文章目录
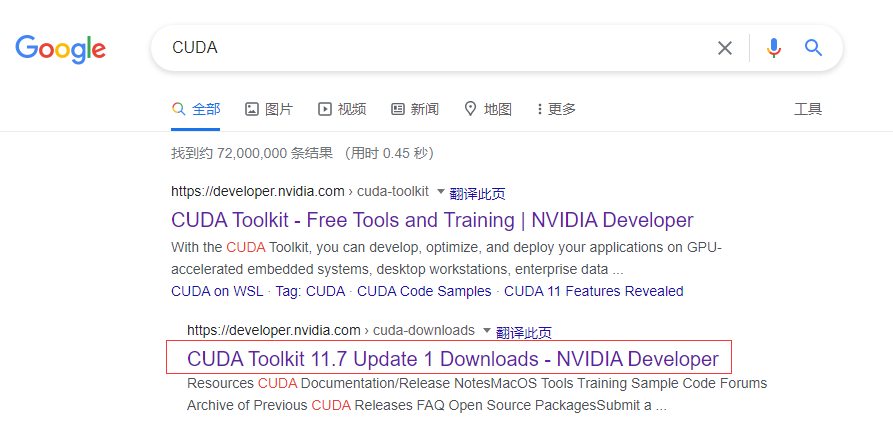
- 1.搜索CUDA,进入官网
- 2.选择以前的版本
- 3.选择指定的版本
- 4.选择操作系统并下载
- 5.以管理员身份运行安装CUDA
- 6.测试是否安装成功
1.搜索CUDA,进入官网
2.选择以前的版本
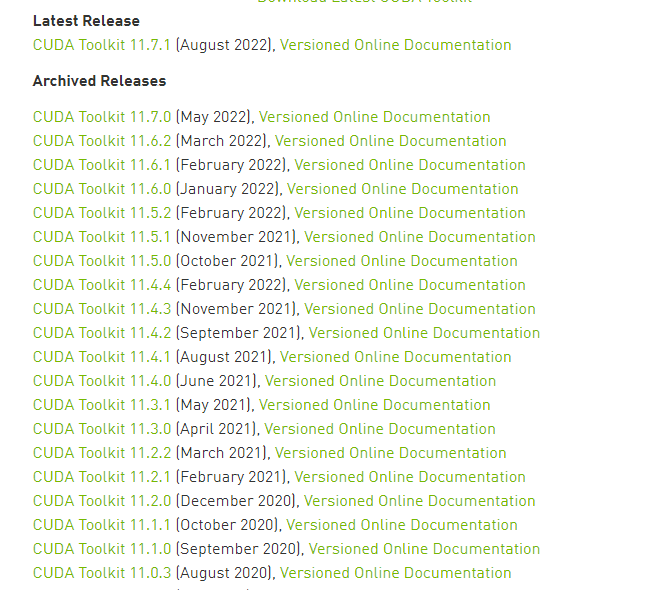
3.选择指定的版本
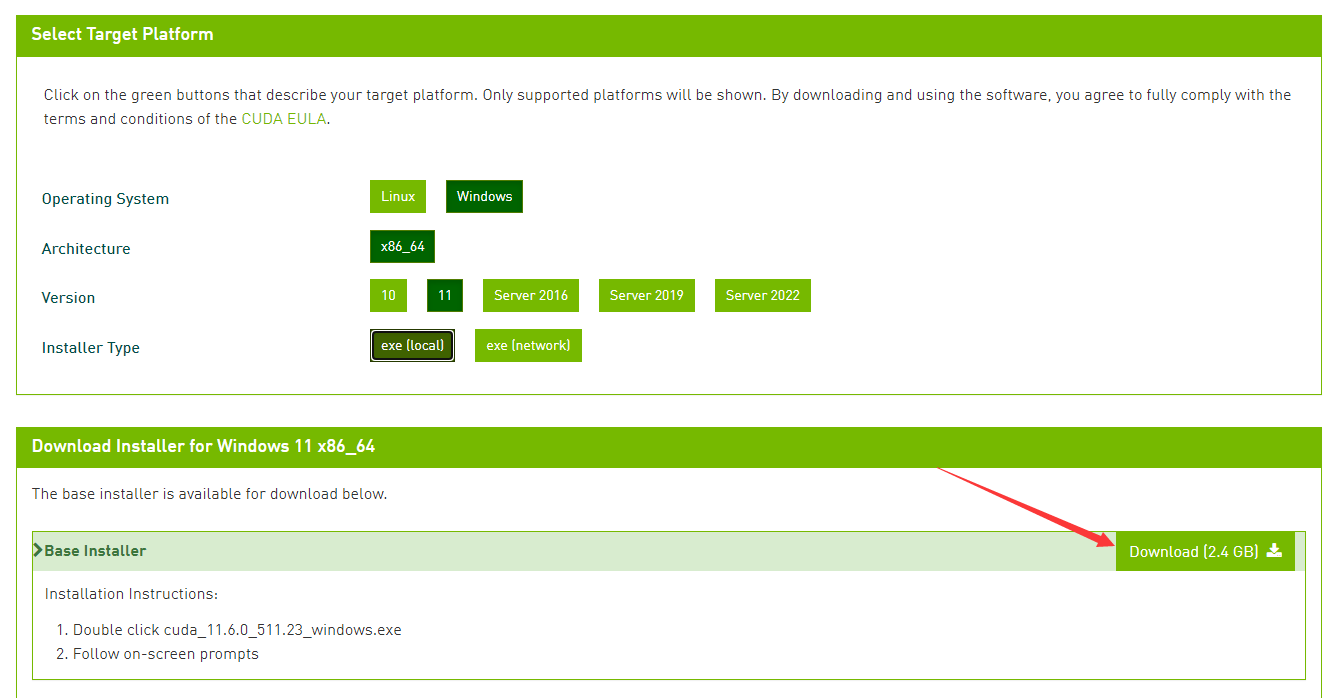
4.选择操作系统并下载
5.以管理员身份运行安装CUDA
- 点击【同意并继续】
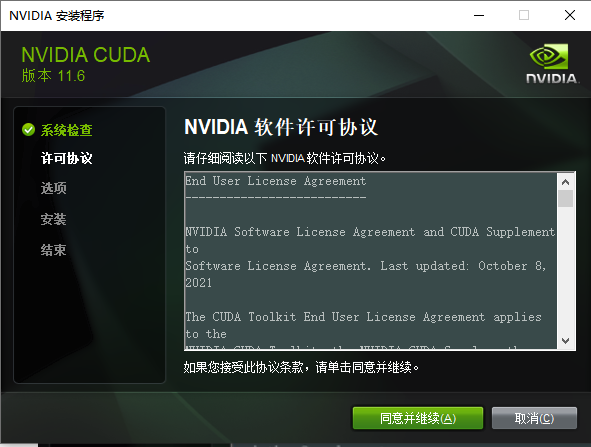
- 选择【自定义】,点击【下一步】
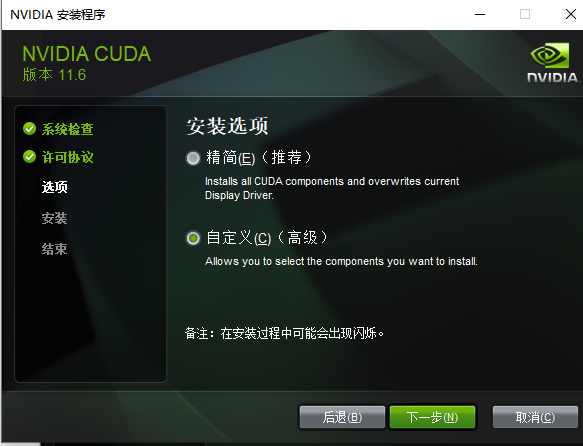
- 自定义安装选项,如果新版本高于当前版本则勾选,如果新版本低于当前版本则不勾选
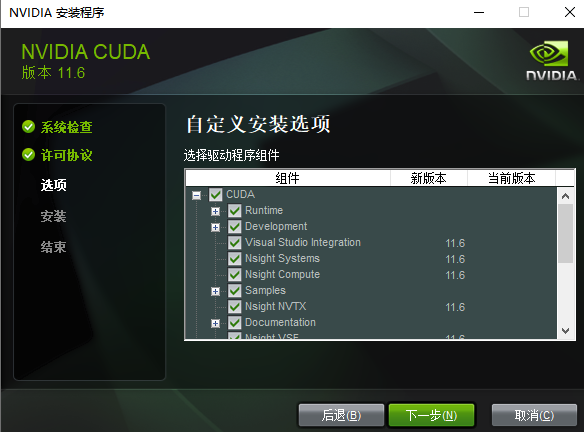
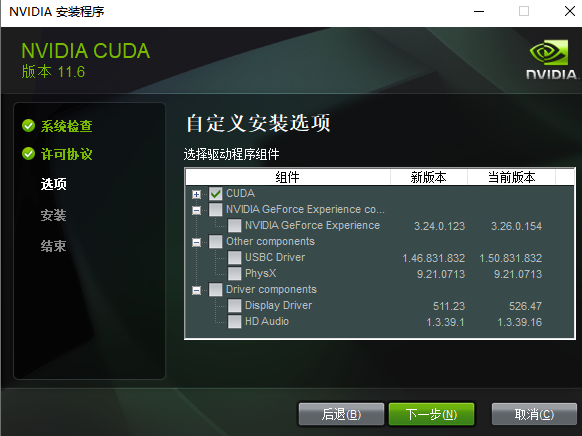
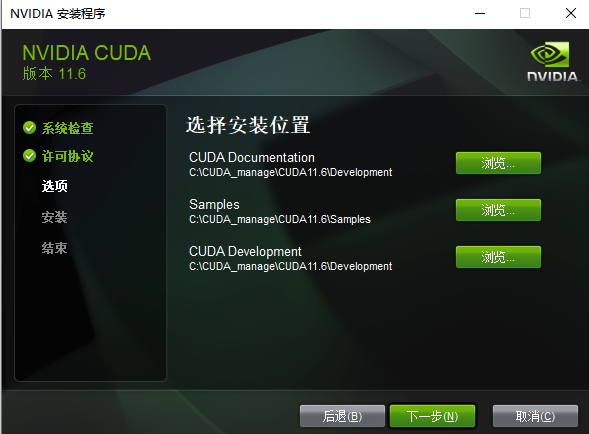
- 选择安装位置
- 在C盘下创建目录 CUDA_manage,在 CUDA_manage 下创建 CUDA11.6,在 CUDA11.6 下创建 Development 和 Samples
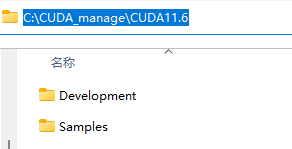
- 选择安装位置:Development 和 Documentation 放在 Development 下,Samples 放在 Samples 下
- 等待安装

- 点击【下一步】
- 点击【关闭】
6.测试是否安装成功
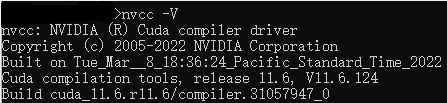
cmd命令行执行:nvcc -V
如果显示版本信息,则说明安装成功
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系:hwhale#tublm.com(使用前将#替换为@)