
MapReduce编程模型开发简单且功能强大,专门为并行处理大规模数据量而设计,接下来,我们通过一张图来描述MapReduce的工作过程,如下图所示。
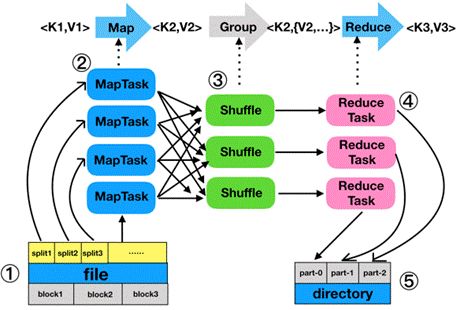
在图中,MapReduce的工作流程大致可以分为5步,具体如下:
1.分片、格式化数据源
输入Map阶段的数据源,必须经过分片和格式化操作。
分片操作:指的是将源文件划分为大小相等的小数据块(Hadoop2.x中默认128M),也就是分片(split),Hadoop会为每一个分片构建一个Map任务,并由该任务运行自定义的map()函数,从而处理分片里的每一条记录;
格式化操作:将划分好的分片(split)格式化为键值对<key,value>形式的数据,其中,key代表偏移量,value代表每一行内容。
2.执行MapTask
每个Map任务都有一个内存缓冲区(缓冲区大小100M),输入的分片(split)数据经过Map任务处理后的中间结果,会写入内存缓冲区中。如果写入的数据达到内存缓冲的阀值(80M),会启动一个线程将内存中的溢出数据写入磁盘,同时不影响map中间结果继续写入缓冲区。
在溢写过程中,MapReduce框架会对Key进行排序,如果中间结果比较大,会形成多个溢写文件,最后的缓冲区数据也会全部溢写入磁盘形成一个溢写文件,如果是多个溢写文件,则最后合并所有的溢写文件为一个文件。
3.执行Shuffle过程
MapReduce工作过程中,map阶段处理的数据如何传递给Reduce阶段,这是MapReduce框架中关键的一个过程,这个过程叫做Shuffle。
Shuffle会将MapTask输出的处理结果数据,分发给ReduceTask,并在分发的过程中,对数据按key进行分区和排序。
4.执行ReduceTask
输入ReduceTask的数据流是<key,{value list}>形式,用户可以自定义reduce()方法进行逻辑处理,最终以<key,value>的形式输出。
5.写入文件
MapReduce框架会自动把ReduceTask生成的<key,value>传入OutputFormat的write方法,实现文件的写入操作。



以上就是播妞为大家分享的干货内容
希望对你有所帮助
黑马程序员
累计培养30余万名优质IT人才
8大学科火热报名中
基础班仅需 28 元,扫码免费咨询

线上课程咨询联系播妞(微信:heiniu526)
丨热门教程资源免费领丨
回复【领取资源】领《黑马8学科汇总教程》
回复【1026】领《SpringBoot2全套》
回复【瑞吉外卖】领《瑞吉外卖项目教程》
回复【mysql1】领《Mysql入门到精通》
回复【毕业设计】领《Java毕业设计项目》
更多教程加播妞领取:heiniu526
(在下方公众号回复对应关键词,即可领取哦)
↓↓↓

本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)