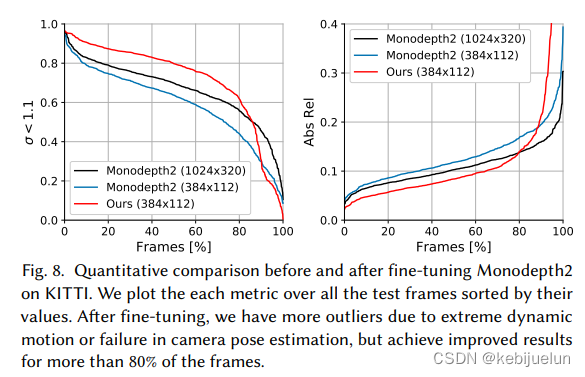
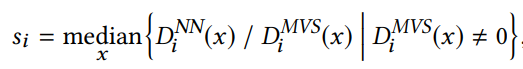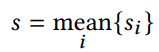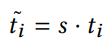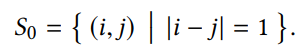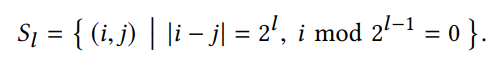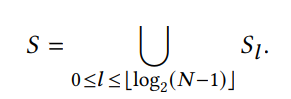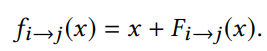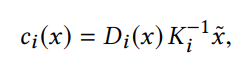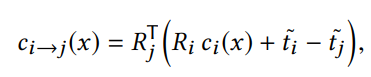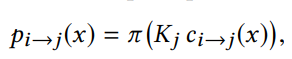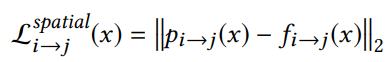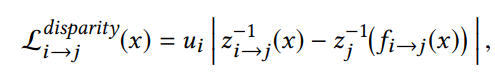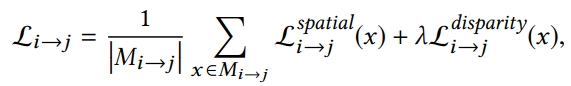对单帧深度估计模型进行 finetune,如上图所示,基于不同帧的稠密匹配关系采样匹配帧,将匹配帧送入单帧深度估计网络得到估计的深度图,通过对估计的深度图进行重投影,并对重投影结果的稠密匹配进行对比可以确认估计的深度图是否满足几何一致性,最后设计了 spatial loss 和 disparity loss 来对网络进行 finetune
预处理细节
scale 匹配: SFM(colmap) 与深度估计网络的 scale 一般是不匹配的,也即两者估计的深度的值域范围不同,这里通过调节 SFM 的 scale 来进行匹配,因为只需要简单在相机内参上乘上一个 sacle,匹配方式为对每张深度图进行中值对齐配准: 其中
D
i
N
N
D_{i}^{NN}
DiNN 为深度估计网络得到的深度,
D
i
M
V
S
D_{i}^{MVS}
DiMVS 为 colmap 产生的深度, D(x) 代表 pixel x 处的深度
image-space loss(图像空间损失):即对比光流映射得到的图像像素(
f
i
→
j
(
x
)
f_{i \to j}(x)
fi→j(x) )与基于重投影得到的像素(
p
i
→
j
(
x
)
p_{i \to j}(x)
pi→j(x) )计算 L2 损失
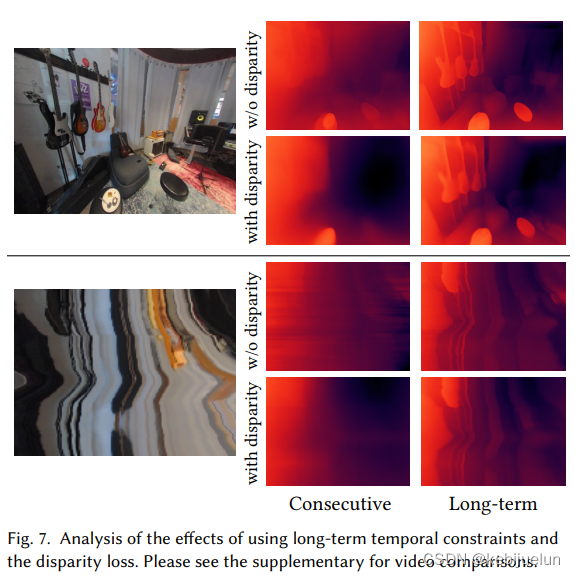
disparity loss(视差损失): 约束不同相机坐标系下的视差一致,也即希望同一个空间点在不同帧预测的深度图中深度保持一致(几何一致性) 其中
u
i
u_{i}
ui 是 i 帧的焦距,
z
i
z_{i}
zi、
z
i
→
j
z_{i \to j}
zi→j 分别是是将 i 帧相机坐标系与 i 到 j 的 z 分量 (深度)
整体损失:
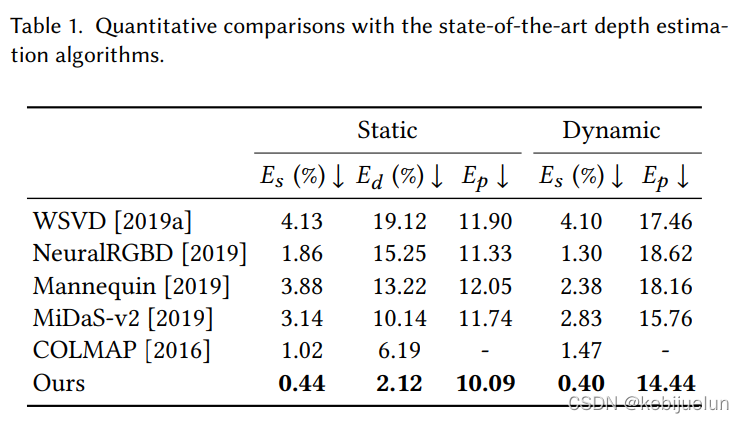
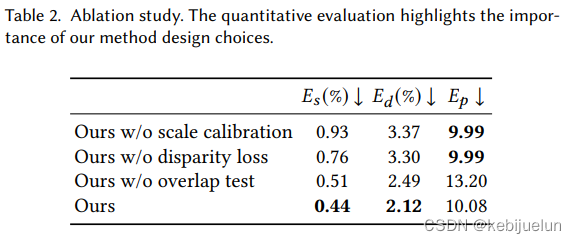
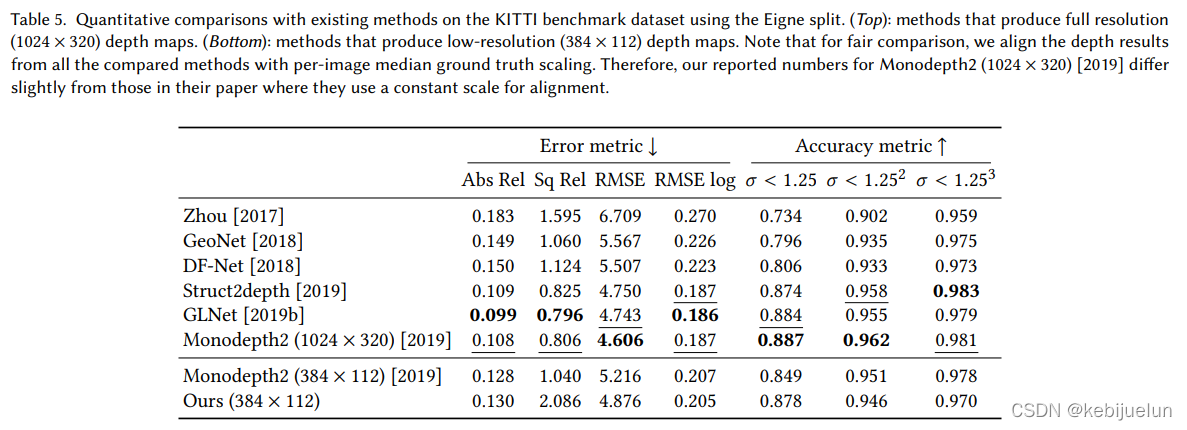
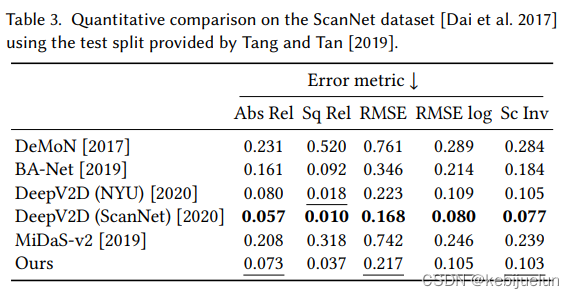
实验结果
finetune 设置:一般训练 20 epoch,对于 244 帧的视频,在 4 NVIDIA Tesla M40 上需要训练 40 min

 整个 PPL 分为两个阶段:预处理、测试时训练
整个 PPL 分为两个阶段:预处理、测试时训练