg['objects']) - 1 是image的索引
for obj in sg['objects']:
obj_idx = self.vocab['object_name_to_idx'].get(obj, None) #获取场景图中目标对应的词库索引
if obj_idx is None:
raise ValueError('Object "%s" not in vocab' % obj)
objs.append(obj_idx) #对应的词库索引 最后用0来代表'__image__' [11, 17, 130, 0, 11, 17, 129, 0]
obj_to_img.append(i) #用于标注 对于当前的图像 这是第几个场景图 [0, 0, 0, 0, 1, 1, 1, 1]
for s, p, o in sg['relationships']:
pred_idx = self.vocab['pred_name_to_idx'].get(p, None) #获取关系对应的词库索引
if pred_idx is None:
raise ValueError('Relationship "%s" not in vocab' % p)
triples.append([s + obj_offset, pred_idx, o + obj_offset])#描述目标之间的关系 不同场景图的不同目标 用不同的索引标注
#[[0, 4, 1], [2, 19, 1], [0, 0, 3], [1, 0, 3], [2, 0, 3], [4, 4, 5], [6, 19, 5], [4, 0, 7], [5, 0, 7], [6, 0, 7]]
obj_offset += len(sg['objects'])
device = next(self.parameters()).device
objs = torch.tensor(objs, dtype=torch.int64, device=device)#所有场景图中出现的所有目标的词库索引
triples = torch.tensor(triples, dtype=torch.int64, device=device) #所有场景图中每一张场景图中目标之间的关系
obj_to_img = torch.tensor(obj_to_img, dtype=torch.int64, device=device)# 标注哪些目标属于哪些场景图
return objs, triples, obj_to_img
将对象和关系使用128维的词嵌入表示,将其输入图卷积网络,得到嵌入向量。
相关代码:
obj_vecs = self.obj_embeddings(objs) #[42,128] 将每个目标用128维的嵌入向量表示
obj_vecs_orig = obj_vecs
pred_vecs = self.pred_embeddings(p) #[63,128] 将每种关系也用128维的嵌入向量表示
if isinstance(self.gconv, nn.Linear): #如果没有设计场景图卷积网络 而是直接加了全连接层
obj_vecs = self.gconv(obj_vecs) #得到128维度的输出向量
else:
obj_vecs, pred_vecs = self.gconv(obj_vecs, pred_vecs, edges) #如果只有一层
if self.gconv_net is not None:
obj_vecs, pred_vecs = self.gconv_net(obj_vecs, pred_vecs, edges)
#如果有多层 就把刚才那一层的输出作为输入
#[42,128] [63,128] 这里42是对象的数量 63是关系的数量
2、 对象布局网络
对象布局网络由两部分组成,一部分是Mask regression network,一部分是Box regression network,如下图所示:

(1)预测对象的bounding_box:
使用一个多层感知器来实现。包含有三层,实验中输入层是128的对象嵌入向量,隐藏层的维度取了512,输出层是4维向量,对每个对象的嵌入向量,得到bouding_box的坐标。
代码:
boxes_pred = self.box_net(obj_vecs) #[42,4] 对于每个对象 预测它们的bounding_box
(2)预测mask:
建立一个mask_net来预测mask。网络的输入是所有场景图中所有对象的嵌入向量。例如一共由42个对象,输入为[42,128,1,1],输出为16*16的mask_pre[42,1,16,16],也就是每个对象的binary masks。网络中主要进行了上采样、卷积等操作。如下列代码所示:
代码:
masks_pred = None
if self.mask_net is not None:
mask_scores = self.mask_net(obj_vecs.view(O, -1, 1, 1))#输入[42,128,1,1]输出[42,1,16,16]
#对于每个对象产生16*16的图像 O是对象的总数目
masks_pred = mask_scores.squeeze(1).sigmoid() #[42,16,16]
def _build_mask_net(self, num_objs, dim, mask_size): #将128维的图像变为1维的mask
output_dim = 1
layers, cur_size = [], 1
while cur_size < mask_size:
layers.append(nn.Upsample(scale_factor=2, mode='nearest'))#上采样图像成原来的四倍(长宽2倍)
layers.append(nn.BatchNorm2d(dim))
layers.append(nn.Conv2d(dim, dim, kernel_size=3, padding=1))
layers.append(nn.ReLU())
cur_size *= 2
if cur_size != mask_size:
raise ValueError('Mask size must be a power of 2')
layers.append(nn.Conv2d(dim, output_dim, kernel_size=1)) #最后的输出图像是单通道的layout
return nn.Sequential(*layers)
(3)bounding_box和mask结合生成图像布局
作者设计了masks_to_layout网络来实现这一功能。输入是obj_vecs, layout_boxes, layout_masks, obj_to_img以及 想要产生的图像布局的尺寸H, W。输出是[N,D,H,W]的形式。
N是要生成的图像batch大小,H,W是尺寸,D是通道数。具体结构原理没看太懂。
如下列代码所示:
layout = masks_to_layout(obj_vecs, layout_boxes, layout_masks,
obj_to_img, H, W)
#输入: obj_vecs[42,128] layout_boxes[42,4] layout_masks[42,16,16]
#obj_to_img[42] H:128 W:128
#layout:[7,128,128,128]
3、级联网络
级联网络来自论文《Photographic image synthesis with cascaded refinement networks》。在得到layout([7,128,128,128])后,作者引入了layout_noise([7, 32, 128, 128]),与其结合成([7, 160, 128, 128])输入级联网络,得到最终的三通道彩图。
级联网络并没有依靠生成对抗网络(GAN)以训练generator与discriminator network的方式来做image-to-image,而是采用了一种级联精练网络Cascaded Refinement Network (CRN)来实现逼真街景图的生成。每个模块接收两个场景布局作为输入,即下采样到模块的输入分辨率和来自前一个模块的输出。这些输入通道连接并传递给一对3*3卷积层; 然后在传递到下一个模块之前使用最近邻插值对输出进行上采样。 第一个模块采用高斯噪声z~ pz作为输入,并且来自最后一个模块的输出被传递到两个最终的卷积层以产生输出图像。
具体的代码模块比较多,这里就不再给出介绍。

代码:
img = self.refinement_net(layout) #输入[7, 160, 128, 128] 输出[7, 3, 128, 128]
至此,模型结构部分介绍完毕。
五、训练
模型使用一对鉴别器网络 和
和 训练图像生成网络f来生成逼真的输出图像。
训练图像生成网络f来生成逼真的输出图像。 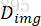 确保生成的图像的整体外观是真实的;
确保生成的图像的整体外观是真实的; 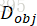 确保图像中的每个对象看起来都是真实的;它的输入是一个对象的像素,使用双线性插值裁剪并重新缩放到固定大小。除了将每个对象分类为真实或虚假之外,
确保图像中的每个对象看起来都是真实的;它的输入是一个对象的像素,使用双线性插值裁剪并重新缩放到固定大小。除了将每个对象分类为真实或虚假之外, 还确保使用辅助分类器来识别每个对象,该分类器预测对象的类别。
还确保使用辅助分类器来识别每个对象,该分类器预测对象的类别。
我们联合训练图像生成网络f、鉴别器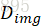 和
和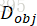 。我们试图最小化6个损失的加权和。
。我们试图最小化6个损失的加权和。
Box loss预测对象的位置信息,惩罚真实对象位置与预测位置的误差。
Mask loss pixelwise cross-entropy使用像素交叉熵惩罚地面实况和预测掩模之间的差异; 不用于在Visual Genome上训练的模型。
Pixel loss惩罚GT图像与生成图像之间的L1差异。
Image adversarial loss鼓励生成的图像整体看起来更真实。
Object adversarial loss 鼓励生成的对象看起来更真实。
Auxiliarly classifier loss确保每一个对象都能够被Dobj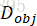 识别。
识别。
训练部分的代码涉及鉴别器和生成器,6种损失,比较复杂(再次膜拜大神),这里就不给出详细的代码理解,只写一下训练主函数的基本流程。
- 搭建train_loader, val_loader用于加载训练数据和验证集数据。
- 建立模型和优化器
- 建立对象鉴别器,建立图像鉴别器
- 建立两个函数gan_g_loss, gan_d_loss分别用于计算生成器和鉴别器损失。其中gan_d_loss输入为真实图像与假图像 或者真实对象与假对象,输出为鉴别器损失。
- 针对对象鉴别器和图像鉴别器分别建立优化器
- 加载对象鉴别器和图像鉴别器权重(如果有)
- 开始迭代优化各个损失的加权和。(这一过程的实现还是挺复杂的)
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)