对于MapReduce相信大家并不陌生,它是大数据Hadoop家族中最重要的成员之一,是一个运行在Hadoop平台上的分布式计算框架,对于大数据这块,大家总是觉得高深莫测,浅尝辄止,今天我们就通俗易懂的给大家讲讲,让大家真正的感受到MapReduce是什么?如何使用?在哪些场景下用?
我们先来一个简单的Case,冬天来了,是吃火锅的季节了,你买了肥牛、蘑菇、白菜、香菜、豆腐、鸭血、小葱,一个个的处理干净,装在盘子里,火锅底料一放,菜一下,香喷喷的火锅就出来了。在这个吃火锅的场景中,我们可以抽象一下,它包含两部分:洗干净菜,煮菜,换做MapReduce的语言,每洗干净一个菜就是一个Map操作,将白菜Map一下,香菜Map一下,每煮一次火锅就是一个Reduce操作。这意味着每煮一次火锅就需要把洗干净的菜都放进来,也就是把所有Map操作的菜都处理一下。
MapReduce还是一个分布式计算框架,所谓分布式就是可以多个操作并行。你煮的火锅实在太好吃了,在民意要求下,你开启了火锅店,做大做强又开启了火锅分店,这时候你需要多个人去洗菜,一个人负责洗白菜、一个人负责切肥牛、一个人负责切豆腐,当所有的人都处理完了之后,就有了处理好的白菜、肥牛、豆腐,这些都是基于Map白菜、Map肥牛、Map豆腐的操作下进行的,Reduce操作是基于Key来进行,Key就是洗干净的白菜、肥牛、豆腐,Reduce之后就是一桌又一桌的火锅。
总结一下,MapReduce是包含两部分,即Map操作、Reduce操作,Map操作就是映射操作,它接受一个输入,产生一个中间键值对的输出,MapReduce框架会把Map函数中参数的中间键值对里相同的键值传给Reduce函数。Reduce操作就是化简,它接受一个键值,将这组值合并产生更小的值。
今年的双十一开始了,老板交给你一个任务,统计下所有牛仔裤最受欢迎的top3。如果是小电商平台,那很简单,写个程序获取所有的牛仔裤,遍历一下每条牛仔裤被购买的次数,再做一个排序,就知道最受欢迎的牛仔裤了。但是当我是一个中型电商平台时,遍历就会比较慢了,这时候可以写一个多线程的程序,在多核机器上去运行就行。当我是一个大型电商平台,比如淘宝、京东、拼多多,我们就可以把计算每个牛仔裤被买次数的作业分给多台机器去计算,把总的销售数据分成N份,每台计算机计算1份,最后汇总起来倒序排即可。上述三种算法,其实我们也可以使用MapReduce来完成噢。
在MapReduce中,Map函数和Reduce函数都是由我们自己定义的,在统计牛仔裤的销量top3场景中,我们定义map函数获取每款牛仔裤,Reduce函数统计每款牛仔裤被购买的次数。在下图中,Map函数接受的key是所有商品,值是取牛仔裤,每遇到一个牛仔裤就产生一个中间键值对<jeans,1>,不同牛仔裤是不同的键值对,比如bluejeans,yellowjeans。Map函数将键值相同的键值对都传递给reduce,reduce将每个键值对的value进行累加,最后获取到每条牛仔裤被购买的次数,存储在底层的分布式文件系统HDFS中,业务层可以通过接口获取数据,展现最热销的top3牛仔裤。
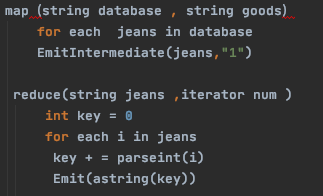
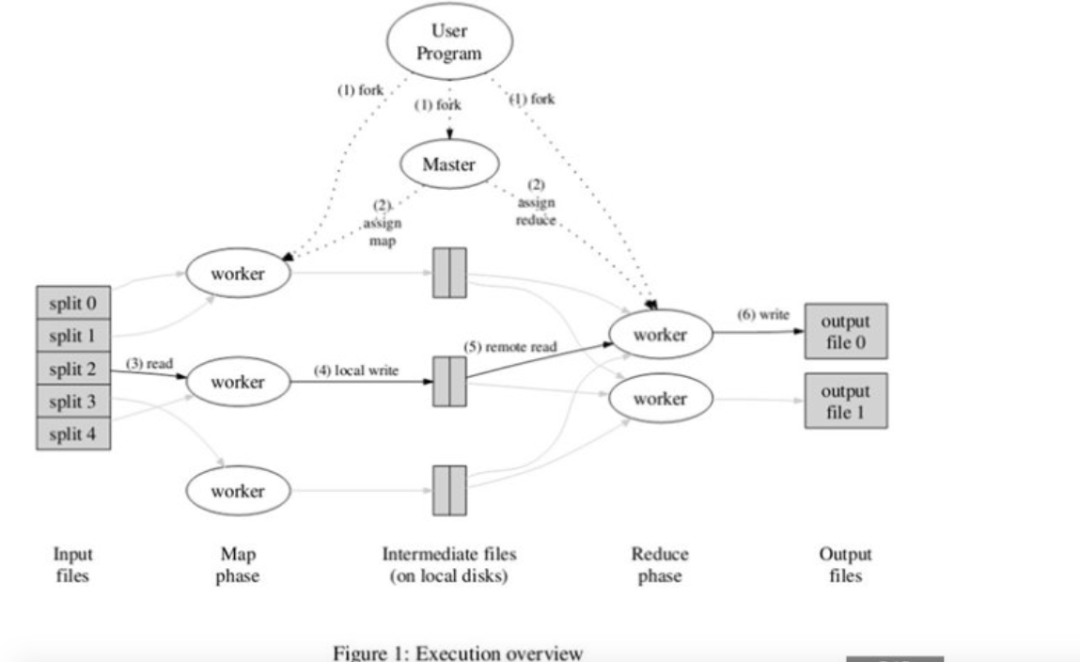
通过实例我们明白了MapReduce是个什么东东,我们可以再结合Google论文中的工作原理流程图来进行最后的梳理。
在流程图中上层业务通过UserProgram连接MapReduce库,将输入文件分成M份,即图中的spilt0、spilt1、spilt2、spilt3、spilt4...,在使用master节点给worker节点分配Map作业,我们有M份文件就分配M个worker,被分配了Map作业的worker读取对应的数据,生成中间键值对,存储在内存和磁盘中,Reduce函数也会根据作业数进行分区,如果有M个作业,就分成M个区,由Master节点把分区作业从磁盘中传递给到ReduceWorker节点,Reduceworker节点获取到所有的中间键值对之后,进行排序处理,获取每个相同中间键值对的值。当所有的Map作业和Reduce作业都执行完了之后,master节点唤醒userprogram获取数据。
通过老板安排的简简单单的获取最热销牛仔裤的任务,我们从原理到实践讲解了MapReduce的使用。MapReduce它比较适合大型网站的数据统计、在海量数据中获取某些有特征的数据,但是不太适合实时计算,从它的输入都是静态数据,计算过程,存储是在HDFS都可以看到执行任务相对耗时比较长。我们结合自己业务情况,使用在最合适的场景即可。
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)