慢查询如何优化?
- 1. 数据库中设置SQL慢查询
- 2. 分析慢查询日志
- 3. 常见的慢查询优化
- 3.1 索引没起作用的情况
- 3.2 分拆关联查询
- 3.4 limit偏移量过大
-
- 3.3 分库分表
- 3.4 使用专业查询的中间件 ES
- 4. 实战慢查询
- 4.1 首先查看是否开启了慢查询日志 slow-query-log
- 4.2 没开启的话就开启
- 4.3 测试慢查询
- 4.4 查看慢查询日志
- 4.5 explain 进行找到对应连接类型
- 4.6 可以查看慢查询出现了多少次
1. 数据库中设置SQL慢查询
windows中是 my.ini 文件
linux和MacOs中是 my.cnf 文件
开启慢查询日志
5.5以上版本
slow_query_log=1
slow-query-log-file=/www/server/data/mysql-slow.log
long_query_time=1
2. 分析慢查询日志
直接分析慢查询日志,
mysql使用explain + sql语句进行模拟优化器来执行分析。
oracle使用explain plan for + sql语句进行模拟优化器来执行分析。
table | type | possible_keys | key |key_len | ref | rows | Extra EXPLAIN列的解释:
table 显示这一行的数据是关于哪张表的
type 这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、indexhe和ALL
rows 显示需要扫描行数
key 使用的索引
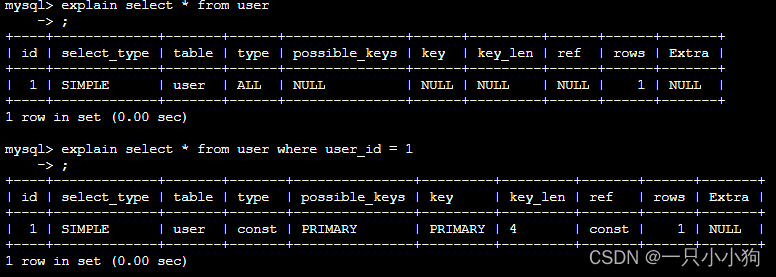
3. 常见的慢查询优化
是否有无使用索引,如果没有使用那必然慢,如果使用了:
3.1 索引没起作用的情况
- 使用了like模糊查询,查询条件中第一个字符为 “ % ” ,索引不会起作用,只有“ % ”字符不在第一个位置时才会起作用。
- 使用多列索引的查询语句,一个索引最多可以包含16个字段,但是只有第一个字段的时候,这个索引才会生效。
3.2 分拆关联查询
SELECT * FROM tag
JOIN tag_post ON tag_id = tag.id
JOIN post ON tag_post.post_id = post.id
WHERE tag.tag = 'mysql';
分解为:
SELECT * FROM tag WHERE tag = 'mysql';
SELECT * FROM tag_post WHERE tag_id = 1234;
SELECT * FROM post WHERE post.id in (123,456,567);
3.4 limit偏移量过大
Mysql下 使用limit
select * from tabl limit 1000,10 0.17s
select * from tabl limit 10000,10 0.12s
select * from tabl limit 100000,10 0.97s
select * from tabl limit 1000000,10 1.66s
select * from tabl limit 10000000,10 8.56s
越往后分页,LIMIT语句的偏移量就会越大,速度也会明显变慢。
索引的结构(B+树)有一个特性,就是叶子节点之间依靠双向链表连接,这个特性主要是针对范围查询做的优化,因此在进行分页查询的时候,我们会直接通过链表进行查询,问题就出在了这里,由于页码过大,而且查询字段过多,每次查询时候需要回表,所以链表在遍历的时候时间过长,造成了性能瓶颈。
3.4.1 解决方案
使用索引查询id
select id from tabl limit 10000000,10 1.3s
在sql中先分页查询到id(不需回表查询速度较快),然后在进行表关联进行分页查询
select table.* from table_name as table inner join ( select id from table limit 3000000,10 ) as tmp on tmp.id=table.id;
或者直接通过主键id进行搜索数据。
3.3 分库分表
- 水平分表: 是将一张表的字段拆分到两张表上,从而达到单表数据存储量降低的目的。
- 垂直分表: 是单表数据过多后,会导致数据查询时候读盘次数增加,从而查询效率降低,这时候就考虑将数据分到多张表上。这里分拆使用分桶就行,将拆分键进行一定的算法(比如:hash运算后按照分表数取模),最终落到某张表中。
分库:一个数据库有最大连接数,如果超过了这个连接数,在高并发情况下就需要考虑分库,参考每秒查询率,QPS queries-pre-seconds。
3.4 使用专业查询的中间件 ES
如果是在查询效率提升不上去,就考虑更换查询中间件吧,使用大数据的处理方式,比如,落ElasticSearch查询。
4. 实战慢查询
4.1 首先查看是否开启了慢查询日志 slow-query-log
SHOW VARIABLES LIKE '%slow_query_log%';
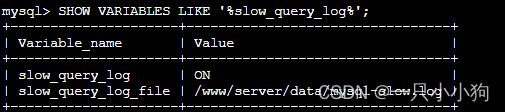
4.2 没开启的话就开启
mysql> set global slow_query_log=1;
查看慢查询判定时间
mysql> SHOW VARIABLES LIKE 'long_query_time%';
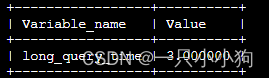
修改为3秒
mysql> set global long_query_time=3;
重新连接后修改成功
4.3 测试慢查询
select sleep(4);
4.4 查看慢查询日志

找到了对应语句
4.5 explain 进行找到对应连接类型

可以看到连接类型是主键id 是最快的const类型,并且只有一行rows需要检索。
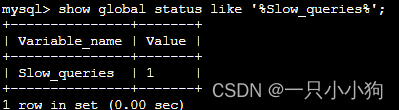
4.6 可以查看慢查询出现了多少次
mysql> show global status like '%Slow_queries%';
如有错误欢迎指正
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)