Learning Deep Features for Discriminative Localization
文章目录
- Learning Deep Features for Discriminative Localization
- 摘要
- 1 引言
-
- *2 类激活图(Class Activation Mapping,CAM)
- 3 弱监督目标定位
-
- 4 用于通用定位的深度特征
-
- 5 可视化特定类别的单位
- 6 总结
摘要
- 回顾全局平均池化GAP仅在图像标签级别上训练就有显示CNN局部化能力,实际上建立了通用的定位深层表示
- 本文网络能定位各类任务中图像中的区别性区域,即使不是专门训练
1 引言
卷积层的卷积单元可以当作是目标检测器,即使是在无目标位置的监督时。全连接层的使用丧失了这种能力。
在训练过程中,使用GAP作结构正则器避免过拟合来实现这种功能。GAP在正则器外还有其他优点。实际上,只需稍作调整,网络就可以保留其出色的定位能力,直到最后一层。 通过这种调整,可以轻松地在一次正向传递中识别出可区分的图像区域,以完成各种各样的任务,甚至包括那些最初不是针对网络进行训练的任务。
相关研究
在仅图像标签级别的训练下,卷积神经网络也有出色的定位目标的能力
弱监督目标定位,卷积神经网络中的
global max pooling,受限于目标边界点,均值池化更好一点。
本文使用 类激活图(class activation map, CAM) 来指代为每个图像生成的加权激活图。
卷积神经网络内部可视化
*2 类激活图(Class Activation Mapping,CAM)
使用全局均值池化生成CAM的步骤:网络主要由卷积层组成,并且在最后的输出层之前, 在卷积特征图上进行全局平均池化,用于全连接层。可以通过将输出层的权重投影到卷积特征图上来识别图像区域的重要性,该技术称为类激活映射(class, activation mapping)。
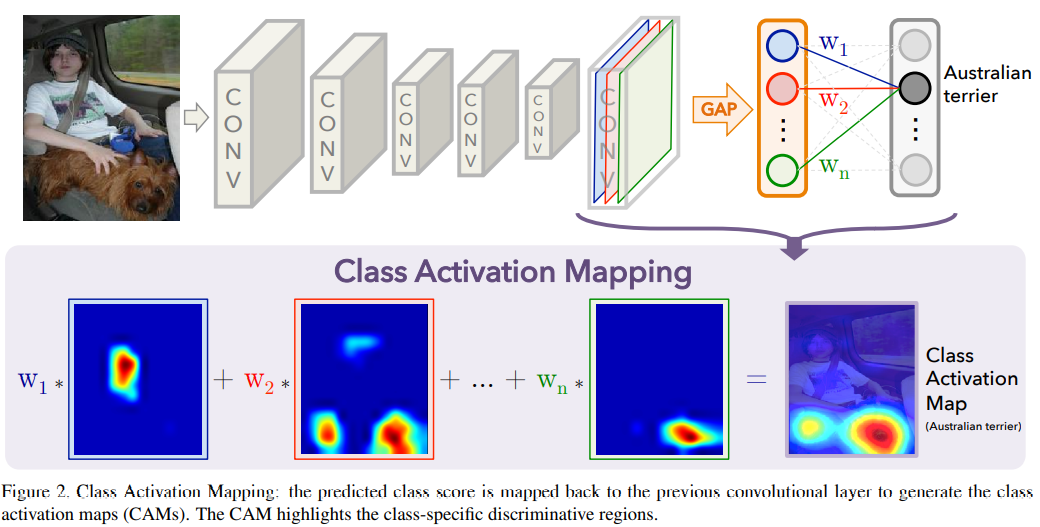
最后一个卷积层输出做全局平均池化得到特征图的空间平均值,这些值的加权和用于生成最终输出。类似地,计算最后一个卷积层的特征图的加权和,获得类激活图CAM。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-orjJUNXr-1618045987224)(https://gitee.com/zhuyu2//personal-drawing-bed-2/raw/master/img/20210410171218.jpg)]
各种类别的图像的区别性区域都被高亮显示。对于同一图片,被分成不同类别得到的CAM不一样。
GAP vs GMP(最大值池化,global max pooling)
GAP和GMP之间的直观区别:
- 与GMP相比,GAP损失鼓励网络确定对象的范围,而GMP鼓励仅识别一个区别性部分。 这是因为,当对图进行平均时,区别部分最大化该值,低激活部分降低该值
- 对于GMP,所有图像区域的最低得分(最具区分性的得分除外)都不会影响得分。通过实验进行了验证,尽管GMP的分类性能与GAP相似,但在定位方面GAP优于GMP。
3 弱监督目标定位
3.1 实验设置
AlexNet、VGG、GooLeNet。作者发现,当GAP之前的最后一个卷积层具有较高的空间分辨率时,即所谓的映射分辨率,网络的定位能力得到了提高。因此在网络中删除了几个卷积层,又加了卷积层最后加上GAP。
(看Pytorch中的三个网络的源码,self.avgpool=self.avgpool = nn.AdaptiveAvgPool2d((6, 6)),self.avgpool = nn.AdaptiveAvgPool2d((7, 7))和self.avgpool = nn.AdaptiveAvgPool2d((1, 1)),分类时多了展开操作x = torch.flatten(x, 1))
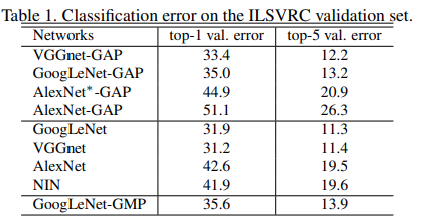
3.2 实验结果
分类
对网络进行变更后有1-2个百分点分类性能的下降。(AlexNet*-GAP是加了两个卷积层)
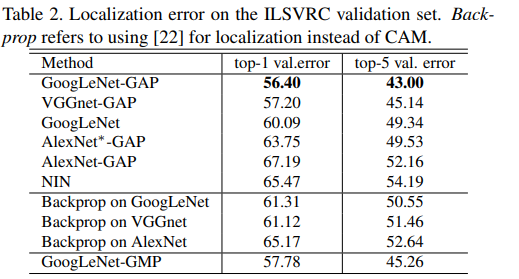
定位
生成边界框,为了从CAM生成边界框,使用一种简单的阈值化技术来分割热图。分割出值高于CAM最大值20%的区域,然后,将边界框覆盖在分割图中,该连接框最大(可以覆盖最大连通分支的最小矩形区域)。
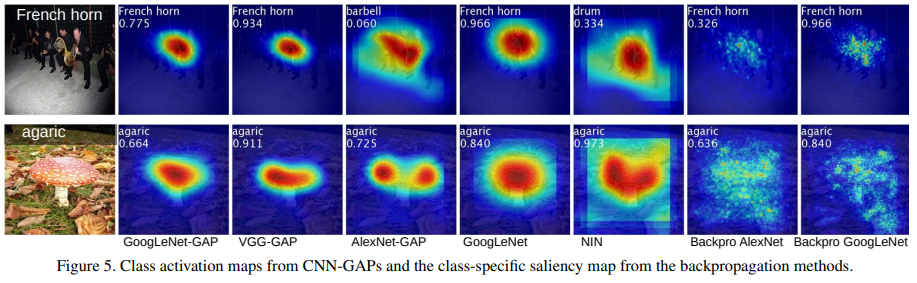

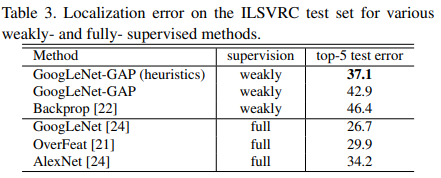
4 用于通用定位的深度特征
CNN较高层的响应已被证明是非常有效的通用功能,并且在各种图像数据集上均具有最先进的性能。 作者证明经GAP CNN所学习的功能也具有良好的通用功能,并且可以识别用于分类的可辨别图像区域,即使没有经过针对这些特定任务的训练。 为了获得与原始softmax层相似的权重,在GAP层的输出上训练线性SVM。(?)
4.1 细粒度识别
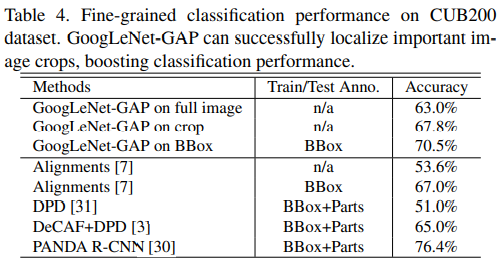
4.2 模式发现
给定一组包含共同概念的图像,想确定网络将哪些区域识别为重要区域,以及这是否与输入模式相对应。
在GoogLeNet-GAP网络的GAP层上训练线性SVM,并应用CAM技术来识别重要区域。
- 场景中发现信息目标:观察到高激活区域通常对应于特定场景类别的对象指示
- 弱标签图像概念定位:即使短语比典型的对象名称抽象,CAM仍定位了概念的信息区域
- 弱监督文本检测器:无需使用边界框注释即可准确地突出显示文本
- 解释视觉问题解答:方法突出显示了与预测答案相关的图像区域
5 可视化特定类别的单位
CNN各个层的卷积单元充当视觉概念检测器,将低级概念识别为高级概念。**随网络深入,单元越具有区别性。 **
但考虑到许多网络中的全连接层,很难确定不同单元对于识别不同类别的重要性。 在这里,使用GAP和排序的softmax权重,可直接可视化对于给定类别最有区别的单位。 称它们为CNN特定于类的单元。

从图中可以识别出对分类最具有区别性的对象部分,并准确地确定了哪些单元可以检测到这些部分。
可以推断出CNN实际上是学习一袋单词,其中每个单词都是一个区分类的特定单元。 这些特定于类别的单元的组合可指导CNN对每个图像进行分类。
6 总结
- 全局平均池化的类激活图技术CAM,这使经过分类训练的CNN可以学习对象定位能力,而无需任何边界框。 类别激活图可以在任何给定图像上可视化预测的类别分数,突出显示CNN检测到的区分对象部分。
- CAM定位技术可以推广到其他视觉识别任务,即可以产生通用的可定位深度特征。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)